夜雨聆风
夜雨聆风2026年的AI圈,有一个消息让全行业震动:英伟达豪掷200亿美金收购Groq,坚定押注HBM+LPU的协同路线,试图垄断从云端到边缘的全场景推理算力。而与此同时,AI行业正面临一个普遍困境——AI快用不起了!智谱、Anthropic等大模型机构密集涨价、调整计费模式,背后的核心症结,正是端侧AI推理的底层架构瓶颈。
如今,全球端侧AI推理赛道已经悄然分成了三条截然不同的路线,分别由英伟达、高通和中国企业主导,三种路线对应三种不同的技术逻辑和市场定位,也决定了各自在端侧市场的竞争力。
第一条是英伟达主导的“补短板式”升级,用LPU弥补GPU推理短板,靠HBM扛住带宽压力,核心适配云端与大规模算力网;第二条是高通深耕的生态绑定式布局,依托骁龙平台的NPU架构,走端云协同路线,聚焦消费端与行业端的轻量化推理;第三条则是中国企业走出的“原生式”创新,不依附现有架构,从底层重构端侧推理逻辑,专门适配手机、PC、智能穿戴等消费端设备,以及边缘端、太空算力网的推理需求。
简单来说,当AI从云端走进我们的口袋、戴在手腕上,国内无数端侧AI公司都在为“功耗高、成本贵、适配难”三大痛点发愁时,英伟达的方案是“将就适配”,用云端技术拼凑端侧方案;高通的方案是“生态适配”,靠绑定终端厂商抢占市场;而中国企业的方案,是“量身定制”,从根源上解决端侧的核心痛点——这就是三者最本质的区别。
| 英伟达的妥协
要理解英伟达的路线,先搞懂一个行业痛点:2026年以来,大模型机构频繁涨价,不是算力不够用,而是传统GPU的架构,撑不住当下AI Agent、重度推理工具的需求。GPU的运算逻辑是逐Token串行生成,面对24小时不间断运行的AI Agent,它的并行优势根本发挥不出来,HBM带宽就成了绕不开的物理瓶颈。
英伟达的解法,其实是一种“妥协式最优解”。2025年底,它以200亿美金拿下Groq,推出AFD架构,核心思路就是“分工协作”:让GPU专注处理需要大容量缓存的运算,发挥HBM的容量优势;让LPU专注处理对带宽敏感的运算,用片上SRAM的高带宽弥补HBM的短板。
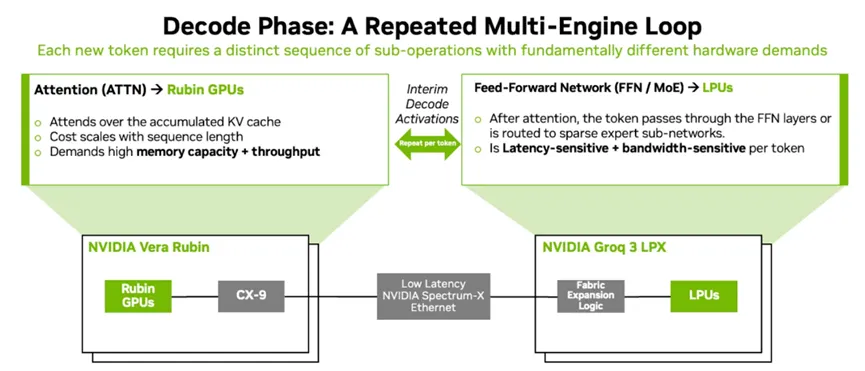
英伟达AFD架构解码原理示意图,源于NVIDIA官网
这套方案在云端和大规模算力中心确实好用,英伟达官方数据显示,每兆瓦功耗的推理吞吐量能提升35倍,万亿参数模型的收益机会也能提升10倍。但一旦放到端侧,问题就全暴露了。
首先是成本太高,HBM作为高端内存,技术门槛高、被少数厂商垄断,一块HBM芯片的成本,甚至超过很多端侧设备的核心芯片总价;其次是体积和功耗失控,HBM+LPU的架构需要复杂的封装和散热,根本塞不进手机、智能手表这类小型设备;最后是适配性差,LPU需要极致的编译器优化,Groq花了8年才达到商用级别,而端侧设备场景多样、需求分散,这套复杂体系很难灵活适配。
说白了,英伟达的HBM+LPU路线,从一开始就是为云端设计的,端侧只是它的“附加场景”,是用现有技术拼凑的“补丁方案”。国内端侧AI公司大多聚焦消费电子、边缘设备,这套方案的“水土不服”,其实早已注定。
| 高通的突围
和英伟达“云端优先、端侧补位”的思路不同,高通从一开始就瞄准了端侧原生场景,依托骁龙全系列平台的Hexagon NPU架构,走出了一条“生态绑定”的差异化路线,精准切入手机、智能穿戴、AI PC等消费端核心场景,和英伟达形成了清晰的市场区隔。
高通的核心打法很简单:NPU主导+端云协同+生态闭环。它放弃了英伟达复杂的HBM+LPU架构,聚焦终端设备“轻量化、低功耗”的核心需求,在骁龙平台中集成高性能Hexagon NPU,专门优化端侧AI推理的功耗和延迟;同时提出“云强、网稳、端智能”的协同理念,让云端负责大模型训练和复杂任务调度,端侧负责实时推理、隐私保护等轻量化任务,完美适配各类终端场景。
2026年,高通的NPU架构也实现了升级,最新一代第五代骁龙8至尊版搭载的Hexagon NPU,性能提升37%,每瓦特性能提升16%,在30亿参数大语言模型上的响应速度很快,还新增了更灵活的模型部署选项,进一步优化了端侧体验。
高通最厉害的还是生态,通过高通AI Hub提供超100个预优化AI模型,联合Meta、谷歌实现主流大模型的端侧原生运行,还深度绑定小米、OPPO、荣耀等国内终端厂商,降低了端侧AI的适配门槛,形成了闭环。此外,高通还推出了AI耳机、可穿戴设备等创新产品,拓展端侧AI的应用边界,甚至试图进军数据中心领域,和英伟达争夺边缘数据中心推理市场。
但高通的路线也有明显短板。首先,它的NPU架构还是传统的“存储与计算分离”设计,数据需要在存储器和计算单元之间反复搬运,虽然通过软件优化缓解了功耗和延迟问题,但没有从根本上解决“内存墙”瓶颈;其次,生态绑定虽然降低了适配成本,但终端厂商必须遵循高通的芯片架构和接口标准,灵活性不足,且核心技术依赖海外供应链,难以满足国内厂商“自主可控”的需求;最后,它的方案在高端边缘推理、太空算力网等场景的适配能力较弱,性能提升也高度依赖工艺迭代。
| 破局
无论是英伟达的“补丁方案”,还是高通的“生态方案”,都没有从根本上解决端侧AI的核心矛盾——数据搬运的开销。对于国内端侧AI厂商来说,他们的需求很明确:高性能、低功耗、低成本、易落地,但这四个需求,前两者都无法完全满足。
国内端侧AI厂商的痛点其实很具体:消费电子行业利润微薄,HBM的高成本、高通芯片的专利费,会直接压缩盈利空间;手机、智能手表依赖电池供电,高功耗会严重影响续航;LPU的优化门槛高、高通的生态绑定限制大,中小厂商难以快速落地;HBM、高通核心芯片被海外垄断,供应链安全得不到保障。
要破解这个困局,必须从底层架构创新。国内一家成立于2021年的公司——微纳核芯,走出了这样一条路——它孵化于浙江省北大信息技术高等研究院,团队由高校博士和大厂大牛组成,在芯片设计领域的实力稳居全球第一梯队,它的核心方案,就是全球首创的3D-CIM™三维存算一体技术,不做训练、只做推理,专门为端侧场景量身定制。
所谓存算一体,核心就是打破传统“存储与计算分离”的架构,把计算单元直接集成在存储单元内部,从根源上消灭数据搬运的开销——这也是它区别于英伟达、高通的核心优势。这套技术体系包含三大核心支撑,精准破解端侧痛点:一是DRAM 3D近存技术,能提供大容量存储和高带宽,适配多模态大模型、高端边缘推理需求;二是存内计算CIM,实现高性能、低功耗、低成本的三重平衡,打破行业“不可能三角”;三是RISC-V存算(RV-CIM™),解决软件适配难题,降低国内厂商的落地门槛。

微纳核芯3D-CIM™三维存算一体架构示意图
| 技术硬碰硬
英伟达和高通的路线,本质上都是“缓解问题”,而中国公司的存算一体路线,是“从根源上解决问题”,两者的差异,在实际应用中体现得很明显。
英伟达靠HBM解决带宽问题,但HBM成本高、功耗大,根本不适合端侧消费电子;高通用常规内存适配端侧,但带宽和能效有限,无法支撑高端场景,且两者都没有解决数据搬运的核心痛点。而中国公司的3D堆叠DRAM,用垂直堆叠技术替代HBM和常规内存,带宽密度远超两者,延迟低至纳秒级,每比特能耗仅为HBM的1/4,成本更是控制在HBM的1/3以下,更重要的是,它能实现全国产化适配,彻底解决供应链卡脖子问题。
再看计算架构,英伟达的LPU需要和GPU协同工作,协同调度复杂,国内厂商难以适配,且无法独立满足端侧轻量化需求;高通的NPU虽然是端侧原生设计,但仍未摆脱“存储与计算分离”的短板,数据搬运消耗大量功耗。而中国公司的数字域SRAM存算一体,把计算单元集成在存储内部,从源头消除数据搬运开销,算力密度和能效比,比英伟达架构提升4-6倍,比高通架构提升3-5倍——应用在智能手表上,能让AI功能续航提升30%以上;应用在手机上,能让大模型推理速度提升50%,功耗降低40%,真正实现了三者兼顾。
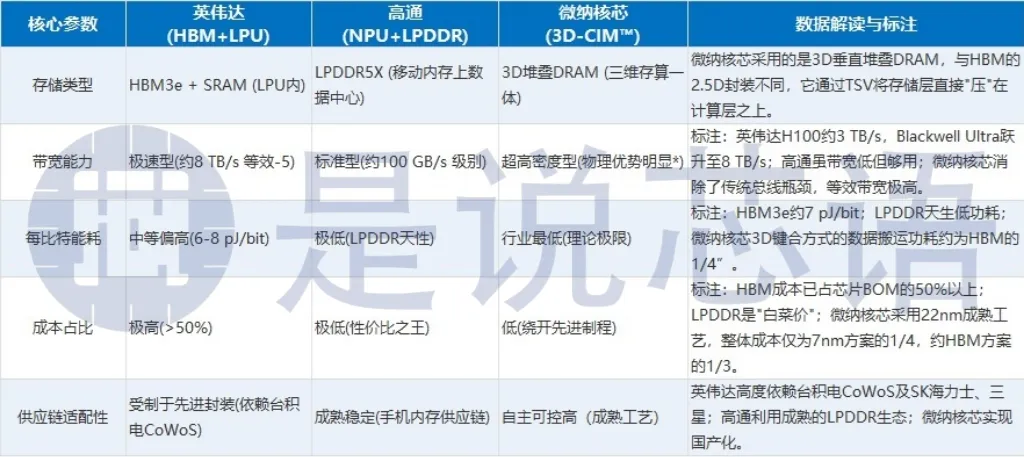
HBM、LPDDR与3D堆叠DRAM核心参数对比
值得一提的是,这套存算一体方案,还通过RISC-V存算(RV-CIM™)解决了软件适配的难题,不用像英伟达那样依赖复杂的编译器优化,也不用像高通那样被生态绑定,能灵活适配国内主流大模型,让国内中小厂商也能快速落地,这也是它最贴合国内市场需求的地方。
| 端侧AI的胜负手
2026年,AI竞争已从云端下沉到端侧,端侧市场的争夺,直接决定着AI产业的未来格局。中国公司的存算一体路线,精准贴合国内端侧AI厂商的实际需求,以原生设计破解了功耗、成本、供应链三大核心痛点,实现了高性能与低成本的平衡,更能适配手机、智能穿戴、边缘设备等各类落地场景,填补了国内端侧推理底层架构的空白。
目前,微纳核芯三维存算一体技术已完成FPGA验证,且已与国内多家消费电子厂商达成合作,正稳步推进商业化落地。相较于英伟达、高通的成熟生态,它仍有优化空间,但对国内端侧AI公司而言,这不是“仰望的标杆”或“参考的模板”,而是当下可落地、能落地,且符合本土供应链需求的最优选择。
未来,端侧AI的落地关键,不在于云端算力的延伸,也不在于生态的强绑定,而在于能否真正解决国内厂商的实际痛点——这正是中国存算一体方案的核心价值,也是其在端侧赛道破局的关键。

是说芯语原创,欢迎关注分享
合作洽谈,进入公众号:服务—>商务合作