 夜雨聆风
夜雨聆风引言:AI不是“万能钥匙”,而是“场景工具箱”
你每天都在和AI打交道:刷脸开门用的是计算机视觉算法,抖音推视频靠的是推荐系统算法,ChatGPT写文案用的是自然语言处理算法,自动驾驶避障依赖多传感器融合算法,医院CT影像分析则是医疗AI算法。
很多人觉得AI高深莫测,但其实每个领域的AI算法都是为解决特定场景问题而生的——就像你不会用螺丝刀拧螺丝,也不会用扳手钉钉子。本文把5大热门领域的AI算法拆成“大白话解释+手把手实操+避坑小技巧”,零基础也能快速上手,看完就能动手写代码做项目。
一、计算机视觉(CV):让AI“看懂”世界的滤镜游戏
1. 核心算法大白话
(1)CNN:图像识别的“滤镜叠叠乐”
把CNN想象成一系列叠加的滤镜:第一层滤镜找图像的边缘线条,第二层找圆形、方形等形状,第三层拼出猫、狗等物体。就像你看照片时,先认轮廓,再辨细节,最后认出是什么东西。
(2)YOLO:实时找物体的“快手侦探”
YOLO的全称是“You Only Look Once”,意思是“只看一眼就搞定”。它能在1秒内扫描整张图片,同时找出所有物体的位置和类别——比如你拍视频时,AI实时框出画面里的人和车,就是YOLO在工作。
(3)GAN:AI界的“造假大师”
GAN是两个AI的“对抗游戏”:一个AI(生成器)负责造假图,比如生成假人脸;另一个AI(判别器)负责打假,判断图片是真还是假。经过几万次PK,生成器能造出以假乱真的图片,比如AI绘画、老照片修复。
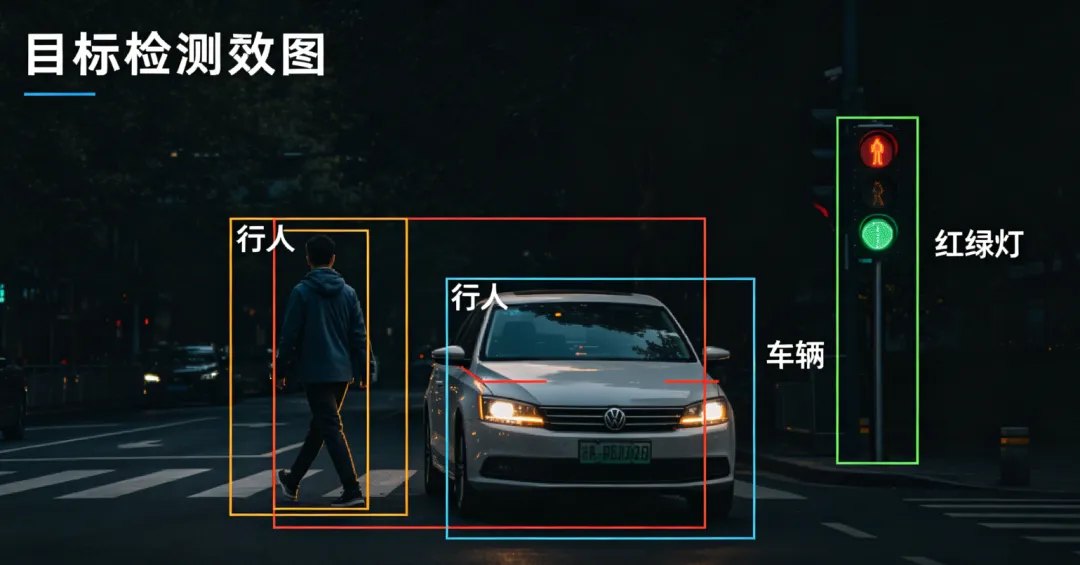
YOLOv8实时检测效果图,画面中框出行人、车辆、红绿灯

GAN生成的人脸对比图,左侧真实人脸,右侧AI生成人脸
2. 手把手实操:用YOLOv8做实时目标检测
步骤1:安装YOLOv8
打开终端,输入以下命令:
pip install ultralytics步骤2:运行实时检测
打开Python编辑器,输入代码:
from ultralytics import YOLO# 加载预训练的轻量化模型(YOLOv8n)model = YOLO('yolov8n.pt')# 调用电脑摄像头做实时检测results = model(source=0, show=True, conf=0.5)运行代码后,电脑摄像头会自动打开,画面中会实时框出检测到的物体(conf=0.5表示只显示置信度≥50%的物体)。
步骤3:自定义检测物体
如果你想检测特定物体(比如口罩),可以用LabelStudio标注100张带口罩的图片,然后用以下命令训练模型:
yolo detect train data=mask.yaml model=yolov8n.pt epochs=50训练完成后,就能用自己的模型检测口罩了。
3. 避坑小技巧
• 数据标注太麻烦:用免费工具LabelStudio,支持自动预标注,减少人工工作量; • 模型跑太慢:用YOLOv8的轻量化版本(v8n),或者把模型部署到GPU上; • 环境变化就失效:给图片加随机裁剪、颜色扰动等数据增强,让模型适应不同场景。
二、自然语言处理(NLP):让AI“听懂人话”的聊天技巧
1. 核心算法大白话
(1)Transformer:大模型的“上下文笔记”
Transformer的核心是“注意力机制”——就像你读文章时,会重点关注关键词和上下文。比如“苹果是红色的”和“苹果发布新手机”,Transformer能区分“苹果”的不同含义,因为它会记住前面的语境。
(2)LLaMA/GPT:预训练的“超级学霸”
这些大模型就像提前读了几百万本书的学霸,能回答问题、写文案、翻译语言。你只需要给它一个“指令”(比如“写一篇关于猫的短文”),它就能生成符合要求的内容。
(3)LoRA:微调大模型的“轻量工具”
大模型动辄几十亿参数,直接训练成本太高。LoRA只修改模型的一小部分参数,就能让大模型适应特定场景——比如把通用大模型改成客服机器人,只需要训练几百个样本。
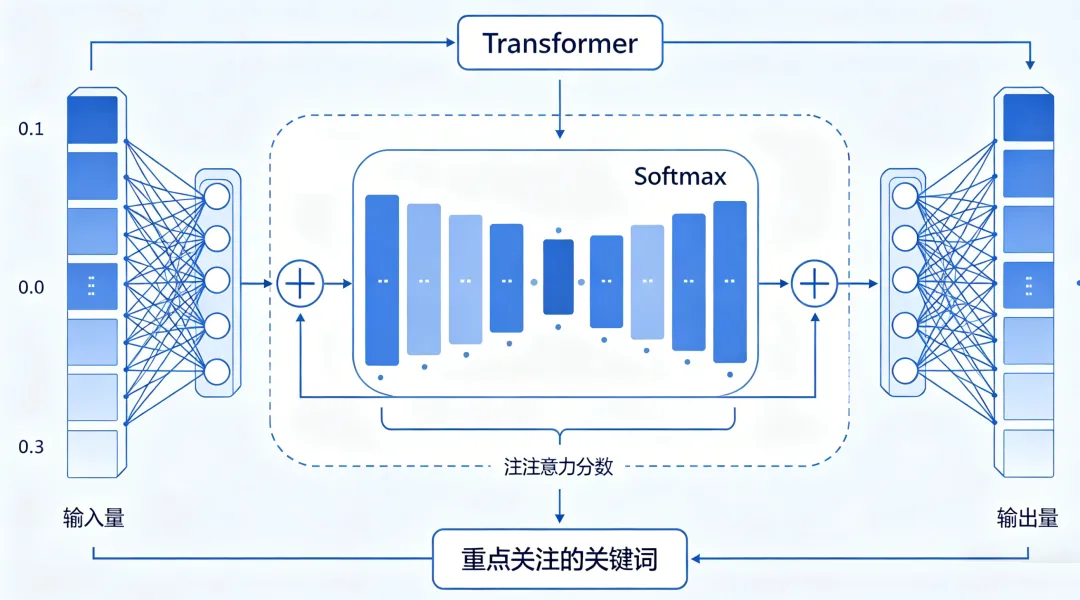
Transformer注意力机制示意图
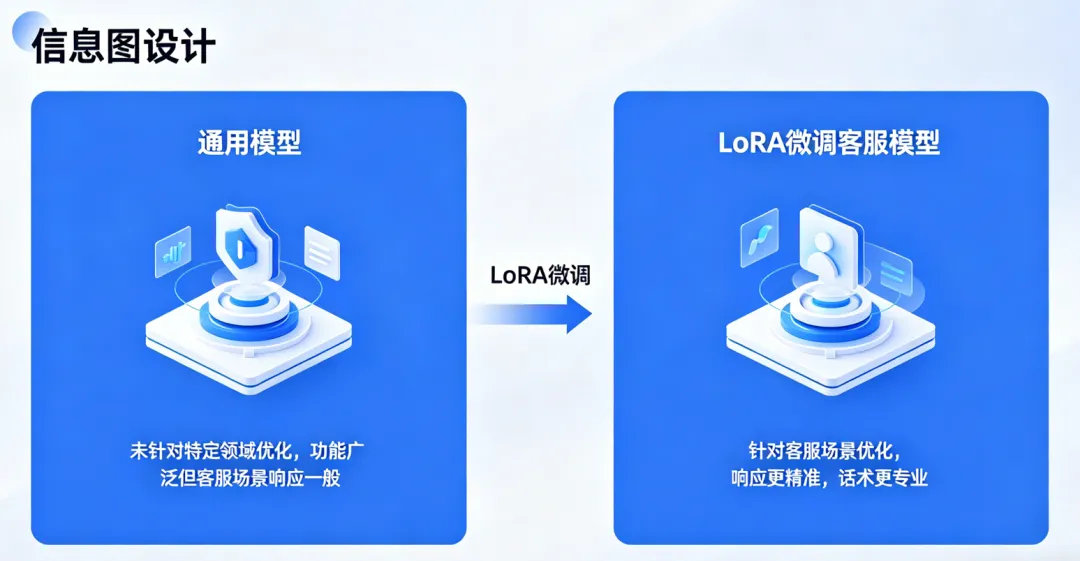
LoRA微调大模型对比图
2. 手把手实操:用LoRA微调LLaMA-2做客服机器人
步骤1:安装依赖库
pip install transformers peft accelerate torch步骤2:加载模型并配置LoRA
from peft import LoraConfig, get_peft_modelfrom transformers import LlamaForCausalLM, LlamaTokenizer# 加载LLaMA-2-7B模型(需要提前申请权限)model = LlamaForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf')tokenizer = LlamaTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf')# 配置LoRA:只训练注意力层的小部分参数lora_config = LoraConfig( r=8, # 低秩矩阵维度,越小参数越少 target_modules=['q_proj', 'v_proj'], # 目标修改的层 task_type='CAUSAL_LM')# 应用LoRA到模型model = get_peft_model(model, lora_config)model.print_trainable_parameters() # 可训练参数仅约0.1%步骤3:训练与推理
准备客服对话数据(比如“用户:我的订单什么时候发货?客服:一般48小时内发货”),然后用以下代码训练:
# 数据处理(示例)train_data = [{"text": "用户:我的订单什么时候发货?客服:一般48小时内发货"}]inputs = tokenizer([d["text"] for d in train_data], return_tensors='pt', padding=True)# 训练(简化版)model.train()optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)for epoch inrange(5): outputs = model(**inputs, labels=inputs["input_ids"]) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad()print(f"Epoch {epoch+1}, Loss: {loss.item()}")# 推理测试model.eval()input_text = "用户:我的订单什么时候发货?客服:"inputs = tokenizer(input_text, return_tensors='pt')outputs = model.generate(**inputs, max_new_tokens=30)print(tokenizer.decode(outputs[0], skip_special_tokens=True))3. 避坑小技巧
• Prompt写不好:用“指令+示例”格式,比如“请作为客服回答用户问题:示例1:用户:订单多久发货?客服:48小时内;示例2:用户:怎么退款?客服:点击我的订单申请退款”; • 大模型跑不动:用4位量化的LLaMA-2模型,或者用免费的Colab GPU训练; • 隐私问题:用本地部署的大模型(比如LLaMA-2、Qwen),避免敏感数据传到云端。
三、推荐系统:让AI“懂你喜好”的私人导购
1. 核心算法大白话
(1)协同过滤:“朋友同款”推荐
• 基于用户的协同过滤:如果A和B喜欢的商品差不多,A喜欢的东西B也可能喜欢——就像你朋友推荐的电影,你大概率也喜欢; • 基于物品的协同过滤:买了手机的人大多会买手机壳,所以给买手机的用户推荐手机壳。
(2)DeepFM:“综合打分”推荐
DeepFM会综合考虑你的年龄、性别、历史浏览记录,以及商品的类别、价格,给每个商品打个分,分数最高的推荐给你——就像导购根据你的喜好和商品特性,精准推荐合适的东西。
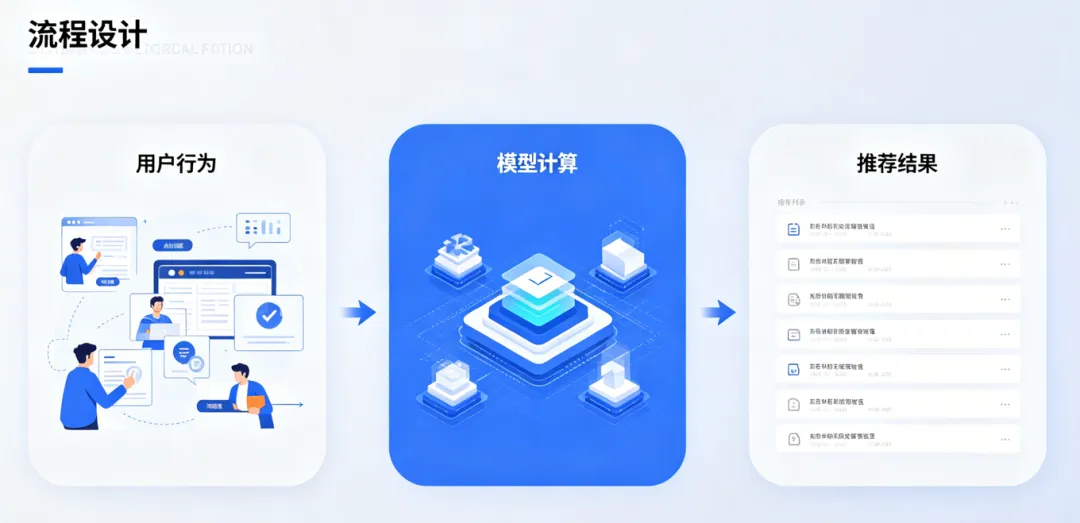
推荐系统流程示意图,“用户行为→模型计算→推荐结果”
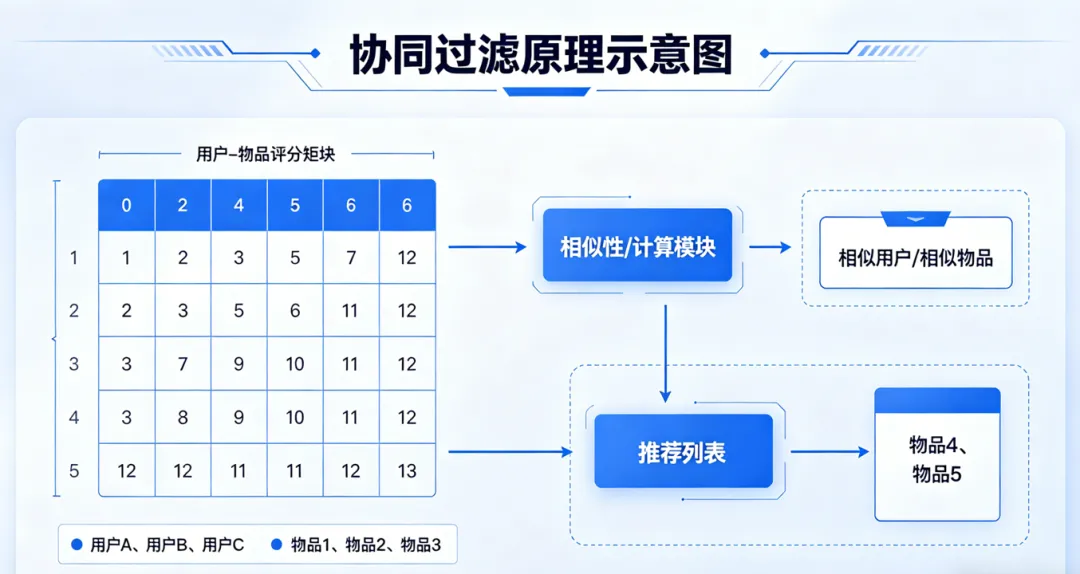
协同过滤原理示意图
2. 手把手实操:用Python做简单的电影推荐
步骤1:安装Surprise库
pip install scikit-surprise步骤2:基于用户的协同过滤推荐
from surprise import SVD, Dataset, Readerfrom surprise.model_selection import train_test_split# 加载电影评分数据(示例格式:用户ID,电影ID,评分)reader = Reader(line_format='user item rating', sep=',', rating_scale=(1, 5))data = Dataset.load_from_file('ratings.csv', reader=reader)trainset, testset = train_test_split(data, test_size=0.2)# 训练模型model = SVD()model.fit(trainset)# 给用户1推荐电影user_id = '1'movies = ['101', '102', '103'] # 未评分的电影IDfor movie_id in movies: prediction = model.predict(user_id, movie_id)print(f"电影{movie_id}的预测评分:{prediction.est:.2f}")步骤3:部署到网站(可选)
用Flask写一个简单的网页,用户输入ID,返回推荐的电影列表:
from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/recommend', methods=['GET'])defrecommend(): user_id = request.args.get('user_id')# 生成推荐列表(省略逻辑) recommendations = ['电影A', '电影B', '电影C']return jsonify({'recommendations': recommendations})if __name__ == '__main__': app.run(debug=True)3. 避坑小技巧
• 新用户没数据:先推荐热门商品,等用户有浏览记录后再切换到个性化推荐; • 推荐太单一:混合热门推荐和个性化推荐,比如80%个性化+20%热门; • 数据稀疏:用用户的隐式行为(比如点击、停留时间)代替显式评分,增加数据量。
四、自动驾驶:让AI“开好车”的老司机养成记
1. 核心算法大白话
(1)BEV感知:“上帝视角”看路况
BEV(鸟瞰图)感知会把摄像头、激光雷达的数据转换成“天空往下看”的视角,这样AI能看到车辆周围的所有物体和道路——就像你在无人机上看地面,不会有盲区。
(2)多传感器融合:“多眼合一”更靠谱
自动驾驶会同时用摄像头、激光雷达、雷达三种传感器:摄像头看颜色和形状,激光雷达测距离,雷达测速度。AI把这些数据融合在一起,就能更准确地判断路况——就像你用眼睛看、耳朵听、手摸,全方位感知环境。
(3)强化学习:“试错学习”当老司机
强化学习就像教小孩开车:AI每次做出决策(比如加速、刹车),如果做得对就给奖励,做错就给惩罚。经过几万次模拟训练,AI就能学会在复杂路况下安全行驶——就像你考驾照时,练得多了自然会开车。
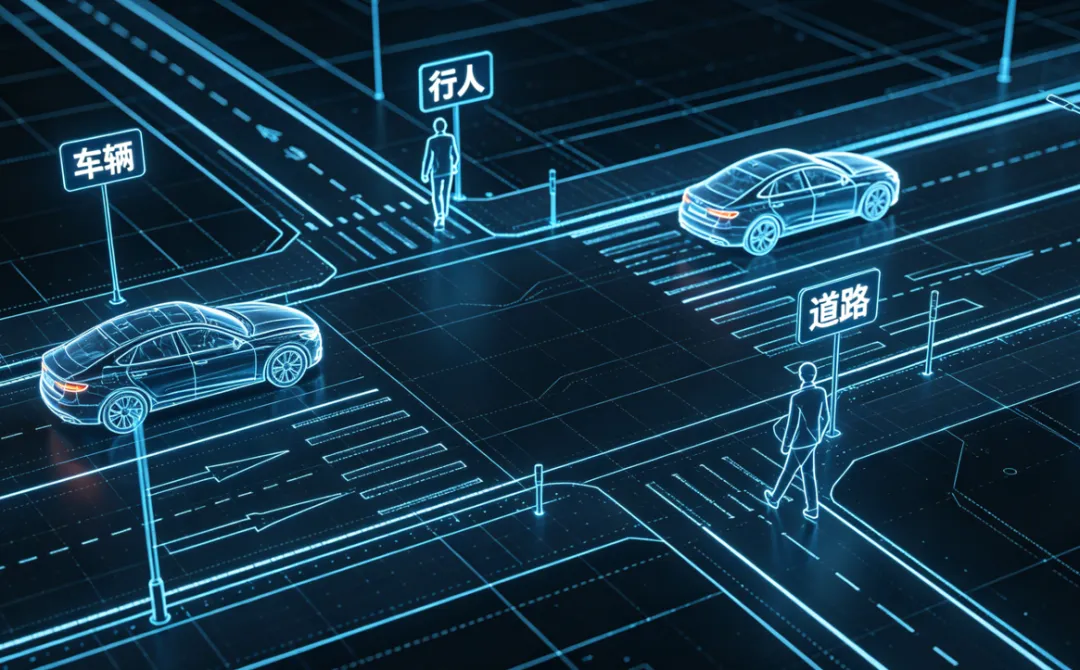
BEV感知效果示意图,鸟瞰图中标注车辆、行人、道路
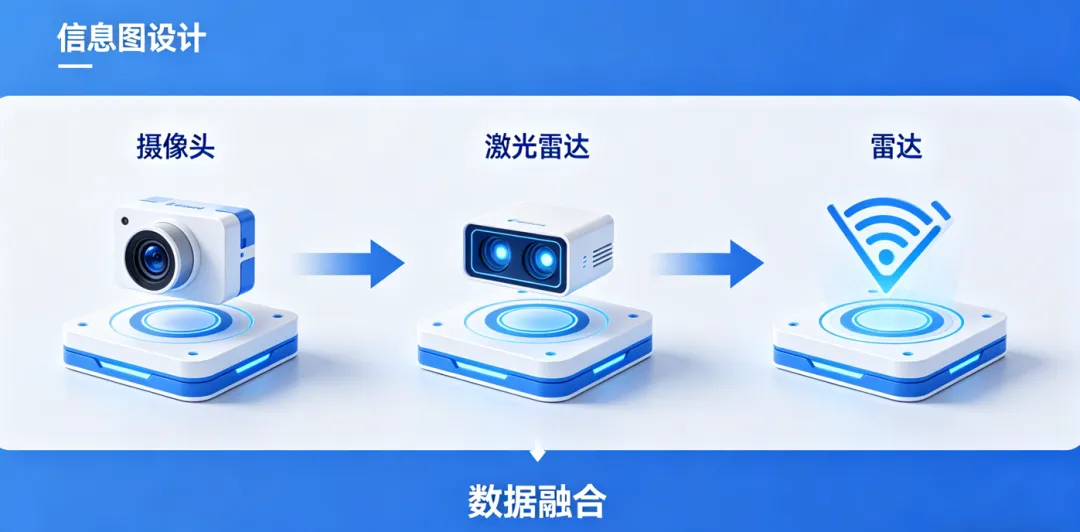
多传感器融合示意图
2. 手把手实操:用Autoware做自动驾驶模拟
步骤1:安装Autoware(开源自动驾驶平台)
参考Autoware官方文档,用Docker快速安装:
docker pull autoware/autoware-universe:latest步骤2:运行模拟环境
启动Autoware后,加载预设的城市地图,然后选择一辆虚拟车辆,点击“启动自动驾驶”,车辆会自动沿着道路行驶。
步骤3:自定义路线
用Autoware的可视化工具,在地图上画出路线,车辆会自动规划路径并行驶——就像你用导航设置目的地,自动驾驶车辆会跟着导航走。
3. 避坑小技巧
• 传感器校准难:用Autoware的可视化校准工具,实时查看传感器数据,调整参数; • 模拟和现实差距大:先在模拟环境中训练,再到封闭场地测试,最后到开放道路; • 安全性没保障:加入紧急制动系统,当AI判断失误时,人工可以接管车辆。
五、医疗AI:让AI“辅助看病”的医生助手
1. 核心算法大白话
(1)医学影像分割:“描病灶”的画笔
医学影像分割会从CT、MRI图像中精准圈出肿瘤、病变组织——就像医生用画笔在CT片上描出病灶,帮助医生更准确地诊断病情。
(2)辅助诊断模型:“超级医学知识库”
辅助诊断模型会学习几百万份病历和影像数据,当输入患者的CT片和病历,就能给出可能的诊断结果和治疗建议——就像一个懂所有医学知识的助手,帮医生快速分析病情。
(3)联邦学习:“隐私保护”的协作训练
医院的患者数据不能随便共享,联邦学习让多个医院的AI模型在本地学习自己的数据,只共享模型参数,不共享原始数据——就像多个医生一起讨论病情,但不泄露患者隐私。
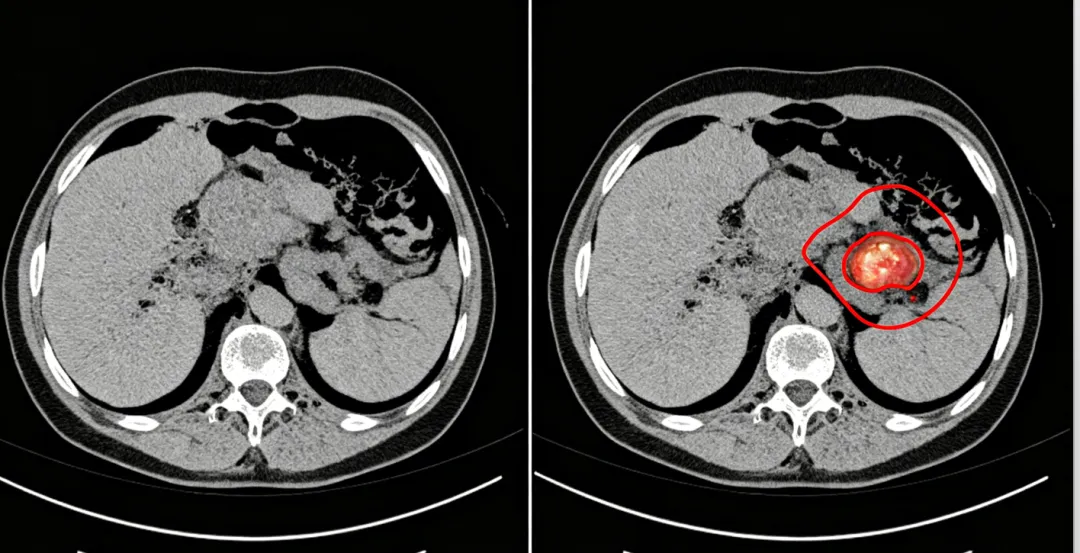
医学影像分割效果图,左侧原始CT,右侧圈出的肿瘤区域
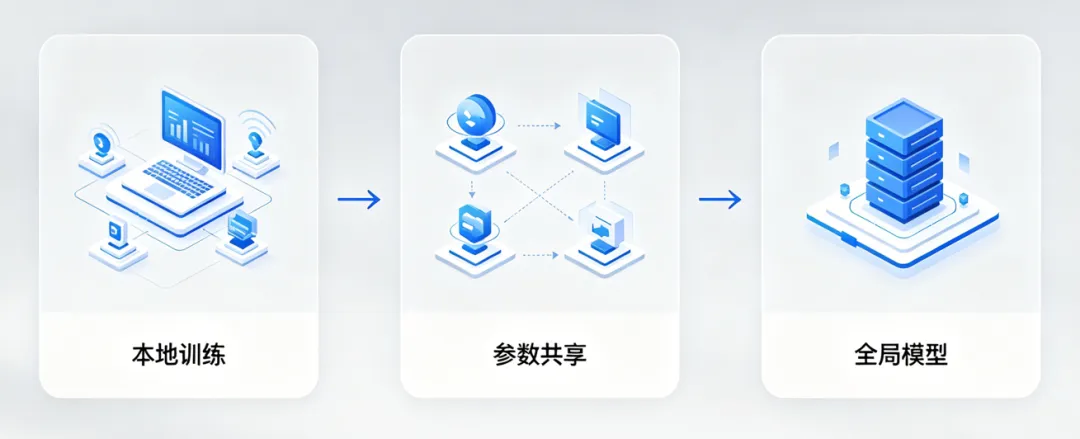
联邦学习流程示意图,“本地训练→参数共享→全局模型”
2. 手把手实操:用MONAI做肺部CT分割
步骤1:安装MONAI(医学AI开源库)
pip install monai步骤2:加载预训练模型分割肺部
from monai.networks.nets import UNetfrom monai.transforms import Compose, LoadImaged, EnsureChannelFirstdfrom monai.data import DataLoader, Datasetimport torch# 加载预训练的UNet模型model = UNet( spatial_dims=3, in_channels=1, out_channels=2, channels=(16, 32, 64), strides=(2, 2))model.load_state_dict(torch.load('unet_lung.pth'))model.eval()# 处理CT图像transforms = Compose([ LoadImaged(keys=['image']), EnsureChannelFirstd(keys=['image'])])data = [{'image': 'lung_ct.nii.gz'}]dataset = Dataset(data=data, transform=transforms)dataloader = DataLoader(dataset, batch_size=1)# 分割肺部with torch.no_grad():for batch in dataloader: outputs = model(batch['image'])# 输出分割结果(0是背景,1是肺部)print(outputs.argmax(dim=1))3. 避坑小技巧
• 数据合规问题:遵守医疗数据隐私法规(比如HIPAA),用联邦学习或差分隐私保护数据; • 临床信任不足:让医生参与模型训练,验证模型的准确性,确保符合临床需求; • 模型泛化差:用来自不同医院、不同设备的影像数据训练模型,提升泛化能力。
总结:AI入门的正确姿势——先选场景,再学算法
很多人学AI时,一开始就啃深度学习理论,结果越学越迷茫。正确的姿势是:
1. 选一个感兴趣的场景:比如你喜欢拍照,就从计算机视觉入手;你喜欢聊天机器人,就学自然语言处理; 2. 做一个小项目:比如用YOLO做实时检测,用LLaMA做客服机器人,在实操中理解算法; 3. 逐步深入理论:当你能做出项目后,再去学习算法的原理,比如Transformer的注意力机制、CNN的卷积层。
AI不是遥不可及的技术,而是解决实际问题的工具。只要选对场景,跟着实操步骤走,你也能快速入门AI,做出自己的项目。
如果你对某个领域的AI算法感兴趣,欢迎在评论区留言讨论!
