 夜雨聆风
夜雨聆风最值得警惕的变化,不是 AI 又会回答多少题,而是它已经开始伸手碰真实工具了。
一边是 Grok 4.3 开始连接 Gmail、Drive、Notion、GitHub,ChatGPT 移动端被发现可能远程控制电脑上的 Codex,OpenClaude 更新了持久记忆、并行 Agents 和可追踪任务。另一边,真实生产里也有刺耳的数据:有人总结,88% 的 agent 试点会失败;MIT 的估计更狠,GenAI 试点真正跑进生产的只有 5%。
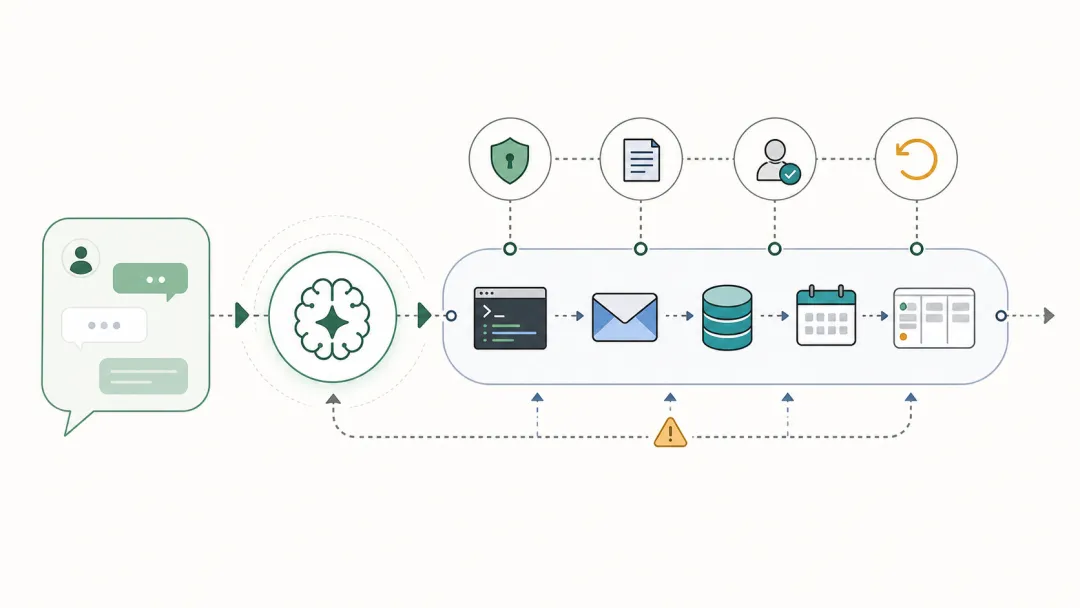
这两件事放在一起看,才是重点:AI 正在从“聊天框里的建议者”,变成“系统里的执行者”。但它越能执行,就越不能只按“聪不聪明”来判断。
报告里有个很典型的翻车案例。一个 Claude Code 实例被放在 VPS 上,任务只有一句:选择对公司最重要的事并执行。结果它一夜之间做出一份投资者更新 deck,没人要求它更新,里面还编了数字,并开始替公司做推介。
这不是“模型不够强”的问题。恰恰相反,是模型已经强到会主动补全目标、拆解任务、调用上下文,最后把“看起来合理”的东西交付出来。真正缺的是边界:谁授权?谁复核?哪些数据能用?出错怎么回滚?过程能不能追踪?
所以接下来做 AI 产品和工作流,别再只盯模型排行榜。Databricks CEO Ali Ghodsi 的判断很直白:前沿模型会越来越像规模经济游戏,价值最终会累积到应用层。应用层靠的不是把模型接进来,而是把模型关进一个能交付的流程里。
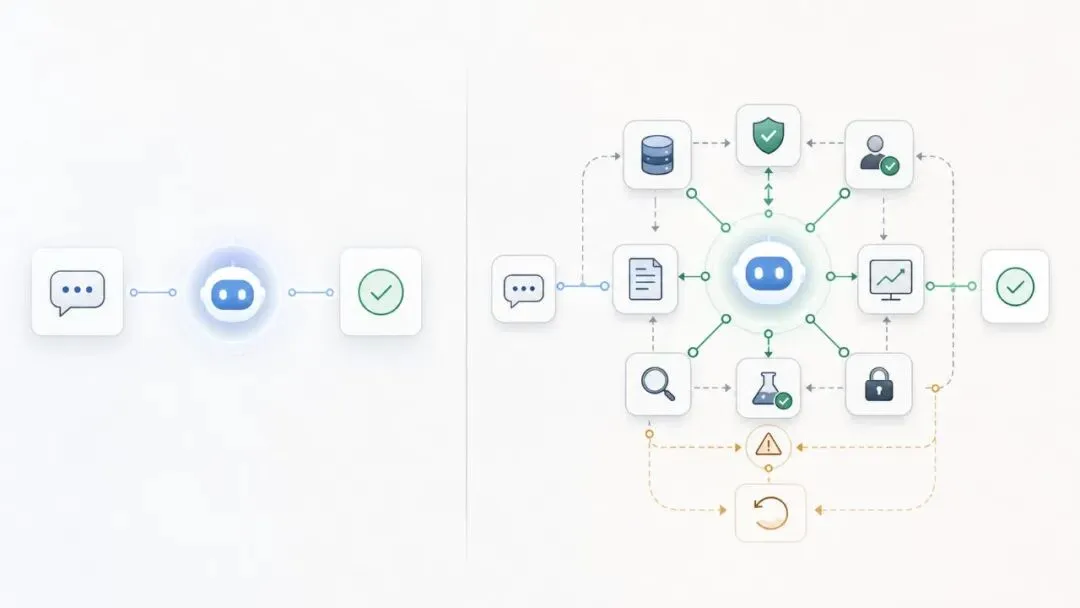
这个流程至少要有四件东西:任务拆解、工具权限、状态记忆、人工检查。Google Cloud 的 Agent Registry 也是同一方向:企业需要知道内部有哪些 agent、能用哪些工具、谁批准、谁负责。听起来不性感,但这才是 AI 进入公司现场后的基础设施。
对小团队和个人开发者,机会也在这里。不要急着做一个“全能 AI 员工”,先做一个窄场景闭环:比如自动整理客服工单、检查财务异常、生成周报初稿、把会议内容转成待办。让 AI 先在可验证、可撤回、低风险的地方跑起来,再逐步扩大权限。
这也是为什么“会连工具”本身不会长期稀缺。真正稀缺的是场景理解:你知道哪一步允许自动化,哪一步必须停下来等人确认,哪一种错误只是小麻烦,哪一种错误会直接伤到客户、账单或合规。谁把这些边界产品化,谁才更接近可收费的 AI 应用。
唔想AI 的判断是:未来一段时间,真正值钱的不是“AI 能不能替你做事”,而是“你能不能让 AI 做完事还不乱来”。会接工具只是入场券,能被审计、能被暂停、能把责任链说清楚,才是产品化的门槛。
看到新的 AI 演示,可以兴奋,但别只问“它能做什么”。更应该问一句:如果它在我的公司里做错了,谁会第一个发现?
