 夜雨聆风
夜雨聆风

上个月在深圳参加了一场腾讯云架构师同盟的闭门辩论,4个半小时,主题就一个——AI 时代,开源和闭源到底谁赢。
参与辩论的有 9 个人,大部分是后端架构师,还有几个做 AI 平台的。本来以为会是一场"开源省钱 vs 闭源省心"的老生常谈,结果聊着聊着就跑了题——从技术路线吵到组织架构,又从组织架构吵到一个叫"ZFlow"的 AI 原生编译系统。
三个话题拧在一起,反而把很多问题说清楚了。
因为这场辩论的核心矛盾根本不是"用开源还是闭源",而是一个更底层的问题:当 AI 能写代码之后,软件这件事到底变成了什么?
Part.01
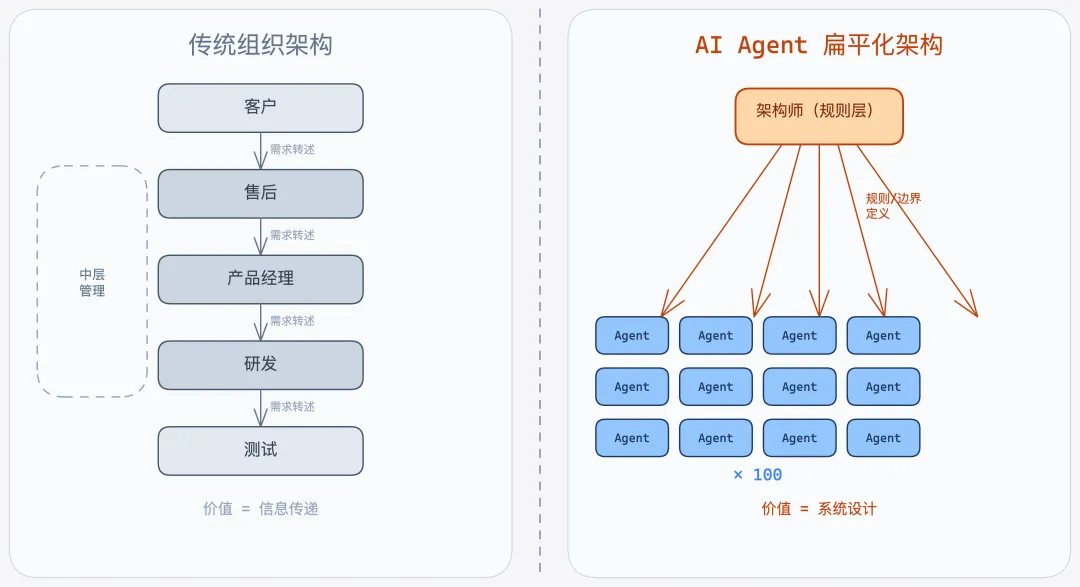
中层管理岗位,正在被Agent蒸发
Coinbase 今年裁了 14% 的人,CEO Brian Armstrong 原话是"工程师一个人配 Agent 舰队,几天能交付以前一个团队几周的东西"。公司现在 40% 的代码是 AI 生成的,目标是超过 50%。Freshworks 更夸张,裁了 11%,自称超过一半代码是 AI 写的。
这些数字单独看并不惊人——AI 辅助编码早就是常态了,Copilot 用了几年的人对这些数据不会太吃惊。但有意思的不是"AI 写了多少代码",而是写了代码之后,原有的组织架构为什么也垮了。
辩论里有人提了一个观点我觉得很准:传统组织的部门墙——售后、研发、测试各管一摊——是建立在信息传递成本之上的。需求从客户传到售后、从售后传到产品、从产品传到研发、研发写完扔给测试,每一层都要沟通、对齐、确认。这个链条上,中层管理的核心价值就是保证信息不丢、不歪、不漏。
但 AI Agent 直接把这道墙拆了。
一个 Agent 能横跨多个代码仓库理解上下文,从客户报障到定位根因到生成修复代码,全链路跑通。这时候你还需要售后把问题"转述"给研发吗?不需要。还需要研发把代码"交接"给测试吗?不需要。传递信息的角色一旦被自动化,靠传递信息吃饭的人就失去了存在的理由。
辩论中一个做了十几年架构的老哥说得特别直接:"以前中层管理的价值是'我知道该找谁',现在 Agent 比你更知道该找谁——因为它读过所有的代码和所有的文档。"
这倒不是说所有中层都会被裁掉。组织变扁平之后,真正升值的角色是两种人:能做架构判断的架构师,和能推动 AI 流程改进的"蒸馏型"人才——这种人能把复杂的业务逻辑蒸馏成 Agent 能理解、能执行的规则。
说白了,以前你管 10 个人写代码,现在你管 100 个 Agent 写代码,但前提是你得知道让它们写什么、怎么验证它们写对了。
我在辩论后的感受是:未来两年内,架构师这个岗位的供需缺口会急剧拉大。 不是每个公司都需要 20 个 CRUD 程序员了,但每个公司都需要几个人能设计出让 200 个 Agent 协作还不打架的架构。
Part.02
当 AI 能读懂 500 万行代码,Apache License 就是一张白纸
辩论进入第二个火药味最浓的环节:AI 时代,开源协议还有意义吗?
先抛一个让你后背发凉的事实:传统开源协议的控制逻辑建立在"人读代码"的前提上。 Apache 2.0 也好,GPL 也罢,它们的约束力来自一个假设——改代码的人必须阅读源码、理解逻辑、然后才能修改或分发。
但问题是,AI Agent 不需要"读代码"。
它直接把整个代码仓库塞进上下文窗口,理解、修改、重写,全程不需要一个人类去看 LICENSE 文件。更麻烦的是,Agent 改出来的代码跟原始代码之间的"血缘关系"在法律上极其模糊——它到底是"衍生作品"还是"独立创作"?如果 Agent 同时读过 20 个开源项目的代码,它输出的结果算谁的?
现场的结论相当悲观:短期内这个问题无解。 不是技术上无解,是法律框架还停留在人写代码的时代。你去法庭上说"这个 AI Agent 侵犯了我们的 Apache 协议",法官连 Agent 是什么都不知道。
这直接冲击了 Open Core 的商业模式。Open Core 的玩法大家都知道——核心开源建生态,高级功能闭源赚钱。但如果 AI 能轻易理解并复现你的"闭源高级功能"呢?你的商业壁垒在哪里?
辩论中有人引了一个数据:MIT 和 Georgia Tech 的研究发现,开源模型在发布时的性能大约是闭源模型的 90%,而且这个差距在 3 到 4 周内就能追平。一年前这个追平周期是 27 周。
当开源模型的质量以天为单位追赶闭源模型时,"闭源就是更好"这个叙事就撑不住了。
但不是所有观点都偏向开源。做企业服务的几位架构师反问得很有力:"你的客户是银行,你敢把一个开源模型直接部署到核心交易链路里吗?出了问题谁负责?社区吗?"
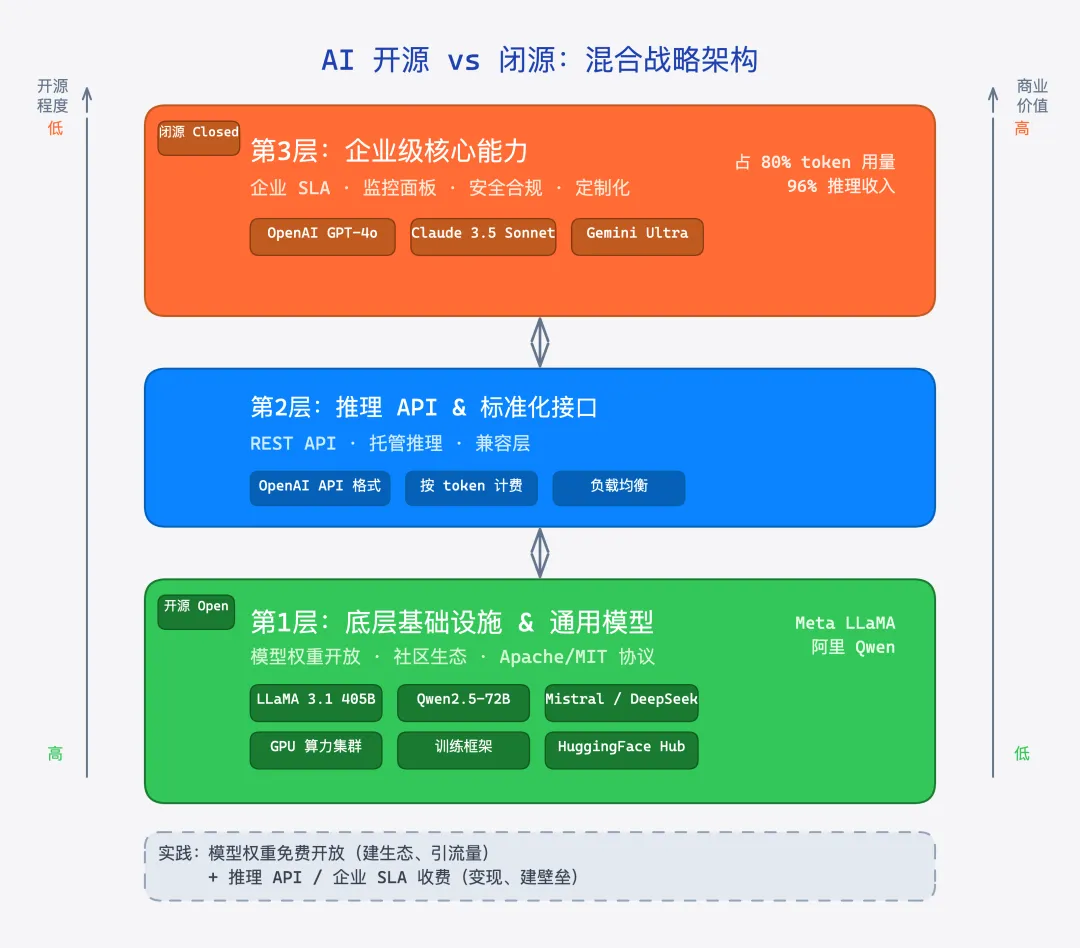
这句话把辩论拉回了现实:企业买闭源,买的不是模型,是 SLA、是责任主体、是出事了有人接电话。 这就是为什么尽管开源模型在成本上便宜 6 到 8 倍,闭源模型仍然占了 80% 的 token 使用量和 96% 的推理收入。
所以辩论的结论不是"开源必胜"或者"闭源必胜",而是一个更有趣的判断:未来最可能赢的是混合策略。 底层基础设施和通用模型开源建生态,上层核心能力和业务逻辑闭源建壁垒。大模型公司(Meta、阿里)已经在这么干了——开源模型权重免费放,但推理 API、企业级 SLA、监控面板收钱。
Part.03
ZFlow:把需求文档当源代码编译
辩论到后半段,有人拿出了一套设计——ZFlow,一个 AI 原生编译系统的概念。这是我全程觉得最有野心、也最容易被误解的部分。
先说 ZFlow 想解决什么问题。
我们现在用 AI 写代码的方式本质上还是"自然语言 → 代码"。你给一个 prompt,AI 给你一段代码。这种方式写个小功能还行,但写一个完整的微服务系统?你会发现 prompt 越长,AI 的输出越不可控——架构一致性、接口契约、边界条件,这些在自然语言里是无法精确描述的。
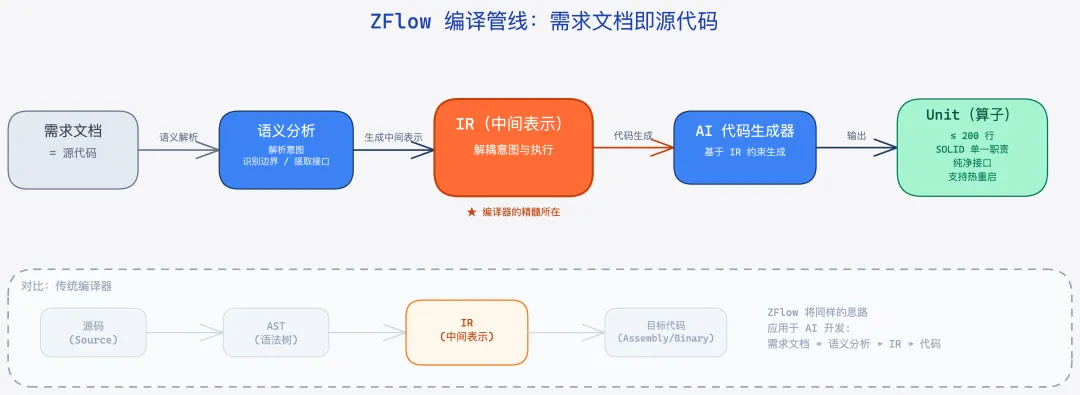
ZFlow 的思路是借鉴编译器:把需求文档当成源代码,做语义分析生成中间表示(IR),再从 IR 编译成可执行的算子(Unit)。
这里的精髓在于 IR 这一层。编译器之所以可靠,是因为 IR 是一个严格定义的中间语言,它把"人想做的事"和"机器要执行的指令"解耦了。ZFlow 想做的事类似——在"自然语言需求"和"AI 生成的代码"之间插入一个 IR 层,用这个 IR 来管理复杂度。
具体的约束规则也很有意思:
每个 Unit 不超过 200 行代码
强制遵循 SOLID 原则,尤其是单一职责
输入输出接口必须纯净,便于单元测试和 AI 生成
通过 Blueprint 和哈希机制支持热重启和状态迁移
01
为什么是200行?
辩论中解释的原因是:这个数字是从实践中试出来的。代码量超过 200 行,AI 的生成质量开始断崖式下降——逻辑分支太多、边界条件遗漏、单元测试覆盖不全。200 行以内的单一职责单元,AI 可以一次生成、一次测试、一次通过。
说实话,这个设计思路跟我之前在一些大型系统里做的"微服务拆分"本质上是同一件事——把复杂度关进小盒子里,让每个盒子足够简单,出错也能定位。区别在于,以前这个拆分是靠架构师的经验和人手去做的,现在 ZFlow 想靠 IR 编译器自动化。
不过辩论中也有人提出质疑:这个模式要求需求文档写得足够精确,而现实中大部分需求文档本身就是一个灾难。如果IR的质量取决于需求文档的质量,那 ZFlow 真正的瓶颈不是编译器,是需求工程。
这个质疑我完全同意。但从另一个角度想——如果 AI 能帮你写代码了,那有人会想"能不能让 AI 帮你写需求文档"?这就变成了一个递归问题:AI 写需求 → 编译器生成 IR → 编译器生成代码。整个链路上,人的角色从"写代码"退到"确认需求",再退到"定义问题"。软件工程的终极形态,可能不是人指挥机器写代码,而是人告诉机器"我要什么",机器自己弄清楚"怎么做"。
这在今天听起来有点科幻,但回想一下,5 年前我们说"AI 能写代码"不也是科幻吗?
Part.04
个性化需求大爆发,SaaS 的估值逻辑要重写
辩论最后绕回来的一个问题,其实比开源闭源之争更根本:当软件开发成本降到几乎为零,会发生什么?
软件行业过去二十年的商业逻辑是"标准化才能规模化"。SaaS 尤其典型——你只能买标准化产品,个性化需求要么额外付费定制,要么忍着。这个逻辑成立的前提是"定制很贵"。
但如果 AI Agent 能在几小时内完成一个定制功能,而且质量不差呢?
以前一个客户说"我想要这个报表加一列自定义字段",SaaS 公司的标准回答是"在我们的 roadmap 里,预计 Q3 上线"。以后的回答可能是"好的,下午发给你"。
当定制成本趋近于零,标准化产品的溢价空间就会被压缩。那些靠"一个产品卖给所有人"的 SaaS 公司,估值模型里"边际成本趋零"这个假设是要重算的——因为竞争对手可以快速定制出一个更贴合客户需求的东西,而客户的忠诚度从来都是建立在"这东西刚好满足我"之上的。
这也是辩论中为什么有人喊出"传统 SaaS 估值逻辑要崩"的原因。
但换个角度看,这也意味着一个巨大的机会:以前被标准化产品忽略的个性化需求,现在有被满足的可能了。 软件市场总体规模不是变小了,是变大了,只是钱不再集中在少数标准化产品手里。
Part.05
我的判断
这三件事——组织架构被 Agent 重构、开源协议在 AI 时代失效、ZFlow 这种编译系统试图重新定义"写代码"——表面上是三个独立话题,但底层是一根线:
软件工程的中心正在从"人"转移到"规则"。
以前软件工程的核心问题是"怎么让人高效地协作写代码"。敏捷、DevOps、微服务、中台,本质上都是在回答这个问题。但 AI 时代,分工和协作的模式被彻底打乱了——Agent 不需要站会,不需要 code review(或者说 Agent 之间的自动 review 比人认真多了),不需要"对齐认知"。
新的核心问题变成了:你怎么定义规则,让 Agent 在规则的边界里高效、安全地工作?
这解释了为什么 ZFlow 要从编译器借设计理念、为什么组织会变得更扁平、为什么开源协议的旧框架在 AI 面前不堪一击。因为"规则"才是 AI 时代真正的护城河——不是你的代码,不是你的模型,是你设计和约束系统的能力。
说到底,架构师在这个时代的价值变大了,还是变小了?
我的答案:做执行层的事情,价值急剧缩小;做规则层的事情,价值急剧放大。 你能设计出让 100 个 Agent 不互相踩脚的架构,你的价值就比以前管 100 个人还大。你只会按 PRD 写代码,那确实危险了。
这个变化已经来了。Coinbase 和 Freshworks 的裁员不是个例,是信号。
Part.06
常见问题
01
Q: "禁止手写代码"是认真的,还是夸张说法?
A: 辩论中提到的是某种极端实践,在特定团队里确实试过——强制用 CodeX 生成所有代码,人只做 review。效果据说不错,但前提是团队有非常完备的 CI/CD 和自动化测试。如果你连单元测试都没写好,千万别学。
02
Q: 开源模型真的能在 3-4 周内追平闭源?是不是太乐观了?
A: MIT 的数据是这样说的,但要注意——这个"追平"是指特定 benchmark 上的性能,不是所有维度。闭源模型在复杂推理和 Agent 工作流上的稳定性目前还是领先的。所以实际选型还是要看具体场景。
03
Q: ZFlow 这个概念目前有开源实现吗?
A: 目前没有公开的实现。辩论中提到的 ZFlow 还处于概念设计和内部验证阶段。但类似的思路(把 DSL 或 IR 作为 AI 编程的中间层)在一些团队里已经在试了。
04
Q: 中小企业现在应该选开源还是闭源大模型?
A: 给你一个直接的建议:内部工具和原型验证用开源(便宜、迭代快),核心业务链路用闭源或者托管开源(有人兜底)。别在省钱这件事上赌核心业务。
05
Q: 架构师需要学什么来应对这种变化?
A: 不是学某一个工具,是建立"系统约束设计"的能力——怎么把复杂需求拆成能独立验证的小单元、怎么设计 Agent 之间的协作协议、怎么在 AI 生成代码的基础上建立质量门禁。这些能力目前没有任何一门课能教,全靠实战。
这场辩论最让我触动的一个瞬间,是有个架构师说:"我们过去十年积累的架构经验,不是没用了,而是突然从'锦上添花'变成了'生死攸关'。"
以前架构好是加分项,架构烂也能跑。但在 Agent 大量参与编码的时代,架构烂的后果是 100 个 Agent 同时写出 100 种不同的烂代码,而且速度快到你来不及修。

