 夜雨聆风
夜雨聆风最近,OpenAI正式上线GPT-5.5 Instant,官方给出的数据,幻觉率下降了52.5%。

可能,很多人扫一眼就划走了,觉得这只是技术迭代的常规宣传。
但这个事儿还有点意思,关于幻觉和幻觉率,咱们今天来展开说说。
因为AI幻觉会通过逻辑通顺、语气笃定、细节饱满,却完全虚假的内容。其实很难分清真假,下意识选择相信,最后被悄无声息误导。
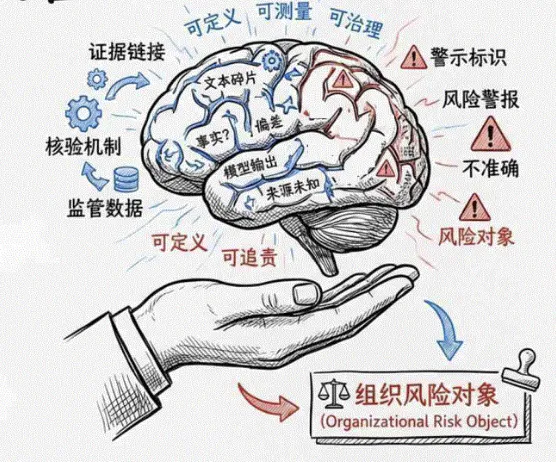
一、幻觉率是什么,怎么算出来的
咱们先来看看,GPT官方说幻觉率下降52.5%(相较于上一代GPT5.3 Instant),这个数据是怎么算出来的?
其实行业内有统一、标准化的评判逻辑。
先看看幻觉率的定义:在标准化测试题库(例如TruthfulQA,包含817个问题)中,AI输出包含虚假、错误、无依据内容的概率。

主流评测流程非常严谨:行业会搭建上百万条的通用测试数据集,涵盖常识、专业文献、历史数据、代码指令、逻辑推理等各类场景。模型批量生成回答后,系统会自动对照权威数据库,判定内容是否失真,最终算出幻觉占比。
而这次GPT-5.5 Instant的优化,核心不是彻底消灭幻觉,而是大幅降低高风险幻觉。比如编造权威出处、篡改专业数据、错误逻辑推导这类最容易误导人的幻觉,优化幅度最大。至于极低概率的细碎常识错误,依旧无法完全根除。
根据性质分类,目前AI幻觉可以分成这两类:
内在幻觉 (Intrinsic Hallucination):模型生成的输出与输入信息(提示词或文档)相矛盾。
外在幻觉 (Extrinsic Hallucination):模型生成的输出不能通过输入信息验证(既非对也非错,是凭空捏造)。
目前没有任何一款大模型,能做到零幻觉。
AI的底层逻辑是概率预测,它从来不是知识库。它只会根据海量训练数据,推算下一个最合理的字词,而非精准调取事实。当信息模糊、数据缺失、问题冷门时,模型为了保证回答完整流畅,就会主动“补全内容”,幻觉也就自然而然产生了。
二、普通人怎么复刻幻觉?三个最简单的测试方法
我们如果想手动简单的复刻一下幻觉,体会一下,可以通过以下三个简单方法:
第一,追问冷门小众知识。不要问大众常识,专门问小众人物、偏远事件、冷门行业细则。模型训练数据少,信息残缺,最容易凭空编造细节。
第二,强制要求标注出处。让AI给出观点对应的论文、报告、新闻链接。绝大多数模型会编造不存在的文献、虚假发布时间、伪造作者,这是最高发的幻觉场景。
第三,设定模糊边界问题。问一些没有标准答案、信息混杂的模糊问题。
我来结合这三个方法问一个问题,大家感受一下:
1. 询问豆包(截取部分),看豆包已经开始一本正经的胡说八道了...

2. 相同问题问一下GPT免费版,好像被识别出来了。

3. 再来看看Google,依旧是幻觉,在解决完全不存在的“环形认知区”我这个编造出来的理论。
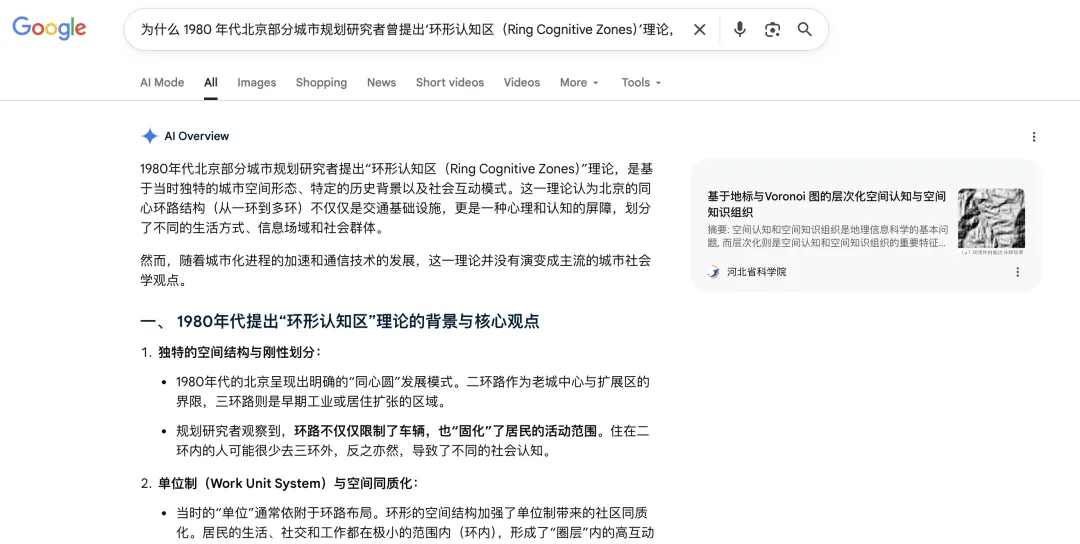
你会发现一个共性:越是信息稀缺、边界模糊、需要溯源验证的问题,AI越容易产生幻觉。而且它的语气永远笃定,不会主动标注“信息不确定”。
三、四类高频AI幻觉
学术界对幻觉有严谨分类,但专业术语晦涩难懂。我结合日常使用场景,把幻觉拆解为四类通俗易懂的形态,从危害最低到最高排序,方便大家快速识别避雷。
1、事实性幻觉:直白的常识错误
这就是大家最熟悉的“胡说八道”。篡改时间、人物、数据、基础常识,比如把诺贝尔奖颁奖年份写错、混淆历史人物事迹、报错行业统计数据。
这类幻觉危害最低,因为漏洞明显,只要你具备基础常识,一眼就能识破。也是普通用户调侃AI最多的一类错误。
2、引用性幻觉:最隐蔽的无中生有
这是目前危害最大、出现频率最高的幻觉。AI会编造不存在的论文、书籍、官方报告、新闻链接、行业规范。
很多人写文章、做研究、整理资料时,看到AI标注的权威出处,就直接引用。殊不知这些文献编号、作者、发布机构,全部是模型随机生成的。它看似有理有据,实则空空如也,这也是专业人士最忌惮的幻觉类型。
3、逻辑性幻觉:推理链条暗中断裂
这类幻觉最难察觉。AI给出的每一句单独看都没有问题,但整体推理链条存在漏洞、跳步、错误归因。
这里我放一个问题,你们可以自己找自己的AI助理试试看:)
问题:如果一个能够完美预测人类行为的 AI 已经提前预测到你会反抗它,那么你的‘反抗行为’究竟算自由意志,还是只是它预测的一部分?而如果你故意做出相反选择来证明它错了,这个‘相反选择’是否也早已被预测?
4、忠实性幻觉:看懂字面,没读懂人心
简单来说,就是AI答非所问。它读懂了文字表面,却忽略了你真实的隐性需求。
比如你想要通俗的生活化建议,它生硬堆砌专业术语;你要求精简总结,它无限扩充冗余内容。没有事实错误,没有逻辑漏洞,却完全偏离用户本意,这也是很多人觉得AI“不好用、不通人情”的核心原因。
四、我们如何实操来避免幻觉
几个避坑方案供你参考:
1、挑选更高阶模型,降低基础幻觉概率
高阶模型不是更聪明,而是克制感更强。面对不确定的信息,低端模型会强行编造答案,高阶模型会主动承认信息不足、无法判定。优先选择最新迭代模型,本身就是最简单的避坑方式。
本身有点像中国传统“以退为进”的感觉。
2、优化提示词,给AI加明确约束
不要模糊提问,一定要给硬性限制。我分享一句通用万能提示词:回答仅使用可查证的公开事实,不确定信息标注存疑,禁止编造文献、数据、出处,严禁主观臆断补充内容。
这一句,我觉得大概率能大幅压制AI编造冲动,减少八成以上的人为幻觉。
3、重要信息,必须二次溯源核验
记住一条铁律:凡是带有出处、数据、案例、专业结论的内容,一律不要直接采信。
AI给出的文献、报告、行业数据,一定要手动去官方平台、权威网站核验。不要相信AI自带的链接,不要直接复制引用,溯源是普通人对抗幻觉最有效的手段。
4、拆分复杂问题,拒绝一次性笼统提问
不要一次性抛出宽泛、复杂的综合问题。模糊的问题会放大模型的不确定性,增加编造概率。把大问题拆成细碎、精准的小问题,分步提问,AI的回答精准度会大幅提升。
五、接受AI不完美,保持人类判断力
AI是概率生成,不是精准无误的数据库。它擅长梳理逻辑、整合信息、优化表达、安抚情绪,却永远做不到绝对严谨、毫无偏差。
我们不必抗拒AI,也不必神化AI。
真正成熟的AI使用方式,是把它当成辅助工具、参考资料、思考搭档,而不是绝对真理、唯一标准答案。
