 夜雨聆风
夜雨聆风上个月在CCF秀湖会议“超大规模智算集群网络的挑战与机遇”专题中,阿里云副总裁蔡德忠的报告中提到一个新型网络架构概念:Token Performance Network。这个名字很有意思:一个数据中心网络架构,竟然开始用Token这个大模型业务词来命名。
这背后也说明一个问题:过去网络团队更关心带宽、时延、丢包;而在大模型推理时代,业务真正关心的是Token间延迟、有效Token吞吐和单位Token成本。
以阿里云为例,我们其实可以看到一条很清晰的演进路线:数据中心网络正在从通用云网络,走向面向AI训练、AI推理和Token生产的AI原生网络。
01
从通用云网络到AI训练网络
在传统云计算时代,数据中心网络面对的流量通常是多租户、多业务混合的。Web访问、数据库请求、存储读写、微服务调用共同构成了整体流量。由图1可以看出,流量输入、流量输出和连接数会随着时间变化,它们的变化往往和业务高峰有关,比如白天访问量增加、夜间流量下降,但整体呈现出比较连续、平滑的波动。
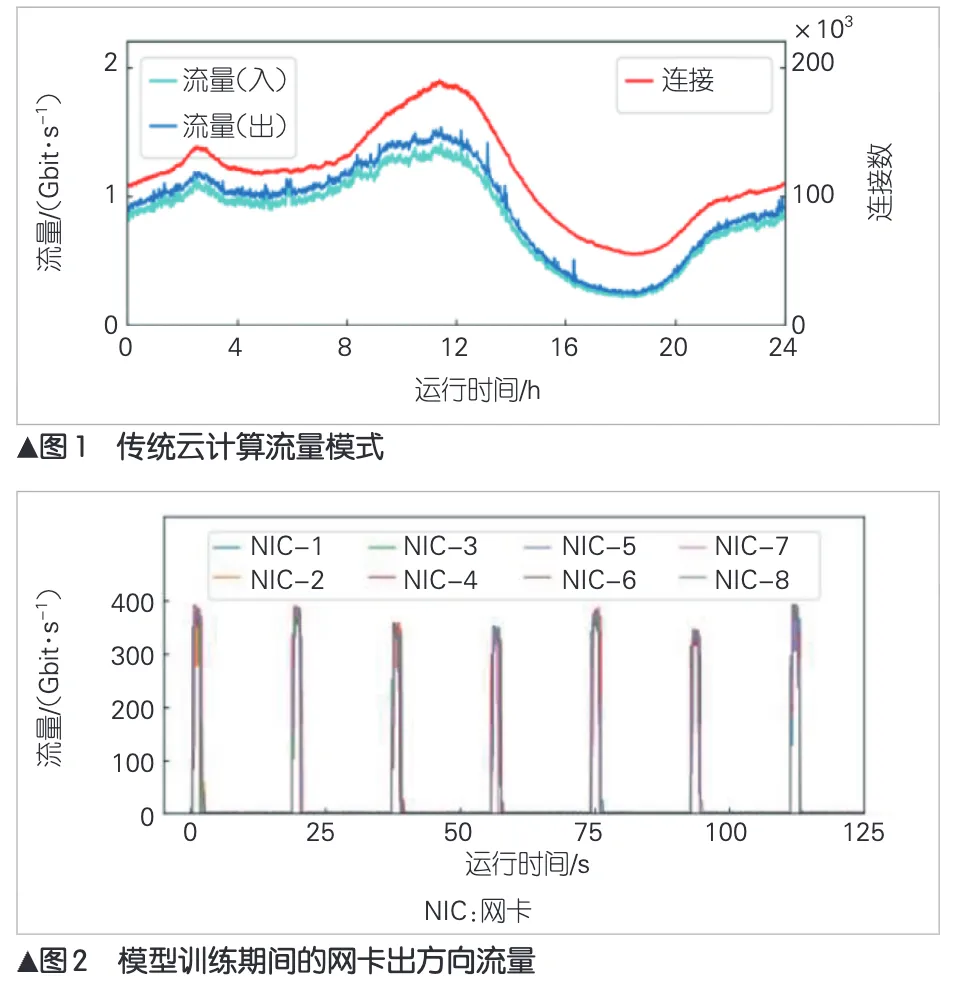
而图2中可以看到,多个网卡的出方向流量大部分时间接近空闲,但在固定时间点会突然冲到很高的峰值。
这也是大模型训练的典型特征:计算阶段网络相对安静,一旦进入通信阶段,所有GPU几乎同时开始交换数据,形成周期性的突发流量。
这意味着,AI时代网络架构的设计重点已经发生变化。过去,网络更多是为了支撑通用业务流量的长期稳定承载;而现在,网络越来越需要适配大模型训练中的突发通信、同步等待和尾延迟敏感性。
02
HPN:当大模型训练走向万卡集群
正是在这种流量模式变化的背景下,AI时代的数据中心网络开始出现新的架构方向。对于训练场景来说,首先需要解决的是Scale-out:当模型训练从单机多卡走向多机多卡,甚至万卡集群时,网络如何支撑更大规模的GPU协同。
针对这个需求,阿里云提出HPN(High Performance Network)。它是一种面向大语言模型训练场景重新设计的数据中心网络架构,主要体现出如下几个特点:
1、HPN面向大规模GPU集群扩展,能够在一个Pod内支持约15K GPU。
2、HPN强调尽量减少网络跳数,并尽可能让GPU-to-GPU通信少绕路。
3、HPN采用dual-plane双平面设计。当一个平面出现拥塞或故障时,另一个平面还能继续工作,流量也更容易被分散到不同路径上。
4、HPN采用dual-ToR设计。即使其中一个ToR出现问题,服务器仍然能通过另一个ToR接入网络,从而降低单点故障对大规模训练任务的影响。
因此,HPN体现了Scale-out网络的一种典型思路:网络不再只是把更多服务器连接起来,而是要围绕大模型训练的通信节奏、同步等待和故障敏感性,重新组织大规模GPU集群。
03
UPN:从连接服务器到连接更多xPU
随着大模型应用不断演进,AI负载也在发生变化。
MoE模型让不同Token被路由到不同专家,长上下文推理让系统需要管理更大的KV Cache,多模态模型需要在文本、图像、视频等不同信息之间进行融合,Agent应用则可能带来更长链路、更高并发、更复杂的推理请求。这些变化带来一个共同结果:AI计算中的通信越来越频繁,也越来越深入模型内部。
这就引出了Scale-up:如何把更多xPU连接成一个更大的超节点。
针对这个目的,阿里云提出的UPN(Ultra Performance Network)就是Scale-up方向的一个代表。它是一种面向xPU超节点互联的高性能网络架构。和HPN主要关注多服务器、多机柜之间的训练集群不同,UPN更关注的是在一个超节点内部,如何把更多xPU以更高带宽、更低时延连接起来。
04
TPN:推理时代的网络构想
大模型推理时代,一个很重要的变化是:Token不只是模型生成文本的基本单位,也正在成为AI服务的计量单位和商业单位。
阿里云提出TPN所代表的趋势,是网络从底层传输能力进一步走向业务感知能力。未来评价AI数据中心网络,可能不再只看带宽、时延和丢包率,而会更加关注它对Token生产的直接影响。具体来说,Token吞吐决定系统单位时间内能够产出多少有效结果,Token延迟决定用户能否获得流畅的交互体验,单位Token成本则决定推理服务能否长期规模化运行。也就是说,网络架构的价值正在从“数据传输能力”转向“Token生产能力”:好的AI网络,不只是链路更快,而是能够让模型以更高吞吐、更低延迟和更低成本持续产出Token。
目前TPN仍然更像是一种新兴的架构构想,公开技术细节还没有完全展开。但它传递出的信号已经很明确:当大模型推理成为AI基础设施的核心负载后,数据中心网络的设计目标正在从“连接算力”进一步走向“服务Token生产”。
05
总结
本文以阿里云HPN、UPN和TPN为线索,可以看到这条演进路径非常清晰:HPN代表Scale-out,关注万卡集群如何高效互联;UPN代表Scale-up,关注超节点内部大量xPU如何高速协同;TPN则代表推理时代的新思路,关注网络如何服务Token吞吐、Token延迟和单位Token成本。
过去的数据中心网络连接的是服务器;今天的AI网络组织的是算力;未来的网络,可能会进一步围绕Token生产效率来设计。谁能让模型以更高吞吐、更低延迟和更低成本持续产出Token,谁就能在AI基础设施竞争中占据更有利的位置。
作者丨李晨曦
NIRC2025级研究生
