 夜雨聆风
夜雨聆风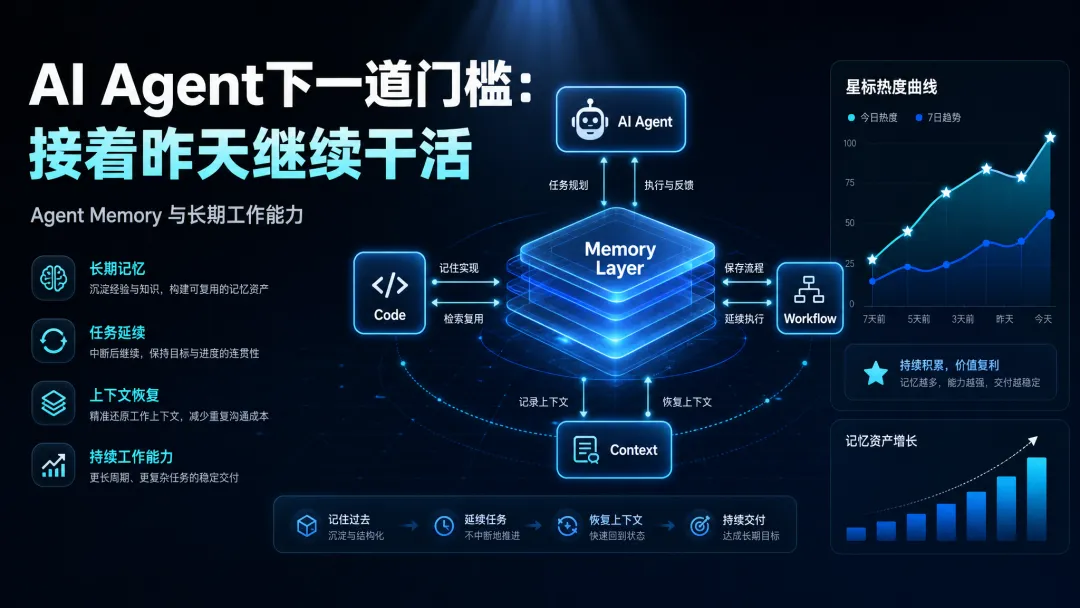
导读:这两天 GitHub 上 agentmemory 这类项目突然热起来。我的判断不是“Agent 终于开始需要记忆了”,而是:这个问题在 Agent 圈早就热了,只是热度正在从少数深度使用者,传导到更大的开发者人群。AI Agent 的下一道门槛,不是更会聊天,而是能不能接着昨天继续干活。
GitHub 热了,但问题不是今天才出现
最近 GitHub 上一个叫 `rohitg00/agentmemory` 的项目很火。
它的定位很直接:
Persistent memory for AI coding agents.
也就是给 Claude Code、Cursor、Gemini CLI、Codex CLI、OpenClaw 等 coding agent 提供持久化记忆能力。
我看了一下项目数据:它已经有 6800+ stars、600+ forks,README 里也写了不少很抓眼球的指标,比如:
- 95.2% retrieval R@5;
- 92% fewer tokens;
- 51 MCP tools;
- 12 auto hooks;
- 0 external DBs;
- 827 tests passing。
这些数字要保持一点谨慎。benchmark 是项目方自己呈现的,不能直接当成行业共识。
但项目为什么火,不难理解。
因为它打中的不是一个小功能,而是 Agent 工作流里越来越明显的痛点:
一个 Agent 如果每次开工都要重新解释背景,它就不是长期助手,只是一个会说话的临时工。
不过我更想说的是:
Agent Memory 不是今天才重要。只是以前热在更小的圈层里,现在通过 GitHub 传导出来了。
热度是有传导路径的
很多技术趋势不是突然爆发的,而是逐层传导的。
第一层,是重度使用者先痛。
真正天天用 coding agent、自动化助手、长期项目助手的人,早就会遇到这个问题:
- 昨天刚定的规则,今天又丢了;
- 上周刚踩过的坑,换个会话又重来;
- 项目背景反复解释;
- 用户偏好无法稳定继承;
- 工作流刚跑顺,换一次上下文又断掉。
第二层,是工具作者开始补基础设施。
于是你会看到 MCP、hooks、skills、memory store、knowledge graph、hybrid search 这些东西越来越多。
它们表面上是不同组件,底层都在回答同一个问题:
Agent 怎么把一次任务里的经验,变成下一次任务里的能力?
第三层,才是 GitHub、Hacker News、X、Product Hunt 这些公共热度场。
也就是说,今天 agentmemory 在 GitHub 上火,并不代表 Agent Memory 今天才成立。
更准确的说法是:
这件事已经从“少数深度用户的工程痛点”,进入了“更多开发者都能理解的公共议题”。
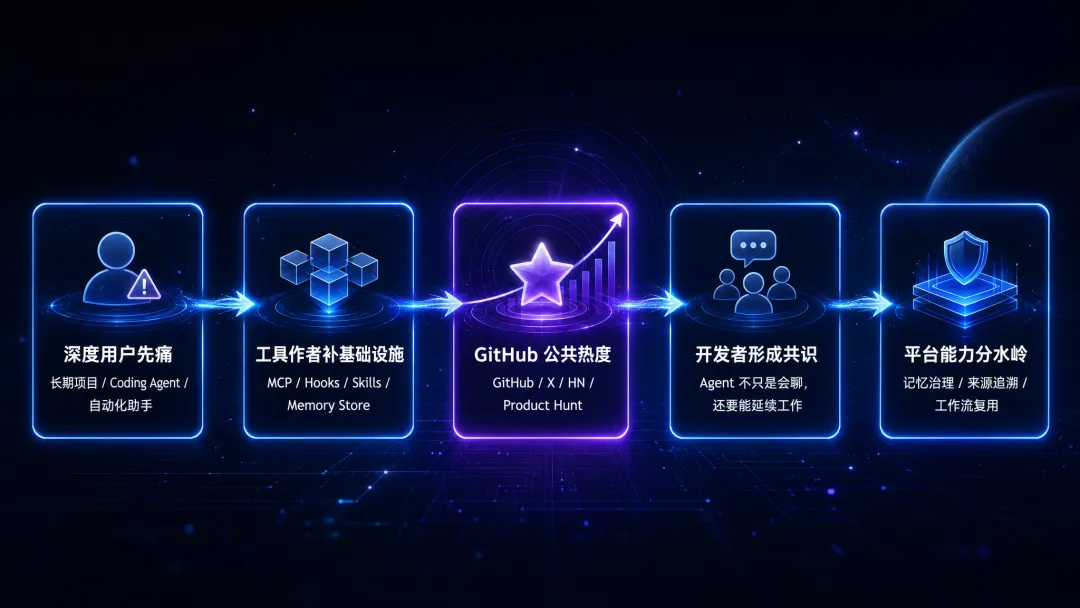
这个传导本身,比单个项目更值得看。
我之前写 Memory,不是为了讲一个功能
前面提到,我之前写过一篇 OpenClaw 记忆系统的文章。
那篇文章的核心不是“我给 AI 加了记忆”,而是恰好相反:
别再让 AI 乱记忆了。
当时我做的是一件比较底层的事:把 OpenClaw 的记忆系统从“重常驻、大仓库、混层堆积”,改成“轻常驻、检索优先、分层归位”。
翻成人话就是:
- 长期硬规则,常驻;
- 稳定 workflow,形成 topic;
- 排障过程和历史证据,沉到 raw;
- 当天发生的事,记进 daily;
- 真要回忆时,再按需取。
为什么要这样做?
因为一个成熟的 AI 助手,不应该靠把所有东西都背在身上来显得自己记性好。
它更应该像一个靠谱的人:
- 重要规则一直记得;
- 历史资料知道去哪找;
- 不确定时会回查证据;
- 过时信息不会一直污染判断;
- 敏感边界不会随便突破。
所以我对 Agent Memory 的理解,从一开始就不是“给模型加一个记忆外挂”。
而是:
给长期工作关系补一套上下文治理系统。
为什么 coding agent 最先把这个问题放大
聊天机器人也需要记忆,但 coding agent 会更快暴露问题。
因为写代码不是一次问答。
一个真实项目里,Agent 要知道很多长期信息:
- repo 的目录结构;
- 哪些命令能跑;
- 哪些测试之前失败过;
- 哪些配置不能随便动;
- 用户偏好哪种实现方式;
- 哪些 workaround 是临时的;
- 哪些规则已经固化;
- 哪些操作必须先确认。
这些信息如果每次都塞进 prompt,成本高,也不稳定。
如果完全不记,Agent 就会反复犯同样的错。
所以 coding agent 对 memory 的需求会比普通聊天场景更尖锐。
它不是为了“更懂你”,而是为了能继续干活。
这里有个很重要的区别:
聊天记忆偏关系,工作记忆偏执行。
聊天记忆可能是“你喜欢什么口味”“你家猫叫什么”。
工作记忆更像是:
- 这个项目怎么构建;
- 这个客户不能这样回复;
- 这个文件夹不能放临时产物;
- 这个流程跑通后要回填状态;
- 这个接口之前因为权限失败过。
后者才是 Agent 真正从玩具走向生产力时必须补上的东西。
但 Memory 不是越多越好
现在很多人一讲 Agent Memory,容易走向一个误区:
只要记得更多,Agent 就会更好用。
我不认同。
记忆系统最危险的地方,恰恰是它看起来都很有用。
什么都记,最后会变成三种问题:
第一,上下文污染。
旧规则、临时判断、错误结论混在一起,Agent 会把过时信息当成新事实。
第二,召回错配。
明明当前任务需要 A 规则,却召回了 B 场景下的历史经验。
第三,信任风险。
用户以为它记得对,但它其实只是记得多。
所以我更关心的不是“有没有 memory”,而是 memory 有没有治理。
至少要回答六个问题:
1. 什么信息可以自动记?
2. 什么信息必须用户确认后再记?
3. 长期规则和短期上下文怎么分层?
4. 原始证据和提炼结论怎么分开?
5. 过期记忆怎么降权或删除?
6. 召回时能不能说明来源?
如果这些问题没有答案,记忆系统可能不是增强,而是负担。
AI 没记忆,是临时工。
AI 乱记忆,是添乱的老员工。
真正好的 Agent Memory,不是“无限记住”,而是“有秩序地记住”。

这波 GitHub 热度真正说明了什么
我觉得 agentmemory 这波热度,至少说明三件事。
第一,Agent 的竞争正在从模型能力,转向工作系统能力。
模型强不强当然重要,但长期使用时,光有模型不够。
你还需要:
- memory;
- tools;
- permissions;
- workflow;
- evaluation;
- audit trail;
- human confirmation。
这些东西合起来,才是一个 Agent 真正能不能长期工作的底座。
第二,开发者开始把“上下文”当成资产,而不是一次性输入。
以前 prompt 用完就丢。
现在越来越多人意识到:每次任务里的决策、偏好、失败原因、验证结果,都应该沉淀下来。
不是为了存档,而是为了下次少走弯路。
第三,memory 会成为 Agent 平台之间的分水岭。
未来你判断一个 Agent 系统好不好,不能只问:
- 它接了多少模型?
- 它有多少工具?
- 它回答快不快?
还要问:
- 它怎么记住长期规则?
- 它怎么处理错误记忆?
- 它怎么证明自己这次用了哪段历史?
- 它能不能把经验沉淀成可复用工作流?
这些问题,才是长期助手的门槛。
结论:这不是追热点,是验证一个方向
所以这次看到 agentmemory 在 GitHub 上火,我不觉得它只是一个值得收藏的开源项目。
它更像一个信号:
Agent Memory 这件事,已经从深度使用者的局部痛点,传导成开发者社区的显性需求。
但我的建议仍然不是马上追项目。
更好的做法是:
1. 先判断自己到底缺哪种 memory;
2. 再拆它的结构:写入、召回、分层、过期、权限、评估;
3. 然后对照自己的工作流,补最短的一段链路;
4. 最后把验证过的东西沉淀成规则、skill 或知识卡片。
一句话总结:
AI 助手的下一阶段,不是更会聊天,而是更会接着昨天继续干活。
而能不能做到这一点,靠的不是一句“我记住了”。

靠的是一套真正可治理、可追溯、可复用的记忆系统。
这也是我为什么认为,Agent Memory 不是一个短期热点。
它会成为长期 Agent 的基础设施之一。
