 夜雨聆风
夜雨聆风
AI 缺陷检测很容易让人产生一种期待:
实际项目里,模型当然重要。
但上线后的误判,很多时候不是模型单点问题,而是数据、成像、标注、工艺波动和判定规则一起造成的。
▶ 一、训练集好看,不代表现场好用
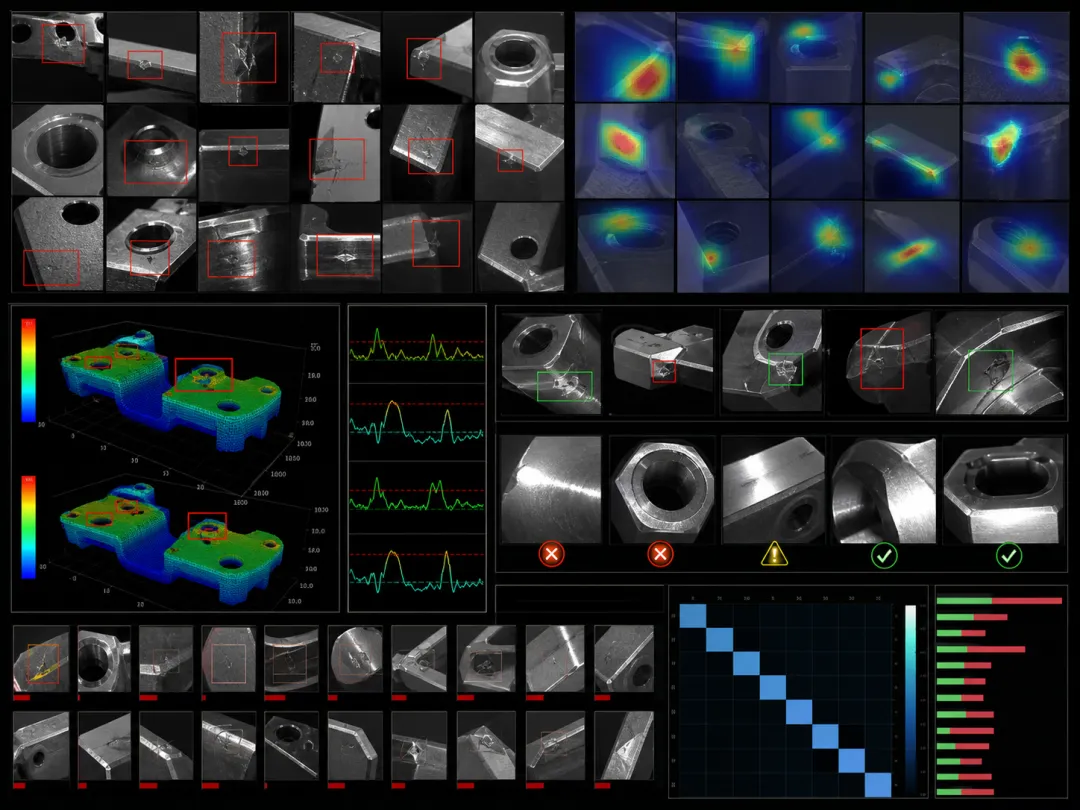
很多 AI 项目打样时效果很好。
原因是样本干净、缺陷典型、背景稳定。
到了量产现场,问题开始变复杂:
表面油污和灰尘增加
光源衰减
产品位置偏移
新缺陷类型出现
良品纹理变化
如果训练集没有覆盖这些变化,模型就会把没见过的正常变化当缺陷,或者把新缺陷当背景。
所以 AI 项目不是一次训练完就结束。
它需要持续收集现场样本。
▶ 二、标注标准不一致,会直接喂坏模型
AI 模型学的是标注里的规则。
如果标注本身不稳定,模型也会不稳定。
常见问题包括:
缺陷边界框大小忽大忽小
脏污和真实缺陷混在一起
轻微外观差异没有等级标准
客户和现场对缺陷定义不一致
这类问题不是调参数能彻底解决的。
上线前应该先把缺陷等级、标注边界、忽略区域和争议样本规则定清楚。
▶ 三、AI 也需要稳定成像
有些人以为 AI 能自动适应各种图像变化。
这很危险。
如果光源、曝光、焦距、位置一直变,模型输入就一直变。
输入不稳,输出自然不稳。
AI 缺陷检测同样要控制:
增益
光源角度
产品姿态
相机焦距
背景干扰
模型不是用来替代成像设计的。
它是建立在稳定成像基础上的判定工具。
▶ 四、误判样本要闭环,而不是只说“模型不准”
上线后最有价值的是误判样本。
每一次误判都应该被归类:
新缺陷类型
标注规则争议
模型漏学
阈值设置问题
工艺波动
机构或触发异常
如果只把所有问题都丢给模型,后期会越改越乱。
更好的做法是建立样本闭环:
记录模型版本
记录参数版本
定期复盘误判类型
补充训练集
小批量验证后再上线
▶ 五、写在最后
AI 缺陷检测不是魔法。
它需要稳定成像、清晰标准、持续样本和版本管理。
项目评审时,不要只问:
还要问:
能回答这个问题,AI 才有量产价值。
