 夜雨聆风
夜雨聆风
📌 图注:OpenAI 5 月 7 日发布 GPT-Realtime-2 等三款语音模型,官博发布视频封面 | 来源:OpenAI 官方博客 · 2026 年 5 月
5 月 7 日,OpenAI 一次发了三个语音模型:GPT-Realtime-2、GPT-Realtime-Translate、GPT-Realtime-Whisper。Realtime API 同步从 Beta 走进 GA,明天就能上生产。
科技媒体的标题清一色都在喊一个名字——萨曼莎。
不熟悉的解释一下:萨曼莎是 2013 年那部电影《Her》里的女主角,一个 AI 操作系统,能听懂男主角的每一句话,能思考、能撒娇、能和他谈恋爱。过去十几年,"萨曼莎"已经变成科技圈一个心照不宣的代号——它代表的不是某个具体产品,而是"AI 能像真人一样跟你对话"的那个理想终态。新智元那篇文章的标题《OpenAI 正式接管人类耳朵》、视频开头那句"Her 终于来了",说的都是同一件事:业界普遍认为,OpenAI 这次在演示视频里展示的 GPT-Realtime-2,已经无限接近萨曼莎了。
演示也确实唬人。你说要在通勤火车站旁开咖啡店,它会停顿,思考,然后告诉你"如果一年后倒闭,大概率是租金和客流不匹配",建议你先做一个站台咖啡推车试试 MVP。情绪、推理、空间感知、并行调用工具,全都丝滑。
但说真的,如果你只看到萨曼莎,你就漏掉了这场发布真正在发生的事。
"这不是音频模型变聪明了。这是 OpenAI 顺手把语音 Agent 中间件这一整层级,整层收编了。"
一、所有人在讨论的:萨曼莎层
先快速过一下大家在聊的浅层。
GPT-Realtime-2 是 OpenAI 第一个被官方描述为**"具备 GPT-5 级推理能力"**的语音模型。它的几个升级点,在媒体口径里被反复提及——上下文窗口从 32K 扩到 128K;可调推理强度从 minimal 到 xhigh 五档;并行调用工具;前导语功能让它能说"让我帮你查一下哈"代替沉默;语调可控(沮丧时同理心、成功时欢快)。
Benchmark 数据看起来也很漂亮。
Big Bench Audio(音频智能):high 档 96.6% 准确率,比 GPT-Realtime-1.5 的 81.4% 高 15.2 个百分点。
Audio MultiChallenge(多轮对话指令遵循):xhigh 档 48.5%,比上一版 34.7% 高 13.8 个百分点。
Zillow 客户实测:他们最难的对抗性 benchmark 上,呼叫成功率从 69% 升到 95%,一口气拉了 26 个点。
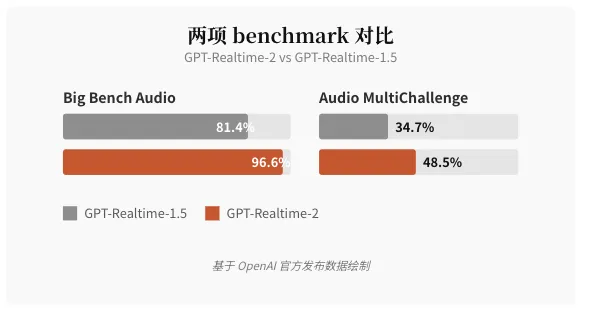
📌 图注:GPT-Realtime-2 在两项语音 benchmark 上的表现(示意图) | 来源:基于 OpenAI 官方博客数据整理绘制 · 2026 年 5 月
价格也不算贵。GPT-Realtime-2 输入每百万 token 32 美元、输出 64 美元(cached input 只要 0.4 美元);Translate 每分钟 0.034 美元;Whisper 流式版每分钟 0.017 美元。
这一层信息,所有 AI 媒体都报了。读完之后你的感受大概是"哇 AI 又进步了一大步"、"Her 真的快来了"、"我得去 Playground 玩一下"。
到这里都没问题。问题在于——这一层叙事,对任何 AI 创业者来说,都不构成可以行动的判断。"AI 进步了"这个结论,写在每篇技术报道的开头,但它没告诉你下周该做什么不同的事。
我想聊的是下面那一层。
二、真正在发生的:一次产业层的收编
你打开 OpenAI 这次的官博,把眼睛从"GPT-5 级推理"这几个字上移开,往下翻,会看到一张图——上面写着三个交互范式:Voice-to-Action、Systems-to-Voice、Voice-to-Voice。
这张图才是真正的发布会主角。
为什么?因为这三个范式,对应的是过去两年整个语音 Agent 行业拼凑出来的三种工作流,而 OpenAI 把它们用一个 API 全包了。
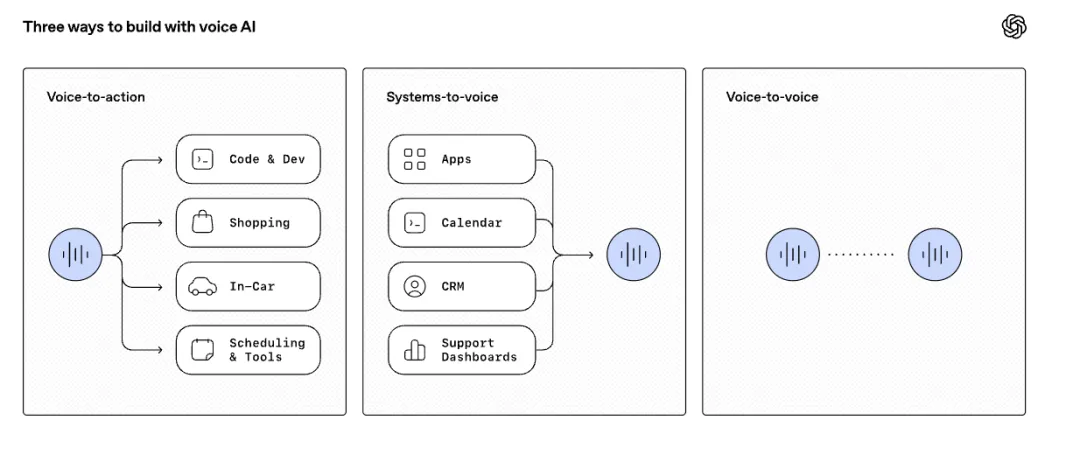
📌 图注:OpenAI 提出的三种语音交互范式:Voice-to-Action、Systems-to-Voice、Voice-to-Voice | 来源:OpenAI 官方博客 · 2026 年 5 月
我跟你拆一下——

看出来了吗?
这三个范式不是"新功能"。它们是过去 18 个月里整个语音 Agent 行业一直在卖的核心工作流。
每一个,原本都是用三到四家供应商的积木拼出来的。Heyloha、Bland、Vapi、Retell、PolyAI——这批公司过去两年的存在意义,就是替开发者把 ASR、LLM、TTS 这三家拼起来。
OpenAI 这次说:你们不用拼了,我这一个 API 直接出。
坦率讲,这是一次很标准的"上一层收编下一层"的操作。
三、这场发布真正的对手不是 Anthropic
媒体在追问"Anthropic 和 Google 怎么应对"。这个问题本身就问错了。
GPT-Realtime-2 的真正对手是谁?是过去靠"做好一件事"赚钱的那批语音中间件公司。

📌 图注:GPT-Realtime-2 真正冲击的是这一批语音中间件公司:Deepgram、ElevenLabs、Cartesia 等 | 来源:示意图整理 · 2026 年 5 月

Deepgram(ASR · 语音转文字)
GPT-Realtime-Whisper 0.017 美元/分钟,定价优势直接没了。BolnaAI 实测 Hindi、Tamil、Telugu 词错率比之前用的方案低 12.5%——意味着即使非英语长尾市场,Deepgram 也守不住差异化。
ElevenLabs(TTS · 语音合成)
GPT-Realtime-2 已经把"calmer when problem-solving、empathetic when frustrated、upbeat when confirming"这种情感化语调内置了,端到端 speech-to-speech 不需要单独走一道 TTS。ElevenLabs 能守住的是"自定义品牌声音"——这部分本来就比通用 TTS 小得多。
Vapi / Bland / Retell(Voice Agent 编排平台)
原来的价值就是替开发者把 ASR/LLM/TTS 三家拼起来。现在 OpenAI 自己一个 API 就能出工作流,他们的存在意义被压缩成"在 OpenAI API 之外提供一层 dashboard 和 telemetry"——这一层 OpenAI 通过 Agents SDK 也已经在做了。
Cartesia / Hume / PlayHT(其他被波及)
这批做 TTS 的小公司,处境更难。它们没有 ElevenLabs 那种品牌护城河,也没有非英语市场的深度积累,正面被压。
我跟你说,这种格局变化不是新鲜事。Twilio 当年也吃掉了一大批短信和电话中间件公司。AWS 当年也吃掉了一大批 IaaS 玩家。
每次平台层往下伸一只手,下一层就会被压扁一大块。
只是这次速度更快——因为模型层的迭代节奏,远远快过传统 SaaS。
四、这个剧本,Anthropic 三月份刚演过一遍
如果你看着这一切觉得熟悉,那是因为——
三月份的时候,Anthropic 也演过一遍类似的剧本。OpenClaw 这个开源项目原本被整个生态当成"AI Agent 的标准协议层",Anthropic 一边支持一边在 Claude Code 里把同样的能力内置了,结果是开源狂欢瞬间退潮。
复盘一下规律就清楚了。
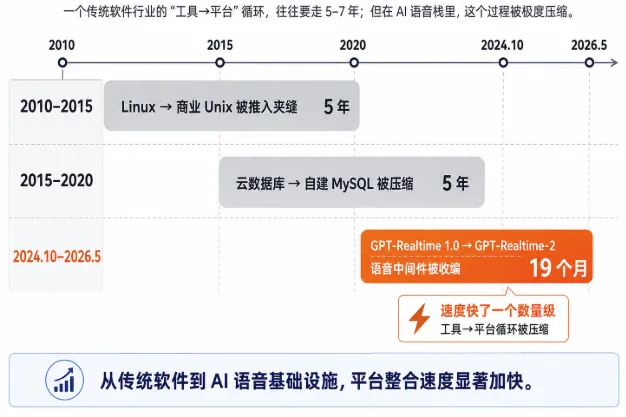
📌 图注:平台收编中间件的速度:从 5-7 年压缩到 19 个月 | 来源:作者整理绘制 · 2026 年 5 月
每一次循环都是同样的四步:
第一步:新能力出现(语音 Agent / Coding Agent / MCP),开源社区和创业公司涌进来抢市场。
第二步:这批早期玩家用碎片化工具拼出第一批可用产品,完成市场教育。
第三步:平台方观察哪些工作流跑通了,把这些工作流原生化到自己的 API 里。
第四步:碎片化玩家被压缩到夹缝里——要么往更垂直、平台不愿意做的细分领域走,要么被收购,要么消失。
Linux 把商业 Unix 推到了夹缝里。MySQL 把商业数据库压扁过一次。云数据库又把自建 MySQL 推到了夹缝里。每一次都是同样的循环。
差别只是这次更快。从 GPT-Realtime 1.0(2024 年 10 月)到 GPT-Realtime-2(2026 年 5 月),只用了 19 个月。一个传统软件行业的"工具→平台"循环要走 5-7 年,AI 行业现在 18 个月就能走完。
五、对你意味着什么
我们的读者里,有相当一部分人在做 AI Agent 相关的产品或者打算做。我想说三件事。
第一件事:如果你的产品定位是"语音 ASR / TTS / 编排"这类中间件,现在不是该不该转型的问题,而是转型时间窗口还剩多少的问题。我自己的判断是 6-12 个月。Vapi、Retell 这种公司不会立刻死,因为短期内还有"非英语市场覆盖更好"、"行业合规更深"、"自定义品牌声音"这类小缝隙可以钻。但中长期赌平台不动手,不是好赌注。
第二件事:如果你做的是"语音 + 垂直行业 Agent"——比如医疗问诊语音、法律咨询语音、教育陪练语音——这次发布反而对你是利好。你不用再花一半时间维护语音管线了,可以把那部分预算和精力释放到行业 know-how 上去。GPT-Realtime-2 加上 Agents SDK 加上你自己的领域提示词和数据,是一个比之前更轻、更快的栈。
第三件事——这一条最重要,也是我自己反复想的。
平台层的收编不会一次性完成。OpenAI 这次拿走的是"语音 Agent 中间件",但它没拿走"语音 + 摄像头 + 物理世界"。没拿走"端侧低功耗语音"。没拿走"超低延迟的电话级别 voice bot"。没拿走"非通用领域的高合规要求场景(金融、医疗的录音/留痕/审计)"。
每一次收编都会留下边界。问题是你能不能比 OpenAI 更快地找到下一个它够不到的角落。
六、键盘没死,只是换了主人
新智元那篇结尾写得很煽情:"键盘已老,语音永生。"
我换一个说法。
键盘没死,只是换了主人。
过去 30 年,键盘是 IBM、微软、苹果之间博弈的入口。鼠标、触摸屏,每一次主入口的变迁都重新分配了一次科技行业的利润。
语音这一层入口,过去两年还是开放的——Deepgram、ElevenLabs、Vapi、Bland,一群小公司拿着不同的拼图碎片在赛跑。
2026 年 5 月 7 日之后,这层入口的拼图被收回去了一大块。
接下来的问题不是"AI 会不会接管人类耳朵",而是"接管人类耳朵的入场券,最终掌握在几家公司手里"。
愚钝如我,目前看到的答案,不太乐观。
但乐观从来不是创业者的工具。看清楚棋局是。
