 夜雨聆风
夜雨聆风从原画衔接,转向参考设计
我现在更认同一种做法:先把角色、场景、镜头结构设计清楚,再让视频模型去执行。
只靠几张原画拼接,很容易出现物体错乱、角色变形、画面停顿的问题。而三视图的优势在于,它能让模型更清楚地知道角色长什么样、发型是什么、服装是什么、体型比例是什么。
如果只是想生成一段 15 秒左右的视频,角色三视图加上明确提示词,已经能得到比较稳定的结果。尤其是 Seedance 2.0 对起始帧和连续动作的处理,比以前那种硬接原画的方法自然很多。
但三视图也不是万能的。它能稳定角色,却不能完全控制背景、镜头节奏和每个 cut 的演出。所以后面还需要分镜来进一步管理画面。
我理解的基本流程
这套方法可以拆成一个比较清晰的流程:先用 image2.0 做出作品的整体概念图,确定世界观、角色气质和视觉方向。
然后根据作品内容,把整支视频拆成多个短段落,比如每 14 秒一组,每组 7 个镜头,每个镜头 2 秒。
接着让 image2.0 根据这个结构生成分镜。分镜出来之后,不是直接拿去生成视频,而是先审一遍:哪里动作不够,哪里演出不够,哪里角色关系不清楚,就继续修改。
等分镜基本成型,再补齐角色三视图、服装设定、背景设定图,最后用“分镜 + 角色参考 + 背景参考”交给 Seedance 2.0 生成视频。
视频生成完成后,还需要在 CapCut 里做剪辑、调色、音乐匹配和回忆段落处理。这不是“输入一句话,等模型变魔法”,而是一套更像动画前期制作的流程。
关键不是提示词,而是参考设计
这篇经验里最值得提炼的,其实是三个点。
第一,分镜和角色参考要分开。分镜负责镜头内容,三视图负责角色稳定。不能指望一张分镜图同时承担所有信息。
第二,要给视频模型一段“读取分镜”的提示词。也就是说,提示词不一定要把所有镜头细节都写满,而是告诉模型:请按照分镜里的 cut 编号、起始帧、结束帧、摄影机运动和视频提示词来执行。
第三,视频失败时,不要只想着改提示词。很多问题其实是分镜本身让 AI 误解了。分镜如果画错了,提示词再补也很累。
把长视频拆成短镜头
花样滑冰这类题材很难,因为动作幅度大,身体姿态复杂,服装也复杂。如果一个镜头里塞太多内容,模型很容易不知道重点。
所以更好的做法是把整体内容拆成短镜头。比如 98 秒的视频,可以拆成:2 秒 × 7 个镜头 × 7 个部分 = 98 秒
每个 2 秒镜头只做一件事:少女看向冰场、明星选手跳跃、教练握着冰鞋、主角旋转、对手登场、母亲守望、教练点头。这样 AI 更容易理解,也更容易保持画面稳定。
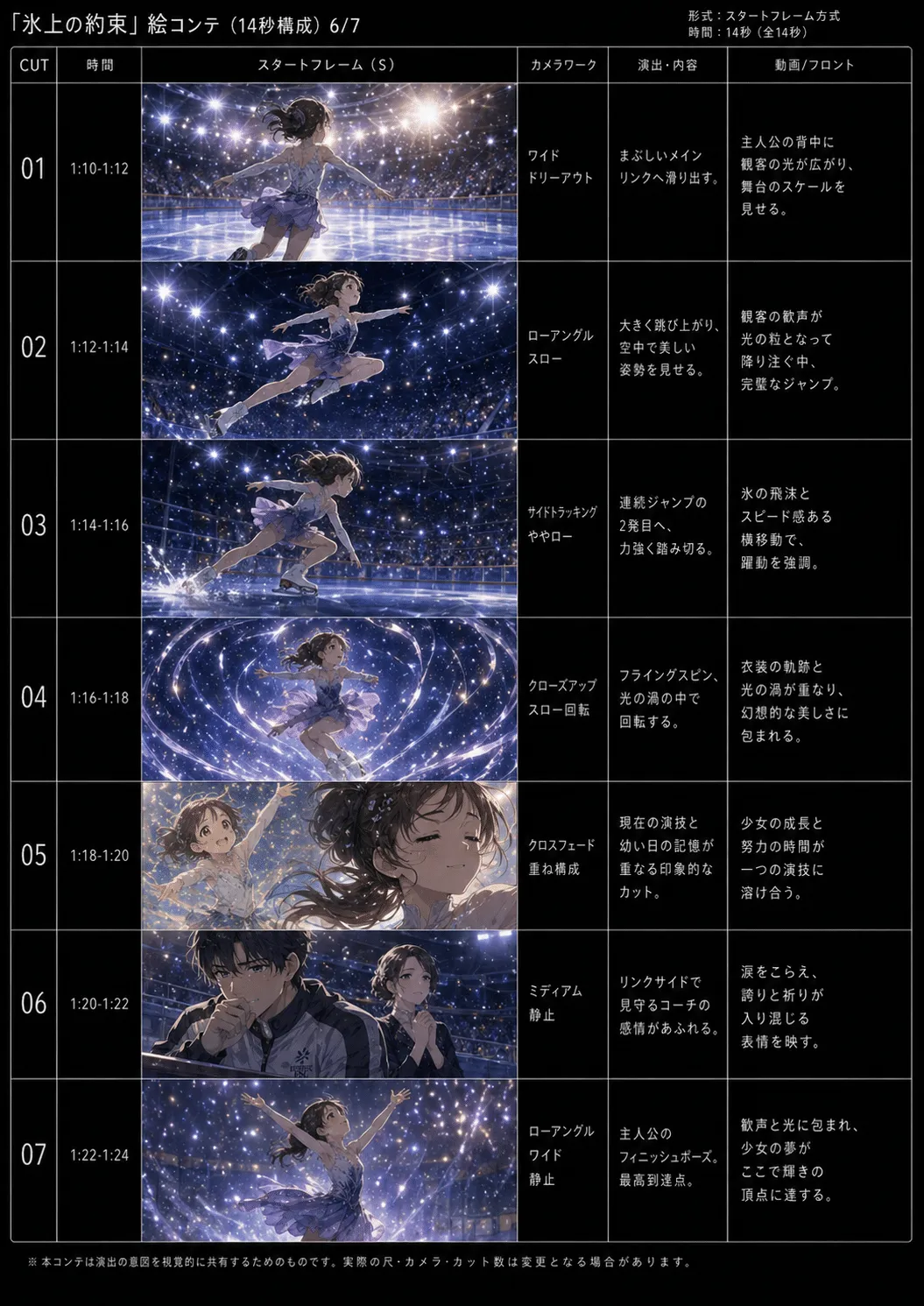
分镜应该是给 AI 看的命令书
我以前可能会把分镜理解成“给人看的画面草图”。但这篇文章提醒我,AI 视频里的分镜最好是“给模型看的命令书”。
所以分镜里不应该只有画面,还应该包含:
cut 编号 起始帧 结束帧 摄影机运动 演出内容 视频提示词
这也是为什么 image2.0 很适合参与前期设计。它不只是生成漂亮图,而是可以帮助我们快速做出可修改、可阅读、可执行的分镜。
角色参考必须单独准备
如果分镜里角色太小,AI 很容易把脸、发型、服装理解错,比如主角本来是侧马尾,视频里却可能变成双马尾。原因很简单:分镜里的角色太小,模型看不清。所以角色参考必须单独准备,而且不同状态最好分开。
同一个主角,日常私服和滑冰服就应该分成两套参考。日常状态强调脸、发型、年龄感和体型;滑冰状态强调服装、身体线条、冰鞋和动作姿态。这比把所有信息塞进一张图里稳定得多。

提示词要让模型“读分镜”
视频生成时,提示词本身可以保持相对简洁。核心不是把每个镜头都重新写一遍,而是明确告诉模型:
参考哪张分镜图,参考哪些角色三视图,每个 cut 如何读取,起始帧和结束帧怎么用,镜头顺序怎么排列,人物设计和色调如何保持一致。
这样的好处是,后续修改更方便。想调整某个镜头,不必重写整段提示词,只要改分镜里的对应内容。
这让我觉得,AI 视频制作的重点正在从“写提示词”转向“设计可被 AI 理解的制作文件”。
制作时踩过的几大坑
同一个角色不要在一个镜头里画多次
花样滑冰有很多连续动作,比如跳跃和旋转。人类画分镜时,可能会在同一张图里画出同一个人的多个姿势,用来表示运动轨迹。但 AI 不一定这么理解。
它可能会把这些姿势当成多个角色,于是画面里就出现“分身”。所以分镜要按 AI 的理解方式来画:一个镜头里尽量只放一个同一角色。动作轨迹可以通过箭头、摄影机运动、残影感或提示词来补充,而不是直接画多个实体人物。
练习场景不要让 AI 自动补观众
花样滑冰题材还有一个问题:模型一看到冰场,就容易联想到比赛现场。
即使你想做的是练习场景,它也可能自动加观众、工作人员、路人,结果画面就变成正式比赛了。
解决方法不是只写“练习场”,而是明确写:这是训练中,场内只有少女和教练。观众席没有人。不要添加观众、工作人员、路人或临时演员。这里不是比赛,而是安静的包场练习冰场。
同时,分镜上也要配合。不要把观众席画得太显眼,必要时让观众席变暗、虚化,或者减少它在画面里的面积。
角色服装要拉开差异
角色一多,服装就容易混。尤其花样滑冰服装本身装饰复杂,如果主角和对手的颜色、轮廓太接近,视频里就会越来越难分辨。
所以角色差异不能只靠脸,还要靠颜色、发型、服装轮廓和气质。
比如主角可以是白色到淡蓝色系,传达柔和、未完成但有希望的感觉。对手则可以用白、黑、红,传达锐利、成熟、天才感。这样 AI 更容易分清角色,观众也更容易看懂关系。
背景设定图也要单独做
只做角色三视图,角色会稳定,但背景会飘。所以背景也需要设定图。比如市民冰场、比赛会场、学校、家庭空间、傍晚回家路、名门俱乐部冰场,这些都应该有明确视觉区别。
市民冰场可以旧一点、本地感强一点,带青白色冰面和傍晚光。比赛会场则更明亮、更大、更正式,有观众席和竞技氛围。
背景一旦区分清楚,观众自然就能理解:哪里是练习,哪里是正式比赛,哪里是过去,哪里是现在。
image2.0 的价值在于快速改分镜
image2.0 最适合的地方,不只是出图好看,而是它可以快速响应修改。
想增加跳跃、增加旋转、清空观众席、修改服装、添加母亲角色、强化镜头意图,都可以直接通过文字修改分镜。这比以前一张张手动改原画高效太多。
更重要的是,它还能帮你组织画面布局。对于花样滑冰这种动作复杂、关系复杂的题材,它能把角色、冰场、教练视线和对手演出整理得更清楚。
后期仍然很重要
如果你要制作非常高质量精品短剧,目前人工介入剪辑是必不可少的
尤其是涉及过去和现在的叙事时,如果不做色调区分,观众很容易混淆。过去场景可以稍微降低饱和度,减弱对比,加一点白蓝色辉光,边缘压暗,再加轻微颗粒或噪点。转场可以用白闪或交叉淡化。这样观众会更容易理解:这是回忆,不是当前时间线。
音乐要配合时长和情绪
如果视频最终是 1 分 43 秒,音乐也要围绕这个时长来做。用 Suno 做 OP 曲时,如果歌词太完整,很容易超过 2 分半。所以歌词要短,情绪要集中。
音乐方向可以是日系动画 OP、女声、青春花样滑冰题材,前奏用钢琴和弦乐,后面进入快节奏 J-pop rock。歌词不需要把花样滑冰解释得太满,只要围绕梦想、冰面、约定、跳跃、未来这些关键词承载情绪就够了。OP 曲不是说明书,它更像情绪推进器。
我从这套方法里学到的核心
这套流程最重要的启发是:AI 视频不是只靠提示词控制,而是靠参考设计控制。
三视图负责角色,背景设定图负责环境,分镜负责镜头流程,简短提示词负责告诉模型如何读取这些参考。
参考图也不是越多越好。越多越容易让模型不知道优先级。关键是分工清楚,每张参考图都承担明确职责。而分镜也不能只按照人类习惯来画,它要画成 AI 不容易误解的形式。
因为篇幅问题,为大家整理所有素材。大家可以关注公众号,后台回复“滑冰”获取素材,大家学着复刻,尊重原创
原创来自

