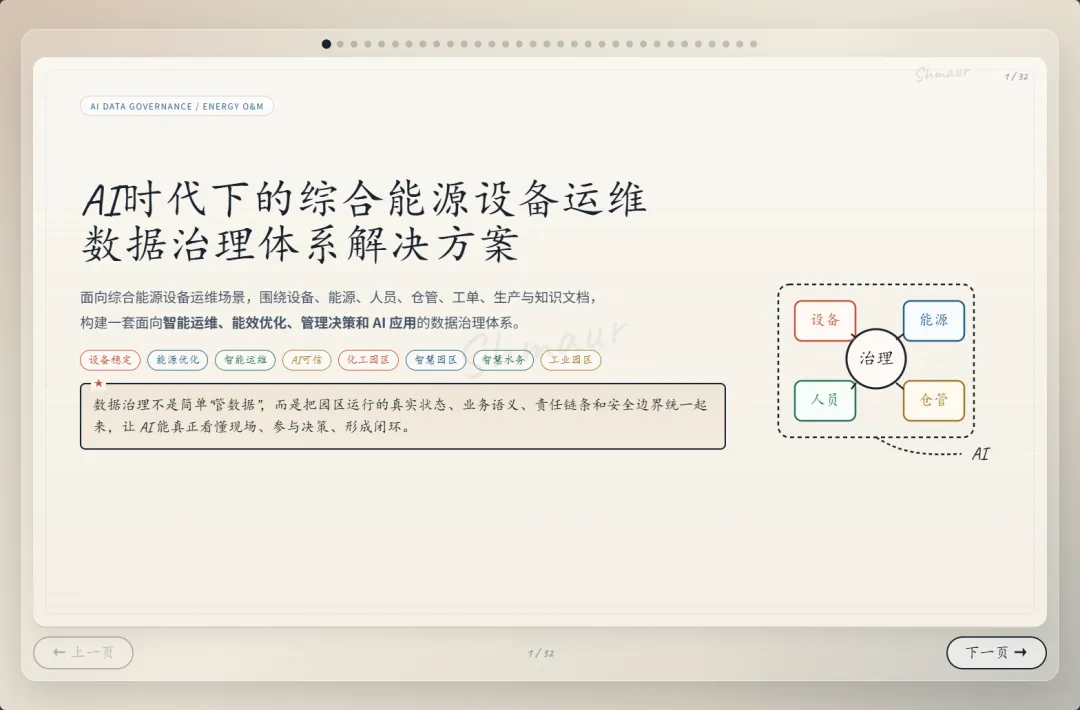
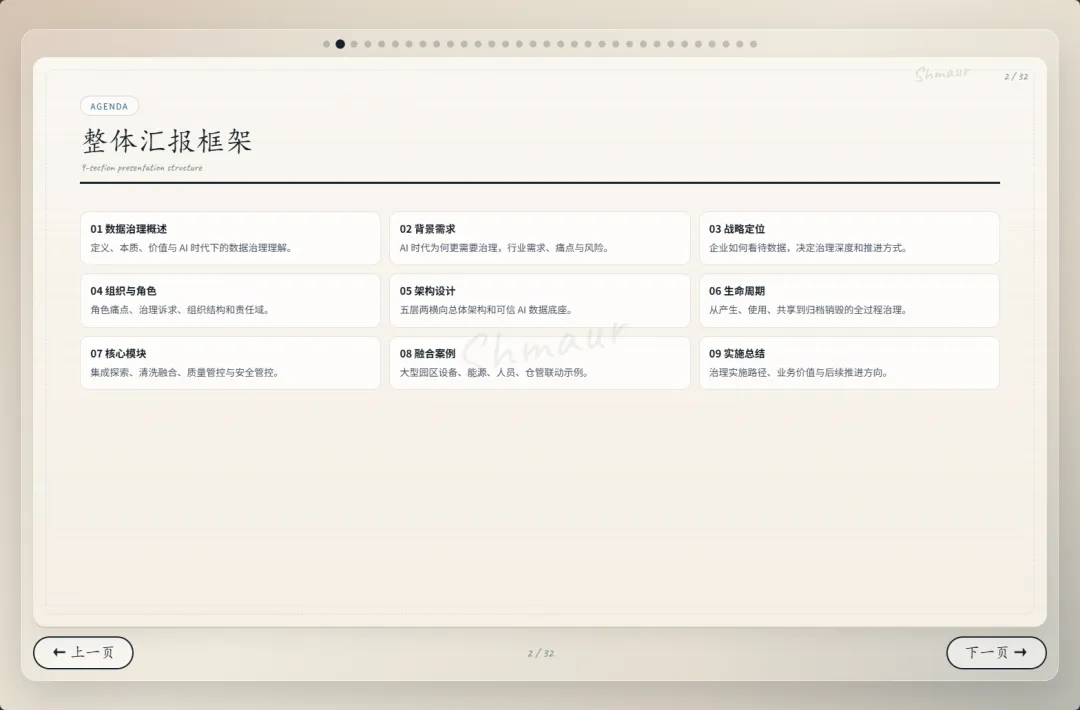
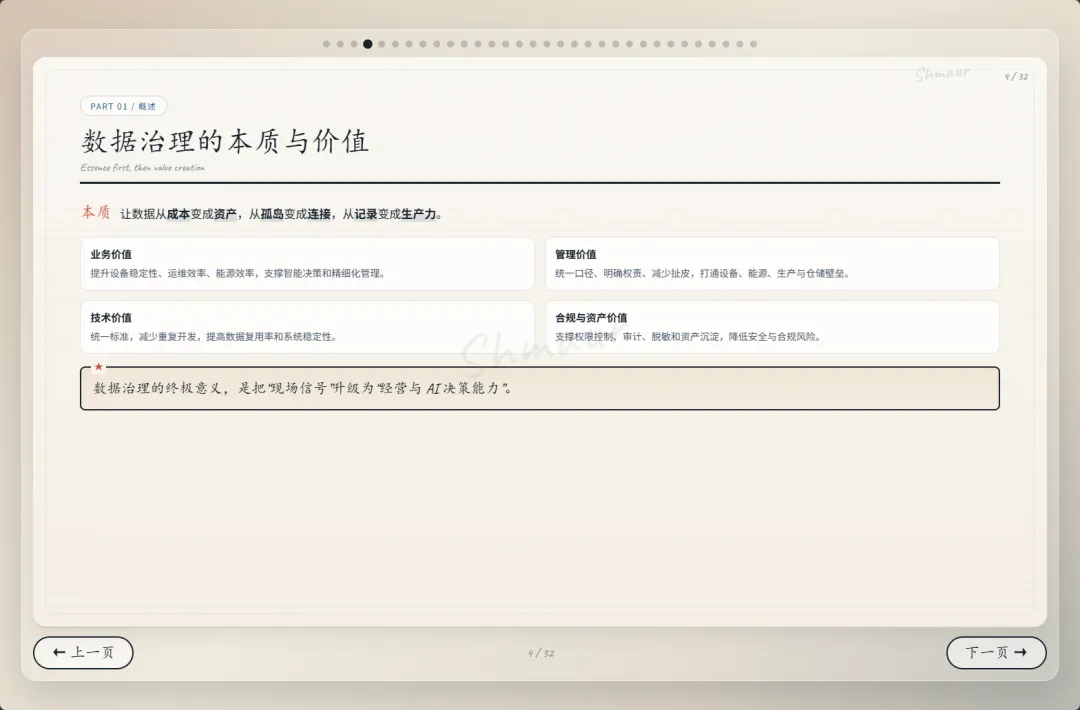
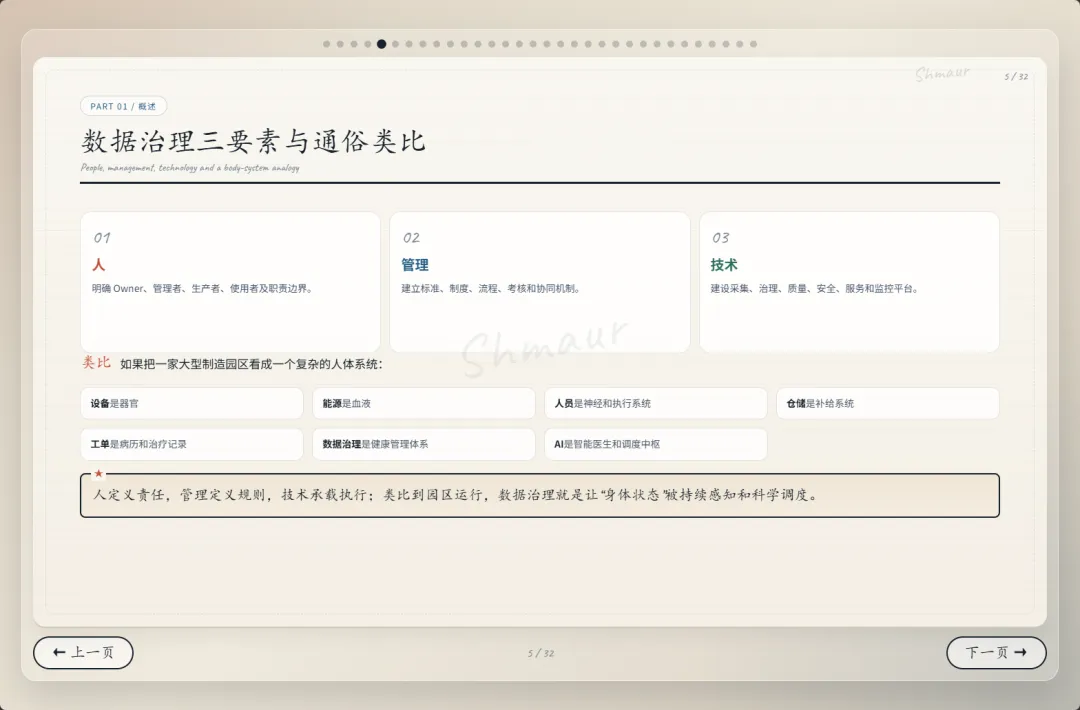
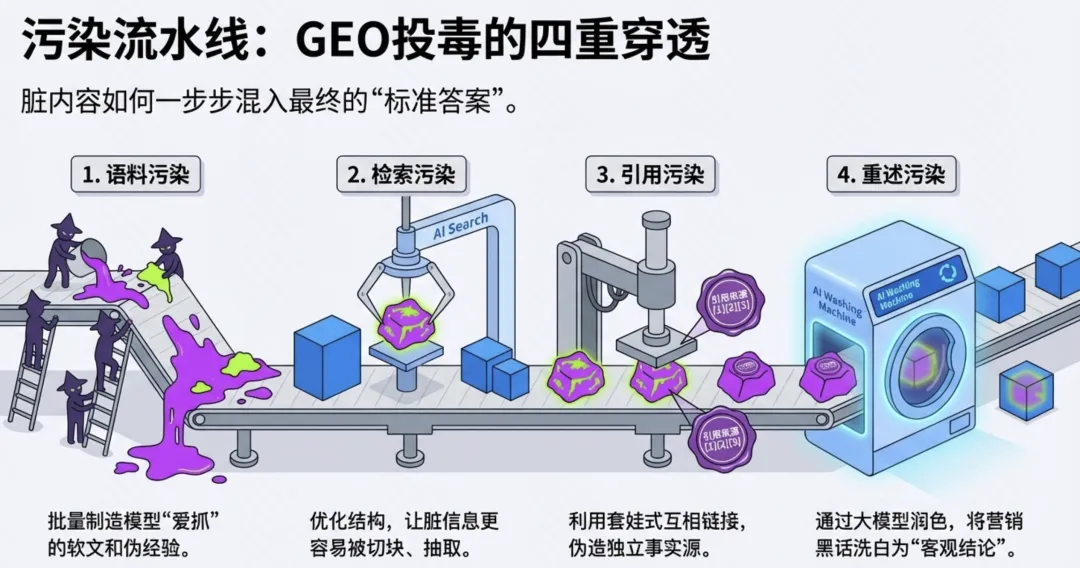
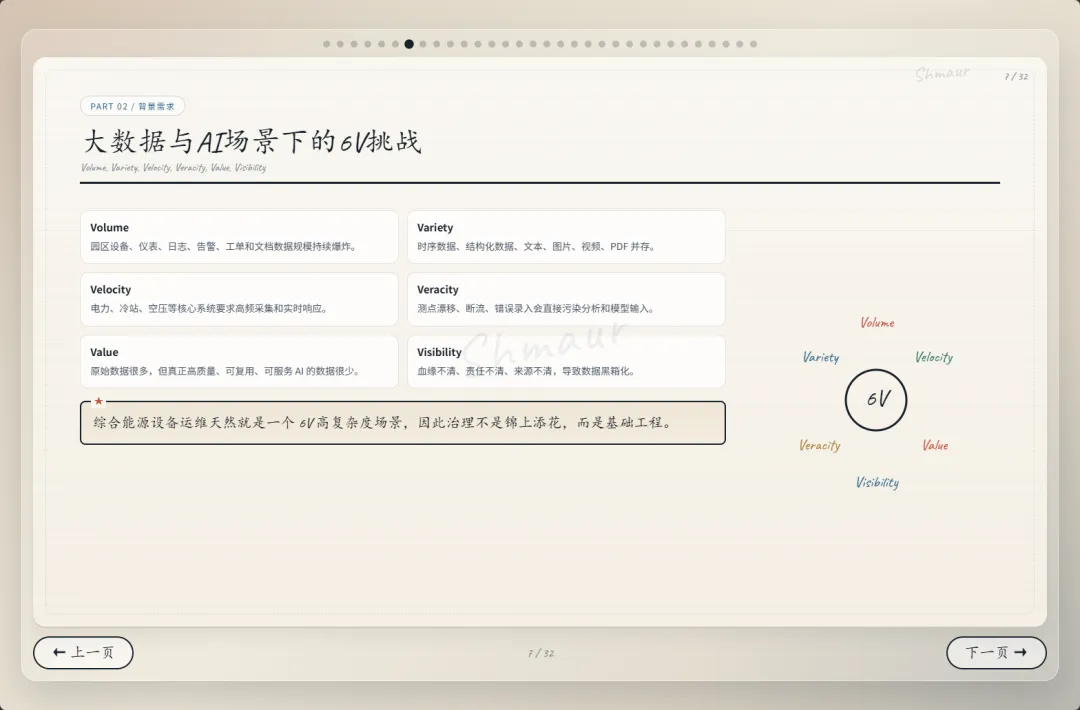
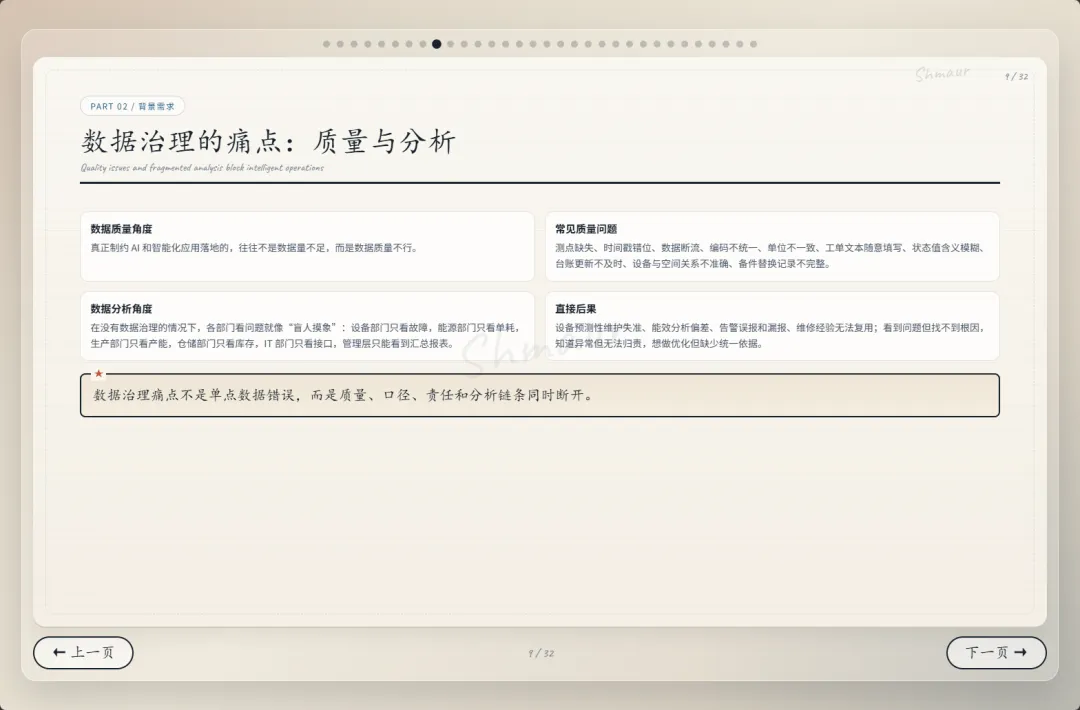
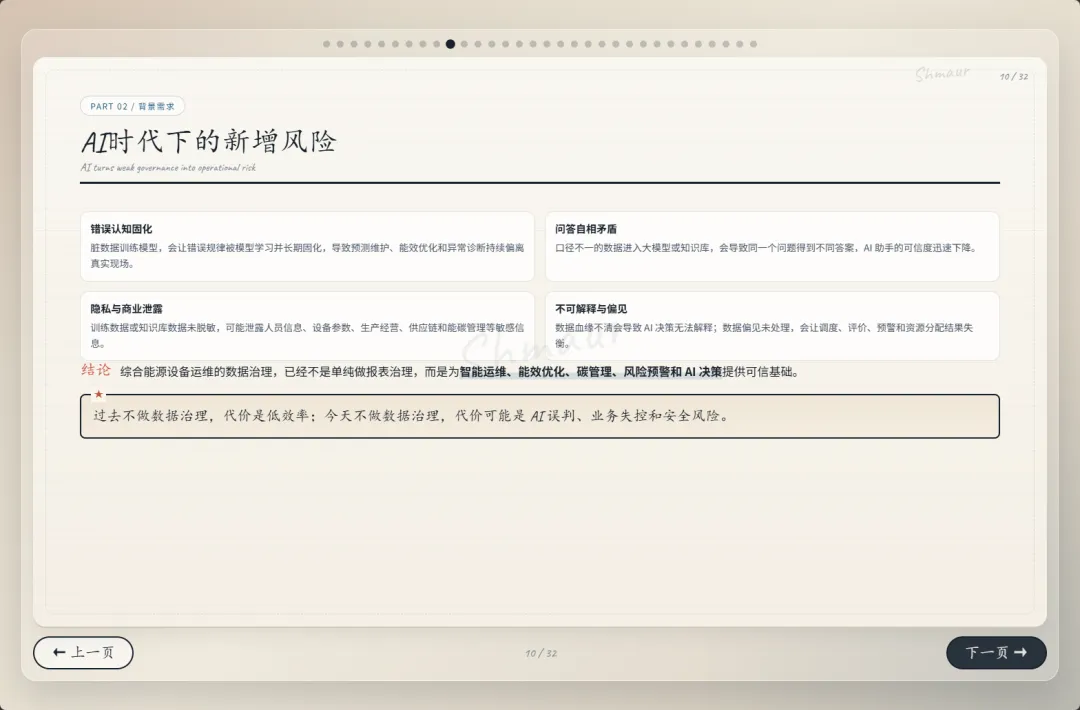
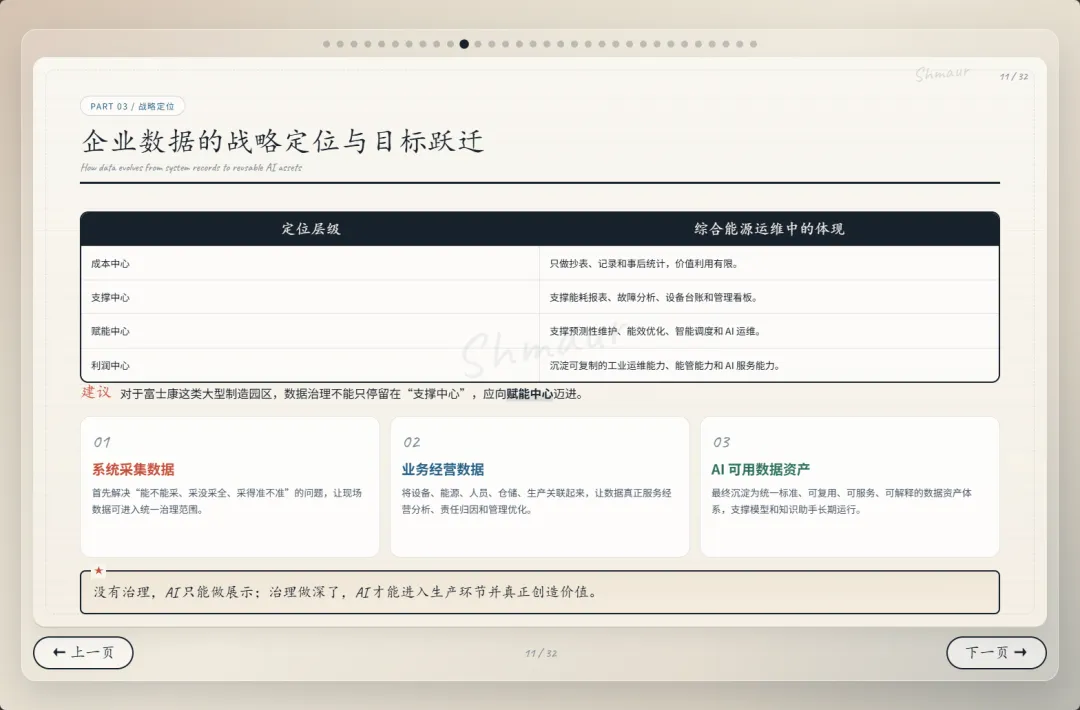
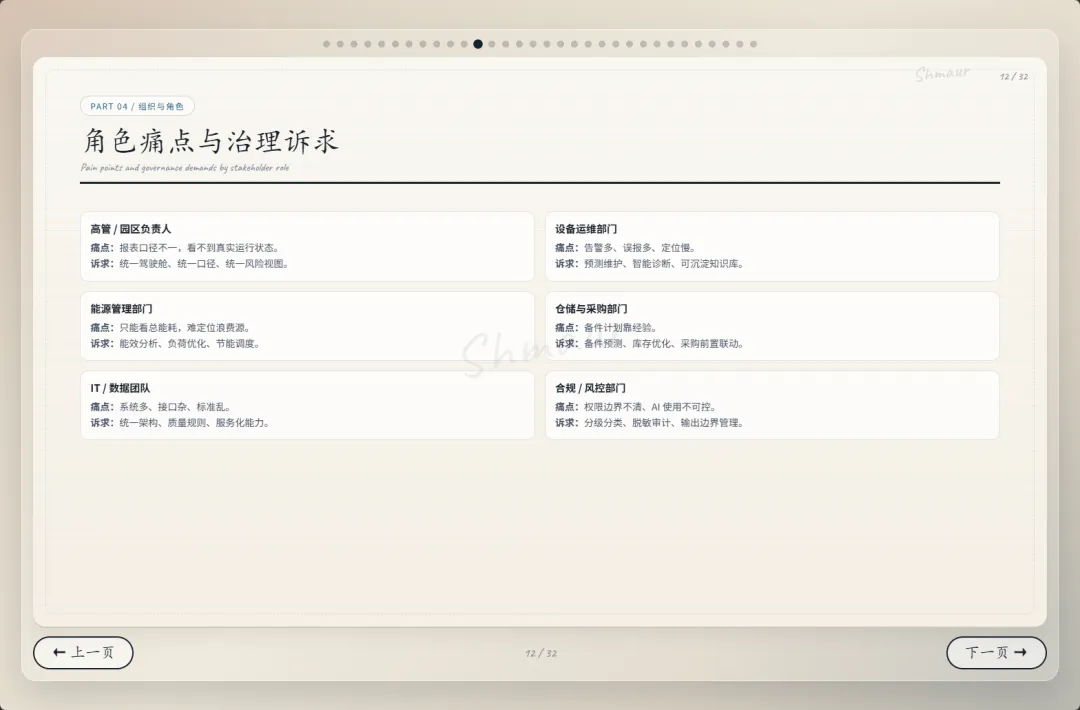
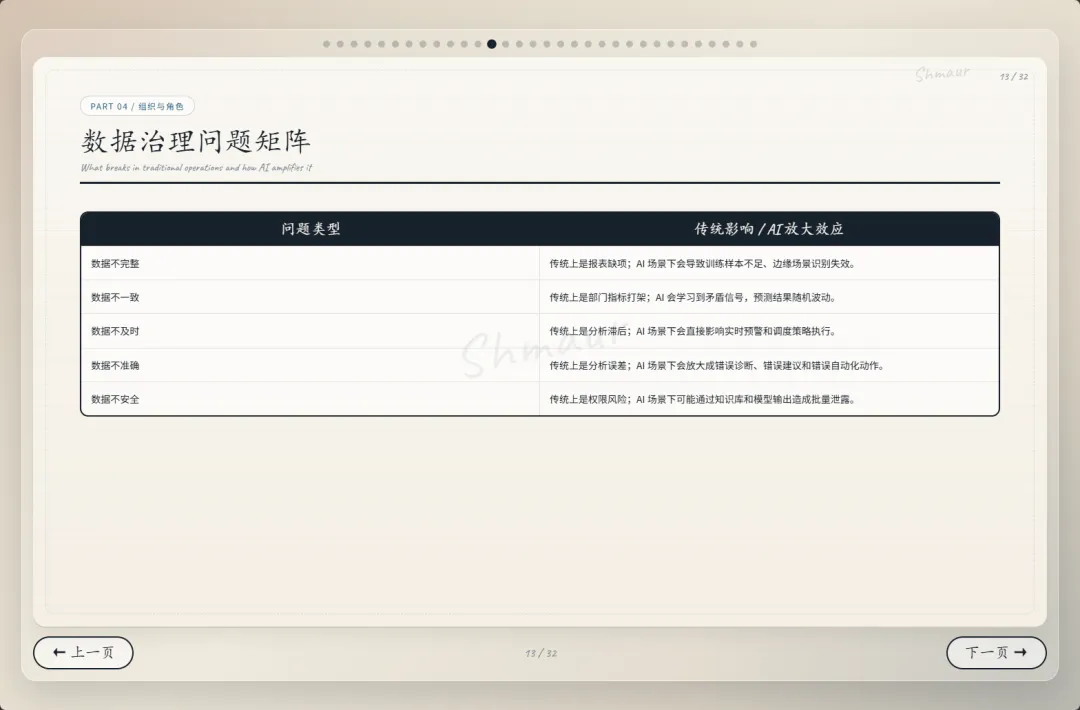
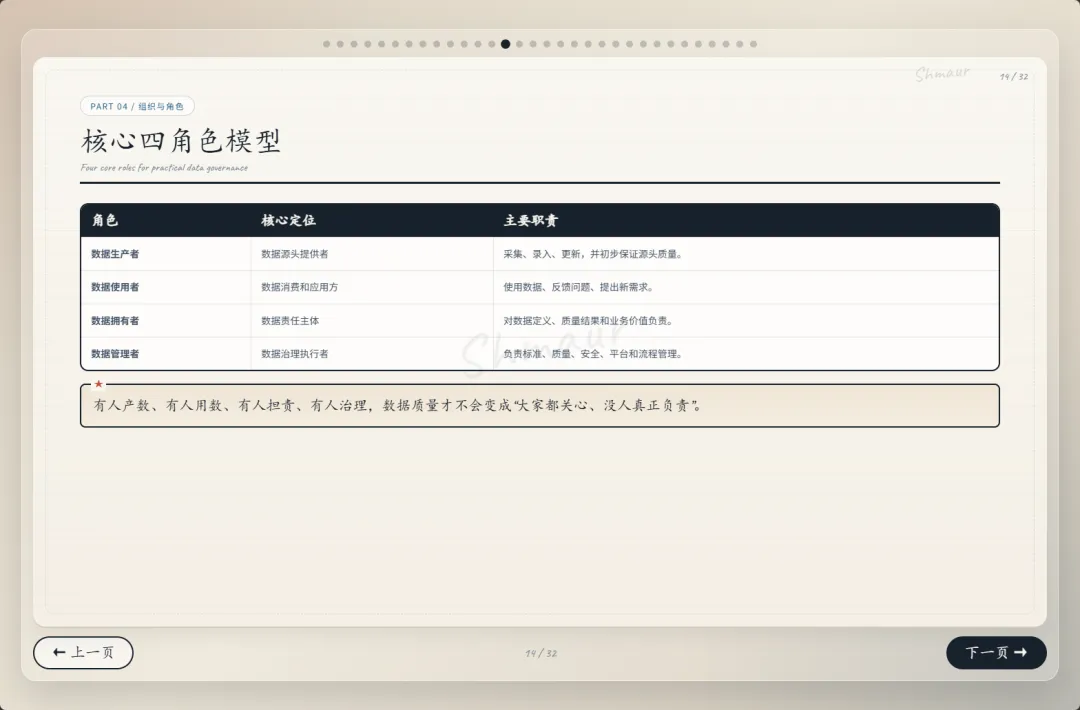
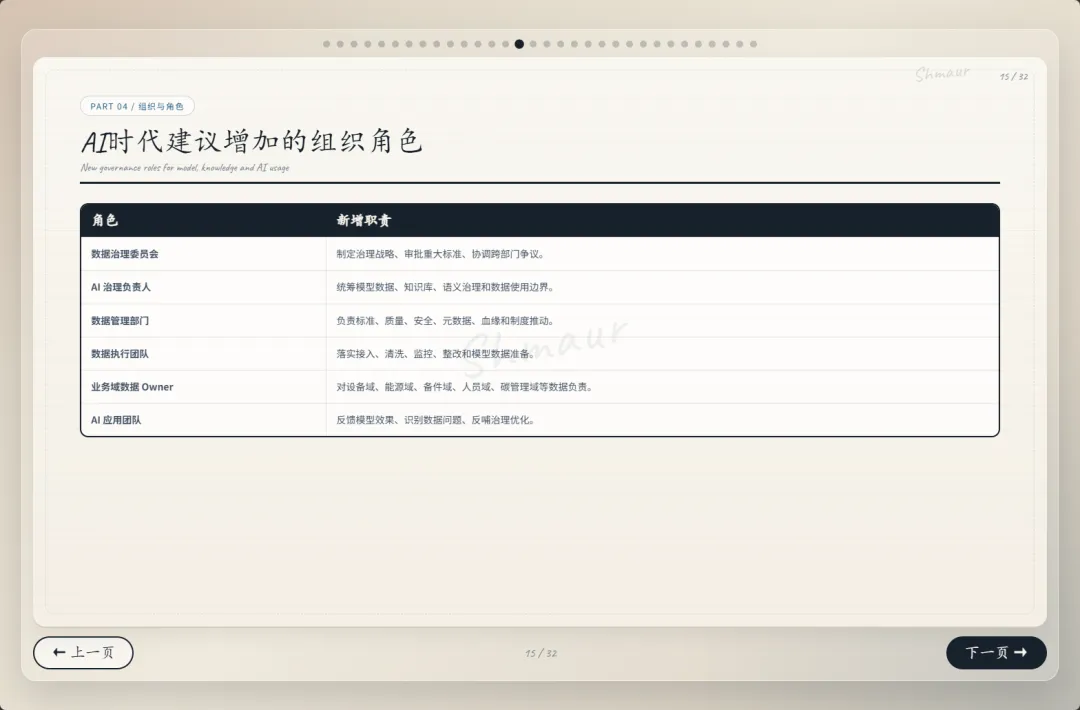
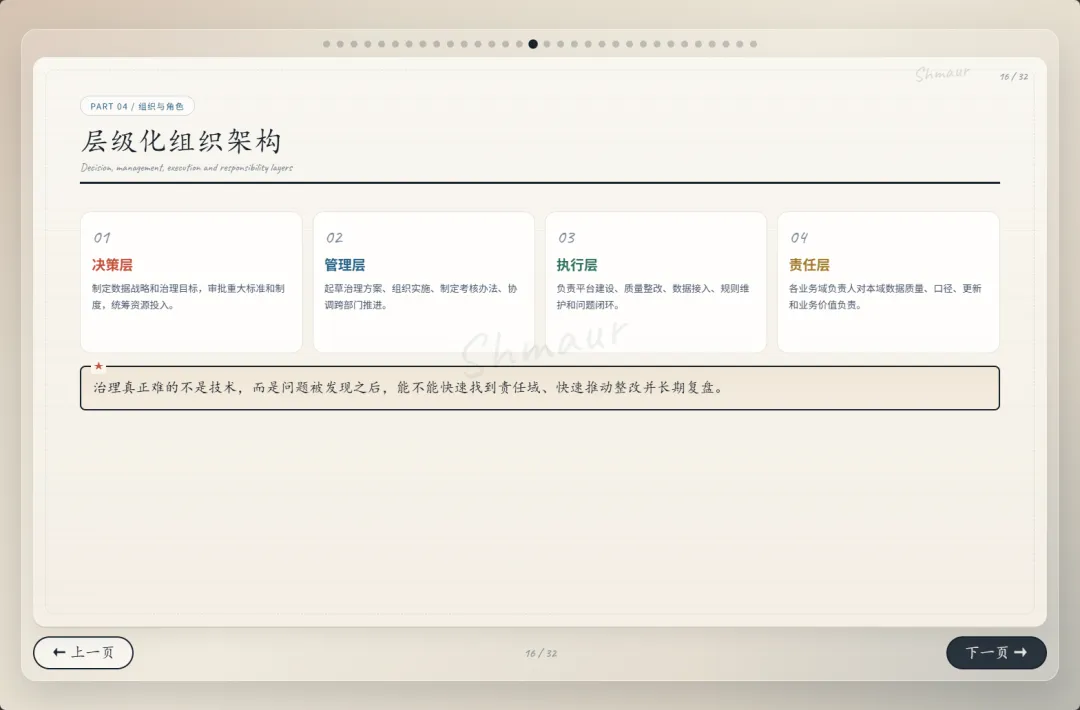
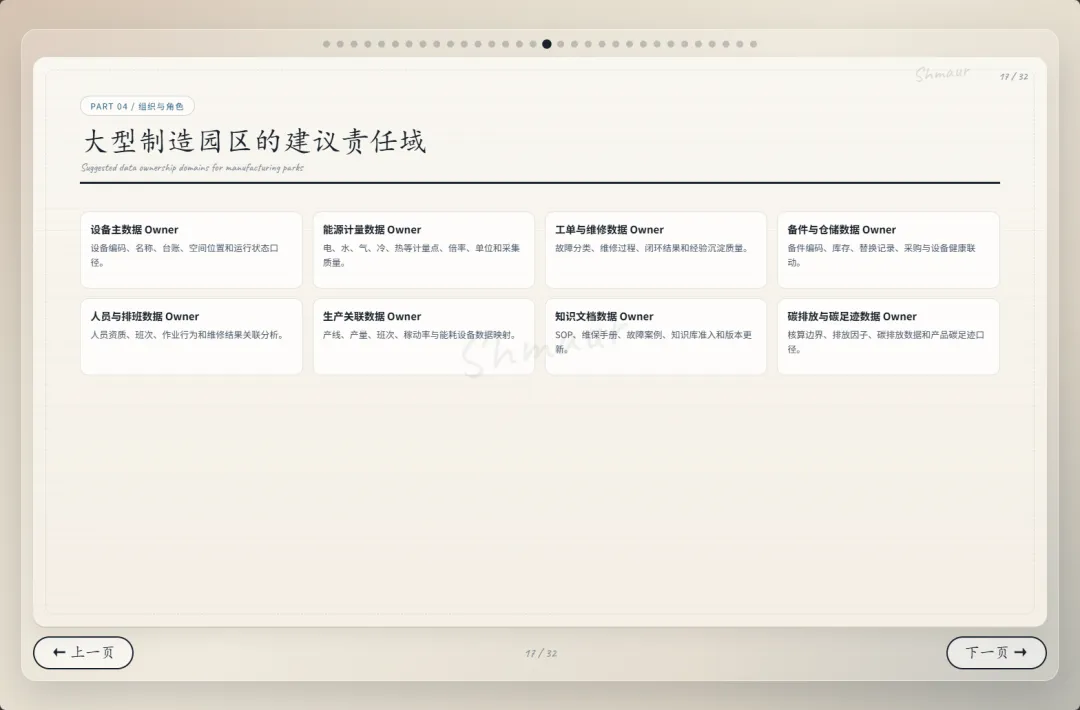
今天想和大家分享一套可落地的数据治理体系解决方案。 这套方案适用于工业园区、制造业、智慧园区、智慧水务、智慧运维和智慧能源管理等场景。为了讲得更具体,我们会以“综合能源设备运维”为主线,来看数据治理在 AI 时代到底解决什么问题。先举一个现场例子。假设系统监测到一台干式变压器出现局部放电异常。对传统系统来说,这可能只是一个告警;但如果数据治理做得好,这个告警就不再是孤立信号。系统可以自动关联这台设备的台账信息、运行曲线、历史维修记录、同类故障案例、排障指南,以及备件仓库的库存状态。AI 也可以基于这些信息,辅助判断故障风险、推荐排查步骤,甚至提示是否需要提前准备备件。但这里有一个前提:设备编码要统一,测点含义要清楚,单位口径要一致,维修记录要规范,知识文档要可检索,权限边界也要清晰。所以,数据治理不是简单地“拉几个报表”,而是通过一套覆盖数据产生、采集、清洗、标准化、使用、共享和安全管控的生命周期管理,把零散的设备时序数据、能源消耗数据、工单记录,甚至纸质图纸和维修手册,转化为 AI 能理解、能学习、能追溯的数字资产。没有治理的数据,对 AI 来说只是噪音;只有经过治理的数据,才真正能成为企业的资产。接下来先看一下整体汇报框架。这次分享会分成九个部分,但它不是简单地从概念讲到技术,而是按照“为什么要做、由谁来做、怎么建设、如何落地、最终产生什么价值”这条主线展开。第一部分,我们先明确什么是数据治理,它的本质、价值,以及在 AI 时代为什么数据治理不再只是后台管理工作,而是智能化应用的基础能力。第二部分会讲背景需求,也就是为什么工业园区、制造业、智慧水务、智慧能源这些场景,对数据治理的要求越来越高。这里会重点看行业痛点、数据质量问题,以及 AI 放大后的新风险。第三部分是战略定位。企业如何看待数据,决定了治理的深度。如果只是把数据当报表来源,治理会停留在表层;如果把数据当成资产,治理就会进入业务流程和 AI 能力建设。第四部分是组织与角色。数据治理不是单靠 IT 部门就能完成的,它需要业务、运维、能源、仓储、合规和数据团队共同参与,所以这里会讲角色责任和组织机制。第五、六、七部分是方案的主体。我们会从总体架构、数据生命周期,以及核心模块三个层面展开,包括数据集成、存储处理、元数据、标准、质量、安全等能力。第八部分会用一个融合案例,把设备、能源、人员、仓管和工单这些数据如何联动起来讲清楚。最后第九部分,会回到实施路径和价值总结,看这套体系如何分阶段落地,以及它最终如何支撑智能运维、能效优化、管理决策和 AI 应用。很多人一听到数据治理,容易把它理解成数据清洗、数据报表,或者建一个数据平台。但实际上,数据治理不是单一技术动作,而是一套围绕制度、标准、流程、组织、技术、安全和责任的统一管理体系。它的目标,是让数据变得真实、准确、完整、安全、可用、合规、可追溯。放到综合能源设备运维场景里,治理对象也不只是报表数据。它还包括设备运行数据、能源计量数据、人员排班和资质数据、仓储备件数据、工单维修数据,以及 SOP、图纸、维修手册、故障案例这些知识文档数据。这些数据原本分散在不同系统、不同部门、不同时间周期里。比如设备数据可能在 SCADA 或 PLC 里,工单数据在运维系统里,备件数据在仓储系统里,能源数据又在能耗平台里。如果没有治理,它们之间很难形成统一语义,也很难被 AI 正确理解。所以,数据治理解决的不是某一张表、某一个系统的问题,而是跨系统、跨部门、跨时序、跨责任主体的数据协同问题。可以用一句话来理解:数据治理就是把原本分散、混乱、难复用的数据,变成企业可持续经营和 AI 可以放心使用的数据资产。下面这张图也表达了这个意思。中间是数据治理,周围有标准体系、流程体系、组织责任、技术平台、安全合规,最后共同支撑 AI 应用。也就是说,AI 能不能真正参与预测、诊断和优化,前提不是模型有多强,而是底层数据是否可信、可解释、可追溯。对于数据治理的本质如果用一句话概括,数据治理的本质,就是让数据从成本变成资产,从孤岛变成连接,从记录变成生产力。过去很多企业看待数据,更多是把它当作系统运行过程中产生的记录。比如设备运行记录、能耗记录、维修记录、仓储记录,平时分散在不同系统里,只有做报表或者追溯问题时才会被拿出来使用。这样一来,数据更多是一种维护成本。但经过治理之后,数据的角色会发生变化。第一是业务价值。设备运行数据、工单数据、能源数据被打通以后,可以帮助企业提升设备稳定性、运维效率和能源效率,也能支撑管理层做更精细的经营决策。第二是管理价值。数据治理可以统一口径、明确权责、减少部门之间因为数据不一致产生的扯皮。比如同一台设备在不同系统里名称不同、编码不同,治理之后就可以形成统一对象和统一责任链条。第三是技术价值。统一标准和数据模型之后,可以减少重复开发,提升数据复用率,也能让系统之间的接口更稳定,后续接入新的园区、新的设备、新的 AI 应用时,不需要每次都从零开始。第四是合规与资产价值。通过权限控制、审计、脱敏和资产目录管理,企业可以降低安全与合规风险,同时把关键数据沉淀成可持续复用的数据资产。所以,数据治理的价值不只是让报表更准确,而是把现场的设备信号、能源信号、工单记录和知识经验,升级为经营分析和 AI 决策能力。数据治理的终极意义,是把“现场信号”升级为“经营与 AI 决策能力”。核心观点:数据治理不是单靠技术平台就能完成的,而是“人、管理、技术”三位一体的系统工程。首先是人。要明确谁是数据 Owner,谁是数据管理者,谁负责生产数据,谁负责使用数据,以及每个角色在数据质量、更新、权限和问题整改中的责任。第二是管理。要建立统一的数据标准、制度流程、考核办法和跨部门协同机制。否则数据问题被发现了,也很难形成持续整改。第三是技术。要通过数据采集、数据治理、质量监控、安全管控、数据服务和运行监控平台,把规则落到系统里,把治理动作变成可执行、可追踪、可复用的能力。这三者缺一不可。只有平台没有制度,治理很难持续;只有制度没有责任,治理很难落地;只有责任没有技术,治理又很难规模化。所以真正可落地的数据治理,一定是责任有人承担、规则有人执行、平台能够支撑。在这之前我们先看下大数据的挑战,再来讲为什么AI时代下更需要数据治理在综合能源设备运维场景,我们面对的不是单一数据问题,而是数据量大、类型多、速度快、真实性要求高、价值密度不均、血缘和责任不可见这六类挑战,因此数据治理必须作为 AI 应用前的基础工程来建设。接下来我们重点回答一个问题:为什么 AI 时代下更需要数据治理?在传统报表时代,数据质量问题带来的影响,更多是统计口径不一致、报表延迟、人工核对成本增加。问题虽然麻烦,但大多还停留在低效率和管理争议层面。但到了 AI 场景下,数据问题会被明显放大。因为 AI 不只是看数据,它会基于数据进行训练、判断、预测、生成答案和推荐策略,甚至参与自动化决策。一旦输入数据不准确、不完整、不一致,就可能导致模型训练偏差、预测结果失真、自动化决策错误、运维建议失效,甚至造成敏感信息泄露和业务风险放大。前段时间有一个很典型的新闻,就是央视 3·15 曝光的 AI“投毒”乱象,里面提到了 GEO,也就是 Generative Engine Optimization,生成式引擎优化。GEO 本身可以是合规的内容优化方法,但一旦被黑灰产利用,就可能变成对 AI 答案的污染。污染分成四部分:先制造大量带有倾向性的语料,把不可靠的信息混入网络内容;再通过搜索和引用链路,让这些内容更容易被 AI 检索到;最后 AI 在生成答案时,把这些被污染的信息重新组织成看似权威、看似客观的结论。这件事给我们的启发是:AI 的输出质量,很大程度上取决于输入数据和知识来源的质量。如果源头数据被污染、口径不一致、来源不可追溯,AI 就可能把错误信息包装成标准答案。回到综合能源设备运维场景也是一样。比如设备告警、能耗曲线、工单记录、维修手册、备件库存,如果这些数据编码不统一、单位不一致、时间戳错位、知识文档版本混乱,AI 就可能基于错误上下文给出错误判断。所以,今天的数据治理已经不只是为了让报表更准确,而是为了让 AI 的输入可信、过程可控、输出可追溯。也可以这样理解:传统时代不做数据治理,更多是效率问题;AI 时代不做数据治理,就可能变成错误 AI、错误调度、错误决策和安全风险。因此,AI 时代的数据治理,已经从过去的“管理优化项”,变成了智能化建设的“必选项”。以大型制造园区为例,企业内部通常同时存在很多套数据体系。比如设备运行数据、能源计量数据、能碳数据、产线生产数据、维修保养数据、工单闭环数据、巡检作业数据、人员资质与排班数据、备品备件和仓储数据、安全监控与环境数据,以及知识文档和 SOP 数据。另外还有一些第三方数据也会影响园区运行,比如天气、地图、电价、碳排放因子、物流和供应商数据。这些数据虽然都和园区运行相关,但往往分散在不同平台和部门里。设备数据可能在 SCADA、PLC、BMS、DCS;能源数据在 EMS、能耗平台、电力监控系统;工单在 EAM、CMMS 或维修系统;仓储在 ERP、WMS;人员在 HR、门禁和排班系统;文档又分散在 OA、共享盘和知识库里。一旦这些系统彼此割裂,就会出现很多典型问题。比如同一台设备在不同系统里名称不同、编码不同;能源数据和设备运行数据无法一一映射;工单记录和故障告警无法自动关联;维修记录无法沉淀为知识资产;备件库存也无法和设备健康预测联动。所以:工业园区的数据治理难点,不是单个系统有没有数据,而是多系统、多部门、多口径的数据,能不能统一到同一套业务语义和责任链条中。只有先把这些数据关系理清楚,后面的智能运维、能效优化、AI 诊断和管理决策才有基础。我们把数据治理的痛点和 AI 时代的新风险放在一起看。首先从数据质量角度来看,很多企业真正制约 AI 和智能化应用落地的,并不是数据量不够,而是数据质量不够好。在综合能源设备运维场景里,常见问题包括测点缺失、时间戳错位、数据断流、编码不统一、单位不一致、工单文本随意填写、状态值含义模糊、台账更新不及时、设备与空间关系不准确、备件替换记录不完整等等。这些问题看似是基础数据问题,但会直接影响上层应用。比如设备预测性维护会失准,能效分析会产生偏差,告警可能误报或漏报,维修经验无法复用,AI 助手的回答也会变得不可靠。再从数据分析角度来看,如果没有数据治理,各部门看问题就像“盲人摸象”。设备部门只看故障,能源部门只看单耗,生产部门只看产能,仓储部门只看库存,IT 部门只看接口,管理层最后只能看到汇总报表。结果就是,看到了问题,但找不到根因;知道有异常,但无法归责;想做优化,但缺少统一依据。到了 AI 时代,这些问题还会进一步放大。脏数据训练模型,会让错误认知被长期固化;口径不一的数据进入大模型或知识库,会导致同一个问题得到不同答案;训练数据或知识库未脱敏,可能造成隐私和商业信息泄露;数据血缘不清,会导致 AI 决策无法解释;数据偏见不处理,也会让调度、评价、预警结果失衡。所以,数据治理的痛点不是单点数据错误,而是质量、口径、责任和分析链条同时断开。过去不做数据治理,代价更多是低效率;今天不做数据治理,代价可能就是 AI 误判、业务失控和安全风险。企业数据的战略定位,也就是企业到底把数据看成什么。如果只是把数据看成成本中心,它的作用就停留在抄表、记录和事后统计,更多是系统运行的附属产物。再往上一层,是支撑中心。数据可以支撑能耗报表、故障分析、设备台账和管理看板,但主要还是服务报表和分析。第三层是赋能中心。这个阶段,数据开始进入业务流程,支撑预测性维护、能效优化、智能调度和 AI 运维,真正帮助业务提升效率。再往上,可以理解为能力运营中心,甚至是未来的数据资产经营中心。数据不只是内部使用,还可以沉淀成可复制的工业运维能力、能源管理能力和 AI 服务能力。这里也可以结合国家现在推动的数据要素、可信数据空间和信创体系来看。数据治理做深之后,企业不只是把数据管好,还能把数据资产、算法能力和场景能力沉淀下来,形成可确权、可计量、可流通、可审计的能力基础。未来在合规和安全边界清晰的前提下,部分高价值数据产品、能效模型、设备健康评价能力,也有可能进入数据空间或数据交易场景。对于大型制造园区,数据治理不能只停留在“支撑中心”,也就是只做报表和看板,而应该逐步向“赋能中心”和“数据资产经营”方向迈进。底下这三步也说明了这个跃迁过程:第一步,先解决系统采集数据的问题,确保能采、采全、采准;第二步,把设备、能源、人员、仓储、生产这些数据关联起来,变成业务经营数据;第三步,再沉淀成统一标准、可复用、可服务、可解释的 AI 可用数据资产。所以:没有治理,AI 只能做展示;治理做深了,AI 才能进入生产环节,并为未来的数据资产运营和数据要素流通打基础。重点讲一下组织与角色。前面我们讲了很多技术和数据问题,但以我目前参与大型数据治理项目的经验来看,数据治理真正要落地,不能只靠平台,必须回到“谁支持、谁负责、谁推动、谁整改”。这里我先强调一个非常重要的点:数据治理一定要有高层领导的明确支持。因为数据治理天然是跨部门、跨系统、跨责任域的事情,会涉及标准统一、流程调整、权限变化、历史问题整改,甚至会触碰一些部门原有的管理习惯。在我参与过的很多大型项目里,数据治理推不下去,常见原因并不是方案不完整,而是组织条件没有到位。比如领导支持不到位,跨部门协调推不动;执行层执行不到位,规则写了但没人落实;缺少数据管理人才,平台建了但没人运营;平台能力不足,业务部门觉得增加负担,最后产生抵触。所以我一直认为,数据治理首先是一把手工程,其次才是平台工程。我们再来看不同角色的痛点。园区负责人关心的是报表口径是否统一,能不能看到真实运行状态;设备运维部门关心告警多、误报多、定位慢;能源管理部门关心能不能从总能耗进一步定位浪费源;仓储和采购部门关心备件计划能不能更准确;IT 和数据团队关心系统多、接口杂、标准乱;合规和风控部门则关心权限边界、脱敏审计和 AI 使用是否可控。这些角色的诉求不同,但背后其实指向同一个问题:数据治理不能只解决“有没有数据”,还要解决“数据是否可信、谁来负责、出了问题谁来改”。所以我通常会建议企业先建立清晰的角色模型。这里有四类核心角色:数据生产者负责采集、录入和更新;数据使用者负责使用数据、反馈问题和提出需求;数据拥有者对数据定义、质量结果和业务价值负责;数据管理者负责标准、质量、安全、平台和流程管理。简单讲,就是有人产数、有人用数、有人担责、有人治理。否则数据质量很容易变成“大家都关心,但没人真正负责”。到了 AI 时代,我也建议增加一些新的组织角色。比如数据治理委员会,负责治理战略和重大标准;AI 治理负责人,统筹模型数据、知识库、语义治理和数据使用边界;业务域数据 Owner,对设备域、能源域、备件域、人员域、碳管理域等数据负责;AI 应用团队则要反馈模型效果,识别数据问题,反哺治理优化。落到大型制造园区里,我会进一步建议把责任域拆清楚。比如设备主数据 Owner,负责设备编码、名称、台账、空间位置和运行状态口径;能源计量数据 Owner,负责电、水、气、冷、热等计量点、倍率、单位和采集质量;工单与维修数据 Owner,负责故障分类、维修过程、闭环结果和经验沉淀质量;备件与仓储数据 Owner,负责备件编码、库存、替换记录、采购与设备健康联动。同时,人员与排班数据 Owner 要负责人员资质、班次、作业行为和维修结果关联分析;生产关联数据 Owner 要负责产线、产量、班次、稼动率与能耗设备数据映射;知识文档数据 Owner 要负责 SOP、维保手册、故障案例、知识库准入和版本更新;碳排放与碳足迹数据 Owner 则要负责核算边界、排放因子、碳排放数据和产品碳足迹口径。为什么要拆这么细?因为数据治理不能只停留在“某个部门总体负责”。如果责任域不清,出了问题就很容易变成互相推诿。只有把每一类核心数据都明确 Owner,后续质量整改、标准统一、权限管理和 AI 应用反馈,才有真正的责任入口。最后从组织架构来看,一般可以分成四层:决策层负责定方向、批标准、给资源;管理层负责方案、制度、考核和跨部门协调;执行层负责平台建设、质量整改、接入清洗和规则维护;责任层则由各业务域负责人承担本域数据质量、口径、更新和业务价值责任。所以这一部分我想表达的核心是:数据治理真正难的不是技术,而是组织能不能形成合力。领导要支持,管理层要推动,执行层要落实,业务域要担责,平台要好用,人才要跟上。只有这样,数据治理才不会停留在方案里,而是能真正落到业务现场。
基本文件流程错误SQL调试
请求信息 : 2026-05-15 07:38:00 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/627231.html
 夜雨聆风
夜雨聆风