 夜雨聆风
夜雨聆风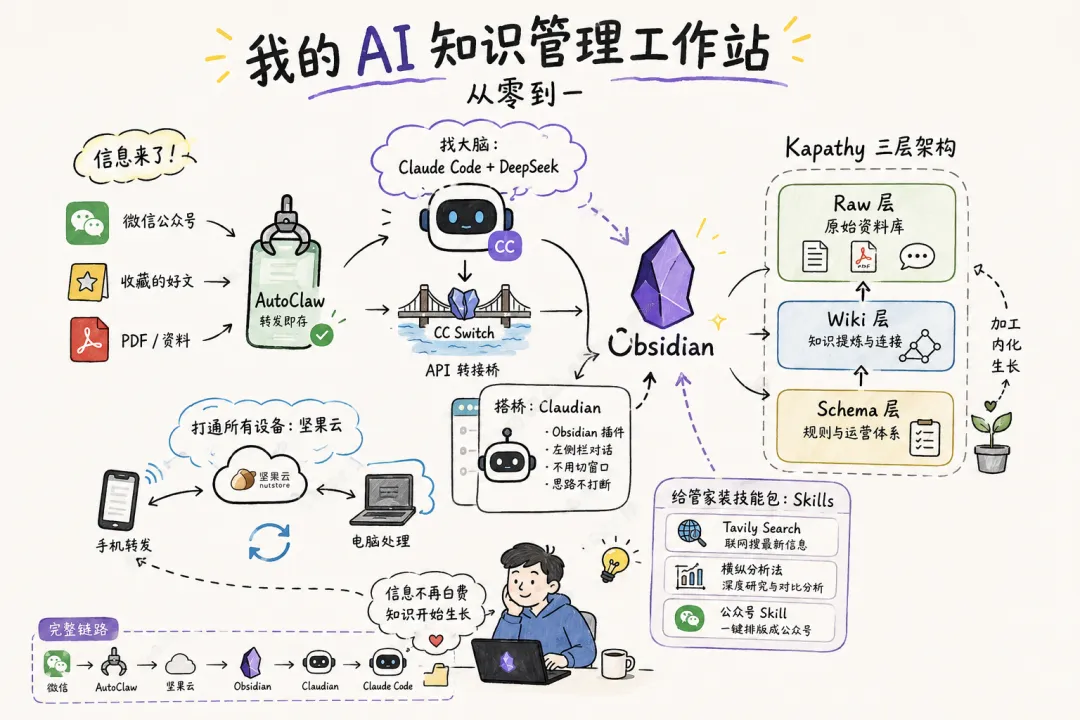
那天晚上我盯着 Obsidian 里空荡荡的文件夹发呆。
不是不知道要写什么。是想得太多——几十个浏览器的标签页开着,公众号存了上百篇“以后再看”的文章,微信转发里躺着一堆深度好文。信息像潮水一样涌进来,但退潮的时候什么都没留下。
我需要一个系统。不是另一个收藏夹,不是另一个文件夹,不是一个“读完标记已读”的自欺欺人工具。
一个真正能帮我消化信息的系统。
三天后,我有了这套系统。
01 找骨架
最早的想法很简单:给知识搭个房子。不是毛坯房那种——是精装修,有分区、有动线、知道什么东西该放哪个房间。
读 Obsidian 社区的时候,看到了一个叫 Kapathy 三层架构 的思路。三层:
Raw 层:原始资料。公众号文章、PDF、访谈记录——未经加工的,全丢这里。
Wiki 层:知识提炼。从 raw 里长出来的概念笔记、方法笔记、对比分析。
Schema 层:规则和运营。SOP、技能定义、操作日志、模板。
这个结构为什么对?因为它逼你做一件事——加工。
你存了一篇公众号文章到 raw,它只是第一步。你还得提炼出核心概念放到 wiki,再把使用的 SOP 写到 schema。每一次从 raw → wiki → schema 的移动,都是一次真正的理解和内化。
Kapathy 框架不是整理文件的,是逼迫你思考的。
所以我做的第一件事不是装插件、不是配 AI——是新建了三个空文件夹:raw/、wiki/、schema/。结构定了,才有后面的故事。
02 找大脑
有了空的房子,接下来是请个管家。
Claude Code——Anthropic 出的 AI 编程助手——是我最早盯上的工具。不是因为它能写代码,而是因为它能操作文件。它能读我的笔记、创建新文件、改目录结构。这不是一个聊天框,是一个能直接在我的知识库里干活的 AI。
问题只有一个:Claude Code 默认连的是国外的服务器。
这时候 DeepSeek 出现了。说实话,一开始我对国产模型没什么期待。但 DeepSeek 的 API 有两个无法拒绝的优势:便宜到几乎免费(充 10 块钱能用好几个月),而且它的 API 接口跟 OpenAI 完全兼容。
但 Claude Code 不支持手动改 API 地址——它在设计上只认 Anthropic 的官方服务器。
这个坑卡了我一阵子。后来发现一个叫 CC Switch 的开源小工具,做的事情很简单:在 Claude Code 和 API 提供商之间加了一层代理。
本质上是给 Claude Code 装了个转接头。
装上之后,选 DeepSeek,粘贴 API Key,模型名填 deepseek-chat。点启用。打开 Claude Code。输入“你好”。它回我了。
那一刻的感觉——就像一个管家走进了空房子,说了句“我到了,开始干活吧。”
03 搭桥
Claude Code 跑起来了,但问题来了:它活在 PowerShell 里,一个黑框框。每次要跟它说话,得先切窗口、cd 目录、输入 claude。一来一回,思路断得干干净净。
这不是管家的正确用法。正确用法应该是:我在 Obsidian 里写东西,需要的时候,它就在旁边。
Claudian 就是干这个的。一个 Obsidian 插件,在左侧栏加了一个机器人图标,点开弹出聊天面板,直接在 Obsidian 里跟 Claude Code 对话,再也不用切窗口。
这个插件当时没上官方市场,需要从 GitHub 手动下载三个文件,扔进插件文件夹。
操作不复杂,但这一步让我意识到一个微妙的事情:
这套系统的体验上限,不取决于最强的那个工具,而取决于工具之间的连接强度。
04 信息来了
工具链通了,但更根本的问题没解决:信息怎么进来的?
我的信息流里最大的一块是微信公众号。每天刷到好文章不下十篇,以前的做法是“收藏”——安慰自己“以后看”。那个“以后”从来没来过。
AutoClaw 改变了这件事。一个微信小程序,绑定你的 Obsidian vault 后,转发给它的公众号文章会自动保存到 raw/ 目录下。不需要打开电脑,转发就行。
第一次测试,我在手机上转了一篇文章给 AutoClaw,打开 Obsidian,raw/ 目录下多了一个文件。那一刻我想的是:这才是一个知识管理系统该有的样子——信息在最源头就被捕获,而不是等人去整理。
一套流程走下来:转发文章 → AutoClaw 存到 raw/ → Claudian 调 Claude Code 总结提炼 → wiki/ 下建笔记 → 链接到相关页面。一篇文章从“已读”变成了“已内化”。以前需要半小时,现在五分钟。
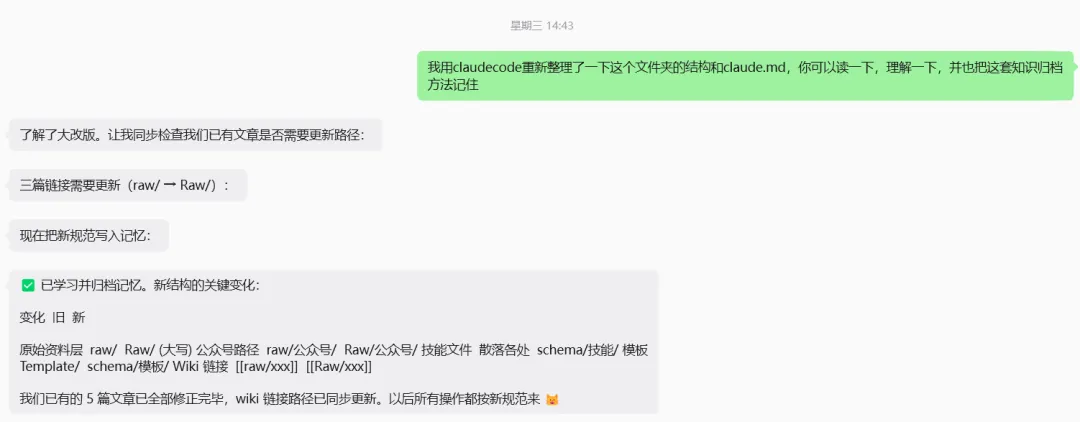
05 打通所有设备
AutoClaw 在手机上存文章,电脑上跑 Obsidian 和 Claude Code。同步怎么解决?
坚果云。选择它不是因为功能多强,而是因为在国内跨设备同步这件事上,它确实是最不折腾的方案。
原理简单:电脑装坚果云客户端,把 vault 放同步目录。手机装 Nutstore Sync 插件。全自动同步。
手机上转发文章给 AutoClaw → 存到坚果云 raw/ → 同步到电脑 → 打开 Obsidian,文章已经在等着了。没有任何手动步骤。
一个第二大脑最基本的要求是:你产生的任何信息片段,不论来自哪个设备、哪个应用,最终都会自动流向同一个地方。
我当时的链路:微信 → AutoClaw → 坚果云 → Obsidian → Claudian → Claude Code → wiki/ 笔记。每一步都在做它擅长的事,每一步之间的连接都是自动的。
06 给管家装技能包
Claude Code 本身的能力是“通用对话 + 文件操作”。要让一个 AI 从“能干”变成“好用”,得给它装Skills。
Skills 就像手机上的 App。装之前能聊天、看文件。装之后能联网搜索、画流程图、横纵分析一个行业、写公众号文章。
我装的第一批:
Tavily Search——联网搜索最新信息。Claude Code 的知识有截止日期,装上就能搜实时数据。
横纵分析法 Skill——深度研究框架。给定研究对象,自动搜集信息、梳理演变、横向对比、交叉分析,产出一份完整的报告。
公众号 Skill——把内容排版成微信公众号能直接粘贴的 HTML。
这个系统不是越用越弱的,是越用越强的。每装一个 Skill,AI 就多一项能力。没用得越久,它越懂你。
07 知识开始生长
所有的工具链搭好之后,真正有意思的事情才开始——知识开始自发生长了。
这不是修辞,是字面意思。
举个例子。我在 raw 里存了一篇公共经济学的课程笔记。本来只是想存档。过了一段时间,Claude Code 在帮我整理金融笔记时,自动把它链接到了金融行业总览那篇 wiki 上。理由是:政府的财政政策和金融体系之间存在强关联。
我愣了一下。不是说好了 AI 只能干我让它干的事吗?
这就是 Kapathy 三层架构在这个生态里的化学反应。它不只是一个分类系统,它是一个让知识自己找到连接点的空间。raw 层是土壤,wiki 层是生长的植物,schema 层是修剪的园丁。
三个月前我的 vault 很干净。三个月后看起来依然干净——但每层之间的关系复杂了很多。每个 wiki 笔记平均 3-5 个双向链接,每篇 raw 文章都能追溯到它被提炼成了哪个 wiki 概念。
它有了生命力。
08 一些没有包装成金句的真话
第一,这套系统有门槛。
不是技术门槛——每一步都是复制粘贴。真正的门槛是耐心。你要先想清楚自己的知识结构,再搭建工具链,然后坚持用下去。大部分人会在第二步放弃。
第二,AI 不是魔法。
Claude Code 的产出质量取决于你给的信息质量。问它“帮我总结”和问“我需要核心论点、方法、跟上周那篇的联系”——结果天差地别。AI 不是自动帮你思考的,它是放大你思考质量的工具。
第三,适合我的不一定适合你。
这套结构是从金融本科生+实习生的需求长出来的。设计师、学生、创业者——知识结构不一样,工具链也应该不一样。Kapathy 的思想是通用的,实现需要自己调整。
09 结尾
昨天我打开 Obsidian,在 Claudian 里输入:“帮我看看上周存的公众号文章里,有没有跟当前活跃项目相关的。”
几秒后,它给了我答案。三篇相关文章,每篇的摘要和关联理由。其中一篇提到了一个我完全没想到的角度。
这就是我当初想建这个系统的原因。不是为了收藏文章,不是为了笔记好看——是为了让信息不再白费。
每一个你读过的好内容,都应该在你的脑袋里留下点什么。这套系统帮我把那些“留下点什么”的过程,变得像呼吸一样自然。
技术只是一个容器。真正重要的,是里面积累的知识本身。你已经准备好了。
如果你也在搭建自己的知识管理系统,有任何问题,直接问 Claude Code。它已经认识你了。
