 夜雨聆风
夜雨聆风开篇
开发 Agent 时,单纯把 Context Window 开大,或者把历史对话塞进 RAG,往往无法很好地处理长期记忆。
正如 Mem0 官方博客所述:Context Window 更像 RAM,而不是 Storage。它适合承载当前推理,但不适合保存长期事实;一旦上下文变长,还会稀释模型注意力并增加 token 成本。
因此,这篇文章想回答的不是“Mem0 怎么用”,而是三个更基础的问题:
为什么 Agent 需要独立的 memory layer,而不是继续依赖 context window、RAG、用户画像或业务数据库? Mem0 为什么不只是“把聊天记录存进向量库”? 从源码看,Mem0 已经做了什么,还有哪些问题不能默认交给它解决?
1. 先明确:不是所有信息都应该叫 memory
很多团队说“给 Agent 加记忆”,其实想要的东西并不一样:
在一次长任务里不丢掉前面的约束。 记住用户偏好、项目背景和历史决策。 让多个 Agent 或多个应用共享用户上下文。 让企业可以审计、删除、授权和评估这些记忆。 让长期运行的 Agent 不被旧事实、重复事实和错误事实污染。
这些不是同一层问题。第一类更像 working memory;第二类才是 persistent memory;第三类开始进入平台化;第四类是治理;第五类是长期质量和时间语义。
Agent 运行时至少会接触四类信息:
这四类信息会同时进入 Agent,但不应该进入同一个系统。
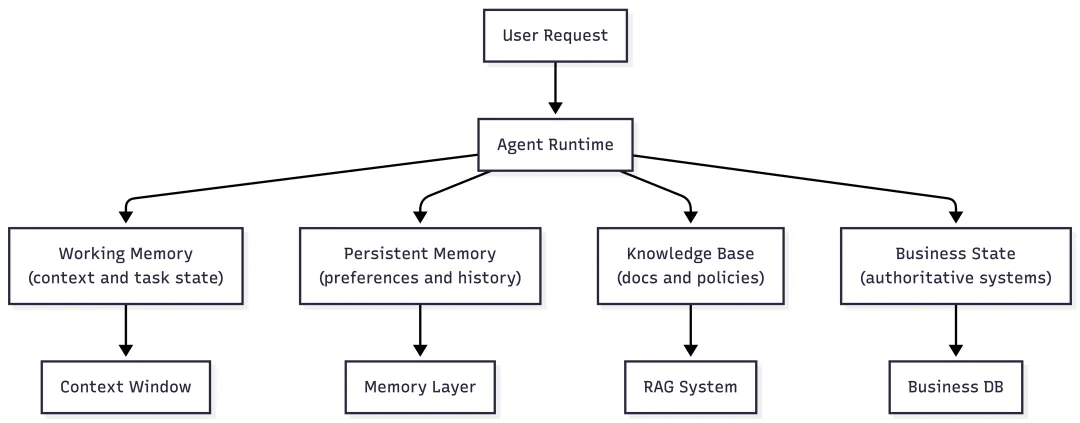
Mem0 的位置在 persistent memory。它和 RAG 都可能使用 embedding 和检索,但目的不同:RAG 解决“外部知识里哪段内容相关”;Mem0 解决“过去交互中哪些长期事实会影响当前 Agent 行为”。
用户画像也不能替代 memory。画像通常是强 schema、可统计的标签,例如城市、行业、会员等级;memory 更接近给模型使用的自然语言事实和历史证据,例如“用户上次明确说不希望看到过度营销文案”。
这个区分很重要。如果把所有东西都写进 Mem0,会很快遇到三个问题:
把临时上下文长期化,导致记忆污染。 把业务数据库中的权威状态复制成自然语言,导致事实分叉。 把知识库文档和用户交互事实混在一起,导致权限和生命周期混乱。
所以,Mem0 不应该“什么都记”。更好的标准是:只记那些未来 Agent 行为需要、且不应只存在于单次上下文中的信息。
2. Mem0 的核心架构与设计取舍
在深入探讨设计细节之前,我们先在脑海中建立一个 Mem0 的大体轮廓。
从最宏观的视角来看,Mem0(特指其开源 SDK)提供了一个统一的 Memory 实例作为 Memory Kernel。对外,它主要暴露出两个核心动作:
读(
search/get):在 Agent 执行新任务时,根据当前上下文、用户 ID 和 Agent ID,召回相关的长期事实。写(
add/update):在 Agent 交互过程中,把自然语言对话转化为结构化的长期记忆存下来。
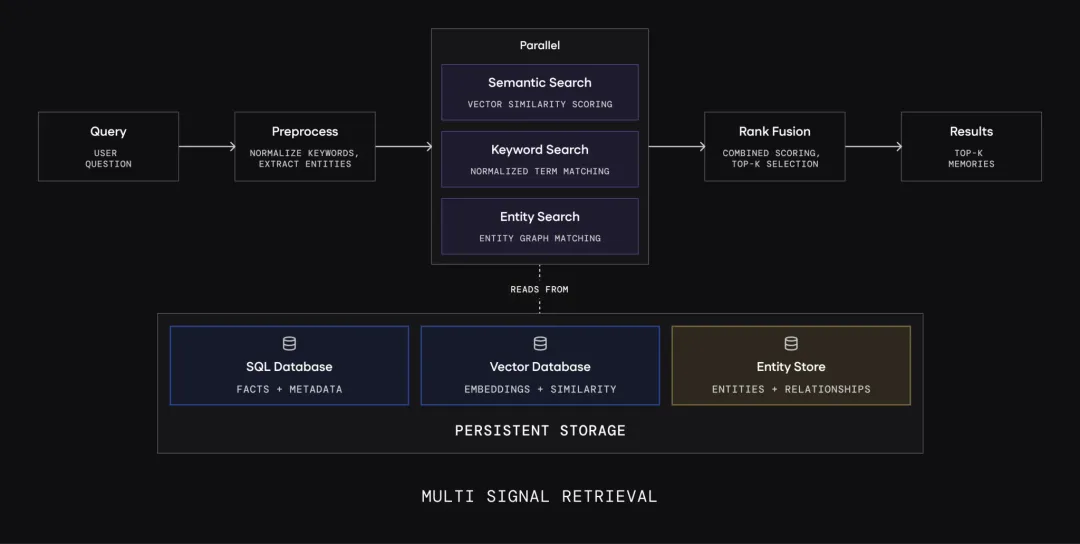

而在内部,它并不是单纯地“把文本丢进向量库”,而是编排了一套多组件协作的流水线:LLM 负责从杂乱的对话中抽取和提炼事实,Embedding 和 Vector Store 负责向量化和语义检索,Entity Store 负责实体链接加权,SQLite 负责保存最近的会话状态以供大模型参考。
接下来,我们看 Mem0 在具体策略上做出的几个关键设计取舍。
2.1 ADD-only extraction:保留演化,而不是覆盖状态
Mem0 2026 算法的核心变化之一是 single-pass ADD-only extraction。旧思路通常是让 LLM 对新信息和旧 memory 做 reconcile,决定 ADD、UPDATE、DELETE。新思路是只 ADD:新事实作为新 memory 进入系统,旧事实不因为新事实出现而被删除。Introducing The Token-Efficient Memory Algorithm
这不是功能倒退,而是一个取舍。
如果用户过去住在 New York,现在搬到 San Francisco,覆盖旧事实会让“用户现在住在哪里”更容易回答,但会丢掉“用户从哪里搬来”“什么时候变化”“为什么变化”这些长期上下文。ADD-only 保留了历史演化,因此更适合长期 Agent、审计和多会话推理。
代价是:当前真值不再天然等于 top-1 memory。应用层或平台层必须有 resolver。否则 Agent 可能同时拿到旧事实和新事实,然后临场猜测。
ADD-only 可以理解成四点:
它让 memory 更像 event log,而不是 mutable profile。 它提高了历史解释能力。 它把“当前状态解析”从写入时覆盖,转移到读取时解析。 它要求内部平台补 state_key、timestamp-aware resolution、权威系统校验等能力。
这也是为什么公司内部不能只部署 Mem0 就认为解决了 memory 问题。Mem0 保存历史,平台要解释历史。
2.2 Agent-generated facts:记住 Agent 做过什么
Mem0 新算法强调 agent-generated facts are first-class。也就是说,不只是用户说的话值得记,Agent 的确认、建议、执行结果和计划也可能成为未来上下文。State of AI Agent Memory 2026
这对内部 Agent 平台很重要。例如:
代码助手曾判断某个模块的测试命令是什么。 客服 Agent 曾向用户承诺下次跟进某个问题。 运维 Agent 曾确认某个告警是误报。 销售 Agent 曾推荐过某个方案,并记录客户反馈。
如果这些内容不进入 memory,Agent 下次就只能依赖业务系统或用户重复说明。但如果它们进入 memory,又必须区分来源。用户明确陈述、Agent 推断、工具返回、人工审核的可信度不同。因此内部平台需要 provenance 字段,例如 source_type、source_actor、source_app、evidence_ref、confidence。
Mem0 让 agent-generated facts 能被记住;企业平台要让它们被正确解释。
2.3 Multi-signal retrieval:语义相似度不够
纯向量检索在 demo 中表现不错,但长期 memory 会遇到三个问题:
两条语义非常相似的 memory,只有时间或状态不同。 查询中有专有名词、项目名、工单号、客户名,embedding 未必足够精确。 多条 memory 通过同一实体关联,但文本表达不相似。
所以 Mem0 新检索栈融合 semantic similarity、keyword matching 和 entity matching。State of AI Agent Memory 2026
从本地源码看,Python OSS Memory.search() 会做 query lemmatization、entity extraction、query embedding、semantic over-fetch、可选 keyword search、entity boost、score fusion 和可选 reranker。它不是“向量库查 top_k 后返回”。
这里的判断是:memory retrieval 不只是在找“语义最近”,而是在找“对当前 Agent 决策最有用”。有时靠语义,有时靠关键词,有时靠实体,有时还要看时间和状态。multi-signal retrieval 给后续演进留下了空间。
2.4 Entity linking:降低部署复杂度,但不是完整图谱
Mem0 的 2026 文章提到,新的 OSS 算法从外部 graph memory 转向 built-in entity linking。写入时抽取实体,存入 {collection}_entities;查询时抽取 query 实体,命中后给相关 memory 加权。State of AI Agent Memory 2026
这个设计的好处是部署简单。self-hosted 用户不一定需要先搭 Neo4j 或 Neptune 才能获得 entity-aware retrieval。
但代价也很明确:它不是可查询的关系图。它能帮助排序,但不能自然支持“沿关系多跳遍历”“展示实体关系网络”“从组织结构推导可见性”。
所以内部如果需要知识图谱或业务实体网络,应该把 Mem0 entity linking 看作 retrieval boost,而不是图数据库替代品。可以让实体图和 memory id 建立引用关系,但不要把 entity collection 误当作完整 graph layer。
2.5 Provider architecture:让 memory kernel 不绑定供应商
Mem0 的 provider 体系把 LLM、embedding、vector store、reranker 都抽象成可替换实现。对 self-hosted 二次开发来说,这不是普通扩展点,而是采用 Mem0 的前提。
公司内部通常有自己的模型网关、embedding 服务、向量检索基础设施、安全策略和日志系统。如果 Mem0 的 memory kernel 与 OpenAI、某个向量库或某个部署方式强绑定,就很难进入企业内部。Provider architecture 的意义是把 memory 逻辑和基础设施供应商解耦。
内部改造可以按这个顺序推进:
接内部 LLM provider。 接内部 embedding provider。 接内部 vector store 或选定标准后端。 再考虑 reranker、decay、temporal metadata 等增强。
这比直接修改 Memory.add() 或 Memory.search() 更稳妥,也更利于后续跟进上游。
3. 源码里的 self-hosted:Mem0 到底做了什么
看 Mem0 self-hosted,最该读的是 mem0/memory/main.py。Memory 不是一个普通 CRUD class,它是一个 orchestrator:初始化时通过 factory 创建 LLM、embedding、vector store、SQLite history 和可选 reranker;entity store 则在第一次用到时懒加载,collection 名通常是主 collection 加 _entities 后缀。
这也解释了为什么 Mem0 适合做 kernel。它把“记忆”拆成几件事:LLM 负责抽取,embedding 负责表示,vector store 负责存和搜,SQLite 记录 history 和最近消息,entity store 做召回增强。
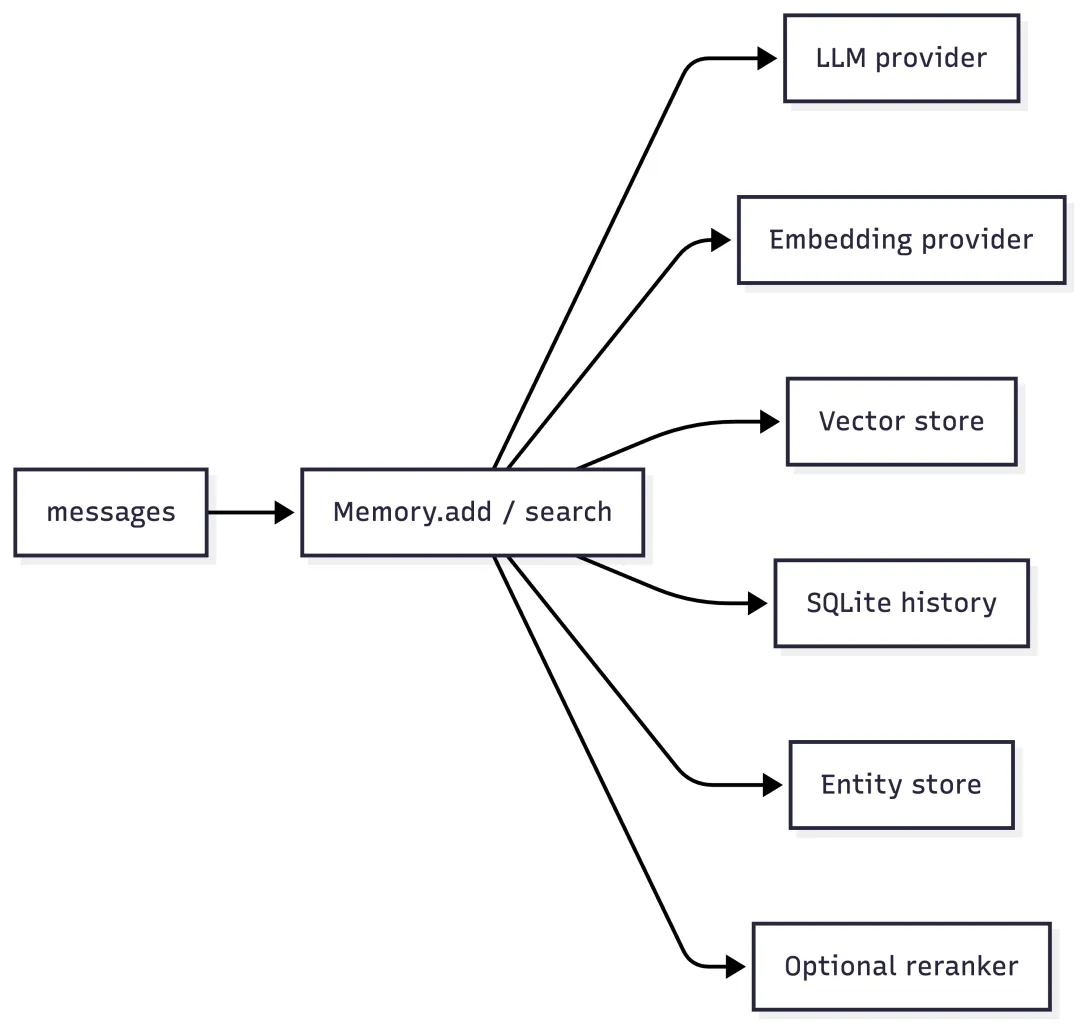
3.1 Memory.add():不是保存对话,而是抽取 memory
Memory.add() 对外看只是一个写接口,内部逻辑比“insert 一条向量”复杂得多。
第一步是确定 scope。代码会把 user_id、agent_id、run_id 写入 metadata 和 filters,并要求至少提供一个。也就是说,Mem0 OSS 已经有基本的 session scope,但它只校验“有没有传”,不会替你判断调用方是否真的有权限使用这个 scope。这也是为什么企业内部还需要 Gateway。
第二步是处理输入。messages 可以是字符串、单条 dict 或 list;字符串会转成 {"role": "user", "content": ...}。普通事实类 memory 会进入 _add_to_vector_store();如果传的是 procedural memory,并且有 agent_id,会走单独的 procedural memory 创建链路。
写入 pipeline 可以简化成这样:
messages -> parse and normalize -> load recent session messages -> search related existing memories -> ask LLM to extract additive memories -> batch embed extracted memory text -> hash dedup -> write vector records -> write ADD history -> extract entities and link entity -> memory ids -> save recent messages这里有几个细节值得注意。
首先,它会从 SQLite 读最近的 session messages,再从 vector store 搜相关旧 memory。这两类上下文会一起交给 LLM:前者补最近对话,后者减少重复抽取。
其次,当前主链路是 additive extraction。代码使用 additive extraction prompt,要求 LLM 返回 JSON,里面是要新增的 memory。旧 memory 会以短 ID 映射形式传给模型,实际 UUID 不直接暴露给 LLM,降低模型编造 ID 的风险。
第三,写入前会做两层去重:一层和已检索到的旧 memory 比 hash,一层在当前 batch 内比 hash。去重是精确文本去重,不是语义去重;相近但表述不同的事实仍可能同时存在。
第四,每条 memory 的 payload 不只是文本。常见字段包括:
data | |
text_lemmatized | |
hash | |
created_atupdated_at | |
user_idagent_id / run_id | |
attributed_to | |
第五,entity linking 是写入链路的一部分。Mem0 会对每条新 memory 抽实体,对实体批量 embedding,然后在 entity collection 中搜索相近实体。如果命中,就把新的 memory id 合并到 linked_memory_ids;如果没命中,就新建 entity 记录。
所以,Memory.add() 的重点不是“保存消息”,而是把消息变成一组可检索、可解释、可关联的长期事实。它已经具备 memory kernel 的样子,但还缺企业平台需要的写入策略、敏感信息拦截、审批和权限判断。
3.2 Memory.search():不是向量 top-k,而是多信号排序
Memory.search() 也比普通向量检索多一层。新版接口要求 user_id、agent_id、run_id 放在 filters 里;随后会校验 threshold 和 top_k,并要求 filters 至少包含一个 scope 字段。
它还支持一层 metadata filter 处理,例如 eq、ne、in、gt、contains、AND、OR、NOT。不过这里要看具体 vector store provider 是否完整支持这些过滤能力,不能只看 Memory.search() 的参数说明。
核心检索在 _search_vector_store(),流程如下:
query -> lemmatize query for BM25 -> extract query entities -> embed query -> semantic search with over-fetch -> keyword_search if provider supports it -> normalize BM25 scores -> search entity store and compute boosts -> score_and_rank -> format MemoryItem results -> optional rerank几个实现细节决定了它和普通向量检索不一样。
第一,semantic search 会 over-fetch。调用方只要较少结果时,底层也会先拿更大的候选池,再做融合排序。这是为了给 BM25 和 entity boost 留空间。
第二,keyword search 是可选能力。vector_store.keyword_search() 如果返回结果,就会把原始 BM25 分数归一化。这个能力是否可用,取决于具体 provider。
第三,entity boost 来自单独的 entity store。查询先抽实体,再去 entity collection 搜索相近实体。命中的 entity 会把 boost 分配给它关联的 linked_memory_ids。如果一个 entity 关联太多 memory,boost 会衰减,避免“大实体”把排序冲掉。
第四,最终分数不是复杂模型,而是加权归一。语义相似度仍是门槛,keyword 和 entity 更像排序增强。
第五,reranker 是 search 入口之后的可选步骤。只有调用方传 rerank=True,并且配置了 reranker provider,才会对结果再排一次。默认路径并不会自动 rerank。
这套设计很务实:先用 vector store 做候选池,再用 keyword 和 entity 补召回/排序,最后按需要接 reranker。它还不是完整的 temporal reasoning,也没有把 access history decay 融入排序,但已经不是简单 top-k vector search。
3.3 server/:可用,但不是企业 Gateway
server/ 是 self-hosted FastAPI wrapper。它启动时构造全局 Memory 实例,默认配置走 pgvector + OpenAI,并通过 HTTP 暴露 add/search/get/update/delete/configure 等接口。新版 server 已经有 JWT、API key、rate limit、request log、配置脱敏等基础能力。
但它仍不等于企业内部 Gateway。企业 Gateway 还需要把内部 IAM、租户、应用、数据分类、审计、限流、灰度、错误码和业务策略接进来。尤其是 scope 不能由调用方随意传,应该由服务端从认证上下文推导。
3.4 OpenMemory:平台化参考,不是最终答案
openmemory/ 更接近产品化平台。它在底层 Mem0 Memory 之外维护用户、应用、ACL、memory 状态、access log 和 MCP server。它说明 Mem0 团队也把 kernel 和 platform 分开看。
但 OpenMemory 更偏本地工具和 MCP 生态。公司内部可以参考它的数据模型和 UI 组织方式,但仍要接自己的 IAM、审计、数据安全和业务应用管理。
3.5 Hosted 能力不能直接等同 OSS 能力
官方博客中的 Memory Decay 和 Temporal Reasoning 是重要方向,但 self-hosted 采用时必须逐项核对。
例如,Memory Decay 文章描述了 search-time access history rerank:最近访问的 memory 最高 1.5x,长期 idle 的 memory 最低 0.3x,并异步记录访问历史。Memory Decay for Long-Running Agents
但从当前 Python OSS Memory.search() 看,主链路没有完整读写 access timestamps,也没有把 decay factor 乘进 score fusion。Hosted client 暴露 project 级 decay 字段,不等于 self-hosted OSS 打开配置即可获得同等能力。
Temporal Reasoning 同理。文章描述了 time signature、memory type、state key、temporal intent 和 temporal rerank。Introducing Temporal Reasoning in Mem0 这些能力对内部很重要,但需要按源码确认 OSS 的落地程度,并可能在平台层自建。
更稳妥的说法是:
Hosted platform 的方向可以作为内部试点的设计参考,但不能默认认为 self-hosted OSS 打开配置就能获得同等效果。
4. 从源码看当前能力边界
把上面的源码分析压缩成一张表,Mem0 OSS 更像 memory kernel,而不是完整企业平台。
Memory.add() | ||
Memory.add() | ||
_entities collection | ||
server/ | ||
openmemory/ | ||
evaluation/ |
这张表的核心不是说 Mem0 不够,而是明确它适合承担哪一层:Mem0 OSS 更像 memory kernel;企业级 memory platform 需要在它外面补工程和治理能力。
5. 总结
基于源码阅读,Mem0 OSS 的价值主要在于:它已经提供了一个相对完整的 memory kernel,把长期事实抽取、多信号检索、entity linking、provider 扩展和 history 组织到了一起。它比“向量库存聊天记录”更进一步。
但企业内部真正要解决的不只是“怎么把 memory 存起来、搜出来”。还要回答几个更现实的问题:谁可以写 memory,谁可以读 memory,哪些信息不能被记住,旧信息和新信息冲突时信谁,以及这套 memory 到底有没有让业务效果变好。
参考资料
State of AI Agent Memory 2026 Introducing The Token-Efficient Memory Algorithm Introducing Temporal Reasoning in Mem0 Memory Decay for Long-Running Agents Context Window Behaves Like RAM, Not Storage Introducing OpenMemory MCP
