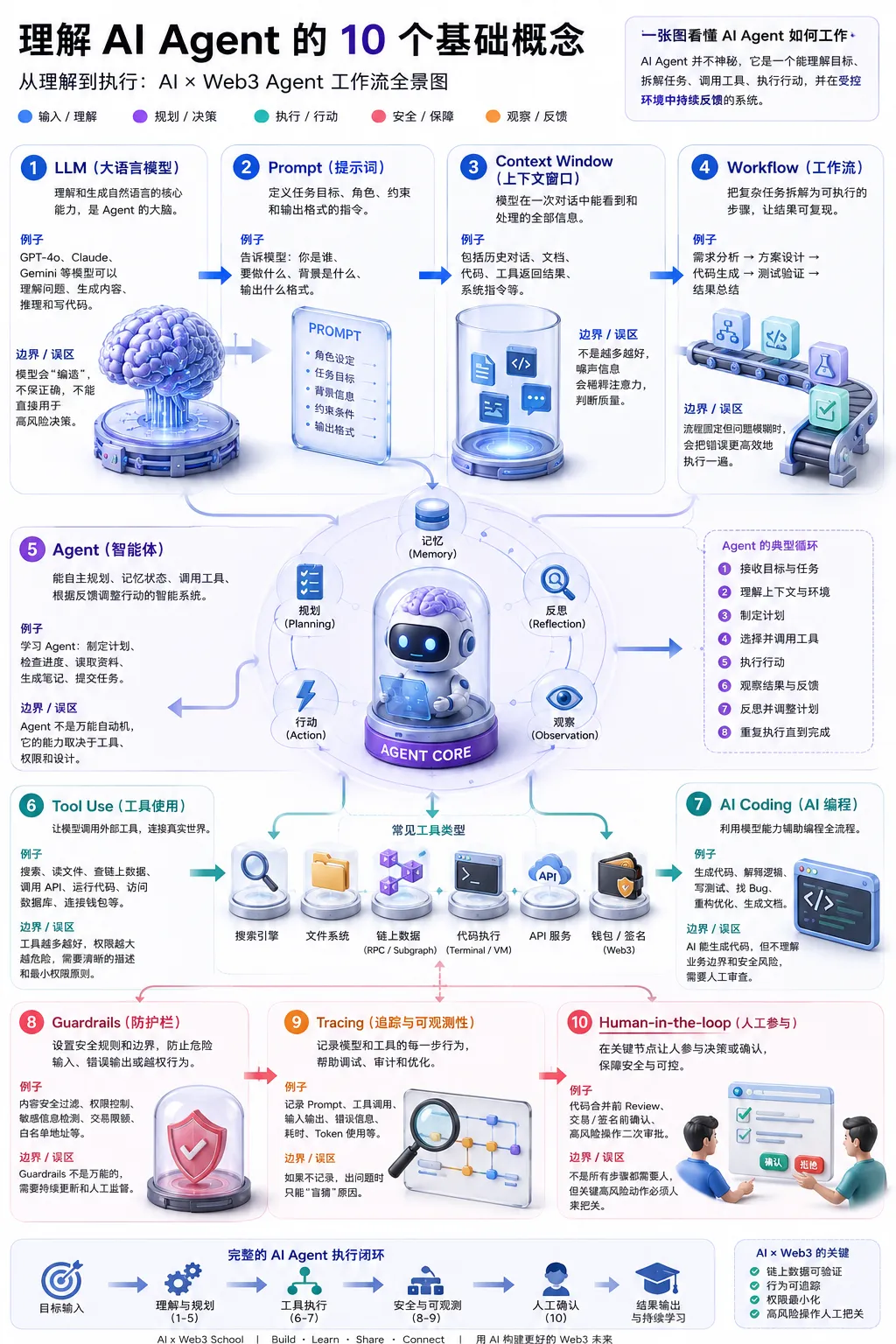
很多人说自己在学 AI,其实学的是工具使用。我一开始也是这样。会用 ChatGPT,能写 prompt,能让 AI 帮我改代码、整理文档、生成方案,就觉得自己已经开始理解 AI 了。但越往后学,我越明显地发现,真正让我卡住的不是工具怎么用,而是一些基础概念之间的关系,我其实没有完全想明白。比如 LLM 到底是不是一个更聪明的聊天机器人?Prompt 是不是写得越长越好?Agent 和 workflow 的区别在哪里?工具调用为什么会成为 AI Agent 的核心能力?如果 AI 接入钱包、签名、链上操作,它的权限边界又应该怎么设计?这些问题如果只从 AI 角度看,可能会有点抽象。但从 Web3 开发者的视角看,它们会突然变得很具体。因为 Web3 系统里有钱包、有签名、有资产、有权限、有链上记录。AI 一旦从“回答问题”走向“帮用户执行操作”,它就不再只是聊天窗口,而可能成为系统流程里的执行者。所以我现在越来越觉得,学 AI Agent 之前,最该先听懂的不是某一个很酷的框架,而是一些底层概念。它们会决定我们后面怎么看 Agent、workflow、AI Coding、链上自动化,以及 AI × Web3 的系统设计。
LLM 自己不会真的查链上数据,也不会真的跑代码、查余额、读合约状态。它需要工具。工具可以是搜索引擎、数据库、区块链 RPC、钱包 SDK,也可以是一个后端接口。这就是 tool use 的意义:让 AI 不只停留在语言层面,而是能连接外部系统,获得真实数据,并在一定规则下完成任务。比如一个 AI 钱包助手,如果没有工具,它只能解释什么是 approve。但如果它接入了链上工具,就可以帮你查你授权了哪些合约、授权额度是多少、最近有没有可疑交互、某个合约是否有风险特征、是否需要取消授权。不过,接入工具不代表结果一定准确。工具只是提供能力,不代表系统一定可靠。如果工具数据源不可信,或者 AI 错误理解了工具返回结果,仍然会出错。所以 tool use 的重点不是“能调用”,而是调用什么工具、什么时候调用、如何校验结果、失败时怎么处理,以及哪些步骤必须回到用户确认。这也是为什么 AI Agent 的难点不只在模型,而在工程系统设计。
07|AI Coding 不是替你写代码,而是参与工程协作
我以前也会把 AI Coding 简单理解成“让 AI 帮我写代码”。但现在我觉得这个理解太窄了。真正有价值的 AI Coding,不是让 AI 一次性生成一大坨代码,而是让它参与完整的开发流程。比如帮我读懂一个陌生模块,帮我梳理某个 hook 的数据流,帮我根据现有项目风格补一个组件,帮我检查类型是否严谨,帮我判断合约有没有权限漏洞,帮我把 PRD 拆成可执行任务,或者帮我写测试用例覆盖边界情况。对 Solidity 和 React 项目来说,AI Coding 最有用的地方往往不是从零生成,而是在已有项目中按规则修改。因为真实项目里最难的不是写出一段能跑的代码,而是让它符合当前架构、类型约束、业务逻辑和安全边界。这里也有一个很容易踩的坑:完全相信 AI 生成的代码。尤其是合约代码,不能因为它看起来很像 OpenZeppelin 风格就直接用。权限、签名、nonce、防重放、资金流向、边界条件,都需要人工 review。我现在更倾向于把 AI 当成一个很强的 junior teammate。它可以很快给我草稿、思路和检查方向,但最终判断必须由开发者自己负责。
08|Guardrails 不是限制能力,而是定义系统边界
如果说 Agent 代表能力,那么 guardrails 代表边界。AI 系统越能做事,越需要清晰的边界。否则它越强,风险也越大。比如一个 Web3 AI 助手,可以帮用户分析交易,但不能直接替用户签名;可以提醒风险,但不能保证某个项目“绝对安全”;可以构造交易参数,但必须展示给用户确认;可以调用工具,但不能偷偷读取用户没有授权的数据。这不是限制 AI 发挥,而是让系统变得可上线、可使用、可被信任。尤其在钱包、资产、身份、权限相关场景里,guardrails 不是锦上添花,而是系统设计的一部分。一个 AI 钱包助手至少应该遵守这些边界:不接触私钥,不自动签名,不隐藏交易风险,不默认扩大授权额度,不把模拟结果当成最终成功,不替用户做不可逆资产操作。这些规则看起来保守,但它们决定了系统是否值得被信任。AI Agent 如果要进入真实产品,能力和边界必须一起设计,而不是先把功能做出来,出问题后再补安全规则。
09|没有 Tracing 的 Agent,本质上还是黑箱
普通聊天里,我们可能只关心最后答案。但 Agent 系统里,只看最后答案远远不够。因为你需要知道它为什么做这个判断,调用了哪些工具,工具返回了什么,中间有没有失败,有没有误解用户意图,有没有越权调用。这就是 tracing 的价值。它记录 AI 系统每一步做了什么、为什么做、调用了什么工具、得到什么结果,让整个执行过程可以被复盘。在 Web3 场景里,这个概念更关键。链上交易本身是可追踪的,但 AI 的推理过程和工具调用如果没有记录,就会变成黑箱。比如一个 AI Agent 帮用户完成一次自动化操作,最后交易失败了。你不能只告诉用户“失败了”,而是要知道失败发生在哪一步:是钱包未连接,网络不对,签名过期,nonce 错误,合约 revert,还是 RPC 节点返回异常。所以 tracing 不只是方便 debug,它也是信任机制的一部分。如果我们真的想做可信的 AI × Web3 系统,就不能只记录最终结果,而要记录关键过程。
10|Human-in-the-loop 是关键节点的人类确认
做自动化的时候,很多人会觉得最好完全不需要人参与。但在高风险场景里,人类确认不是落后,也不是低效,而是必要的系统设计。AI 可以帮用户分析一笔交易,比如调用的合约是什么,转出的资产是什么,授权额度是多少,是否涉及无限授权,是否存在高风险函数,模拟执行结果如何。但最后是否签名,应该由用户决定。这就是 human-in-the-loop。它指的是在 AI 系统流程中,保留人的判断、确认或干预。尤其在 Web3 里,这个机制非常自然,因为钱包签名本身就是一个人类确认节点。我不太相信“只要 AI 足够聪明,就可以把人完全拿掉”。至少在资产、权限和身份相关场景里,好的系统不是让人消失,而是让人在关键地方出现。AI 负责处理复杂信息,工具负责获取真实数据,workflow 负责组织流程,guardrails 负责限制边界,human-in-the-loop 负责关键决策。它们组合起来,才更接近一个可靠的 Agent 系统。如果把这 10 个概念拆开看,它们好像都是 AI 入门词汇:LLM、prompt、context window、workflow、agent、tool use、AI coding、guardrails、tracing、human-in-the-loop。但如果把它们放到 AI × Web3 的场景里,它们会组成一套完整的系统语言。Prompt 定义任务,context 提供信息,workflow 拆解流程,agent 判断下一步,tool use 获取真实数据,guardrails 限制越权,tracing 记录过程,human-in-the-loop 保留关键确认。
最后
我是 yoona,区块链技术专业出身,一名正在系统学习 AI 的开发者。我想把自己学到的知识,尽量放回真实项目和开发场景里去理解。接下来,我会继续记录自己学习 AI 的过程,也会分享我对 Web3 技术、AI 工具和 Agent 系统设计的一些观察和理解。
欢迎大家一起交流学习呀~
基本文件流程错误SQL调试
请求信息 : 2026-05-22 15:47:31 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/648765.html
 夜雨聆风
夜雨聆风