 夜雨聆风
夜雨聆风一、一个常见的误解
如果你在科技媒体上随手搜"Physical AI",会读到大量"AI + 机器人"的合并表述。某某公司发布了一台会跳舞的人形,某某厂商在仓库里部署了带 AI 视觉的拣选机械臂——这一类故事,都被打上"Physical AI"的标签。
听起来合理。但仔细看,会发现一个奇怪的现象:1990 年代就有的工厂机械臂,今天换上一个 YOLO 模型做缺陷检测,也叫"Physical AI"。2010 年代家用扫地机器人,加一个语音识别接 ChatGPT,也叫"Physical AI"。
如果"Physical AI"这个标签可以同时盖在 1995 年的电焊机器人和 2026 年的 π*0.6 上,它的信息量就近乎为零。
所以这一讲我想先从相反的方向开始——不是去问"什么是 Physical AI",是去问"什么不是"。
工厂里那台焊枪机器人不是。它的"AI"是事后贴的——核心控制逻辑还是按照工程师写好的轨迹运行。扫地机器人加 ChatGPT 也不是。语言模型在回答"你扫了几遍",但扫地的策略本身没变。

▲ 不是任何带 AI 的机器人都是 Physical AI,区别在哪儿,这一讲讲清楚
一个有趣的对照例:2023 年初波士顿动力 Atlas 那段在工地上跳跃、扔工具的视频惊艳全网。但这段视频的核心算法,公司自己讲得很清楚——是 MPC(model predictive control,模型预测控制)配合精心建模的动力学,每个动作是工程师把模型预测组合出来的。这里头 也许 也用了一些学习模块,但骨干仍然是经典控制论。它聪明,但它没有那种"在新工地上自己学新动作"的能力。换一个工地,它需要工程师重新调参。
而同一年,Physical Intelligence 的 π0 训练完之后,能去一个它从未见过的实验室、抓一个它从未见过的杯子、做一个它没被专门教过的任务。一个能跳过去,一个能学新东西。
外行看会觉得是同一件事——都是机器人在动。但学界把这两件事划在不同的世界里。
那么,Physical AI 的真正定义是什么?
二、三个必要条件
我用三个条件来界定 Physical AI。三个条件缺一不可——少了任何一个,都退化到别的东西。
条件一,它感知的是真正的物理世界。这听起来废话,但其实有讲究。物理世界的感知有三个特征:连续的(不是离散符号)、有噪声的(不是干净像素)、部分可观的(你看不到桌子背面)。一个聊天机器人接 描述 物理世界的文字("杯子在桌上"),不算。它面对的是 token,不是 photon。
条件二,它对因果和物理约束有内部表征。这一条最容易被忽略。机器抓一个杯子,它必须 理解 "杯子比手柄重就会翻"、"水洒了会顺着坡流下去"——这是物理因果。光靠图像识别+模式匹配过不去。这是为什么世界模型这条线这两年突然热起来——研究者发现,VLA 单纯靠模仿学习训出来的策略,遇到没见过的物理情景就崩,必须给它装个"想象引擎",让它在头脑里先推演一遍。
条件三,它产生可执行的、影响物理状态的动作。注意"可执行"和"影响物理状态"两层。一个推理模型输出"请把杯子放到水槽里"——这只是描述,不是动作。一个 VLA 输出一连串关节角度和力矩控制——这才是动作。说话不算物理 AI。说话让另一个东西去做事,也不算。只有当 AI 本身的输出直接驱动了物理状态的变化,才叫 Physical AI。
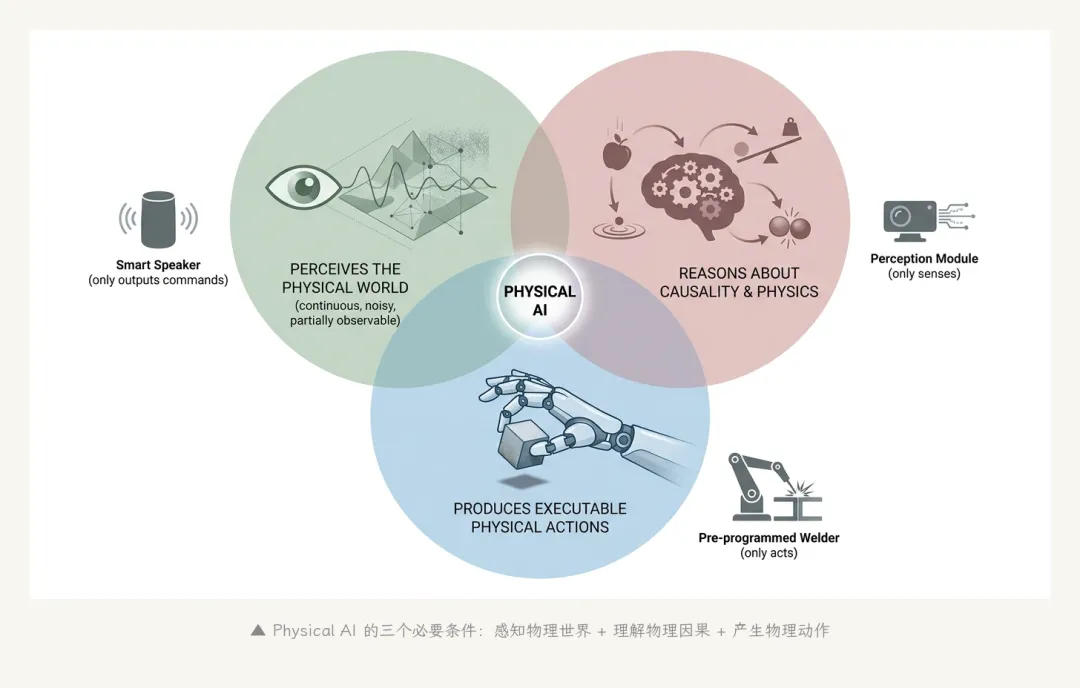
▲ Physical AI 的三个必要条件:感知物理世界 + 理解物理因果 + 产生物理动作
把这三条加在一起,就有了一个相对干净的判断标准。
反例 1:智能音箱控制家电。它感知的是语音(信息),它输出的是指令(信息),具体的物理动作由空调、电视、灯泡分别执行。AI 没有直接和物理状态耦合。这不是 Physical AI——这是 IoT + LLM。
反例 2:自动驾驶的感知模块。它感知物理世界(条件一满足),但它只输出"前方有行人"这种符号信号(条件三不满足——动作交给下游 planner)。这是 Physical AI 的 组件,不是完整的 Physical AI 系统。
反例 3:工厂的预编程焊接机械臂。它产生物理动作(条件三满足),但它不感知世界(条件一只是局部满足)、不理解因果(条件二完全不满足)。这是经典工业机器人,不是 Physical AI。
正例:π*0.6 在真实家庭里折衣服。它感知衣服的形状、皱褶、阻尼(条件一);它推理"先抓领口对折,会比从中间对折更稳"(条件二);它的策略输出直接驱动机械手指的每一个关节(条件三)。完整闭环。这是 Physical AI 的当前标杆。
三、和几个相邻概念的边界
我们再用三条边界,把 Physical AI 和它最容易被混淆的几个邻居切开。
Physical AI vs 经典机器人学(Robotics)。
机器人学有几十年历史,它的核心范式是"建模 + 控制"。给定一台机器,先建立运动学模型、动力学模型,再设计一个控制器去跟踪期望轨迹。MPC、PID、运动规划——这一套语言体系成熟到每年的 ICRA 大会都收近两千篇论文(2024 年 1765 篇)。
Physical AI 的核心范式不一样。它的核心是 学习——用神经网络从数据里拟合策略,而不是从模型里推导策略。经典机器人学是给定模型求解,Physical AI 是给定数据学习。
这个差别在工程上影响巨大。经典机器人学需要工程师亲手把环境建模——这就是为什么换一台机器就要从头调;Physical AI 需要数据——但同一个模型可以驱动多种机器(这就是"跨形态泛化"的来源)。
需要补一句:现实里两者并不互斥,最强的系统往往把两者结合——上层用 VLA 做高层决策,下层用经典控制器做关节级跟踪。GR00T 的 dual-system 架构、Figure Helix 的 S1/S2 架构,都是这个思路。
Physical AI vs 具身智能(Embodied AI)。
这两个词在中文圈基本是同义词,区别更多是用语习惯:
- "具身智能"是学术界更习惯的术语,源自 1980-90 年代认知科学和机器人学的 embodied cognition 传统——Rodney Brooks、Lakoff、Varela 那一拨人讨论"智能必须有身体"的哲学命题。
- "Physical AI"是黄仁勋 2024-2025 之后推热的工业用语,强调产业化、商业化、跨形态。
学术圈讨论一个 GR00T 这样的人形机器人通用大脑,更习惯说"具身智能模型"。工业圈讨论同一个东西,更习惯说"Physical AI 解决方案"。两者覆盖范围 95% 重合。如果有差别,那就是"Physical AI"显得更工程、更产品、更落地,"具身智能"更哲学、更研究、更广义。
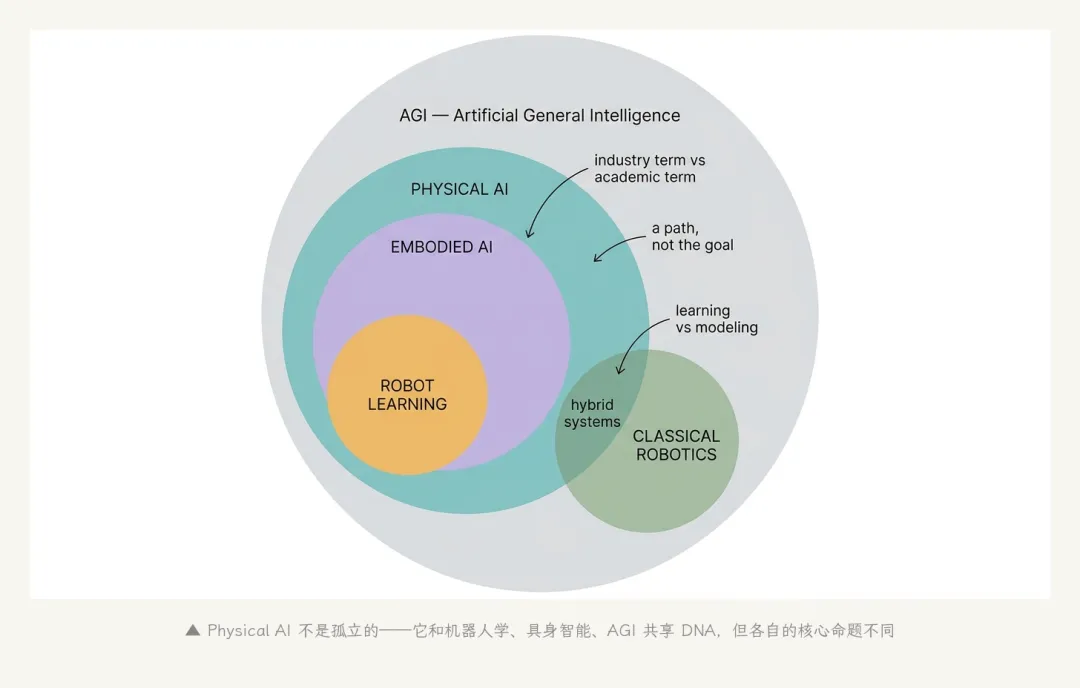
▲ Physical AI 不是孤立的——它和机器人学、具身智能、AGI 共享 DNA,但各自的核心命题不同
Physical AI vs AGI / Embodied AGI。
AGI(通用人工智能)是终极目标——一台机器具备人类所有的认知能力。Physical AI 是 通往 AGI 的一条具体路径——而且是越来越多人认为的"主路径"。
为什么?因为 LeCun、Bengio、Hassabis 都在一个判断上趋于一致:仅靠互联网文本无法训出 AGI——它学到的是"关于世界的描述",而不是"世界本身"。要训出真正的智能,AI 必须在物理世界里 亲自试错。这就把 AGI 和 Physical AI 接到了一起。
但 Physical AI 不等于 AGI。一台能在工厂里 24 小时拧螺丝的 Physical AI 是 Physical AI,但不是 AGI——它不会写诗,不会编程,不会做数学。两者交集很大,但不能划等号。
Physical AI vs Robot Learning。
Robot Learning 是机器人学里的一个分支学科,名字里就带"学习"——它是 Physical AI 在学术圈的前身。RL、模仿学习、self-supervised learning,全部都是它的工具箱。
Robot Learning ⊂ Physical AI。Robot Learning 是技术,Physical AI 是包含产品、商业、生态的更大范畴。
四、Physical AI 的四个标志性问题
定义清楚之后,更有用的视角是看这个领域 在解决哪些问题。下面四个,是当前 Physical AI 研究的"硬骨头",每一个都能直接看出技术水平:
问题一:跨形态泛化(Cross-Embodiment Generalization)。
一个 VLA 模型在 Franka 机械臂上训好,能不能直接在 UR5 上用?人形机器人 GR-1 上训的策略,能不能迁移到 Atlas 上?这就是跨形态泛化。
2023 年之前,这是不可能的——每个机器人型号都要单独训。2023 年 10 月 Open X-Embodiment 数据集发布之后,这件事有了基础。2024 年 8 月 Berkeley 的 CrossFormer 论文(arXiv 2408.11812)展示了单个模型权重覆盖 20 种不同形态——从机械臂到四足狗到无人机——的可行性。2025 年 10 月,Gemini Robotics 1.5 通过 Motion Transfer 实现了在 ALOHA、双臂 Franka、Apollo 人形之间的零样本技能迁移。
这是 Physical AI 区别于经典机器人学最关键的特征。
问题二:长程任务(Long-Horizon Manipulation)。
让机器人抓一个杯子放到桌上,这是短程任务,几秒钟搞定。让它"整理一整张餐桌,把脏碗放进洗碗机,擦干净桌面"——这要几分钟,几十步动作,每一步都不能错。这是长程任务。
为什么难?因为误差会累积。每一步的小错误会传给下一步,到第十步可能完全偏离轨道。LLM 处理长上下文已经够难了,机器人处理长动作序列要难得多——LLM 出错可以删掉重写,机器人出错的代价是物理的。
到 2025 年底,长程任务才开始出现可靠的突破。π*0.6 多小时家务任务、Gemini Robotics 1.5 的 chain-of-thought 长链推理,都是这条线的代表。再到 2026 年 5 月,Figure 直播 Helix-02 单班次连续工作八小时、处理超过三万件包裹,把这一档推到了"小时级量产"的新高度。这件事一旦被攻克,Physical AI 才算真正走进日常作业,而不只是演示。
问题三:从演示到部署(Demo → Deploy)。
你在 Twitter 上看到的机器人视频是 演示。把同样的模型放进 1000 户人家的厨房里,让它 24/7 工作——这叫 部署。两者之间隔着一条很深的沟。
演示视频里的机器人通常在受控环境下做精心挑选的任务。部署需要的是在 陌生环境 里做 陌生任务 时还不崩。这件事到 2025 年底才有头部玩家敢尝试——Figure 02 在 BMW Spartanburg 工厂跑了十个月的试点(处理过九万件零部件)、1X NEO 的 Early Access 家庭计划、Physical Intelligence 的真实家庭测试。
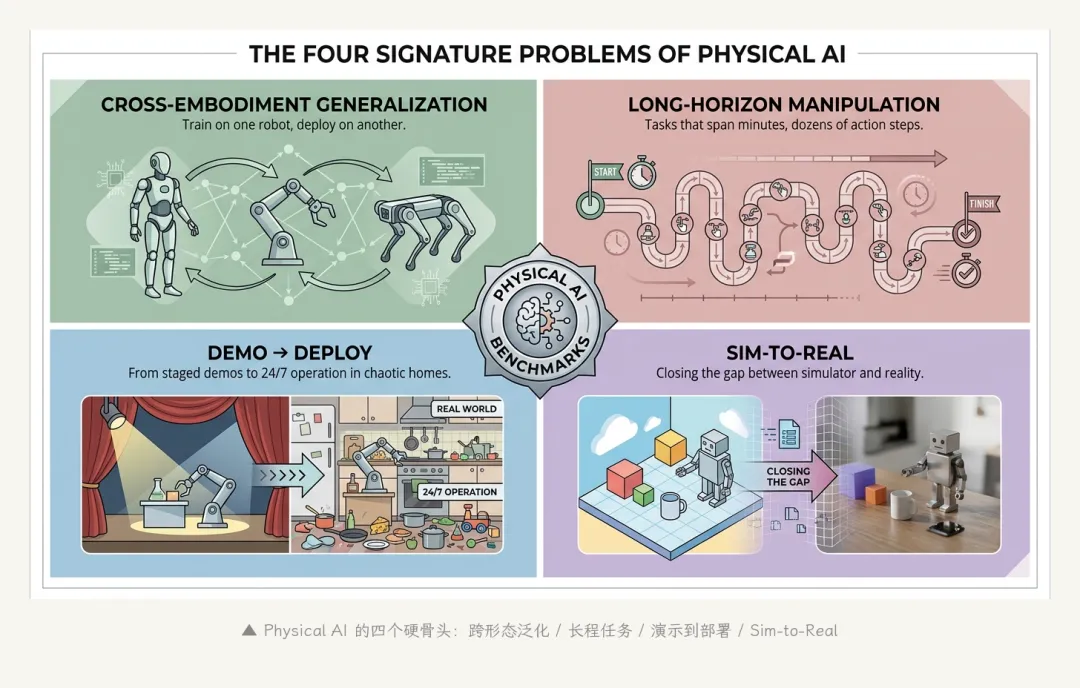
▲ Physical AI 的四个硬骨头:跨形态泛化 / 长程任务 / 演示到部署 / Sim-to-Real
问题四:Sim-to-Real(仿真到现实的迁移)。
这是机器人学攻克了三十年的老问题。在仿真器里训练出来的策略,移到真机上经常崩——因为仿真物理参数和真机有微小差异,被神经网络放大。
2020 年代之前,这个问题的主流解法是"domain randomization"——在仿真里随机化大量物理参数,让策略对参数变化鲁棒。这条路走得很慢。
2024-2026 年,生成式世界模型给了一个新解法。如果世界模型能直接从真实视频学到现实的物理分布,那它生成的训练数据就天然贴近现实——sim-to-real gap 在源头被压缩。NVIDIA Cosmos 的核心商业逻辑就是这个:用 Cosmos 生成的合成数据训练 GR00T,GR00T 部署到真机上时的迁移损失小得多。
四个问题。每一个都是判断一个 Physical AI 工作技术含量的标尺。看到一篇宣称做了 Physical AI 的论文/产品,你可以直接问:它在这四个问题上推进了哪一个?推进了几个?
五、三个层次的 Physical AI
最后一个角度——按"智能水平"分层,Physical AI 可以分成三档:
第一档:弱 Physical AI(Configurable Physical AI)——能执行 预先指定 任务的 AI 机器人系统。"教它做 A,它能做 A"。这一档已经很成熟——工业自动化、专用机械臂、自动驾驶 L4 的特定路段都属于这一档。它有"AI"成分(视觉识别、轨迹优化),但泛化能力有限。
第二档:中 Physical AI(Generalist Physical AI)——能在 新任务 / 新环境 上零样本或少样本泛化。教它做 A、B、C,它能用这些知识去做没见过的 D。当前 frontier 模型基本都在这一档:π*0.6、π0.7、GR00T N1.7、OpenVLA、Gemini Robotics 1.5 / ER 1.6。最新的里程碑是 2026 年 4 月 16 日发布的 π0.7——它第一次展示出"涌现式组合泛化":在没有任何 UR5e 双臂衣物数据的情况下,零样本就能在 UR5e 上折衣服。这是第二档能力的明确推进。
第三档:强 Physical AI(Autonomous Physical AI)——能 主动 探索、学习、积累经验。不光被动接受教学,还能在世界里自己发现规律、自己改进策略。这一档目前还是研究方向,没有可靠的工业实例。最接近的是 Physical Intelligence 的 RECAP 框架——让模型在部署后通过 RL 继续改进——但严格意义上的"自主学习"还非常初级。
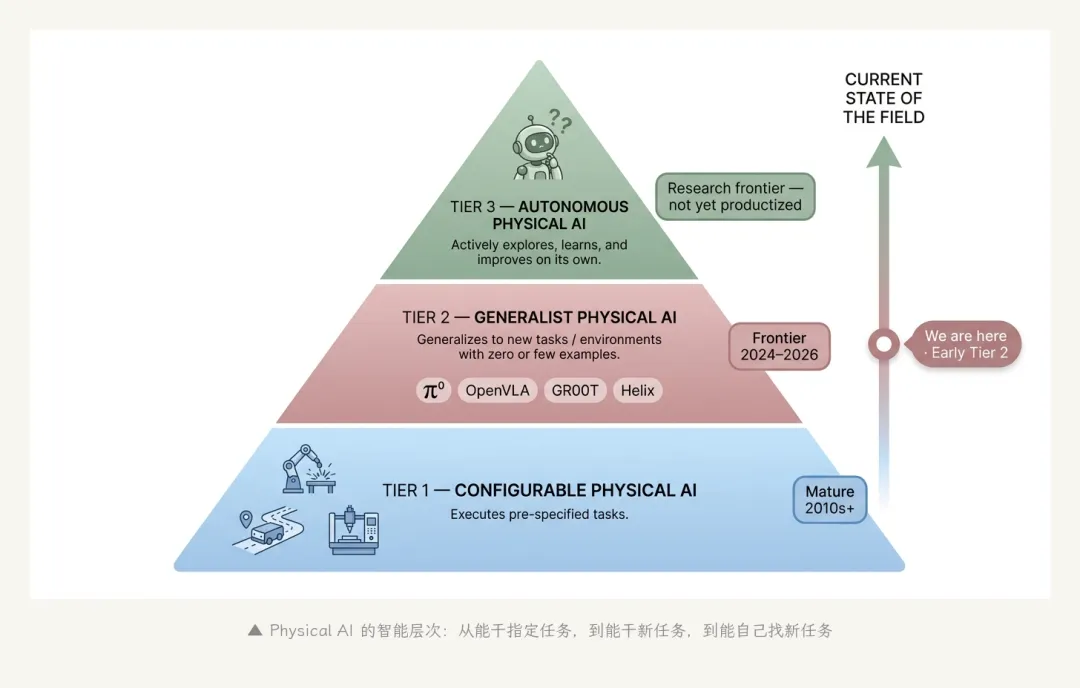
▲ Physical AI 的智能层次:从能干指定任务,到能干新任务,到能自己找新任务
当前业界的位置在哪?第二档的中段。π0.6 (2025-11) 已经能在陌生家庭里折衣服、做咖啡;π0.7 (2026-04) 又跨过了一道更难的门槛——"涌现式组合泛化",意思是模型见过 A 形态 + B 任务、见过 C 形态 + D 任务后,能直接做 A 形态 + D 任务,无需补数据。但即便如此,频繁失败仍要人工接管,离 无人值守 24/7 作业* 还差很远。
理解了这个分层,你就能去掉对"Physical AI"的不切实际预期。所有声称"我们做出了通用机器人"的公司,目前都在第二档的某个位置爬坡。第三档还在未来。
六、为什么"定义"这件事比看起来重要
讲了这么多定义,听起来像在抠词。但定义这件事,在 Physical AI 这个赛道上有非常实际的用处——它能帮你识别炒作。
举几个具体场景:
场景 1:Tesla 发了一段 Optimus 跳舞的视频——典型例子是 2024 年 10 月 We Robot 那场晚宴上 Optimus 倒酒服务的视频,后来 Bloomberg 揭穿是真人遥操。怎么判断?检查三个条件——感知物理世界?看不出(视频里没有展示泛化)。理解物理因果?无从判断。产生物理动作?是。再检查四个标志问题——它跨形态吗(没演示)?长程吗(30 秒)?部署了吗(没在真实家庭)?sim-to-real 了吗(无法判断)。结论:从公开信息看,这更像第一档(按预设动作执行)的演示,甚至连第一档都谈不上——这是 人在操作,根本不是 AI 在控制。
场景 2:Figure 公布 Helix-02 在物流仓库做 8 小时班次。检查同样的清单——这是真实部署(demo → deploy 的标志问题被推进),是长程任务,使用的是经过训练的 VLA 模型。结论:这是货真价实的第二档 Physical AI 进展。
场景 3:某创业公司说"我们在用大模型做工业 AI"。问几个问题:你们的模型直接输出关节角度还是输出 建议?它在多少种不同的工业设备上验证过?换一个工厂需要多久重训?如果答案是"我们的 LLM 帮工程师写控制脚本",那不是 Physical AI——那是 AI Coding 在工业场景的应用,是另一件事。
定义清楚的目的,不是为了排除谁,是为了在听到一个声音时能问对问题。Physical AI 这个赛道接下来五年会非常喧闹——人形机器人、合成数据、世界模型、各类 VLA——每一波都会带来一批宣称自己是 frontier 的公司。能用一套清晰的定义和判断标准过滤这些声音,是这一讲我希望你带走的东西。
七、剩下八讲的承接
接下来的八讲,会按这一讲的定义结构展开:
第三讲行话速查会把术语层面的东西彻底讲清——VLA、世界模型、Sim-to-Real、Diffusion Policy、Action Chunking——每一个都给一个能用的工作定义。第四讲 VLA 演化会沿着"问题二(长程)+ 问题一(跨形态)"这两个标志问题的解答路径,串起 RT-1 到 π*0.6 的整个发展。第五讲三大阵营用"哲学差异"切入,看 DeepMind / Pi / 开源轴在四个标志问题上各自押的方向。第六讲世界模型专攻"问题二(因果)+ 问题四(Sim-to-Real)"。第七讲 NVIDIA沿着工业链解读 Cosmos + GR00T + Newton 的闭环。第八讲人形战场专门看"问题三(demo → deploy)"在 Figure、1X、Tesla、Apptronik 上的现实进展。第九讲国内进展比照海外四大问题做镜像分析。第十讲上手指南回归读者本位——如果你想自己玩起来,第一步该怎么走。
定义本身不是终点,但定义是后面所有讨论的脚手架。
八、收尾
定义一个新领域,永远是一件危险又必要的事。
二十多年前我们定义"互联网公司"的时候,吵过类似的争论——一个有官网的传统企业算不算?一个只在线上卖货的零售商算不算?答案永远在事后才清楚——能在十年后回头看,依然站得住的定义,才是好定义。
Physical AI 这个标签,会在未来五年被反复争夺、稀释、重新定义。会有一群创业公司给自己贴上这个标签,会有大批传统机器人厂商重新包装成这个标签,也会有人提出新的术语来替代它。
我在这一讲里给出的三个条件、四个问题、三个层次——不是权威定义,是 工作定义。它们的价值不在于"正确",而在于"可用"——你拿这套框架去看接下来的新闻、论文、产品发布,能比别人更快地看出来:哪些是真进展,哪些是包装精致的旧东西。
下一讲,我们进入第三讲:行话速查。把这个领域所有让人头大的术语,一个一个解清楚。
(第二讲完。下一讲:《物理 AI 行话速查》——VLA、World Model、Action Chunking、Diffusion Policy、System 1/2 双速率、Sim-to-Real——一节扫盲。)
— 在浏览器中 Ctrl+A 全选 → Ctrl+C 复制 → 粘贴到微信公众号编辑器 —
