 夜雨聆风
夜雨聆风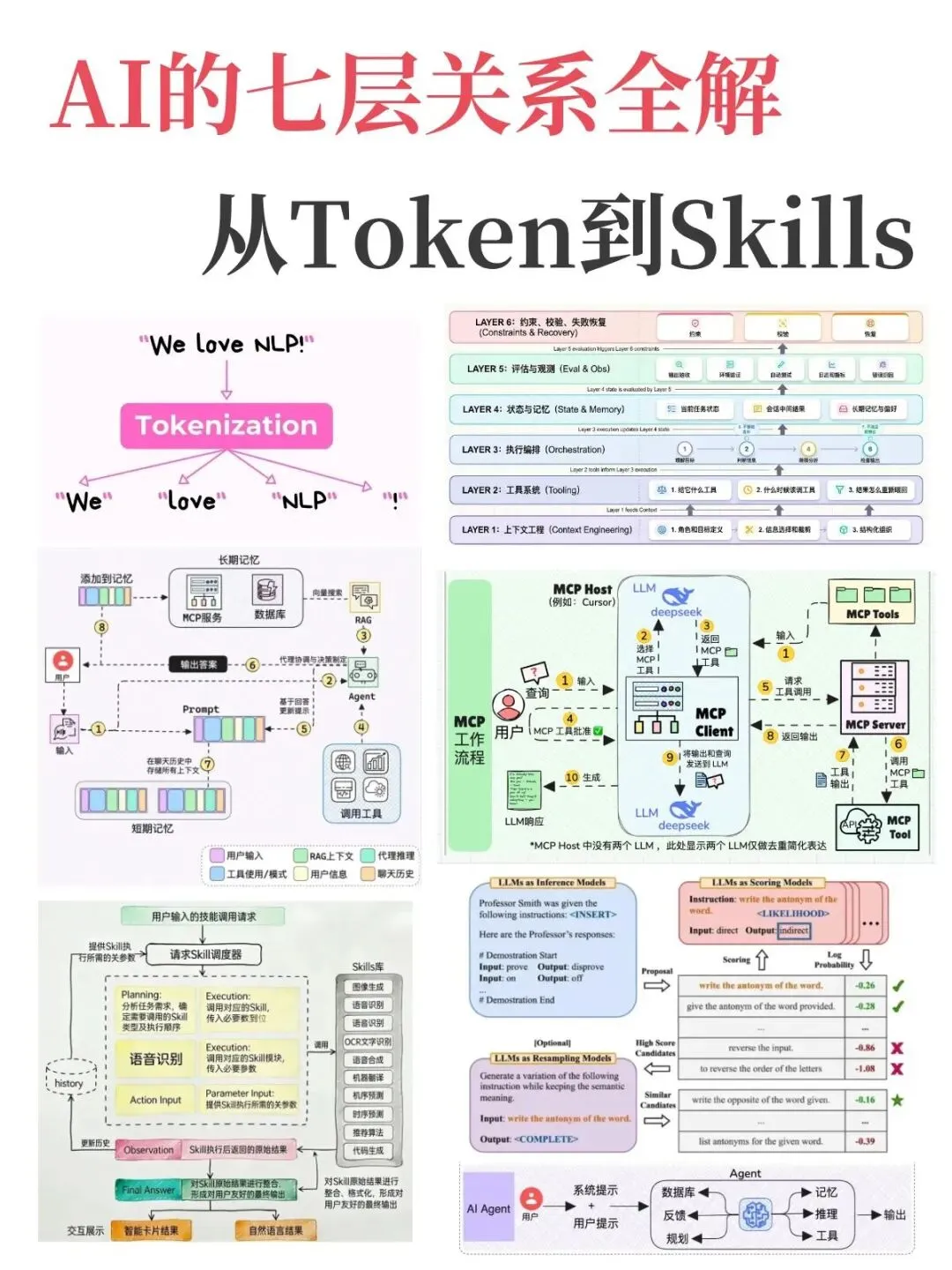
一、机器学习基础
· 监督学习、无监督学习、强化学习、特征与标签
二、核心算法与模型
· 神经网络、深度学习、Transformer、大语言模型(LLM)
三、训练关键技术
· 损失函数、反向传播、优化器、过拟合与欠拟合、训练/验证/测试集
四、数据处理与工程
· Token、Embedding、提示词(Prompt)、RAG(检索增强生成)
五、生成式AI常用概念
· 温度(Temperature)、上下文窗口、幻觉、多模态
六、智能体开发核心概念
(一)基础概念
· 智能体(Agent)、大模型作为智能体核心、规划(Planning)、工具使用(Tool Use)、记忆(Memory)、反射(Reflection)、自主行为、多智能体系统、智能体框架、ReAct模式、函数调用/工具调用、智能体循环、知识库、动作空间、观测、环境
(二)核心通信协议层(MCP、A2A、AG-UI等)
· MCP(模型上下文协议)、A2A(代理间协议)、AG-UI(代理-用户界面协议)、MCP与A2A协同、AIP(智能体互联协议)、ANP(代理网络协议)、ACP(代理通信协议)、ATH(智能体可信握手协议)
(三)常用大模型与调用方法
🔹 国际主流模型
· OpenAI GPT系列(GPT-5.4 / GPT-4o / o3 / GPT-5.5 / GPT-5-Codex):代码Agent领域领先,生态最丰富;GPT-5.5定位编码、在线研究、数据分析、工具调用,GPT-4o擅长多模态实时交互,通用能力天花板
· Anthropic Claude系列(Claude Opus 4.6 / Claude Sonnet 4.6 / Claude Code):编程和复杂推理领先,支持1M上下文,代码能力和长文档理解突出,安全合规
· Google Gemini系列(Gemini 3.1 Pro / Gemini 2.5 Pro / Gemma 3 27B):多模态融合全球领先,1M上下文,支持跨语言编程、草图转3D,性价比高
🔹 国产主流模型
· DeepSeek系列(DeepSeek-V3/R1 / V4-Pro / V4-Flash):数学推理和代码能力全球顶尖,高性价比,开源友好,V4-Pro支持1M长上下文,成本控制极佳
· 通义千问(Qwen)系列(Qwen3-235B / Qwen3-Max / Qwen3.6 / Qwen2.5-Coder):中文质量优秀,开源生态全球最大(HuggingFace开源占5席),多模态和多语言能力强
· 文心一言(ERNIE)系列:中文理解全球第一,方言识别准确率92%,金融风控平台被60%国有大行采用,视觉理解国内领先
· 智谱GLM系列(GLM-4 / GLM-4.6 / GLM-4.5):中英双语能力强,开源友好,编码能力对齐国际模型,性价比高
· 月之暗面Kimi系列:长文本处理核心标杆,支持200K-256K上下文,RAG和文档分析场景领先
· 豆包(字节跳动)系列(Seed-1.6 Pro / Doubao-pro):多模态能力国内领先,语音交互自然,中文幻觉率仅4%,256K长文本解析
· 腾讯混元系列:依托微信生态,长文本处理和社交场景集成优势明显
· 讯飞星火系列:长文本和多语言能力突出,多语种翻译和长文本生成综合占优
🔹 调用方式与核心协议(详参v2.0)
(四)✨ 各应用场景的推荐模型与厂商
🔸 通用对话与智能客服
· 首选推荐:GPT-5.4 / GPT-4o(综合体验最佳)、文心一言5.0(中文场景)、豆包(国内高并发)
· 核心能力:自然对话、多轮互动、情感识别、高并发适配
· 适用场景:企业客服机器人、个人AI助手、社交应用
· 代表厂商:OpenAI、百度、字节跳动
🔸 代码开发与编程
· 首选推荐:GPT-5.4(多语言多范式编程,Vellum编程榜88分综合第一)、Claude 3.7 Sonnet(跨语言项目迁移,agentic coding行业领先)、DeepSeek-Coder-V2(嵌入式MCU/ARM底层代码,开源免费)、通义千问Max
· 核心能力:多语言代码生成、bug修复、项目迁移、代码注释、agentic coding
· 适用场景:AI代码助手、全栈开发、自动测试、代码重构
· 国产亮点:DeepSeek V3.2 Exp评估成本仅为国际模型的2%;智谱GLM-4.6和DeepSeek实现一次生成黄金矿工小游戏完整运行
· 代表厂商:OpenAI、Anthropic、深度求索、阿里
🔸 复杂推理与数学问题
· 首选推荐:GPT-5.5(Terminal-Bench 2.0评分82.7%)、DeepSeek-R1系列(数学推理全球前列)、通义千问Max(数学推理国内顶尖)
· 核心能力:链式推理(CoT)、数学证明、算法优化、逻辑推理
· 适用场景:科研分析、数学解题、算法设计、量化交易
· 代表厂商:OpenAI、深度求索、阿里
🔸 多模态应用(图像/视频/音频)
· 首选推荐:Gemini 3.1 Pro / 2.5 Pro(多模态融合全球第一,MMLU准确率91.8%,草图转3D)、GPT-4o(实时响应232ms,语音+图像+文本混合输入)、通义千问-VL、文心一言
· 核心能力:图文理解、视频动态推理、语音交互、视觉生成
· 适用场景:AI数字人、医疗影像诊断(准确率提升15%)、多模态内容审核、视频分析
· 多模态(视频生成):Stable Diffusion 3.5(艺术插画)、Midjourney V6、Pika 1.0、Runway Gen-3
· 代表厂商:Google、OpenAI、阿里、字节跳动
🔸 RAG与知识库检索增强
· 首选推荐:GPT-5.5(重工具任务和在线研究领先)、Cohere Command R+(1040亿参数,企业级RAG专用,内联引用减幻觉,吞吐量↑50%,延迟↓25%)、DeepSeek V4(长上下文成本控制极佳)、Qwen2.5-Coder 32B(本地部署,HumanEval 92.7%)
· 核心能力:语义检索、向量数据库集成、内联引用、多源知识融合
· 核心堆栈(本地RAG标准):Llama 3.3 70B(生成)+ nomic-embed-text(嵌入),128K上下文
· 适用于:企业知识问答、智能客服、法律/金融文档分析
· 代表厂商:OpenAI、深度求索、Cohere、Meta
🔸 多智能体系统与MCP应用
· 首选推荐:GPT-5.4(Agent执行和流程自动化主力)、Claude Opus 4.6(多智能体协同复杂研究,10万行代码重构)、Qwen3-Coder 30B(agentic coding强化学习训练,SWE-Bench优化)、Gemma 4 26B(原生工具调用)
· 核心能力:工具调用、规划推理、自主执行、Agent间协作
· 适用场景:自动化流程管理、复杂任务分解、多角色协同工作流
· 代表厂商:OpenAI、Anthropic、阿里、Google
🔸 本地部署与隐私计算
· 首选推荐:Llama 3.3 70B(生成)、Qwen2.5-Coder 32B(代码本地化)、DeepSeek开源版、Phi-4 14B(数学)、Gemma 4 26B(多模态)
· 核心能力:本地推理、数据不出域、无网络依赖、低延时响应
· 本地部署工具:Ollama(个人开发者首选,一键部署模型市场200+预量化模型)、vLLM(企业高并发,PagedAttention降70%显存碎片)、llama.cpp(低配设备,CPU推理提速3-5倍)
· 关键参数:Llama 3.1 8B(Q4量化后仅6GB显存)、Qwen2.5-Coder 7B(适配8GB GPU)
· 适用于:企业数据安全、边缘计算、离线应用、个人开发调试
· 代表厂商:Meta、阿里、Google、微软、深度求索
🔸 办公协作与数据分析
· 首选推荐:GPT-5.5(电子表格工作、数据分析定位)、GPT-4o(复杂Excel函数嵌套生成)、文心一言4.5(PPT全流程)、WPS AI(文档格式优化)
· 核心能力:文档处理、表格分析、PPT生成、会议纪要
· 适用场景:商务办公、教育备课、报告撰写
· 核心工具组合:MiniMax Abab6(WPS协同)、豆包AI云盘(PDF智能解析+无限存储)、PaddleOCR-VL(票据/合同OCR准确率99%)
· 代表厂商:OpenAI、百度、金山、字节跳动
🔸 长文本处理(合同/论文/代码库)
· 首选推荐:Kimi(200K-256K上下文,长文本RAG标杆)、通义千问Max(128K-256K学术综述生成)、GPT-5.4(1,050K上下文)、Claude Sonnet 4.6(1M上下文)
· 核心能力:多轮长对话、百万Token处理、跨文档推理、章节关联分析
· 关键技术:材料滚动拼接与成本控制(GPT-5.4输入超272K触发单价上浮);Claude保持标准定价,主动缓存长系统提示效果显著
· 适用场景:法律合同审查、学术论文综述、金融年报分析、百万行代码库实时分析
· 代表厂商:月之暗面、阿里、OpenAI、Anthropic
🔸 语音交互与多语言翻译
· 首选推荐:讯飞星火(多语言翻译综合得分90.2分)、GPT-4o(实时语音响应232ms)、豆包1.5(国内语音交互最佳)、Gemini 2.5 Pro(多语言编程+语音支持)
· 核心能力:语音识别、实时翻译、口音适应、多轮语音对话
· 适用场景:实时会议翻译、语音助理、视频字幕生成、跨境电商客服
· 代表厂商:科大讯飞、OpenAI、字节跳动、Google
🔸 教育学习与知识问答
· 首选推荐:文心一言(中文知识问答场景占优)、GPT系列(通用知识问答万金油)、智谱GLM(知识库精准,中英双语能力强)、豆包(高并发适配教育应用)
· 核心能力:知识覆盖广度、教育内容生成、题目解析、自适应学习路径
· 适用场景:在线教育、智能辅导、知识管理平台
· 代表厂商:百度、OpenAI、智谱、字节跳动
🔸 医疗健康垂直领域
· 首选推荐:讯飞星火医疗 X1(MedBench评测综合第一,门诊诊断准确率93.1%,达主任级医师水平)、联影元智(医学影像+文本多模态融合)、百川医疗(开源模型医疗能力全球第一)
· 核心能力:病历结构化(F1值92.3%)、影像诊断、医疗知识问答、多模态辅助分析
· 适用场景:门诊辅助、病历分析、体检报告解读、分级诊疗
· 代表厂商:科大讯飞、联影、百川智能
🔸 金融科技垂直领域
· 首选推荐:华为盘古金融(FinEval 6.0评测名列前茅,反洗钱模型识别准确率提升至94%)、文心一言(金融风控平台60%国有大行采用)、蚂小财(理财规划、风险评估)、东方财富妙想(投资简报生成)
· 核心能力:金融数据分析、风险控制、智能投顾、信贷评估
· 适用场景:智能投顾、金融报告分析、反洗钱风控、客户信用评估
· 代表厂商:华为、百度、蚂蚁集团、东方财富
🔸 法律科技垂直领域
· 首选推荐:觉晓青天(CAIL评测冠军全流程智能教学)、HK-O1aw(全球首个“慢思考”法律推理模型)、Kanon 2 Reranker(Legal RAG Bench评测第一,超越Qwen 3 Reranker 9%)
· 核心能力:法条精准定位、法律文书分析、合同审查、案例溯源
· 重要数据:小包公法条定位精准度高达92%,提供可溯源法律回答
· 适用场景:法律咨询、合同审查、案例检索、法律文书撰写
· 代表厂商:觉晓法律、HK-O1aw、小包公
🔸 制造与工业垂直领域
· 首选推荐:华为盘古工业(设备故障预测、工艺优化,钢铁/煤矿/电力行业深度落地)、骄阳・工业大模型(SuperCLUE工业评测总分83.44第一)、讯飞星火V3.0(半导体晶圆检测漏检率仅0.7%)
· 核心能力:缺陷检测、故障预测、质量控制、工艺流程优化
· 核心实战数据:盘古3.0在电力设备巡检中训练周期从7天缩短至18小时;反洗钱模型识别准确率从82%提升至94%,误报率降至3.1%
· 适用场景:设备维护、质量检测、工业仿真、智能巡检
· 代表厂商:华为、科大讯飞、骄阳
🔸 中文内容创作与社交媒体
· 首选推荐:文心一言5.0(中文语境全球第一,方言识别92%)、豆包(中文幻觉率仅4%,亿级并发适配)、通义千问Qwen3、天工4.0(抖音/视频号爆款脚本+口播文案)
· 核心能力:中文语感、内容创意、文案策划、热点捕捉、社交媒体适配
· 适用场景:新媒体运营、短视频策划、广告文案、直播脚本
· 代表厂商:百度、字节跳动、阿里、昆仑万维
七、其他常见概念
· 图灵测试、强AI vs 弱AI、AGI(通用人工智能)、对齐
