 夜雨聆风
夜雨聆风这是2025年SNIA开发者大会(SDC25)上,戴尔存储CTO办公室的技术演讲主题,聚焦如何通过存储层优化解决LLM推理中KV缓存的容量与性能瓶颈。


大语言模型(LLM)推理的两个核心阶段:Prefill(预填充)与Decode(解码)。
首先,在Prefill阶段,用户的输入提示词(如示例中的“Istomatoafruit?”)会被一次性并行处理,生成第一个输出token(如示例中的“Yes,”);随后进入Decode阶段,模型会采用自回归(auto regressive)方式,将上一步生成的token作为输入,逐个迭代生成后续的token(如“it”、“is.”),直到遇到停止条件(如句末符号)才结束。
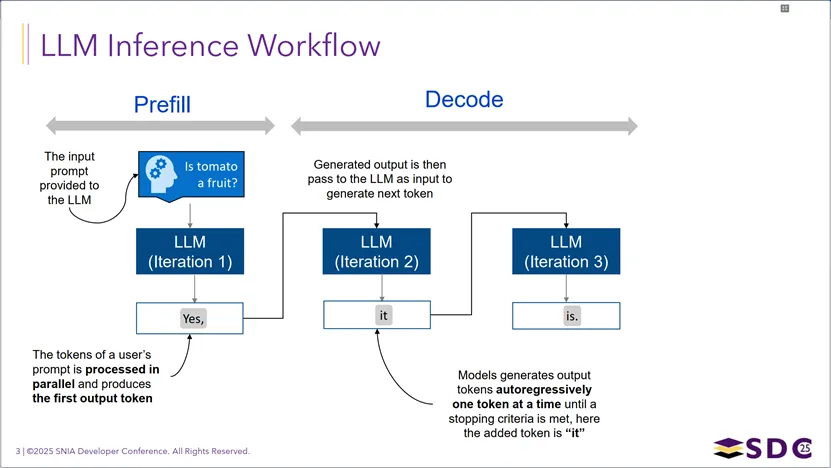
Transformer架构中的KVCache(键值缓存)优化技术:在LLM推理的Prefill阶段,模型处理输入提示词时,会将每个token生成的Key(键)和Value(值)向量存入缓存;到了Decode阶段生成后续token时,模型无需重复计算所有历史token的Key/Value,只需计算当前新token的Query,并直接读取缓存中的历史Key/Value来完成注意力计算,从而大幅减少重复运算、提升解码效率。
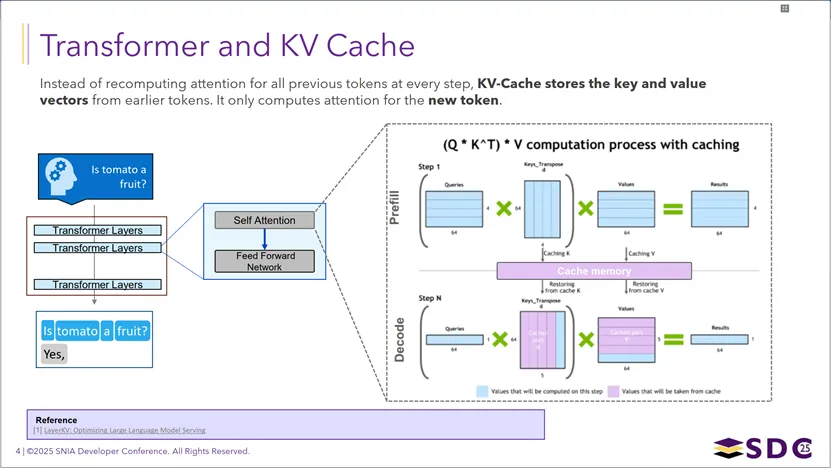
KVCache如何作为Transformer大模型推理的核心优化手段,下图清晰区分了Prefill和Decode两个阶段的特性:在Prefill阶段,模型一次性并行处理用户输入提示词,生成并存储所有token的Key/Value向量,构建起KVCache,这个阶段属于计算密集型任务,决定了首token延迟(TTFT);进入Decode阶段后,模型不再重复计算历史token的Key/Value,而是直接读取缓存中的数据,仅为当前新token计算Query,自回归地逐个生成后续token,这个阶段属于内存密集型任务,决定了token间延迟(ITL),从而大幅降低重复计算开销,提升整体推理效率。
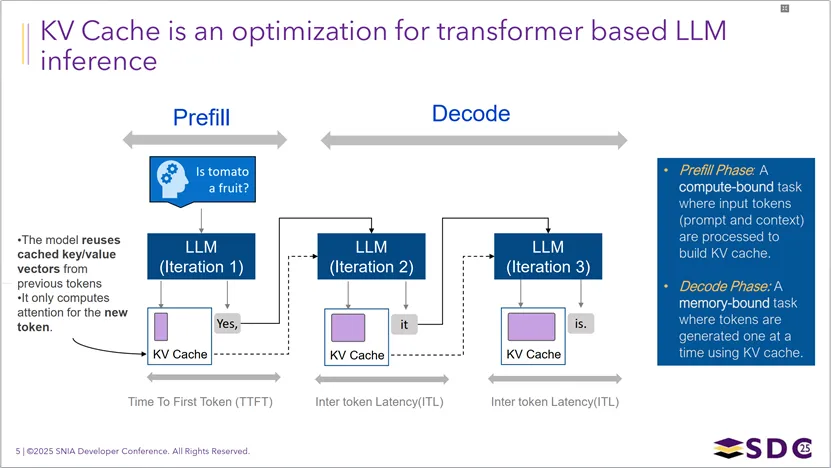
大规模LLM推理部署中采用的解耦式架构:它以分布式KVCache池为核心,通过API Server接收用户请求后,由Router将请求路由至Prefill节点处理输入提示词、生成KVCache,再将KVCache发送给Decode节点完成后续解码生成,最终返回结果给用户;这种架构将Prefill和Decode任务分离部署,通过专用路由(如KV感知路由、会话路由)实现资源调度,最大化GPU利用率并提升整体推理性能。
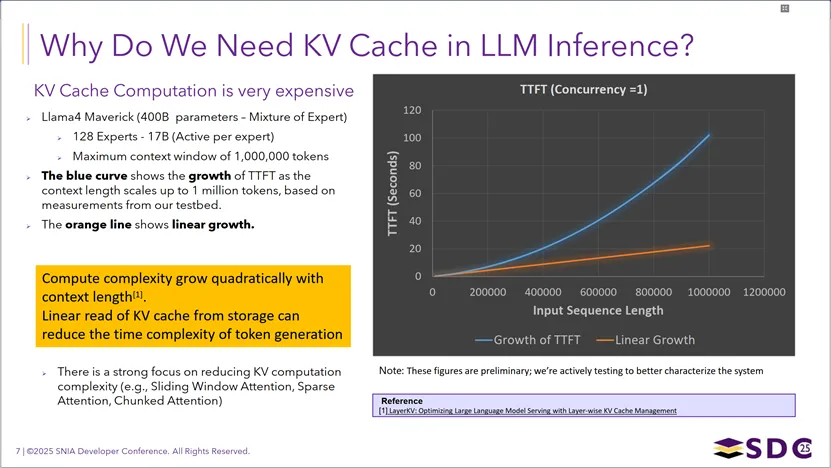
这张图解释了LLM推理中引入KVCache的核心动因:以Llama4 Maverick(400B参数MoE模型,最大上下文窗口100万token)为例,KVCache相关计算的复杂度会随上下文长度呈二次方增长,直接导致首token延迟(TTFT)急剧攀升(图中蓝色曲线),远高于线性增长(橙色线);而通过从存储中线性读取KVCache,能将token生成的时间复杂度从二次方降为线性,从而大幅降低延迟,这也是业界普遍聚焦优化KV计算复杂度(如滑动窗口注意力、稀疏注意力等技术)的根本原因。
下图围绕长上下文场景下的LLM推理展开,指出在多轮对话、文档摘要、代码分析、RAG、多模态等真实场景中,上下文长度增加会直接延长Prefill阶段耗时(TTFT),拖慢用户响应并提升成本;因此提出优化思路:无需为每个查询重复生成KVCache,而是一次生成后在后续查询中复用,以此降低Prefill开销、提升长上下文推理效率。

LLM推理中KVCache的容量需求:它指出KVCache的存储占用由模型层数、KV头数、头维度、精度等因素决定,并给出了单token KVCache大小的计算公式;同时通过表格数据展示,以FP16精度为例,Qwen3-8B、LLaMA-3.3-70B、LLaMA-3.1-405B等模型的KVCache占用会随序列长度线性增长,单token仅需数十KB,但百万token上下文下最高可占用516GB空间,凸显了长上下文场景下KVCache对存储资源的巨大需求。

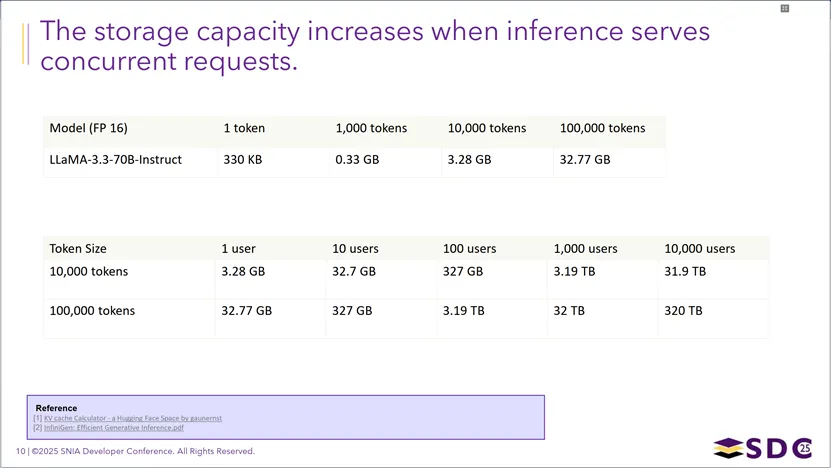
以LLaMA-3.3-70B-Instruct(FP16精度)模型为例,LLM推理在处理并发请求时,KVCache存储容量的需求会随用户数量和上下文长度呈线性增长:单用户场景下,1万token上下文仅需3.28GB、10万token上下文需32.77GB;而当并发用户扩展至10000时,1万token场景的KVCache需求将飙升至31.9TB,10万token场景更是达到320TB,凸显了大规模并发推理部署中,KVCache对存储资源的巨大压力。
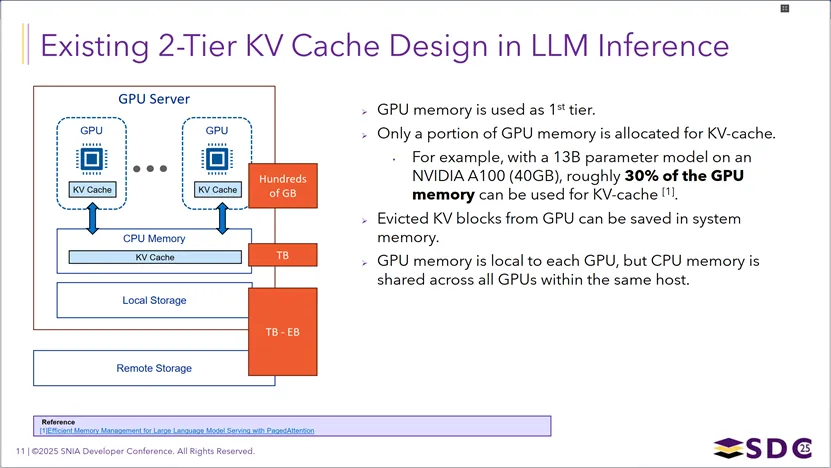
当前LLM推理中主流的两层级KVCache架构:以GPU显存作为第一级高速缓存(但受限于显存容量,例如A100 40GB显存运行13B模型时,仅约30%的显存可用于KVCache),将GPU中被驱逐的KV块存入主机共享的CPU内存作为第二级扩展缓存,同时可进一步延伸至本地存储甚至远程存储,形成容量从数百GB到TB级乃至EB级的层级结构,以此缓解大规模并发和长上下文场景下的显存压力。
通过LLaMA3-70B模型的分析,揭示了本地内存KVCache的局限性:该模型单token KVCache约320KB,1TB DRAM仅能缓存约3M token;真实场景中约50%的token KVCache可复用,但本地3M token容量下,各类业务的缓存命中率仅能达到理论最大值的41%-75%,远低于理想水平;要接近100%的理论命中率,需至少20TB DRAM(约50M token),成本极高,说明仅靠本地内存无法充分发挥KVCache的复用价值,必须引入更底层的存储扩展方案。

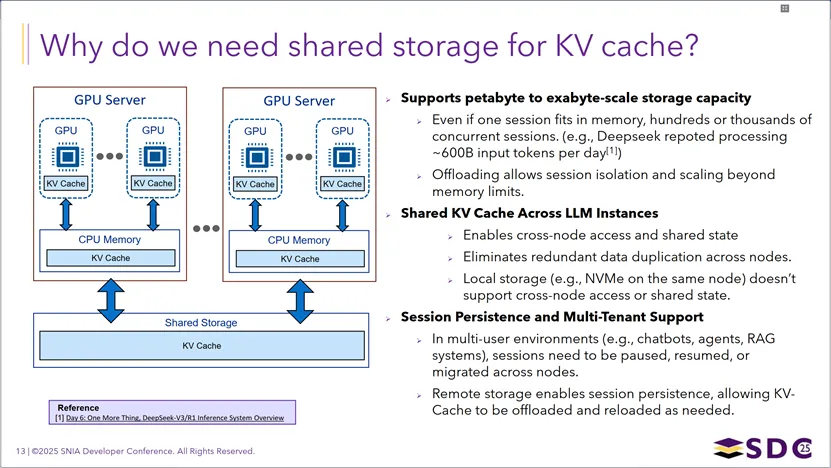
LLM推理中为KVCache引入共享存储的必要性:它能提供从PB级到EB级的超大容量,支持DeepSeek这类日处理千亿token的大规模并发场景,通过KVCache的卸载与隔离突破单机内存限制;同时实现跨节点的KVCache共享,消除数据冗余,解决本地存储无法跨节点访问的问题;还能支持会话持久化与多租户场景,让会话在节点间暂停、恢复和迁移,从而支撑高并发、长上下文的LLM推理部署。
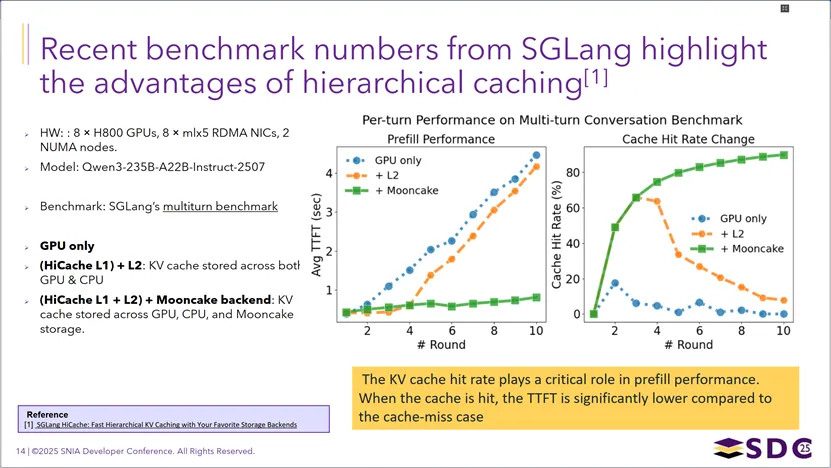
在SGLang在多轮对话场景下,对分层KV缓存架构的性能测试结果:在8×H800GPU、Qwen3-235B模型的测试中,对比了“仅GPU缓存”“GPU+CPU二级缓存”“GPU+CPU+Mooncake存储三级缓存”三种方案,结果显示随着层级扩展,缓存命中率显著提升(Mooncake方案的命中率随轮次持续走高,而仅GPU缓存命中率快速下降),首token延迟(TTFT)也大幅降低,印证了分层缓存(尤其是引入共享存储层)能通过提升KV缓存复用率,显著优化长上下文多轮对话的Prefill性能。
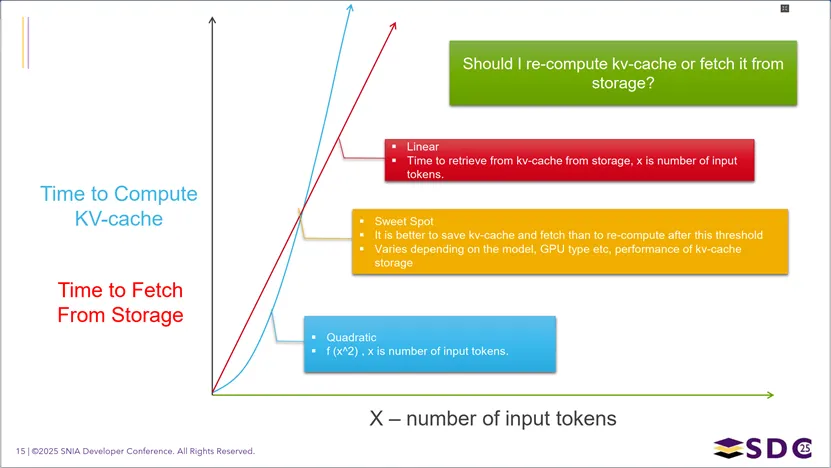
对比两种策略的耗时曲线,回答了“在LLM推理中,是重新计算KVCache还是从存储中读取更高效”的问题:重新计算KVCache的耗时随输入token数呈二次方增长,而从存储中读取的耗时为线性增长;两条曲线存在一个“平衡点(Sweet Spot)”,当token数超过该阈值时,从存储中读取KVCache的耗时会显著低于重新计算,因此更适合复用缓存;这个平衡点会随模型、GPU性能、存储系统性能的不同而变化。
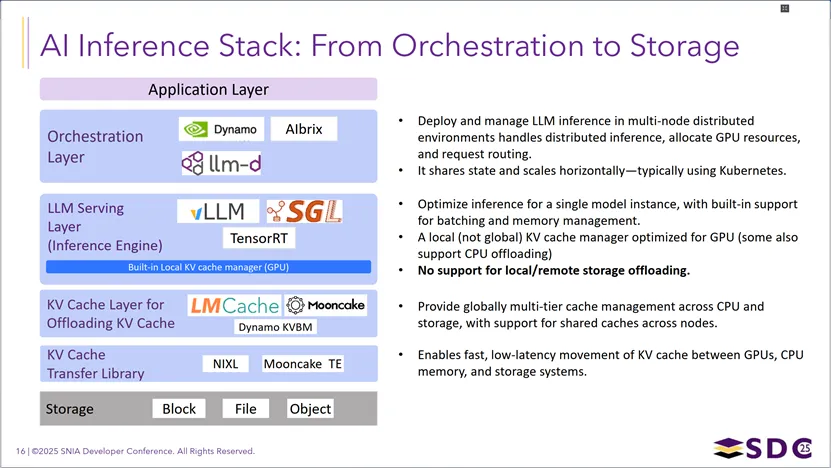
AI推理栈从编排到存储的分层架构:从上到下依次为应用层、编排层(如Dynamo、Albrix、llm-d,负责多节点分布式部署、GPU资源分配与请求路由)、LLM服务层(如vLLM、SGLang、TensorRT,内置GPU本地KV缓存管理,支持批处理与内存优化,但不支持向本地/远程存储卸载)、KV缓存层(如LMCache、Mooncake、Dynamo KVBM,提供跨CPU和存储的全局多层级缓存管理与跨节点共享)、KV缓存传输库(如NIXL、Mooncake TE,实现KV缓存在GPU、CPU内存与存储间的低延迟传输),以及底层的块/文件/对象存储,完整呈现了支撑大规模LLM推理的技术栈,尤其是新增的KV缓存卸载与共享能力。
LLM推理中KV缓存分层与管理的演进:传统的vLLM、SGLang等推理引擎采用本地两层缓存架构,以GPU显存为L1、CPU内存为L2,但仅支持本地管理,无法跨节点共享;而LMCache等方案在此基础上扩展出包含CPU内存与本地/远程存储的L2+L3多层架构,支持vLLM的直写模式、SGLang的多种写入策略,采用LRU/LFU/FIFO等淘汰算法,以256 token为粒度的块级操作优化读写性能,还支持零拷贝传输和Cache Gen压缩,实现了KV缓存向更底层存储的卸载与高效管理。

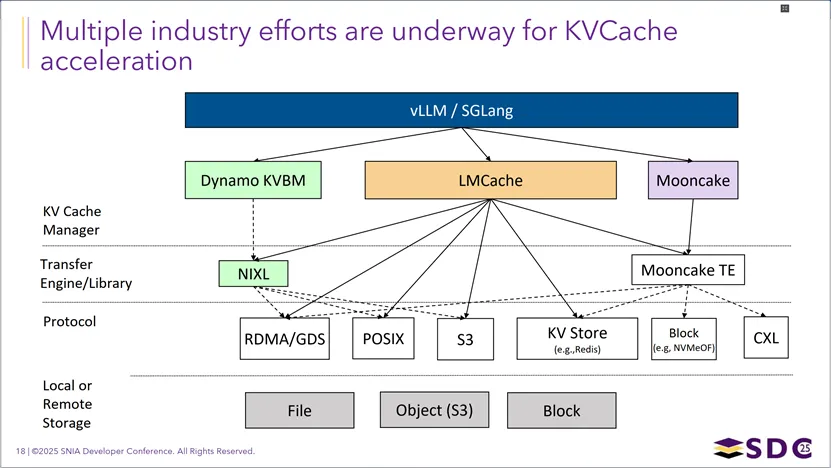
这张图梳理了当前行业内KVCache加速的主流技术栈生态:以vLLM/SGLang这类推理引擎为上层入口,向下对接Dynamo KVBM、LMCache、Mooncake等KV缓存管理器;这些管理器再通过NIXL、Mooncake TE等传输引擎,基于RDMA/GDS、POSIX、S3、CXL等多种协议,将KV缓存数据读写对接到底层的文件、对象、块存储中,形成了一套覆盖缓存管理、高速传输、多协议适配与异构存储的完整技术体系,以实现跨节点、跨层级的KVCache高效访问与加速。
LLM推理中KVCache向远程存储卸载时的I/O特性:整体是读密集型工作负载,以从存储中读取已计算的KV块供复用为主;读取时,缓存未命中会触发从存储将固定大小的KV块(100KB至100MB+)加载到GPU显存,需要精确的前缀匹配,存在顺序与随机读两种模式;写入则是将GPU/CPU中的KV块复制到共享存储层,多为单次写入、无修改的随机写模式;数据访问以块级为粒度,而非单个键值对;同时整个流程对延迟高度敏感,读取路径上RDMA技术至关重要,而写入对RDMA的依赖相对较低,且当前主流实现中I/O操作仍由CPU发起。

