 夜雨聆风
夜雨聆风

当前最先进的AI视觉系统(如ResNet、ViT、CLIP)与人类视觉存在根本性“错位”。人类看物体主要依赖轮廓形状,而AI却严重依赖局部纹理。这导致AI在面对模糊、噪声、遮挡或抽象线条画时,识别率会断崖式下跌,且极易被对抗性攻击欺骗。此前的研究试图通过数据增强或特定训练来提升“形状偏置”(Shape Bias),但效果有限且难以逼近人类水平。德国研究团队独辟蹊径,不再纠结于“喂什么数据”,而是转向“如何喂数据”——他们从人类婴儿到成人的视觉发育过程中汲取灵感,为AI设计了一套“发育视觉食谱”。
德国奥斯纳布吕克大学Zejin Lu 与Tim C. Kietzmann 教授研究团队基于人类视觉发育心理学数据,构建了一套发育视觉食谱(DVD,Developmental Visual Diet)预处理流程。该流程模拟了人类从出生到25岁视觉成熟过程中,视觉 acuity(锐度)、对比度敏感度和色彩感知的渐进发展轨迹。在训练初期,AI看到的图像是模糊、低对比度、低饱和度的(模拟婴儿视觉),随着训练进行,图像质量逐渐提升至高清。实验表明,经过DVD训练的模型(如ResNet-50)在形状偏置上实现了质的飞跃(从基线~0.3提升至~0.9,接近人类水平),并且在抽象形状识别、图像失真鲁棒性及对抗攻击防御方面均达到新的SOTA水平,且无需增加模型参数或数据量。该研究以题为“Adopting a human developmental visual diet yields robust and shape-based AI vision”发表于国际著名期刊《Nature Machine Intelligence》。

范式创新:首次将人类视觉发育的连续轨迹(而非离散阶段)量化为AI训练的数据预处理流程,提出“训练轨迹对齐”的新范式。
性能突破:在标准架构(ResNet-50)上实现接近人类的形状偏置(>0.9),大幅超越现有SOTA模型(包括CLIP、ViT等)。
机制揭示:通过消融实验证明,对比度敏感度的发展是驱动模型形成形状偏置的关键因素,而非此前公认的单纯模糊(Blur)。
系统验证:在多个维度(形状偏置、抽象形状、失真鲁棒性、对抗攻击)上系统验证DVD的有效性,证明其普适性。

图1:人类视觉发育食谱(DVD)的构建蓝图
核心看点:DVD的核心在于“先模糊后清晰”的训练轨迹,这迫使神经网络像人类婴儿一样,先学会看“轮廓”,再学会看“细节”,从而在底层表征中植入形状优先的偏好。
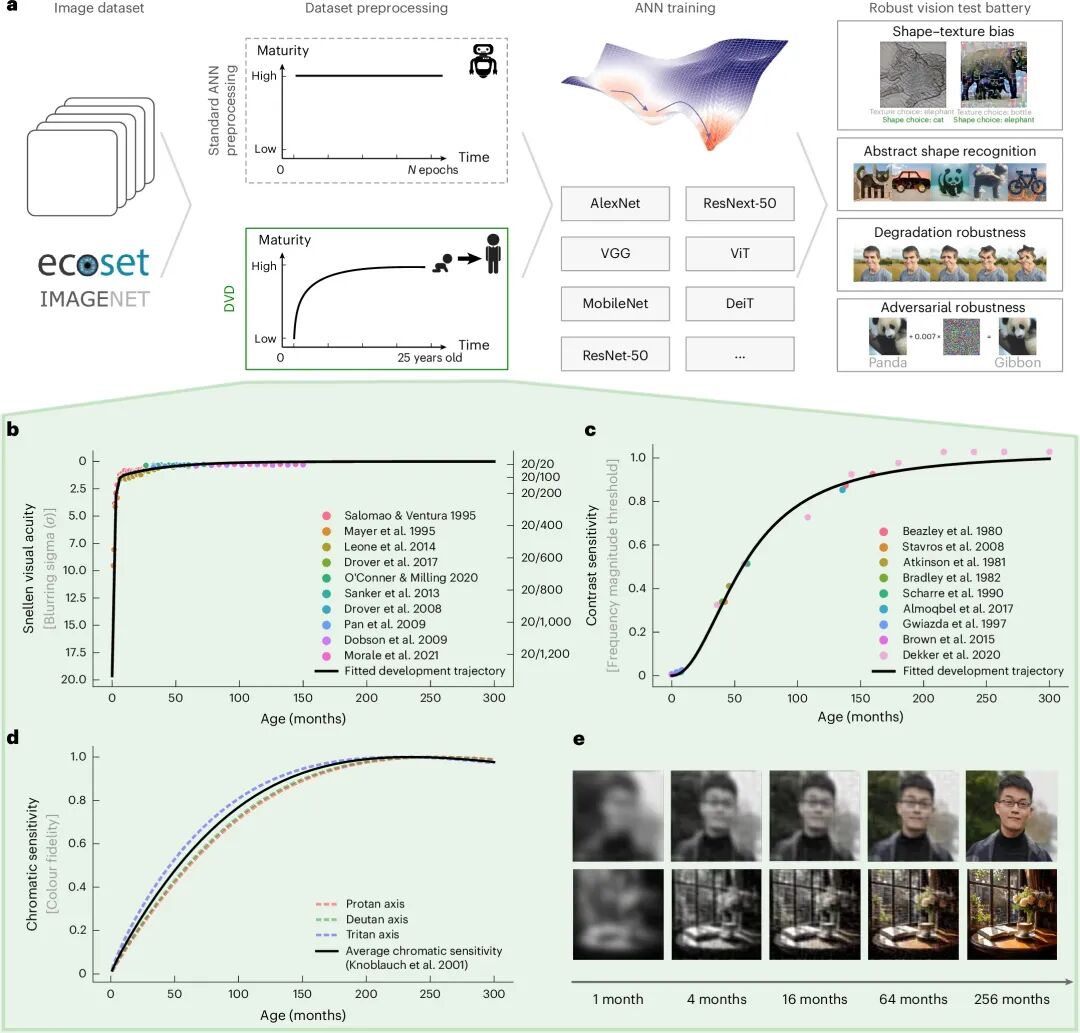
图1构建了从生物学到算法的映射桥梁。人类婴儿并非一出生就拥有高清视觉,其视觉系统在出生后的数年中,会经历视觉 acuity(看清细节的能力)、对比度敏感度(分辨明暗差异的能力)和色彩感知的渐进式成熟。研究团队系统梳理了从新生儿到25岁成人的心理物理学数据,将这些发育轨迹转化为可计算的图像预处理参数。例如,视觉 acuity 的发育被映射为高斯模糊核大小的动态衰减,对比度敏感度被映射为频域滤波的强度变化。DVD流程在训练开始时对输入图像施加强烈的模糊、低对比和去色处理,模拟“婴儿视觉”;随着训练 epoch 的增加,这些退化效应逐渐减弱,最终在训练末期呈现高清图像。这种设计强制模型在早期学习阶段关注全局、低空间频率的形状信息,而非局部的纹理细节。
图2:DVD训练诱导出接近人类的形状偏置
核心看点:DVD证明无需改变模型架构或增加数据量,仅通过改变数据呈现的时序,就能让AI的“思维方式”从“看纹理”转变为“看形状”,这是对齐人类视觉的关键一步。
图2通过经典的“形状-纹理冲突”实验(将大象的纹理贴在汽车的形状上),量化了DVD模型的决策偏好。在标准训练(Baseline)下,ResNet-50模型严重倾向于纹理(Shape Bias ~0.3),即它会将“大象纹理的汽车”识别为大象。而经过DVD训练的模型,其决策偏好发生根本性逆转。通过调节DVD的超参数,研究者得到三种典型模型:DVD-P(性能优先,Shape Bias ~0.7,准确率与基线相当)、DVD-B(平衡型,Shape Bias ~0.8+)、DVD-S(形状偏置优先,Shape Bias ~0.9+)。令人震惊的是,DVD-S模型的形状偏置直接落入人类儿童(4-6岁)的行为区间,显著超越所有对比的SOTA模型(包括自监督模型和大规模视觉语言模型)。
图3:跨数据集与架构的普适性验证
核心看点:DVD不是某个特定模型的“魔术”,而是一种可迁移的训练框架,能够普遍地提升现有视觉模型的形状感知能力。
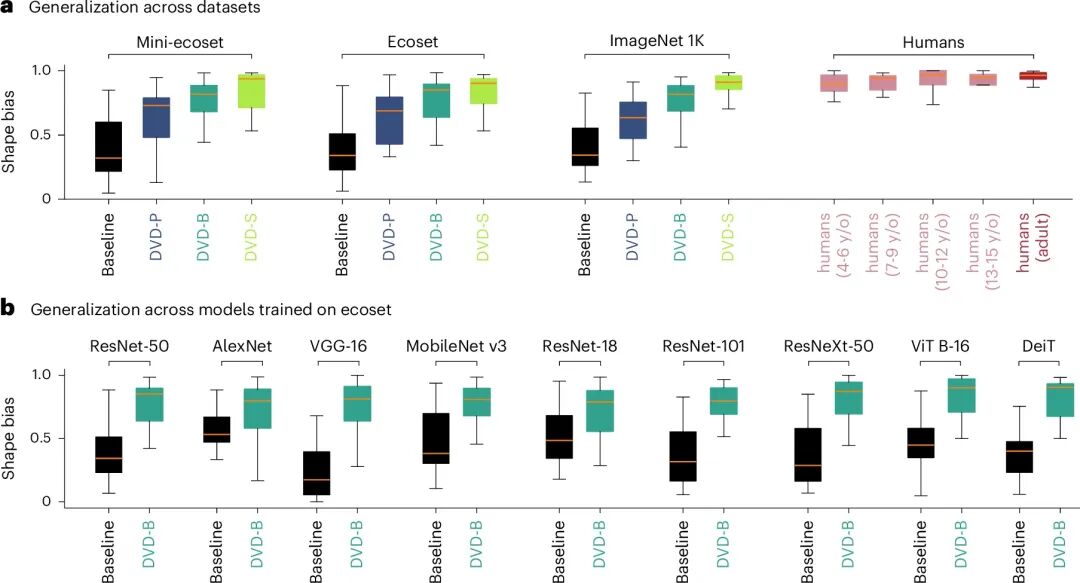
图3验证了DVD方法的泛化能力。首先,研究者在三个不同规模的数据集(mini-ecoset, ecoset, ImageNet-1K)上重复实验,发现DVD-S模型在所有数据集上均能稳定地将形状偏置提升至接近人类水平,证明其不依赖于特定数据集。其次,研究者将DVD-B训练方案应用于8种不同的神经网络架构,包括传统的CNN(如VGG、DenseNet)和现代的Vision Transformer(ViT)。结果显示,所有架构经过DVD训练后,形状偏置均得到显著提升,且提升幅度相当一致。这表明DVD是一种架构无关的通用训练策略,能够广泛适用于各类视觉模型。
图4:DVD如何改变模型的“注意力”
核心看点:DVD的有效性并非来自简单的“模糊”,而是来自对比度调制对模型特征提取策略的根本性重塑。
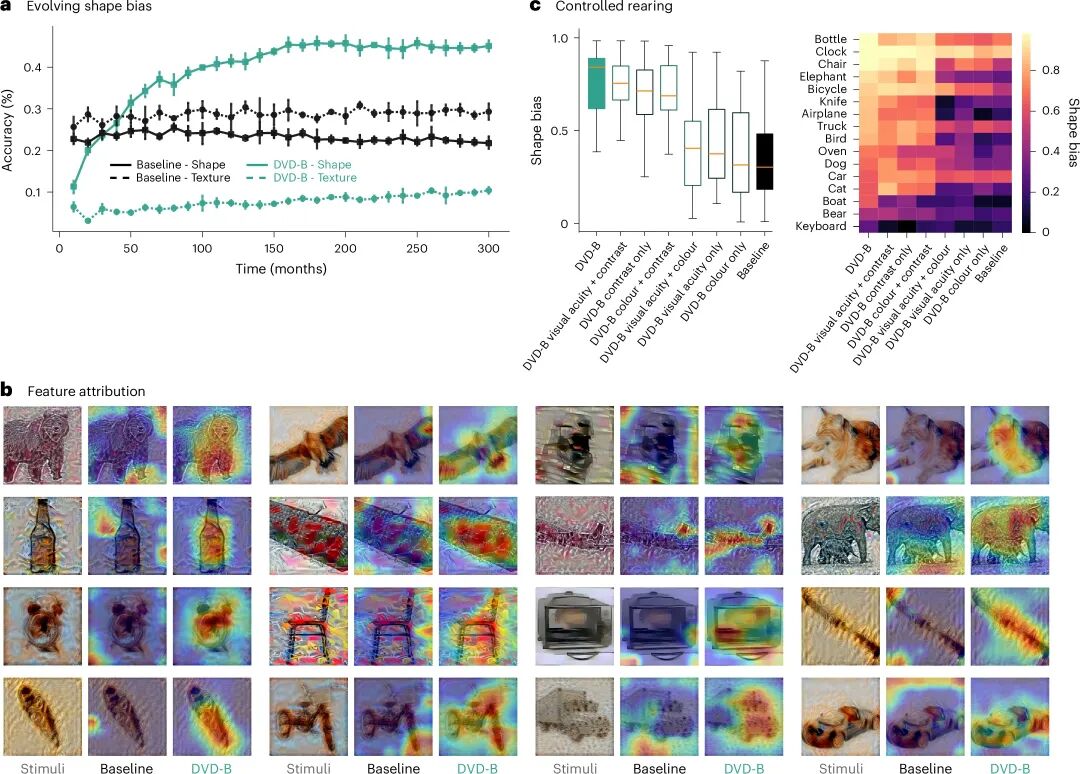
图4深入探究了DVD起效的机制与关键因素。通过分析训练过程中的动态,发现DVD模型在早期(对应人类约20个月大时)就已建立起强烈的形状偏置,并保持稳定,这与人类婴幼儿的发展轨迹相似。通过Grad-CAM可视化模型的注意力热图,发现基线模型关注的是物体表面的局部纹理斑块,而DVD模型则关注物体的整体轮廓和关键部件,其注意力分布更接近人类。最关键的发现来自消融实验:研究者分别关闭DVD中的 acuity、对比度或色彩发育模块。结果发现,对比度敏感度的发育轨迹是提升形状偏置的最强驱动力,其贡献甚至超过单纯的模糊(acuity)。这是因为适度的对比度退化保留物体的全局轮廓,同时抑制高频纹理细节,强制模型学习更具判别力的形状特征。
图5:抽象形状识别与表征分析
核心看点:DVD训练赋予了AI一种类似人类的“完形”感知能力,使其能够忽略杂乱背景,提取并识别出纯粹的几何形状信息。
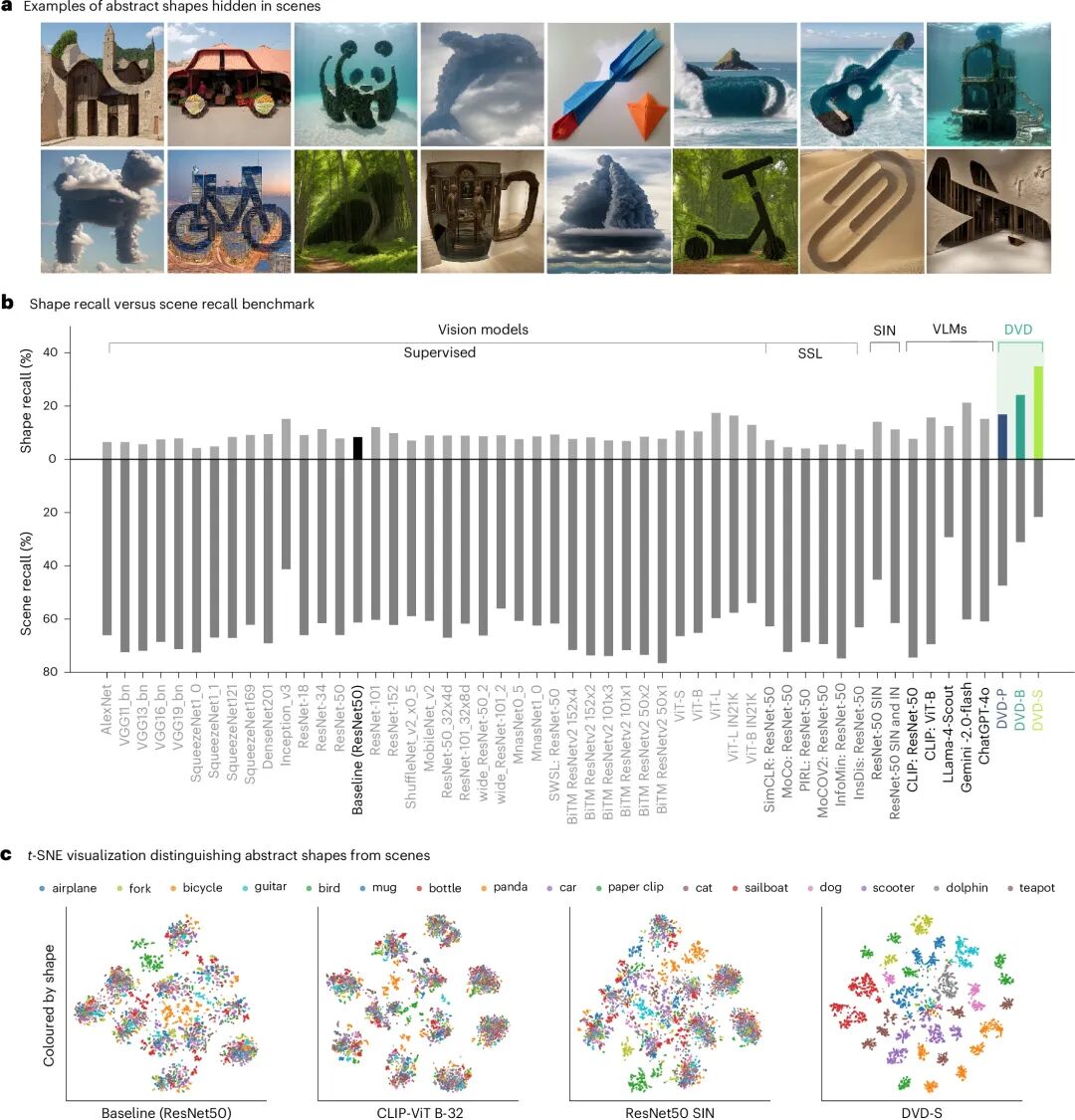
图5展示DVD在更具挑战性的“抽象形状识别”任务上的表现。人类能轻易地从复杂自然场景中识别出由线条构成的抽象形状(如三角形、星形),而现有AI模型往往被背景纹理干扰,无法识别形状。在IllusionBench基准测试中,基线模型(包括CLIP、GPT-4V等VLMs)的抽象形状召回率极低(<20%),而DVD-S模型达到了36.2%,显著优于所有基线。更深入的表征分析(t-SNE可视化)显示,基线模型倾向于将相同背景场景的图片聚在一起(基于纹理/场景聚类),而DVD模型则成功地将相同抽象形状的图片聚在一起(基于形状聚类),证明其内部表征确实编码了形状语义。
图6:对失真与对抗攻击的鲁棒性
核心看点:DVD不仅让AI“更像人一样看”,也让它“更像人一样稳”,为解决AI视觉的脆弱性问题提供了一条数据驱动的有效路径。
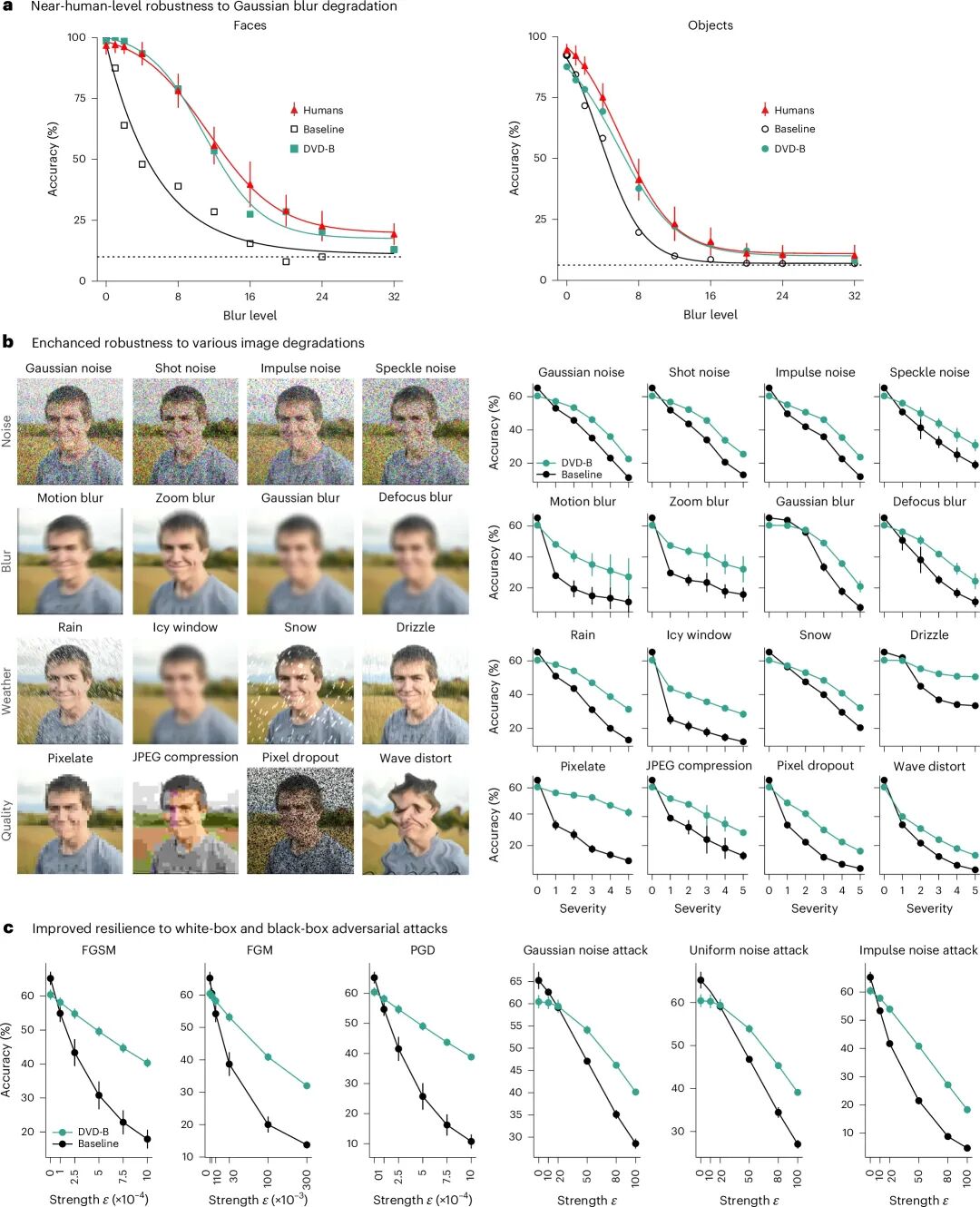
图6验证DVD带来的“副产品”——极强的鲁棒性。由于DVD模型依赖的是全局形状而非局部纹理,它对图像失真(如高斯模糊、噪声、雨雪天气遮挡、JPEG压缩等)具有天然的抵抗力。在15种不同的失真类型测试中,DVD模型在严重失真下的准确率是基线模型的2-4倍,其性能衰减曲线与人类行为数据高度吻合(缓慢下降而非断崖式下跌)。在对抗攻击测试中,DVD模型同样表现出色,无论是白盒还是黑盒攻击,其攻击成功率均显著低于基线模型。这是因为对抗攻击通常针对高频纹理细节进行微扰,而DVD模型根本不依赖这些细节,使得攻击“失效”。

这项研究告诉我们,让AI变强的不一定是更多的数据或更大的模型,而是像养育孩子一样,给它一份科学的“视觉辅食”,让它先学会看世界的大概轮廓,再慢慢看清细节。该研究为AI训练提供“发育对齐”(Developmental Alignment)的新思路,强调训练过程(How to learn)与训练数据同等重要。在形状偏置、抽象形状识别和鲁棒性等多个关键指标上实现突破,且计算成本极低(仅需修改数据预处理流程)。显著提升AI在开放环境(恶劣天气、低质量图像)下的可靠性,并增强其对对抗攻击的防御能力,推动了安全、可信AI的发展。
未来趋势
多模态扩展:将“发育对齐”理念扩展到视觉-语言多模态模型(VLMs)的训练中,让AI在语言理解上也遵循人类认知发展轨迹。
神经科学启发:引入更精细的发育因素,如双眼视觉、运动感知、注意力机制的发展,构建更完整的“仿生”训练轨迹。
产业应用:在自动驾驶、医疗影像、机器人等对鲁棒性要求极高的领域,DVD训练策略有望成为提升模型泛化能力的标准配置。

Zejin Lu, Sushrut Thorat, Radoslaw M. Cichy, et al.Adopting a human developmental visual diet yields robust and shape-based AI vision. Nature Machine Intelligence(2026).
https://doi.org/10.1038/s42256-026-01228-6
往期推荐
 突破后摩尔时代互连极限!三星首创“晶粒取向工程”,原子层沉积钌实现单晶通孔与高定向导线 |
 当nMOS和pMOS不再“共用一种硅”:IMEC用混合沟道CFET打开新思路 |
 IEDM 重磅突破:无锌a-IGO晶体管硬扛550°C热预算,亚10nm垂直DRAM迎来“非晶氧化物”时代 |


