 夜雨聆风
夜雨聆风假设你是一名工程师,你手里有一个很强的模型,你想知道它代码能力到底有多强。直觉上,答案应该是个固定的数字——模型就是模型,它有多强就是多强,对吧?但是真实的结果可能有点反直觉...
2026 年 4 月,安全公司 Endor Labs 把这件事真的测了一遍,他们拿 OpenAI 当时最新的 GPT-5.5,放进两个不同的"运行环境"里跑同一批真实编程任务。第一个环境是 OpenAI 自家的 Codex,也就是这个模型的"原生主场";第二个环境是 Cursor。同一个模型,同样工作时间,同一批任务。在 Codex 里,功能正确率是 61.5%。而到了 Cursor 里,87.2%。中间隔了将近 26 个百分点。没换模型,没微调,没改一个字的 prompt,仅仅是换了个"壳"。
这个"壳",就是今天的主角「Harness」,而围绕它形成了一门新学科:Harness Engineering。也就是大家常说的「驾驭工程」


Harness Engineering可以拆解为六大核心板块:Prompt 系统(System prompt)、工具生态(Function Calling)、上下文工程(Context Engineering)、记忆系统(Agent Memory)、Agent 循环(Agent Loop)、Agent评测与监控(Agent Evaluation)这就是为什么说:Agent = Model + Harness;这六大部分几乎就是一个Agent如何设计,如何构建,最终效果好不好的全部内容了。
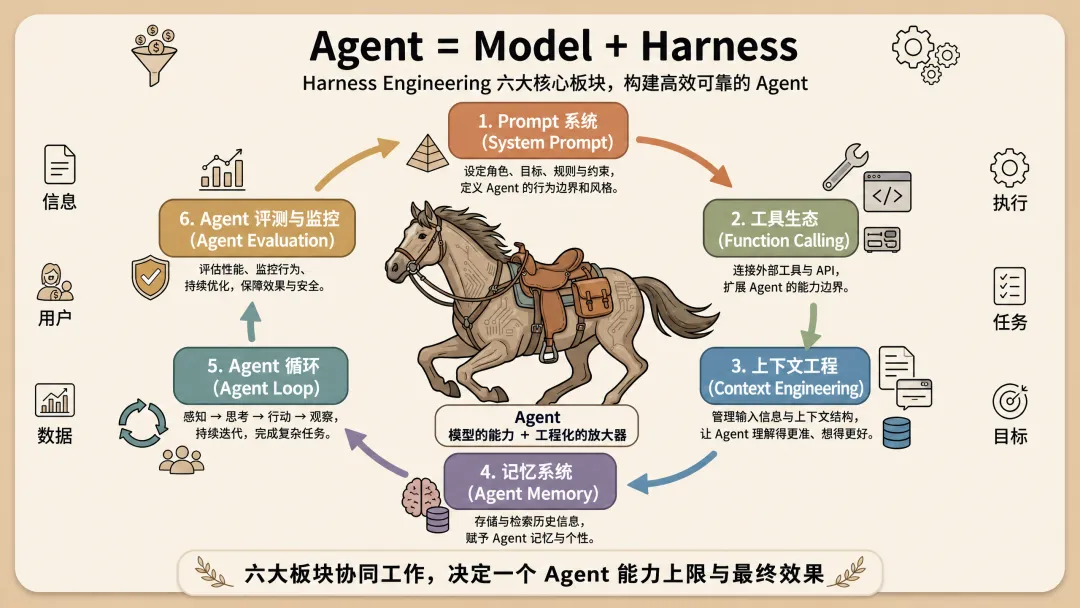
1、Prompt 系统:AI时代的底层代码
Prompt系统是整个Harness的地基,也是最容易被外行所低估的核心组成部分。很多人以为 prompt 就是"用户敲进去的那句话"。但在一个成熟的 Harness当中真正起决定作用的,是用户根本看不见的那套系统级 prompt(System Prompt):它给 Agent 定下身份、交代工作流程、划清红线,还要预设好兜底方案。它决定了Agent怎么干活、会不会干活、干活前需要准备什么、干错了应该怎么办、干完后以哪种规范给到用户。
2、工具生态:Agent和真实世界的接口
没有工具生态(Function Calling)的Model只是个聊天框,能"动手"才叫 Agent。工具生态就是定义这个 Agent 长了哪些手脚:能不能读写文件、能不能跑命令、能不能查数据库、能不能调外部 API。工具的搭建这里有个特别容易被忽略、但极其要命的细节:那就是工具的"说明书"写得好不好。 同一个删除文件的工具说明,描述清晰、带好用法和边界,模型就用得稳;而一段含糊的描述,它可能在错误的时候调用、或者干脆不敢用。
3、上下文管理:决定Agent此刻能看见什么
这是整个 Harness 调优的主战场。模型的注意力是有预算的、有限的,所以上下文管理的核心,就是在每一轮对话当中挑出"信号最强的 token"喂给它。塞太少Agent信息不够只能瞎猜;塞太多关键信息被海量噪音淹没,Agent精度下降、开始走神。而且Context不是配一次就完,是每一轮对话都要重新做一次的动态取舍——所以它既最影响结果,又最难调好。
Claude Code 的 Skills 机制「渐进式披露」就是一个很完美的例子它分三级按需加载:第一级只读YAML描述Agent判断是否调用;第二级才加载完整说明;第三级才去拉引用文件。这就是"用多少拿多少",而不是一上来把整个仓库全塞进去。
4、记忆系统:决定Agent是否拥有自我
上下文管理解决的是"这一轮里看什么",记忆系统解决的是"跨越很多轮、甚至很多天怎么让Agent还记得自己是谁。早先时候大家和模型对话都有体会:你这次费半天劲教会它你的规范、你的偏好、你项目里那些只有你懂的坑,结果一关窗口,下次它又是一张白纸,得从头再教一遍。模型天生就是"金鱼记忆"——每一次新会话都是一次彻底的失忆。而一个好的记忆系统要存的大致是两类东西:短期记忆和长期记忆。短期记忆是任务内的工作状态:一个跑好几小时的长任务进行到哪一步了做过哪些决定。长期记忆是跨任务的长期沉淀:你的习惯、你的偏好、你在项目踩过的坑、这些不该随某一次会话结束而蒸发,而应该攒下来,让 Agent 越用越懂你。
5、Agent 规划循环:Harness的核心发动机
一个真正的 Agent,不是被动等指令,而是会自己把大目标拆成步骤、动手执行、看结果、再调整;这就是Agent 规划循环。例如Anthropic把 Claude Code 的这套规划循环描述得很精炼:搜集上下文 → 动手 → 验证 → 再来一遍。当任务复杂到一个 Agent 啃不动时,规划循环还会往上长一层派生多个专精的子 Agent 分工协作。保证Agent可以循环工作几个小时甚至几天。
6、Agent 评测与可观测性:给狂奔的Agent装上仪表盘
前面几个板块主要关注的是让 Agent 能干活,但你凭什么信它干得对?这就「评测|Evaluation」和「可观测性|Observability」要回答的。评测(Evaluation)是对Agent搭建后的评分拿一批标准任务去考它,看它的功能正确率、安全正确率到底几分;而可观测性(Observability)是实时的监控,它现在在读哪个文件、为什么这么改、下一步要干嘛,全程可见。而这两部分是很多个人甚至企业忽视的部分,我会单独出一篇文章来讲解。
随着各家大厂的模型能力越来越强,模型本身变得像水电煤一样。当所有人都能调到同一批前沿模型,差异化就不再来自模型本身。Harness的作用变得越来越重要。说到底AI 时代的工程开发,正在从"人来写代码",悄悄变成"人来设计那套管理Agent怎么行动的系统";
而Harness Engineering 是一门较为庞大的AI体系,在这篇文章当中PM小易只能大概描述Herness的作用和构成。在这篇文章发布后的半个月时间,我将从Harness的六大组成部分出发一点一点得把整套系统尽可能细节得展示给每一个人。
