 夜雨聆风
夜雨聆风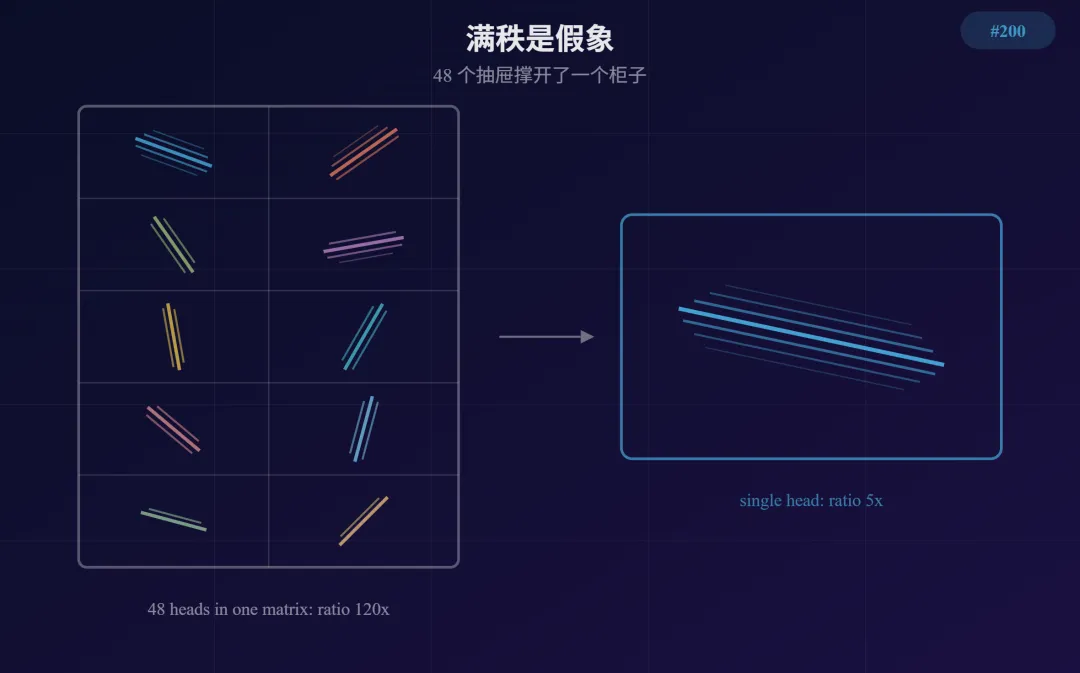
━━━━━━━━━━━━━━━━━━━━
这是第 200 篇(中间有几篇写完没发,公众号实际期数没到 200)。从第 1 篇到现在,换过选题方向,换过写作风格,换过合作的 AI。没换的是读者和好奇心。不煽情,继续学习。
━━━━━━━━━━━━━━━━━━━━
◆ 前情提要
━━━━━━━━━━━━━━━━━━━━
194 期( 【DeepSeek V4】权重空间是弯曲的——满秩是假象,流形只有百维 )在 DeepSeek V4 Flash 280B 上直接测了权重矩阵的几何结构。用了两把尺子:
- eRank
(有效秩):对权重矩阵做 SVD(奇异值分解),把奇异值归一化成概率分布,算信息熵,取指数。它测的是"这块权重在多少个线性独立方向上有分量"——可以理解为量"包围盒"有多大。 - TwoNN
(两近邻法):对权重矩阵的每一行当作高维空间中的一个点,看每个点的最近邻和次近邻的距离比。从这个距离比的统计分布反推出点云的"本征维度"——它测的是"每个点附近的邻居排列得像几维空间"。
两把尺子差一个数量级——eRank 说 1000-3600,TwoNN 说 30-277。当时的结论是:权重空间是弯曲的,线性方法把弯曲误认成了多出来的维度。
195 期( 【线性注意力】直尺擦弯曲的画布——Qwen3.6的遗忘机制准确吗? )把同样的工具搬到 Qwen3.6-27B,测了线性注意力层(DeltaNet)和标准注意力层(GQA)。发现管遗忘/写入的门控权重 ratio 只有 1.5x-2.4x(几乎平直),管内容的 K/V 权重 ratio 42x-91x("严重弯曲")。标题叫"直尺擦弯曲的画布"。
这一期修正 194/195 的核心解释:ratio 不是曲率指标,是子流形拼接的副产品。
但这只是第一层。
真正有意思的不是"之前解释错了",而是错因本身暴露了一个更深的结构:大模型的权重不是一整团连续流形,而是一组低复杂度子空间被分格摆放、相互隔离、局部正交化。
单个 head 没有想象中那么复杂。复杂的是 head 和 head、专家和专家之间的组合拓扑。
换句话说:规模化买到的不是一个越来越复杂的单元,而是越来越多低复杂度单元,以及更精细的隔离方式。
━━━━━━━━━━━━━━━━━━━━
◆ 为什么"弯曲"的解释有问题
━━━━━━━━━━━━━━━━━━━━
想象一条直线段,eRank 看它一维,TwoNN 看它也一维,ratio = 1。
把它掰成 V 形——两条完全平直的线段首尾相接,夹角 90 度。eRank 看到二维(两条臂朝不同方向),TwoNN 看到一维(每个点附近的邻居都在同一条直线上)。ratio = 2。
但两条线段都是完全平直的。ratio = 2 不是因为弯了,是因为两条直线拼在一起。
推广到高维:k 个 d 维子流形拼在一张矩阵里,eRank 约等于 k × d,TwoNN 约等于 d,ratio 约等于 k。ratio 是子流形数量的代理指标,不是曲率指标。
"弯曲"和"拼接"在 ratio 上看起来一模一样,但有一个可验证的区别:如果是拼接,按功能边界拆开后 ratio 应该系统性大幅下降;如果只是单个连续流形的弯曲,拆开未必会稳定帮上忙。
━━━━━━━━━━━━━━━━━━━━
◆ 实验:拆了就降
━━━━━━━━━━━━━━━━━━━━
权重矩阵里最明确的功能边界是 attention head。一个 q_proj 矩阵把 48 个 head 的权重拼在一起存成一张大矩阵。按 head 切开,对每个 head 单独测 eRank 和 TwoNN。
有人会说:head 本来就是拼在一起的,拆开后 ratio 降了,这不是废话吗?
是废话。但 194/195 期拿整个 q_proj 测 ratio 91x-442x,报告说"权重空间弯曲"——没有意识到这个数字里绝大部分来自拼接效应。这篇要做的不是"发现 head 是拼接的"(这确实是废话),而是量化拼接贡献了多少 ratio、拆开后剩下多少。
Qwen3.6-27B q_proj:48 个 head × 256 维
(GQA 层的 Q 投影。GQA 层的 K/V 只有 4 个 head,共享压缩后每个 head 对应 12 个 Q head——head 数太少不适合做拆分分析,所以 GQA 层只测 Q。DeltaNet 层的 V 有独立的 48 个 head,下一节单独测。)
(per-head 列是 48 个 head 的均值。ratio/48 = 假设 48 个 head 完全正交时的理论 per-head ratio。比值 = per-head ratio ÷ ratio/48,反映 head 之间的方向重叠程度:1 = 完全正交,越大 = 重叠越多。)
整体 ratio 54x-442x,拆到 per-head 后全部落到 4.7x-8.9x。 比值 1-5x 说明 head 之间有部分方向重叠但大部分独立。
Qwen3.6-27B DeltaNet V 段:48 个 head × 128 维
DeltaNet 层把 Q/K/V 拼在一张矩阵 in_proj_qkv [10240, 5120] 里。V 段有 6144 行、48 个 head。按 head 拆:
V per-head ratio 在全部深度稳定在 2.1x-2.6x。 整体 ratio 从浅层 41x 涨到深层 102x(V 段整体的 TwoNN 在深层下降),但拆到 per-head 后差异消失——说明深层 V 段的高 ratio 主要来自 head 之间的拼接/正交度变化(比值从 2.1 降到 1.2,越来越接近完全正交),而不是 head 内部结构同步变复杂。
DeepSeek V4 Flash wq_b:128 个 head × 256 维
换一个完全不同的模型。V4 Flash 是 280B 的 MoE(混合专家)模型,注意力用了低秩分解——query 先压缩到 1024 维再展开到 128 head(wq_b [32768, 1024])。和 Qwen GQA 一样,KV 共享压缩(V4 只有 1 个 KV head),只有 Q 有足够多的独立 head 适合拆分分析。按 head 拆 wq_b:
V4 的 43 层交替使用三种注意力:L00/L01 是标准 MLA,偶数层是 CSA(压缩比 4,每 4 个 token 的 KV 压成 1 组),奇数层是 HCA(压缩比 128,用 hash 选 top-k KV)。CSA 和 HCA 配对测:
注意:MLA 架构中 head 之间设计上就共享低秩表示(1024 维瓶颈),不像 Qwen 的 head 是独立拼接的。所以整体 ratio 本来就不高(5-45x),不能简单用"整体 ratio / head 数"来推断 head 间正交度。
per-head ratio:CSA 层 4.4x-6.6x,HCA 层 2.8x-6.2x,整体约 3-7x。 和 Qwen 的 Q 类 4.7x-8.9x 在同一量级。
━━━━━━━━━━━━━━━━━━━━
◆ 真正的发现
━━━━━━━━━━━━━━━━━━━━
发现一:单个 head 的复杂度跨模型收敛
27B vs 280B,dense vs MoE,架构完全不同——但同类 head 内部的 ratio 落在同一范围。两者 head 维度不同(Q 256 维,V 128 维),不能直接比较功能复杂度,但共同点是:拆分后的 ratio 都远低于整体矩阵暗示的程度。
这说明一件事:head 内部的局部几何复杂度可能不是随模型规模无限增长的。
Qwen 的 Q head 是 4.7x-8.9x,DeepSeek 的 Q head 是 3.0x-6.6x。一个 27B,一个 280B,参数差 10 倍,单个 head 的 ratio 没有差 10 倍,甚至没有差 2 倍。
这很像一个架构常数:注意力头作为一个计算原语,内部复杂度有上限。模型变大,主要不是把单个 head 训练成更复杂的怪物,而是增加 head 数、专家数、层数,以及它们之间的组合方式。
这比"满秩是假象"更重要。
如果后续 Llama、Mistral、MiniMax、Kimi 等开源模型的同类 head 也落在 3-9x 附近,那就可以提出一个可复现的经验定律:
attention head 的局部几何复杂度是架构级常数,规模增长主要体现为子流形数量和拓扑组织的增长。
────────────────────
发现二:中间层会出现 head 正交化窗口
Qwen 的 q_proj 是 48 个独立 head 拼接的。如果 head 方向完全正交,整体 ratio / 48 应该等于 per-head ratio:
比值 1-5x,说明 head 之间有部分方向重叠但大部分独立。严格验证还需要直接算 head 子空间相似度、principal angles(主角)或余弦矩阵;这里的 ratio 除法关系先作为一个粗略代理指标,用来判断 head 间方向重叠的大致趋势。
L07 比值 1.0 是个有趣的异常——head 之间几乎完全正交。更有意思的是,相邻层也出现同类现象:
L08 没有 L07/L09/L10 那么极端,更像过渡层。但这个小窗口里至少出现了三个强信号:整体 ratio 暴涨,per-head ratio 正常。也就是说,高 ratio 不是单个 head 内部复杂化,而是 head 之间的方向关系被重新拉开。
这不像"某个 head 突然变复杂了"。更像模型在这个深度区间做了一次坐标整理:单个 head 仍然是正常复杂度,但 head 之间被训练推开,方向变得更独立。
可以把它叫作 正交化窗口。
它的功能可能不是处理某类具体知识,而是把前面层混在一起的表示重新分格摆放,减少后续层的串扰。
这和人类直觉里"越深越抽象、所以每个模块越来越复杂"不一样。数据更像在说:
深层复杂度不一定来自单元变复杂,也可能来自单元之间更干净地分开。
(V4 的 wq_b 不能做这个分析——MLA 架构中 head 之间设计上就共享低秩表示,不是独立拼接。)
────────────────────
发现三:DeltaNet 深层压力表现为防串扰
DeltaNet V 段还有一个更隐蔽的信号。
整体 V ratio 从浅层 41x 涨到深层 102x,看起来像"深层 V 内容越来越复杂"。但按 head 拆开以后,per-head ratio 始终稳定在 2.x。
这意味着深层变化不在 head 内部,而在 head 之间。
DeltaNet 的状态矩阵大小固定,每个 head 都要把历史信息压进 128×128 的格子里。越到深层,概念越抽象,方向越容易互相蹭到。这个时候,模型有两条路:
让单个 head 内部变复杂; 让不同 head 的方向更分开,减少写入串扰。
数据更支持第二条。
所以 195 期那条"直尺擦弯曲画布"要改写成更准确的一句话:
线性注意力的深层压力,表现为 head 间正交化,而不是 head 内复杂化。
这可能是混合架构里 25% GQA 层必须存在的另一个几何解释:DeltaNet 用固定状态矩阵省缓存,但固定空间会带来串扰;模型一边用 head 正交化降低串扰,一边保留标准 attention 做高清校准。
────────────────────
发现四:alpha/beta 的低 ratio 是测量尺度问题(顺手修正 195 期)
195 期还说 DeltaNet 的 alpha/beta 门控权重"全模型最平直"(ratio 1.5x-2.4x),和 K/V 内容通道的 42x-91x 形成对比。但 alpha/beta 只有 [48, 5120]——一行对应一个 head,48 个点。拿 48 个点测"本征维度"然后说"好平直啊",就像拿一颗棋子和一盘棋比"复杂度"。
V 投影拆到 per-head 后 ratio 1.76x-2.41x——和 alpha/beta 的 1.5x-2.4x 重合。所以 195 期不能把 alpha/beta 的低 ratio 直接解释成"门控比内容简单"。 更保守的解释是:alpha/beta 天然少了一层多 head 拼接膨胀,而且 48 点样本使 TwoNN 估计本身不稳。K/V 的高 ratio 大部分来自多 head 拼接。至于 per-head ratio 里还有多少是真正的弯曲,这篇没有深入测。
────────────────────
发现五:专家不是一起变复杂,而是开始分化
DeepSeek V4 Flash 每层 256 个专家,每个专家有独立的权重矩阵。对每层抽 4 个专家(× 3 个矩阵 = 12 个 ratio):
最值得看的不是均值,是标准差——从 L00 的 4.0 涨到 L30 的 40.9,增大了一个数量级。浅层专家内部结构都差不多(最大/最小不到 3 倍差距)。深层出现极端分化(7 倍差距)。深层专家不是均匀变复杂,是分化了:部分高度特化,部分保持通用。
这和 head 的故事是同一个方向:模型规模化不是把每个单元都推向同一种高复杂度,而是让不同单元承担不同角色。
head 是正交化分区。expert 是功能分化分区。两者合起来,才是大模型真正的几何结构。
━━━━━━━━━━━━━━━━━━━━
◆ 总结
━━━━━━━━━━━━━━━━━━━━
194 期说"满秩是假象,流形只有百维"——判断方向没错,但解释错了。
修正后的一句话:满秩不是因为信息铺满了整个高维空间,而是因为多个低维子流形被拼在一张矩阵里,撑开了包围盒。
但更重要的一句话是:
大模型不是一整块越来越复杂的流形,而是一套分格摆放的子空间系统。
按功能边界拆开后,ratio 从一到两个数量级降到个位数。两个架构完全不同的模型,per-head ratio 收敛到同一范围(Q 类 4-9x,V 类 2-3x)。中间层出现 head 正交化信号。DeltaNet 深层 V 的整体 ratio 上升,主要不是 head 内复杂化,而是 head 间隔离增强。深层专家内部的方差暴涨一个数量级,说明专家不是一起变复杂,而是开始分化。
这期真正的发现不是"弯曲解释错了",而是:
模型把智能拆成了一堆低复杂度子空间,然后用正交化和专家分化把它们隔开。
如果将来微调或记忆更新能定位到子流形级别——"这条知识属于哪个 head、哪个专家"——操作精度会比在整张矩阵上动刀高得多。但那是下一步的事。这篇先把结构看清楚:不是揉成一团,而是分格摆放。
━━━━━━━━━━━━━━━━━━━━
◆ 复现
━━━━━━━━━━━━━━━━━━━━
代码和完整数据开源在 GitHub:
https://github.com/lmxxf/ai-theorys-study/tree/main/arxiv/wechat200
Zenodo 存档:DOI 10.5281/zenodo.20364987
需要一张 8GB 显存的消费级显卡 + 对应模型权重。逐矩阵流式分析,峰值显存不到 1GB。
━━━━━━━━━━━━━━━━━━━━
◆ 参考文献
━━━━━━━━━━━━━━━━━━━━
Roy & Vetterli, "The Effective Rank: A Measure of Effective Dimensionality", EUSIPCO 2007 Facco et al., "Estimating the intrinsic dimension of datasets by a minimal neighborhood information", Scientific Reports 2017 Aghajanyan et al., "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning", ACL 2021 Yang et al., "Gated Delta Networks: Improving Mamba2 with Delta Rule", ICLR 2025
━━━━━━━━━━━━━━━━━━━━
// 靳岩岩的 AI 学习笔记 × Claude 的严谨 × Gemini 的浪漫
// 2026-05-25
