 夜雨聆风
夜雨聆风一、为什么需要模板计算?
科学计算中最核心的任务之一,是对 偏微分方程(PDE 求数值解。 以三维热传导方程为例:
其中 是温度场, 是热扩散系数。 这类方程在计算流体力学、地震模拟、电磁场仿真中无处不在。 要在计算机上求解它,必须先完成两步转化。
1.1 离散化:
将连续的物理空间切分成规则点阵,每个格点存储一个数值,这就是离散化。 三维问题对应边长为 的立方体网格,共 个格点,格距为 。
1.2 有限差分
离散化之后,连续导数无法直接计算,需要用邻点函数值来近似。 对 关于 的二阶导数,利用泰勒展开:
两式相加,消去奇数项,得到二阶精度的中心差分公式:
差分阶数越高,需要的邻点越多,精度也越高。 下图展示了一维情况下,一阶(3点)、二阶(5点)、三阶(7点)模板随阶数增加邻点增多的过程:
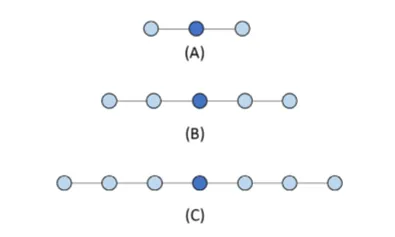
图 1:一维差分模板的阶数对比。(A) 一阶:中心点 + 左右各 1 个邻点,共 3 点; (B) 二阶:中心点 + 左右各 2 个邻点,共 5 点; (C) 三阶:中心点 + 左右各 3 个邻点,共 7 点。 阶数越高,差分截断误差越小,但每次计算依赖的邻点越多,访存开销也越大。
将三个方向的差分公式代入拉普拉斯算子,对网格点 有:
三维七点模板的本质就是 每个输出点是中心点加上 六个轴向邻点的加权和,权系数由差分精度决定。
二、模板计算的基本原理
| 离散化 | |
| 模板运算 | |
| 模板遍历 |
常见模板类型
根据维度和阶数的不同,模板形状差异显著:
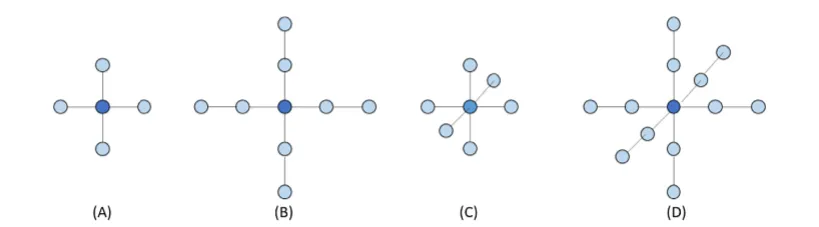
图 2(Figure 8.3):常见模板形状对比。 (A) 二维五点模板(一阶):中心 + 上下左右 4 邻点,用于二维泊松/热传导方程; (B) 二维九点模板(二阶):中心 + 上下左右各 2 邻点,每轴向精度更高; (C) 三维七点模板(一阶):中心 + 前后左右上下 6 邻点,三维 PDE 最常用; (D) 三维 13 点模板(二阶):每轴向取 2 个邻点,共 12 邻点 + 中心,精度更高。 深色圆点为中心点(当前计算目标),浅色圆点为参与加权求和的邻点。
三、模板计算CUDA 核函数实现
3.1 从网格到一维内存:寻址方式
GPU 内存本质上是一维线性空间,二维/三维网格需要手动线性化存储。 如下图所示,对于二维情形,五点模板的中心点(蓝色)在线性内存中的位置 并不相邻于其上下邻点,访问时需要额外的跨行跳转:
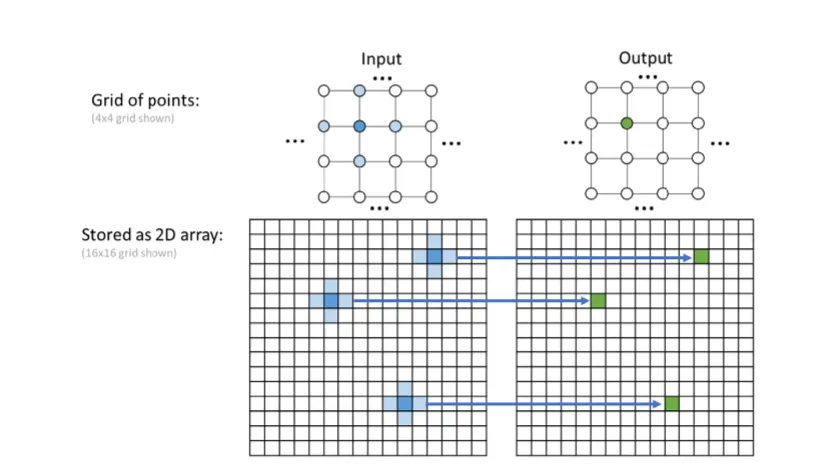
图 3(Figure 8.4):二维网格的存储方式与五点模板的内存访问模式。 上方: 网格中,蓝色为输入模板涉及的点(中心 + 4 邻点), 绿色为对应的输出点。 下方: 网格以二维数组形式存储时, 中心点的左右邻点在内存中连续,而上下邻点则相距一整行(步长为 )。 这说明同一 warp 内的线程若沿行方向(
k方向)分配, 可实现合并访问;而跨行访问(j或i方向)则会产生非连续访存。
三维情形下,坐标 的线性下标为:
方向在内存中连续,因此应将 映射到 threadIdx.x, 让同一 warp 的 32 个线程访问连续地址,实现合并访问(coalesced access)。
3.2 核函数结构
三维七点模板的基础实现思路非常直接:一个线程负责一个网格点。
// 差分系数(由差分精度推导,此处为拉普拉斯算子归一化示例)__constant__ float c0 = -6.0f, c1 = 1.0f, c2 = 1.0f;__constant__ float c3 = 1.0f, c4 = 1.0f, c5 = 1.0f, c6 = 1.0f;__global__ void stencil_kernel(const float* __restrict__ in, float* out,unsigned int N){// 将线程ID映射到三维坐标unsigned int k = blockIdx.x * blockDim.x + threadIdx.x; // x方向(内存连续方向)unsigned int j = blockIdx.y * blockDim.y + threadIdx.y; // y方向unsigned int i = blockIdx.z * blockDim.z + threadIdx.z; // z方向// 只处理内部点,跳过边界if (i >= 1 && i < N-1 && j >= 1 && j < N-1 && k >= 1 && k < N-1) { out[i*N*N + j*N + k] = c0 * in[i*N*N + j*N + k] // 中心点 + c1 * in[i*N*N + j*N + (k-1)] // x-1 + c2 * in[i*N*N + j*N + (k+1)] // x+1 + c3 * in[i*N*N + (j-1)*N + k] // y-1 + c4 * in[i*N*N + (j+1)*N + k] // y+1 + c5 * in[(i-1)*N*N + j*N + k] // z-1 + c6 * in[(i+1)*N*N + j*N + k]; // z+1 }}3.3 几个细节说明
边界处理:跳过最外层一圈点,防止越界。 实际工程中边界条件通常单独设置(Dirichlet、Neumann 等)。
__restrict__ 修饰:告知编译器 in 和 out 不存在指针别名, 有助于编译器生成更优化的内存访问指令。
四、性能瓶颈分析
4.1 运算访存比
分析基础核函数的计算强度:
每个输出点:7 次乘法 + 6 次加法 = 13 FLOPs 内存访问:读取 7 个 float(28 字节)+ 写入 1 个float(4 字节)= 32 字节
现代 GPU(如 A100)的峰值算力约 312 TFLOPS(FP32),内存带宽约 2 TB/s, 理论机器屋脊线 ≈ 156 OP/B。0.41 OP/B 距此相差约 380 倍, 属于极度内存带宽受限的计算,GPU 的计算单元大量空转。
4.2 与卷积的对比
模板计算与卷积的根本区别在于邻域形状: 模板只取坐标轴方向的点(稀疏),卷积取整块方形邻域(密集)。
| 三维七点模板 | 7 | 13 | ~3.25 OP/B |
"理论访存比上限"指在完全数据复用假设下(每个输入字节只从内存读一次)的上限值。 维度和阶数越高,模板与同规模卷积的差距越大。
五、共享内存分块优化
5.1 基本思路
GPU 的共享内存(Shared Memory)位于片上,延迟约 1~5 ns, 是全局内存(~300 ns)的 100 倍以上。分块优化的思路是:
将输出网格划分为若干 Output Tile(输出块) 每个线程块负责计算一个输出块,先将对应的**输入块(含 Halo)**整体搬入共享内存 在共享内存上完成全部模板计算,避免反复访问全局内存
输入块 vs 输出块的关系如下图所示:
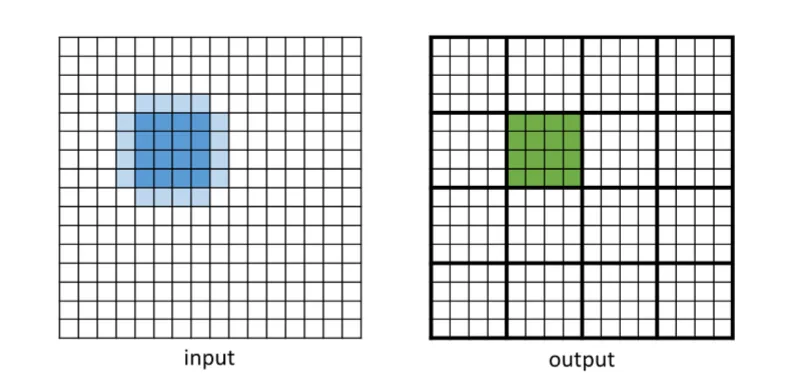
图 4:二维五点模板下,输入块(蓝色)与输出块(绿色)的关系示意。 深蓝色区域为输出块(Output Tile),浅蓝色外圈为Halo 区域, 即模板计算所额外依赖的边缘邻点。 右图绿色为最终写入的输出块,输出块的边长比输入块小 2(每侧各缩 1)。 三维情形下,Halo 扩展到六个面,输入块边长 。
5.2 分块核函数实现
#define OUT_TILE_DIM 6#define IN_TILE_DIM (OUT_TILE_DIM + 2) // = 8__global__ void stencil_tiled_kernel(const float* __restrict__ in, float* out,unsigned int N){// 全局坐标:减1以让线程块向外扩展一格,覆盖halo区域int k = blockIdx.x * OUT_TILE_DIM + threadIdx.x - 1;int j = blockIdx.y * OUT_TILE_DIM + threadIdx.y - 1;int i = blockIdx.z * OUT_TILE_DIM + threadIdx.z - 1; __shared__ float in_s[IN_TILE_DIM][IN_TILE_DIM][IN_TILE_DIM];// 阶段一:所有线程协作将输入块(含halo)加载到共享内存if (i >= 0 && i < (int)N && j >= 0 && j < (int)N && k >= 0 && k < (int)N) { in_s[threadIdx.z][threadIdx.y][threadIdx.x] = in[i*N*N + j*N + k]; } else { in_s[threadIdx.z][threadIdx.y][threadIdx.x] = 0.0f; // 边界外填零 } __syncthreads(); // 必须等所有线程完成加载// 阶段二:只有输出块内部线程(去掉halo层)执行计算if (i >= 1 && i < (int)N-1 && j >= 1 && j < (int)N-1 && k >= 1 && k < (int)N-1) {if (threadIdx.z >= 1 && threadIdx.z < IN_TILE_DIM-1 && threadIdx.y >= 1 && threadIdx.y < IN_TILE_DIM-1 && threadIdx.x >= 1 && threadIdx.x < IN_TILE_DIM-1) { out[i*N*N + j*N + k] = c0 * in_s[threadIdx.z ][threadIdx.y ][threadIdx.x ] + c1 * in_s[threadIdx.z ][threadIdx.y ][threadIdx.x-1] + c2 * in_s[threadIdx.z ][threadIdx.y ][threadIdx.x+1] + c3 * in_s[threadIdx.z ][threadIdx.y-1][threadIdx.x ] + c4 * in_s[threadIdx.z ][threadIdx.y+1][threadIdx.x ] + c5 * in_s[threadIdx.z-1][threadIdx.y ][threadIdx.x ] + c6 * in_s[threadIdx.z+1][threadIdx.y ][threadIdx.x ]; } }}5.3 代码细节说明
坐标偏移 -1 的:threadIdx.x = 0 对应输入块左边界 halo 点, threadIdx.x = IN_TILE_DIM-1 对应右边界 halo 点, 中间 [1, IN_TILE_DIM-2] 的线程才对应有效输出点。 偏移 -1 正是让每个线程块的坐标范围向外扩展一格,使线程与共享内存下标对齐。
双重边界判断:
第一层:防止加载时访问超出网格 [0, N)的地址(越界保护)第二层:确保只有有效内部点(全局坐标在 [1, N-2],且局部坐标排除 halo 层)才写入输出
__syncthreads():这个屏障同步是正确性保证,不是性能优化。 必须等 IN_TILE_DIM³ 个线程全部完成加载,才能进入计算阶段读取共享内存。
5.4 性能提升量化
分块后,每个输入块的数据只从全局内存读取一次,在共享内存上被多个相邻输出点复用。 运算访存比公式:
当 (对应 ):
相比基础核函数的 0.41 OP/B,提升约 3.3 倍。 当 ,比值趋向理论上限 OP/B。
六、硬件限制:为什么分块不能做大?
6.1 线程数上限
CUDA 规定单个线程块最多 1024 个线程。三维分块时:
因此实际工程中, 只能取 8 或 10。
6.2 共享内存上限
一个 SM 上的共享内存通常为 48~164 KB(视 GPU 型号而定)。三维输入块占用:
三维情形下内存增长是立方级别,即使线程数允许,共享内存也会成为新的瓶颈。
6.3 Halo 开销问题
当 ():
超过一半的全局内存读取发生在 Halo 区域,而 Halo 点不产生输出,对计算毫无贡献。 这是三维模板计算相对于二维情形更难优化的根本原因:维度越高,Halo 占比越大。
6.4 内存访问模式问题
的线程块在访问 、 方向邻点时, 一个 warp(32 线程)会跨越多个不连续的内存行,难以实现完美的合并访问, 实际带宽利用率会进一步打折。
七、总结
共享内存分块已将运算访存比提升至 1.37 OP/B,但距离理论上限 3.25 仍有 2.4 倍差距。 三维模板计算始终是内存带宽受限的计算模式,无法通过简单分块突破。
进一步提升性能需要更激进的优化手段:
线程粗化(Thread Coarsening):一个线程负责沿某方向的多个输出点, 在寄存器层面复用相邻层的数据(又称"pencil"优化) 寄存器分块(Register Tiling):将 方向的滑动窗口数据缓存到寄存器, 极大降低对共享内存的依赖 循环展开与指令级并行:结合 #pragma unroll,减少分支开销异步预取:使用 memcpy_async隐藏 Halo 数据的加载延迟
