第三章设计稿转代码工具链把设计变成能用的前端,是 AI 见效最直接的场景。这一章先给一张全景图,再把你点名的 Google Stitch、Figma、Pencil、Open Design 逐个拆开讲,顺带补几个最近很火的工具,最后说选型。3.1 全景图:三种路子2026 年的设计转代码工具,大致是三种路子。选之前先想清楚自己要的是哪一种。设计转代码的三种路子:先想清楚自己要哪一种3.2 Google StitchGoogle Stitch 是 Google Labs 在 2025 年 Google I/O 上推出的 AI UI 设计工具,底层是 Gemini,目前免费。它的玩法很直白:用一句话或者一张图描述你想要的界面,Stitch 直接给你生成 UI,还能导出代码。能做什么底层模型。跑在 Gemini 2.5 Pro 上,文字和图片都能看懂。一次出一堆。一次给你多套设计变体、多屏布局、Material Design 3 组件,还自带浅色和深色两版。原型能点。生成的是可点击的原型,不是静态图,方便拿去做用户测试或者汇报。代码能导。能导出 HTML/CSS 和组件级代码,也能导回 Figma 继续编辑,或者接进 Google AI Studio、Antigravity 去搭完整应用。2026 年 3 月的大更新2026 年 3 月,Stitch 从一个单屏生成器升级成了多屏原型工作台。现在能一次生成最多 5 个互相连通的屏幕,加上 AI 原生的无限画布、语音输入和一个设计 Agent,导出还支持 7 种框架的生产级代码,已经在正面对标 Figma 和一批 AI 设计创业公司了。
适合谁会写代码但没什么设计功底的前端。Stitch 能给你一个有样式、有结构的起点和一份能改的代码,比对着空白 HTML 发呆强多了。一句提醒:它的产物到不了资深设计师的水准,定位是一个不错的起点,后面还得你自己加工。
3.3 Figma:Dev Mode MCP、Figma Make、Code Connect设计稿转代码,源头多半还是 Figma。2025 到 2026 年它在 AI 这边补齐了三块能力,前端值得重点掌握。① Dev Mode MCP Server(强烈建议先学这个)Figma 在 2025 年推出了官方的 MCP Server,把设计文件里的结构化内容通过 MCP 暴露给 AI 编程工具,包括 VS Code 里的 Copilot、Cursor、Windsurf、Claude Code 等等。它是高保真还原的地基。它给的是结构化数据,不是截图。节点树、变体信息、布局约束、设计变量(design tokens)、资源引用都有,这些在截图里都看不到。好处。因为能引用到具体的变量、组件、样式,生成的代码更准,也更省 token,做设计系统和组件化的时候尤其顺手。双向打通。2025 年底开始还能把代码结果推回画布,设计和代码两头能对上。② Code Connect(让 AI 用你自己的组件)Code Connect 做的事,是把 Figma 里的设计组件,对应到你代码仓库里真实的那个组件。这层映射会通过 Dev Mode 进到 MCP 的返回里。这样 AI 不会另写一个按钮,而是直接调你项目里的那个 Button。想把 AI 的产物真正接进现有设计系统,这一步是关键。③ Figma Make(一句话出应用)Figma Make 在 Config 2025 上发布,2025 年 7 月正式可用。你用自然语言描述,它会生成一个基于 React 加 Tailwind CSS 的、能交互的真实原型,在 Code 标签里还能看和复制底层代码。它有个挺好用的点选即改:直接点预览里的某个元素,让 AI 只动那一块,比反复重写整段提示快多了。
价格和获取(2025 到 2026 的情况)Dev 席位在 Professional 年付方案里大概 12 美元每月起,含 Dev Mode、Code 属性、MCP Server 访问和 FigJam。MCP 在测试期免费,以后可能改成按量付费。Figma Make 所有用户都能用,但发布、私享、AI 额度、导入设计库这些高级能力,得看你的付费方案。
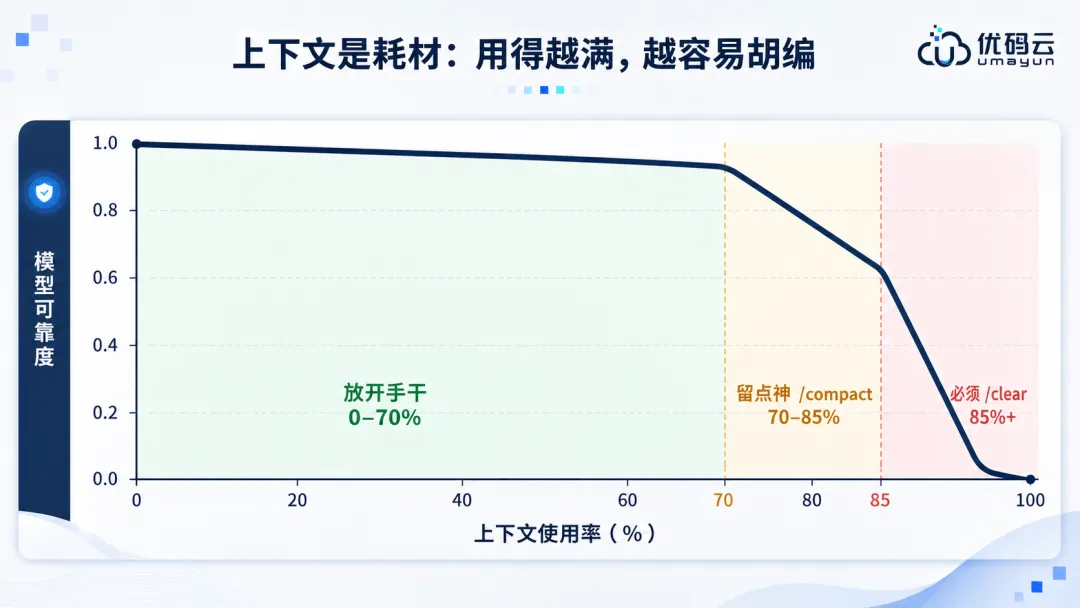
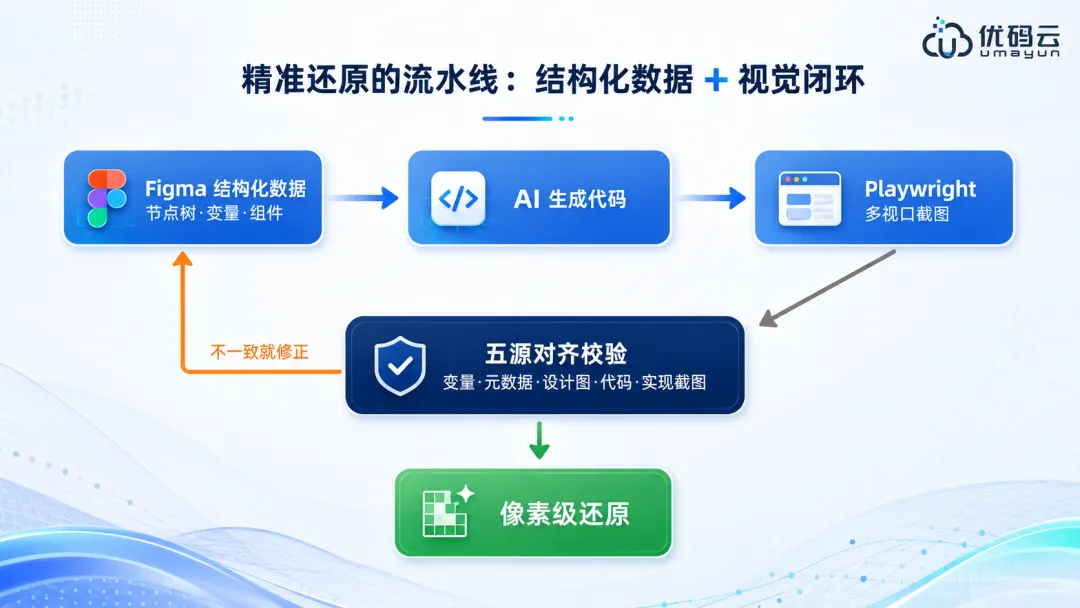
第五章把设计稿精准还原成页面让 AI 把设计稿或者截图高保真地还原成页面,是前端用得最多、也最容易翻车的需求。这一章给一套能照搬的方法,把还原从碰运气变成有把握的工程。5.1 AI 为什么会还原翻车先弄清楚为什么会失败,才好对症下药。截图丢了太多信息。一张图里没有图层结构、间距规则、设计变量、组件层级,也没有响应式约束,AI 只能靠猜。提示太含糊就会发散。一句"做个登录页",会逼着 AI 替你做几十个你没说的决定,而且每次决定还不一样。细节它看不准。自定义图标、图表、精细间距、字体度量,光靠眼睛看容易有偏差。没有验证环节。没有对照和回看的机制,AI 自己也不知道差在哪。5.2 一条原则:给结构化数据,别只给截图最靠谱的还原路径,是让 AI 拿到设计的结构化事实,而不是一张像素图。拿 Figma 当唯一标准。通过 Dev Mode MCP 让 AI 直接读节点树、布局约束、设计变量、组件映射,这些在截图里都看不见。用 Code Connect 复用组件。让生成的代码去调项目里真实的组件和 token,别另起炉灶重写一套,从源头上保证一致。跟设计 token 对齐。把颜色、间距、字号统一到 token 体系里,AI 出的东西自然就贴规范。5.3 五源对齐有个被实践验证过的高保真技巧:让 AI 交叉比对五个来源,五个都对上的时候,结果最接近像素级。
来源
作用
① 设计变量(tokens)
定下颜色、间距、字号、圆角的标准答案
② 设计元数据(节点和约束)
定下布局、层级、自动布局规则
③ 设计稿截图
提供整体视觉参照
④ AI 生成的代码
待校验的实现
⑤ 实现渲染后的截图
把实现拉回来跟前三个对
五个来源都对齐,基本就到像素级了。只要有一个对不上,就去定位差异、改掉、再比一遍。5.4 视觉闭环:让 Playwright 帮你截图比对这一步是把 AI 看不准变成 AI 能自查的关键。通过 Playwright MCP,Agent 可以自己开浏览器、点进页面、对每一页截图,再把实现截图和参照图放在几个视口下对比,自动改到视觉对上为止,全程不用你一张张手动对。为什么管用。Anthropic 的最佳实践里说得很直接:让 Claude 能验证自己的工作,比如跑测试、对比截图、校验输出,是单点最划算的一招。结构快照更省。Playwright MCP 能给出可访问性的结构快照,比直接发截图省 token,也更快更稳。怎么落地。给 Claude Code 装上 Playwright 插件或者 MCP,让截图、对比参照、修改、再截图变成一个自动循环。精准还原的流水线:结构化数据负责对得准,视觉闭环负责改得对5.5 高保真还原的提示词模板下面这个模板按项目替换占位符就能用,完整版见附录 B。
第六章完整学习路线规划这一章给一条能照着走的成长路线,从会用 AI 工具,一直到能用 AI 做全栈、做 AI 应用。对有一年以上前端经验的人,整体大概 6 到 12 个月,看你投入多少、目标定多高。6.1 总路线和时间
阶段
周期
目标
产出
阶段一 · 打基础
第 1 到 4 周
把 AI 工具用进日常前端工作
能用 Cursor 或 Claude Code 做功能、还原页面
阶段二 · 工程化
第 2 到 4 个月
Agent 工作流加上下文工程加自动化
CLAUDE.md、MCP、视觉闭环、可复用技能
阶段三 · 拓展
第 4 到 9 个月
往全栈 AI 和 AI 应用走
Python 加 LLM API、RAG、Agent、作品集
前端转 AI 的学习时间轴,约 6–12 个月6.2 阶段一:打基础挑一个主力 Agent,建议先用 Cursor 过渡,再配一个 CLI(Claude Code),两边都跑通它改我审这个循环。拿真实工单练手,让 AI 修 bug、加小功能、写测试,逼自己养成先看方案再放行的习惯。把第二章的概念和提示词原则吃透,顺手建一个自己的提示词片段库。完整做一次设计稿到页面的还原,用 Figma Dev Mode MCP 加截图闭环。6.3 阶段二:工程化给主力项目写 CLAUDE.md 或 .cursor/rules,把架构、命令、规范、禁区沉淀下来。接 MCP:Figma、Playwright、数据库,把视觉回归、测试、评审都自动化。练 vibe 加 spec 的混合打法,原型阶段快糙猛,定稿了写规格再实现。再上第二个、第三个 Agent,形成日常、架构、后台的分工。把重复套路沉淀成 Skills 或 Subagents,记得先确认需求真实再加。6.4 阶段三:拓展这一步能把你和只会前端的人拉开差距。好消息是前端经验在这里大量复用,异步、API、状态机都用得上。Python 和基础(第 1 到 3 个月)。你已经会编程,这一步是学语法不是学概念,目标是把 Python 用熟。LLM API 和提示词工程。直接调各家模型的 API,把函数调用、工具调用搞明白。RAG(检索增强生成)。动手搭一个能用的检索问答系统。Agent 框架。比如 LangGraph,骨子里是状态机,把你 Redux、Zustand 那套经验迁过来。部署和作品集。把成果真正上线,攒下两三个能体现前端加 AI 组合的项目。
作品集怎么挑挑能凸显你这个稀缺组合的:一个带 RAG 后端的流式聊天界面;一个带 React 仪表盘的 AI 代码评审工具;一个带实时可视化的多 Agent 系统。
6.5 技能树
层级
能力
工具层
Cursor、Claude Code、Codex;Figma Dev Mode MCP、Playwright MCP
方法层
提示词工程、上下文工程、vibe 和 spec 的取舍、视觉还原闭环
工程层
规则文件、MCP 集成、自动化测试和视觉回归、Skills 和 Subagents
拓展层
Python、LLM API、RAG、Agent 框架、部署
软技能
拆需求、审方案、对 AI 产出的判断和验收、团队协作
6.6 30、60、90 天计划
周期
重点
能交付的东西
第 1 到 30 天
让主力 Agent 进日常,完整做一次设计还原
用 AI 做完 5 个以上真实工单,一个像素级还原的页面
第 31 到 60 天
把 CLAUDE.md、MCP、视觉闭环工程化
项目规则文件,接好 Figma 和 Playwright,自动视觉回归
第 61 到 90 天
多 Agent 分工,开始碰 Python 和 LLM
沉淀 3 个以上 Skills,做完第一个 LLM API 小应用
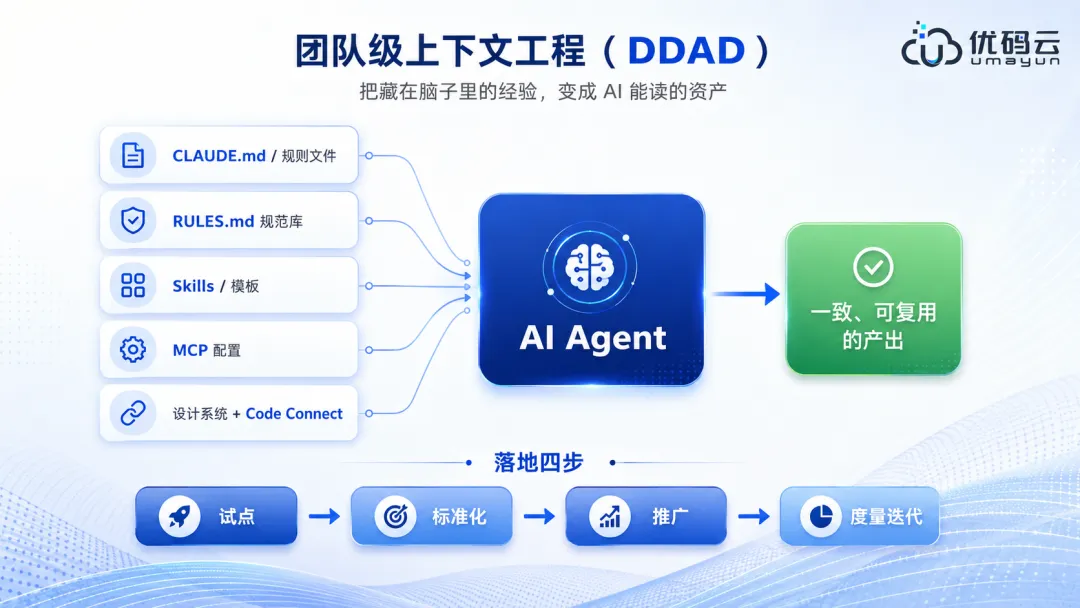
6.7 资源清单官方课程。Anthropic 的 Claude Code in Action(免费)、Introduction to MCP;OpenAI Codex 的官方文档和更新日志。文档。code.claude.com/docs 的最佳实践、developers.figma.com 的 MCP 文档、modelcontextprotocol.io。社区。GitHub 上的 Claude Code Ultimate Guide 这类开源学习仓库,还有 roadmap.sh 的 AI Engineer 路线。动手项目。从把现有前端项目接上 AI 工作流开始,比光看教程有用得多。第七章公司前端团队怎么转 AI Coding个人会用 AI,和团队层面把 AI 变成稳定产能,是两码事。这一章写给带团队、或者要推动落地的人,讲方法、度量和治理。7.1 团队转型难在哪一致性。vibe coding 一个人写很爽,但多人协作时同一个需求出十种写法,技术债很快就堆起来了,大概三个月就会撞墙。知识在脑子里。架构约定、规范、踩过的坑,没沉淀成 AI 能读的形式,AI 每次都得重新猜。不敢规模化。团队担心 AI 产出的质量、安全和合规,没有验收闭环就不敢放开用。工具各搞各的。每个人一套,缺统一的规则文件、MCP 配置和最佳实践。7.2 DDAD:用文档驱动开发2025 年逐渐成型的一种团队打法叫 DDAD,全称 Document-Driven AI Development,文档驱动的 AI 开发。核心是把最佳实践和约束写进 CLAUDE.md、RULES.md 这类文档里,让文档成为团队协作的底座。转变在哪。开发者从写代码,转向打磨可执行的共识,更像是在指挥一支 AI 乐队。收益。业界有实践报告说这种模式能明显提升交付效率,有的案例提到大概四成五。关键是把藏在人脑里的隐性知识变成显性的、AI 能复用的东西。和 spec-driven 是一脉相承的。都是拿规格或文档当唯一标准,让上下文和底线跨会话、跨 Agent 都保持一致。7.3 团队级的上下文工程把第二章讲的上下文工程放大到团队规模,是转型的技术核心。
资产
内容
作用
CLAUDE.md / AGENTS.md / .cursor/rules
架构、技术栈、目录约定、命令、代码规范、禁区
每次会话自带团队背景,产出一致
RULES.md 或规范库
命名、提交、评审、安全红线
统一怎么做,少发散
Skills 和模板
把一个功能怎么标准化生产教给 AI,从领域建模到架构脚手架再到实现绑定
可复制的标准产能
MCP 配置
统一接 Figma、Playwright、内部数据和服务
全员同一套能力,少踩坑
设计系统加 Code Connect
把设计映射到真实组件和 token
AI 还原时直接复用,保证一致
有些企业级工具(比如 Tabnine 的企业上下文引擎)会去学组织自己那套代码架构和规范,确保生成的代码符合内部的安全和合规要求。如果是自建,用上面这套文档体系加私有 MCP,也能做到类似效果。团队级上下文工程:把经验沉淀成 AI 能读的资产7.4 落地四步第一步,试点。找一个小而真实的项目,两三个意愿强的工程师,先写个精简的 CLAUDE.md,在真实生产里跑两周。第二步,标准化。把试点里磨出来的规范、提示词、MCP 配置、还原流水线固化成团队资产。Skills 和 Subagents 等需求被验证了再加。第三步,推广。做内部分享、结对,把规则文件和模板推到更多项目,再配一份 AI 工作流的内部文档和值班答疑。第四步,度量和迭代。用指标验证收益,持续打磨文档和流程,具体看 7.5。7.5 度量和 ROI
维度
可以看的指标
效率
需求交付周期、PR 合并时长、设计还原工时、每个任务的 token 消耗
质量
缺陷率、视觉回归通过率、返工率、可访问性达标率
采纳
AI 参与的 PR 占比、活跃使用人数、规则文件覆盖了多少项目
体验
工程师满意度、上手时间、重复劳动少了多少
一个提醒:先量出基线再推广,不然没法证明收益。第一批度量优先挑 AI 收益明显的前端活,比如设计还原、样式重构、补测试。7.6 风险和治理代码质量。把先看方案再放行、自动测试、视觉回归设成合并的硬门槛,AI 产出一样要走 code review。安全合规。明确数据和密钥不进提示,私有代码用本地或企业版工具,敏感场景可以选本地优先的方案,比如 Open Design 那种自带密钥、本地运行的。别堆技术债。约定不能随便加新依赖,要求复用现成的组件和 token。可追溯。把规格、决策文档和变更记录都留好,受监管行业尤其要做到。7.7 角色会怎么变转型做得好的团队,工程师的价值会往上走:从亲手敲实现,转到定义意图和约束、设计上下文、审阅验收、把控架构和质量。前端不会消失,而是变成既懂体验、又能高效带着 AI 干活的人。这正好是稀缺、也值钱的位置。第八章一个端到端的实战案例用一个例子把前面的方法串起来:把一个 Figma 营销落地页做成生产组件。假设技术栈是 React 加 TypeScript 加 Tailwind,已经有现成的设计系统。场景和目标设计师交来一个 Figma 文件,里面有 Hero、特性卡片、价格表、FAQ 和页脚。要求是像素级还原、复用现有组件、三档视口自适应、可访问性达标,并且一个工作日内交出能评审的 PR。一步步怎么走① 准备上下文。确认 CLAUDE.md 里写清了技术栈和组件库路径,在 Figma 里配好变量和 Code Connect 映射。② 接工具。在 Claude Code 里接上 Figma Dev Mode MCP 和 Playwright MCP。③ 先探索。让 AI 先生成整页草稿,快速判断组件拆分合不合理。④ 再固化。把组件拆分、命名、交互状态写成一份简短规格,当作这次实现的标准。⑤ 实现加闭环。选中各帧,照第五章的模板派活。AI 读结构化数据生成代码,Playwright 在 375、768、1440 截图,按五源对齐校验,自动改。⑥ 终检。照 5.6 的清单人工复核可访问性、状态、资源、代码质量,跑 lint、类型、测试。⑦ 交付。提 PR,CI 跑视觉回归当合并门槛,评审过了再并进设计系统。端到端实战:从 Figma 到上线的七步为什么这么做能成结构化数据保证对得准,视觉闭环保证改得对,规则文件保证风格一致,自动门槛保证质量可控。整个过程你都在当指挥:定意图、设边界、审方案、验结果。这也正是转型之后的主要工作形态。附录 A 名词表
 夜雨聆风
夜雨聆风