 夜雨聆风
夜雨聆风过去五十年(1965-2015)的半导体产业是很无聊的。在摩尔定律(Moore's Law)的统治下,整个产业只需要做一件事——把晶体管做小。节点每缩小一代,延时更低,面积密度更高,功耗也更低,你好我好大家好,不用做取舍。产业链只需要围绕这一条主线自然分工。代工厂缩小晶体管,设计公司拿到更快器件跑更高频率,系统厂商拿到更强芯片做更好产品。所有人同时受益,不需要额外协调。
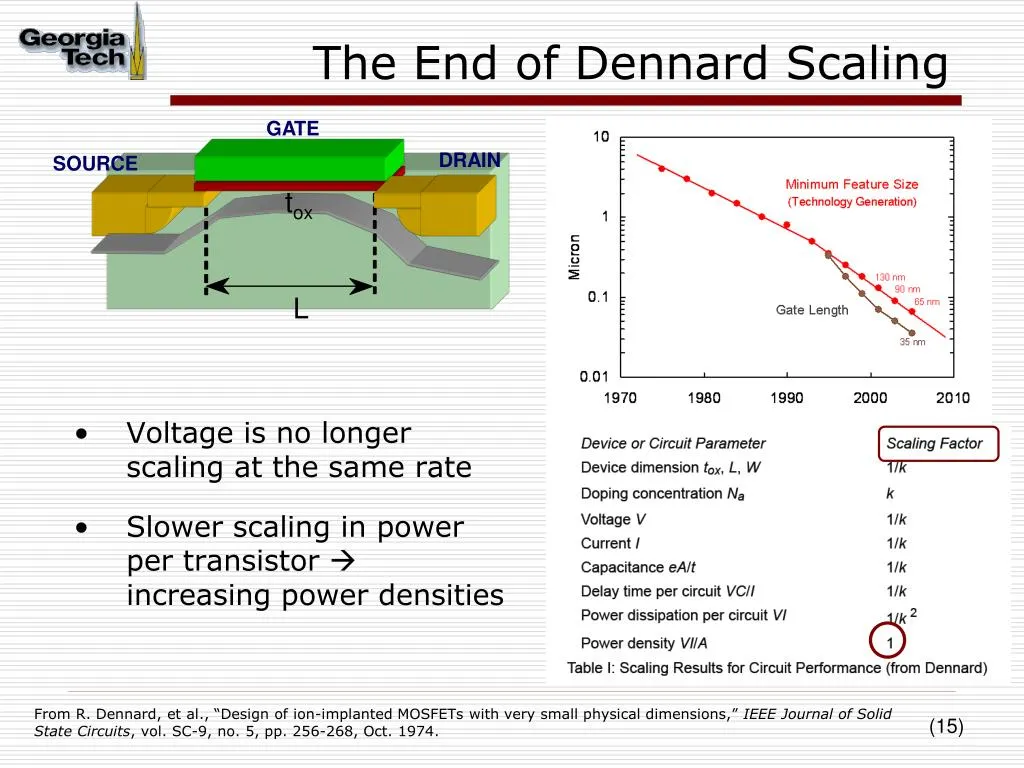
现在这个好日子到头了。晶体管小到接近原子尺度后,各项指标开始像打地鼠:缩小沟道想提速,量子隧穿让漏电止不住,功耗冒出来;缩细金属线想提密度,线电阻飙升,延时反而更大。继续缩的收益越来越薄,代价越来越重。不说那些叽里咕噜的东西,我们普通人对摩尔定律的放缓其实也是有感知的。2016年的电子产品和2006年的相比像是两个时代,而2026年的产品比起2016年却没什么变化。手机、电脑、电视、电器几乎都是如此。
摩尔定律彻底终结,芯片尺寸被“锁死”,是整个行业迟早要面对的问题。贸易战之后,以华为为代表的中国芯片企业被切断了先进制程的供应,不得不提前直面这个问题:如果无法继续沿着摩尔定律往下走,芯片该怎么如何设计?六年的探索和 381 颗量产芯片的经验,让华为提出了“τ 定律(τ Scaling Law)”——一个号称要接替摩尔定律的新定律。
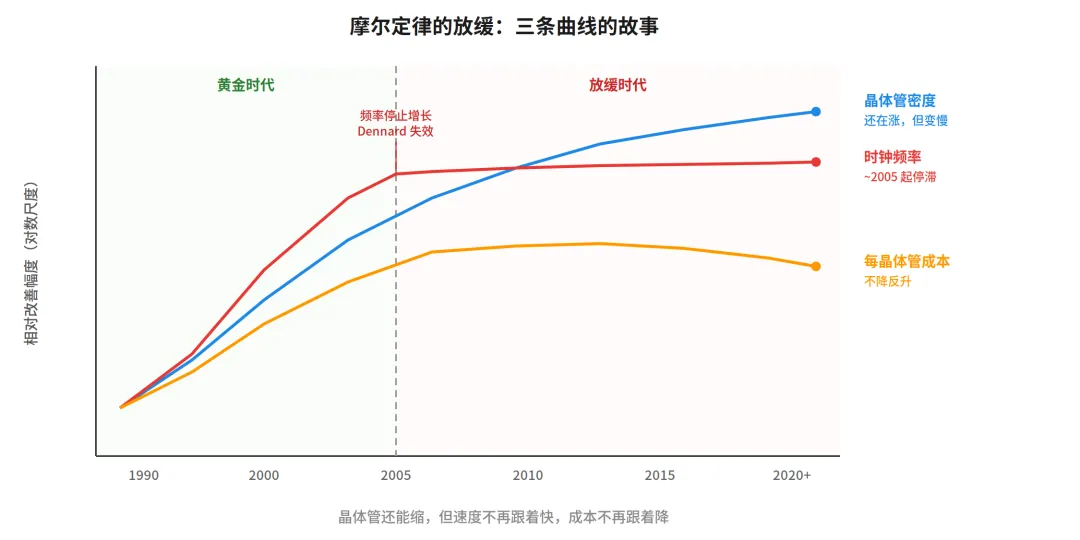
τ 定律的本质是抓大放小:既然延时面积功耗等指标已经无法既要又要,那我们就主攻最重要的一个指标——延时,而将其他指标降格到设计空间去权衡取舍。只要延时能降下来,功耗大一些、成本高一些,都可以接受。因为数据中心不缺物理空间,面积大一些不致命;中国的电力供应不是硬瓶颈,功耗高一些也可以承受。而延时降低所带来的更快的AI推理、更及时响应的自动驾驶、更高的办公效率,都可以实实在在地转化为生产力。
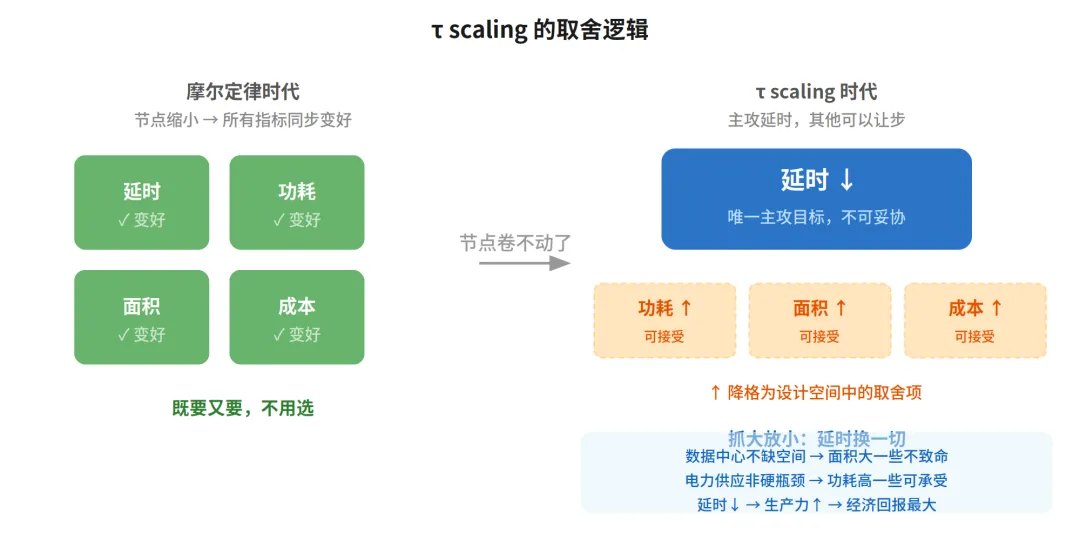
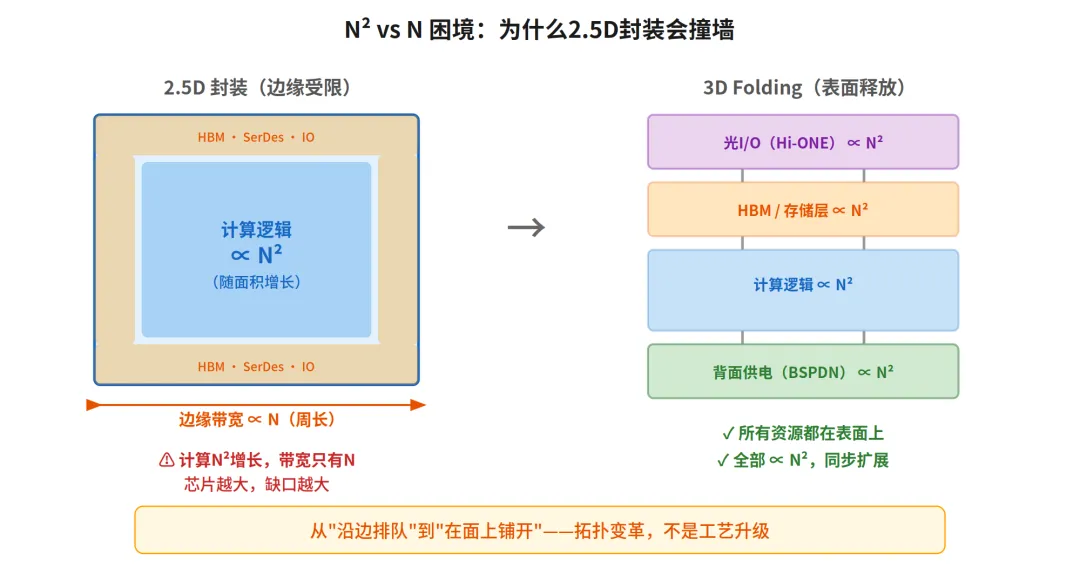
当目标只是更低的延时,我们就不必再死磕先进制程了。华为的核心替代方案是“3D 堆叠”。传统芯片所有逻辑门平铺在一个平面上,信号水平跑几毫米,线越长延时越大。 3D 堆叠把这个平面竖起来:逻辑门垂直堆叠成多层,层间用混合键合连接,原本几毫米的水平走线变成几微米的垂直通孔,延时急剧下降。
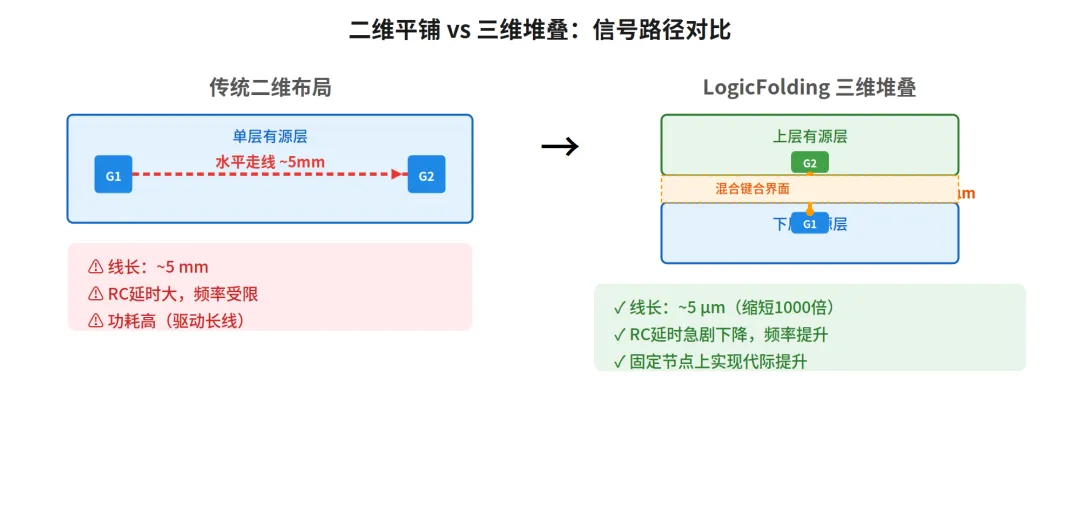
在何总的论文里,这套技术在不同层有不同名字。在电路层它叫 LogicFolding,把关键路径逻辑门分到上下两层,走垂直方向缩短信号路径,固定节点上把频率提上去;在系统层它叫 3D Folding,传统封装中内存、供电、IO 全挤在芯片边缘,带宽受限于周长,3D Folding把这些资源搬到表面,从沿边排队变成在面上铺开,带宽瓶颈随之打开。
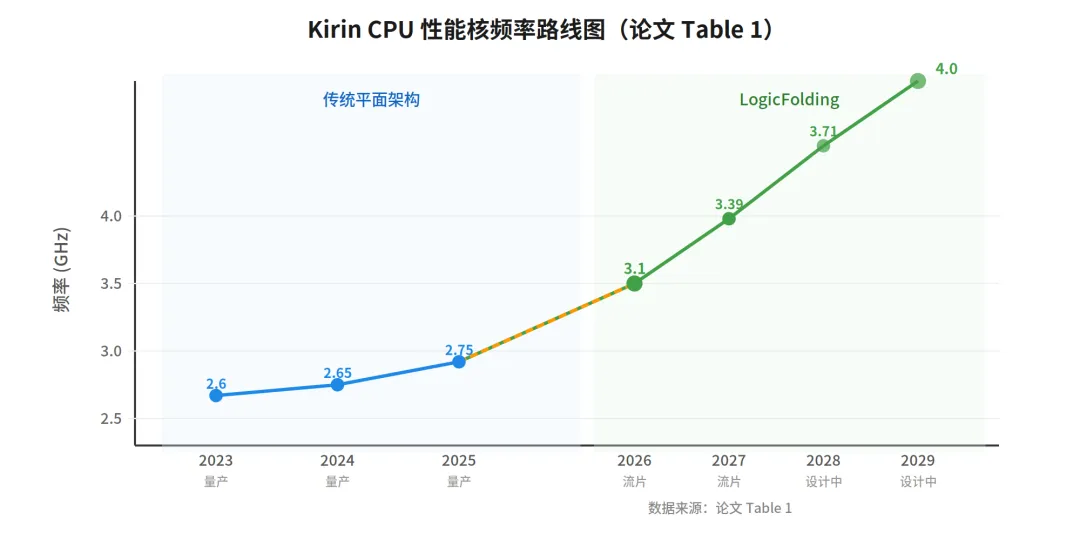
麒麟芯片的成功证明了这条路走得通。当然,3D 堆叠不是华为独创。AMD 的3D V-Cache、台积电 SoIC、Intel Foveros都在同一方向上,只是切入角度和集成深度各有不同。
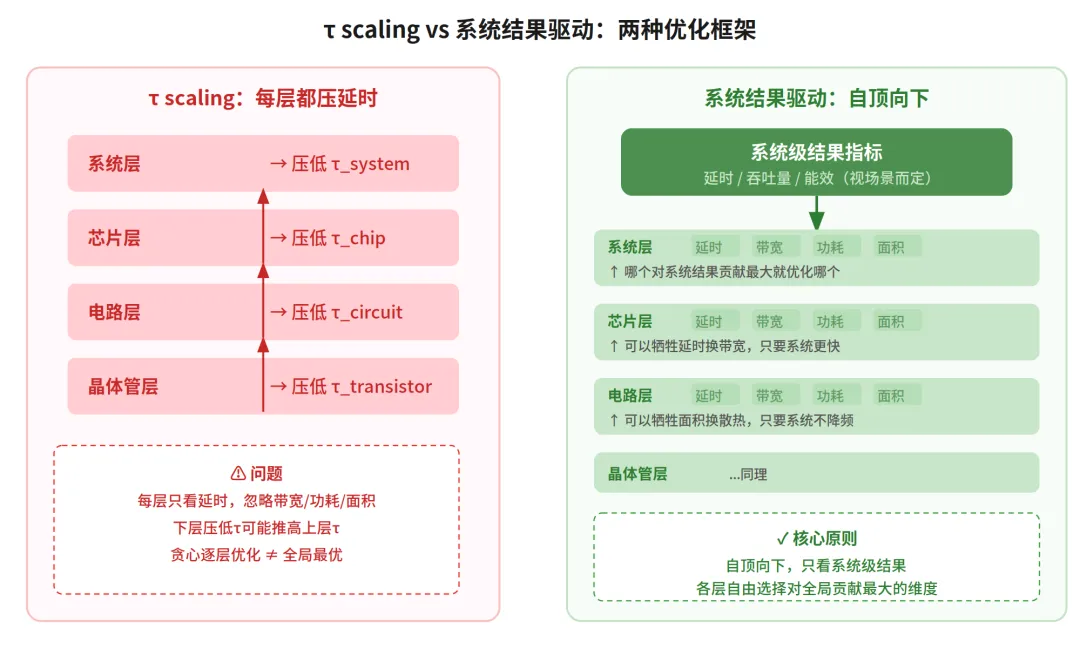
但 τ 定律的理论框架似乎有一些别扭的地方。论文的核心公式把整体τ写成晶体管、电路、芯片、系统四层τ的函数,并为每一层指出了降低τ的手段,似乎在说只要每层各自把自己的τ压低,整体τ就自然降低。

但现实没这么简单。下层τ的降低往往伴随代价,这些代价可能反而会推高上层τ。
比如说,3D 堆叠虽然缩短了线长降低了电路层延时,但恶化了散热,可能导致芯片层被迫降频,上层τ反而增加。
再比如说,GPU 的访存延时很高,但在 AI 训练场景下,访存延时完全可以被大规模线程切换隐藏,继续压低访存延时对系统几乎没有收益。
这本质上是贪心算法的问题,每一步都选择局部最优解,最终不一定能获得全局最优解。所以,工程实践中反而常常主动牺牲局部延时来换取带宽或热预算,让系统整体更快。
因此,或许一个更准确的框架应该是:以系统级结果为唯一指标,具体延时、吞吐量或能效都可以,取决于场景;而底下各层不预设优化方向,延时、带宽、功耗、面积往哪个方向动都是合法选择,以对系统结果贡献最大为准。
说到底,从学术的角度来讲,τ 定律并没有贡献全新的认知,从某些角度上看它还有点以偏概全的嫌疑,强行让所有维度的设计以降低各自延时为唯一目标。
但从产业的角度看,它就是华为面向半导体产业的一则宣言,向业界传达一个认知:不要总是“制程挂帅”,3D 堆叠、全栈协同等方向,同样可以给芯片带来不亚于甚至优于尺寸微缩的收益。它告诉代工厂多投 3D 堆叠而非只追节点,告诉 EDA 厂商开发 3D 原生工具链,告诉存储厂商准备好逻辑与内存的再融合。
就像曾经摩尔定律的作用一样,华为希望把 τ 定律作为整个行业的节拍器,为失去方向感的产业重新设定节奏。
参考文献:
Tingbo He.A Time Scaling Theory for Multi-Layer Electronic Systems.ChinaXiv.[DOI:10.12074/202605.00224]
可视化:Claude Opus 4.6
