 夜雨聆风
夜雨聆风设计一个具有特定功能的蛋白质,曾经如同在浩瀚的序列宇宙中寻找一根针。传统方法如定向进化靠“瞎蒙乱试”,理性设计依赖昂贵且稀缺的结构信息,二者都难以高效穿越这片序列荒漠。
人工智能正在彻底改变这一局面。从精准预测结构到从零生成全新蛋白,AI让蛋白设计从“试错艺术”变成了“预测科学”。本文将沿着最新综述《AI-driven protein design》的图示脉络,带你一步步走进这场技术革命。

第一篇:三代进化史——AI蛋白设计工具的前世今生
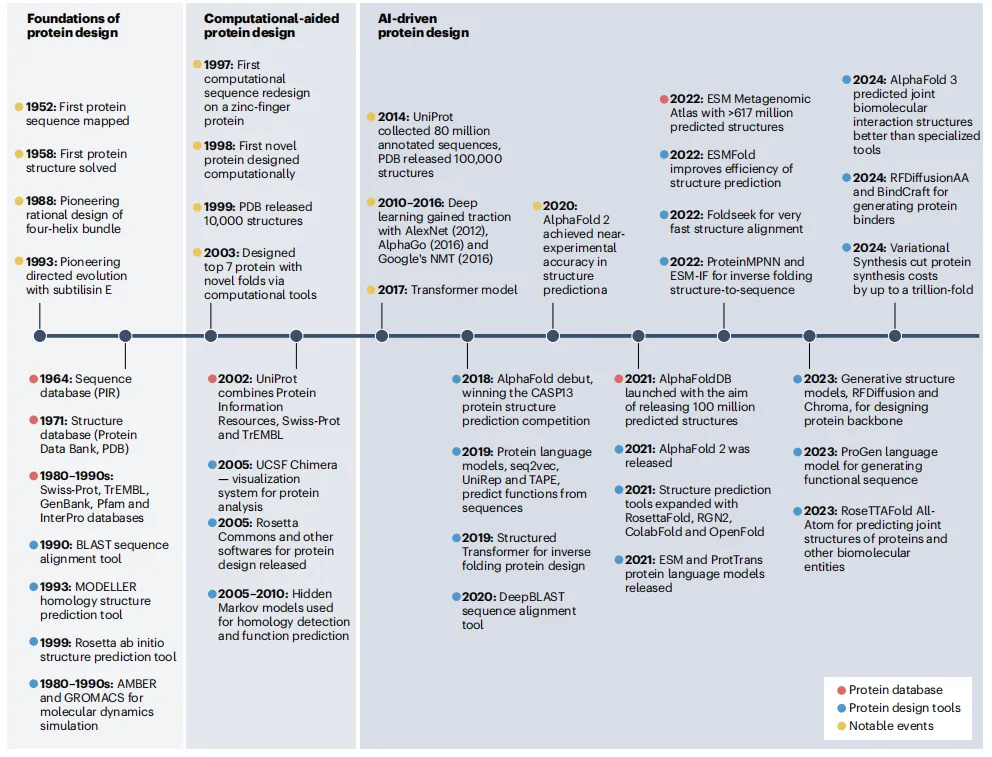
AI驱动蛋白设计的发展可分为三个时代:
第一代:奠基期(1950s-1990s)建立了蛋白质数据库(PDB)和序列数据库(UniProt),开发了BLAST等基础比对工具。这是蛋白设计的“石器时代”。
第二代:计算辅助期(1990s-2010s)同源建模、分子对接等计算工具兴起,但预测精度有限,设计仍高度依赖专家知识。
第三代:AI驱动期(2018年至今)→ 转折点:AlphaFold 2(2021年)实现近实验精度的结构预测。随后ESMFold用单序列预测、速度提升百倍;RFDiffusion和Chroma可从零生成蛋白骨架;AlphaFold 3和RoseTTAFold All-Atom将预测范围扩展到蛋白-小分子-核酸复合物。
→ AI的三大学习范式(见Box 1):监督学习(从标签数据学习)、无监督学习(从无标签数据挖掘模式,如语言模型、扩散模型)、强化学习(在虚拟环境中试错优化)。配合Transformer、图神经网络、几何3D网络等架构,AI模型已能“理解”蛋白的折叠密码。
第二篇:两大兵法——定向进化 vs 理性设计
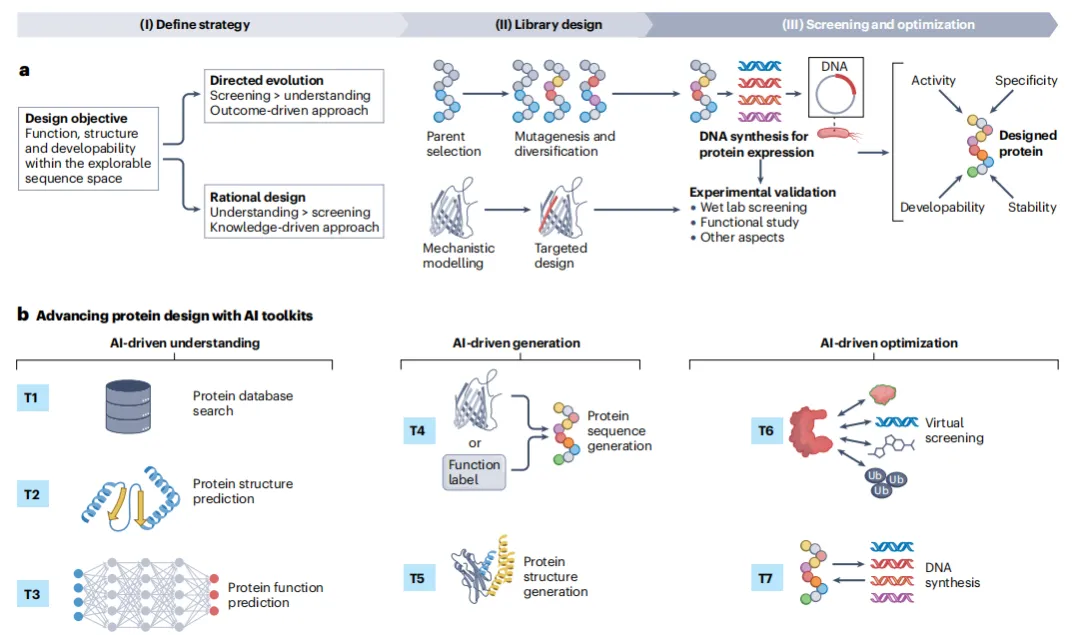
蛋白设计项目始于明确定义目标:功能、结构、可开发性。随后进入迭代循环:
→ 定向进化:回答“做什么”。选择父本蛋白 → 随机或半理性诱变 → 高通量筛选 → 选出更优变体。AI加速点:用序列-功能模型虚拟筛选,将实验轮次从数十轮压缩到2-3轮。例如,ESM语言模型可在零样本下预测突变效应。
→ 理性设计:回答“怎么做”。基于结构-功能机制 → 靶向修饰 → 实验验证。传统依赖晶体结构和定点突变,AI扩展点:可从零生成全新骨架(de novo design),或基于功能基序“生长”出稳定支架。
→ 两派并非对立,常可联用:用理性设计构建初始文库,用定向进化精细优化。
第三篇:七大工具包——你的蛋白设计“瑞士军刀”
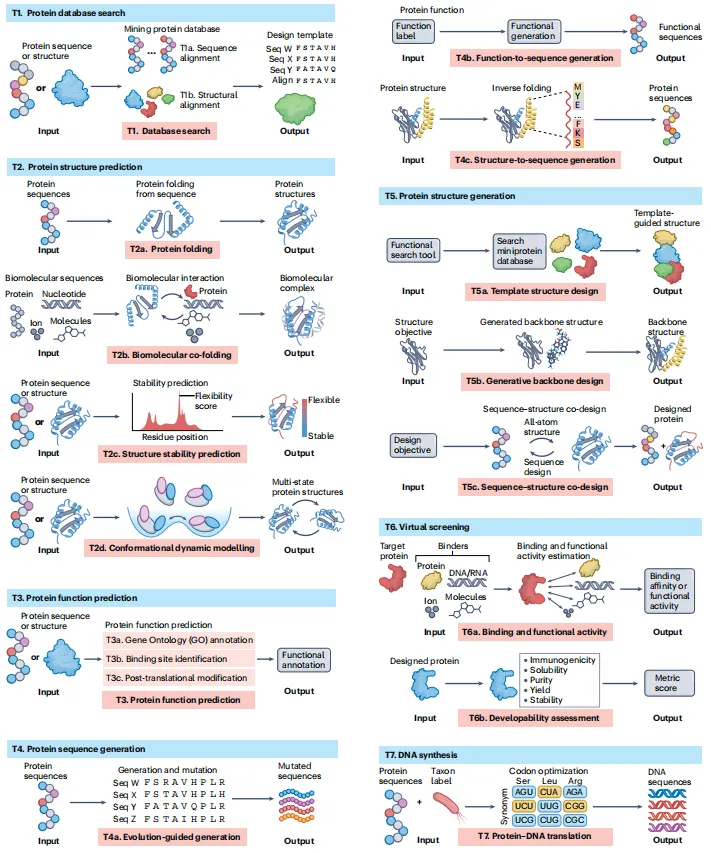
作者将AI工具分为七大类,覆盖设计全流程:
T1. 数据库搜索——序列比对(如pLM-BLAST)和结构比对(如Foldseek),从海量数据中找模板。
T2. 结构预测——蛋白折叠(AlphaFold 2)、生物分子共折叠(AlphaFold 3)、稳定性预测(TemStaPro)、构象动力学建模(AlphaFlow)。
T3. 功能预测——GO注释(NetGO 3.0)、结合位点识别(MaSIF)、翻译后修饰位点预测(MusiteDeep)。
T4. 序列生成——进化引导(ESM-1b,生成“进化合理”的突变)、功能到序列(ProGen,用标签生成序列)、结构到序列(ProteinMPNN,反向折叠)。
T5. 结构生成——模板搜索(MaSIF-search)、生成式骨架设计(RFDiffusion)、序列-结构共设计(RFDesign)。
T6. 虚拟筛选——结合与活性预测(PSICHIC、ESM-1v)、可开发性评估(DeepSoluE、NetMHCpan)。
T7. DNA合成——密码子优化与回翻译(CodonTransformer),将设计转化为可合成的DNA。
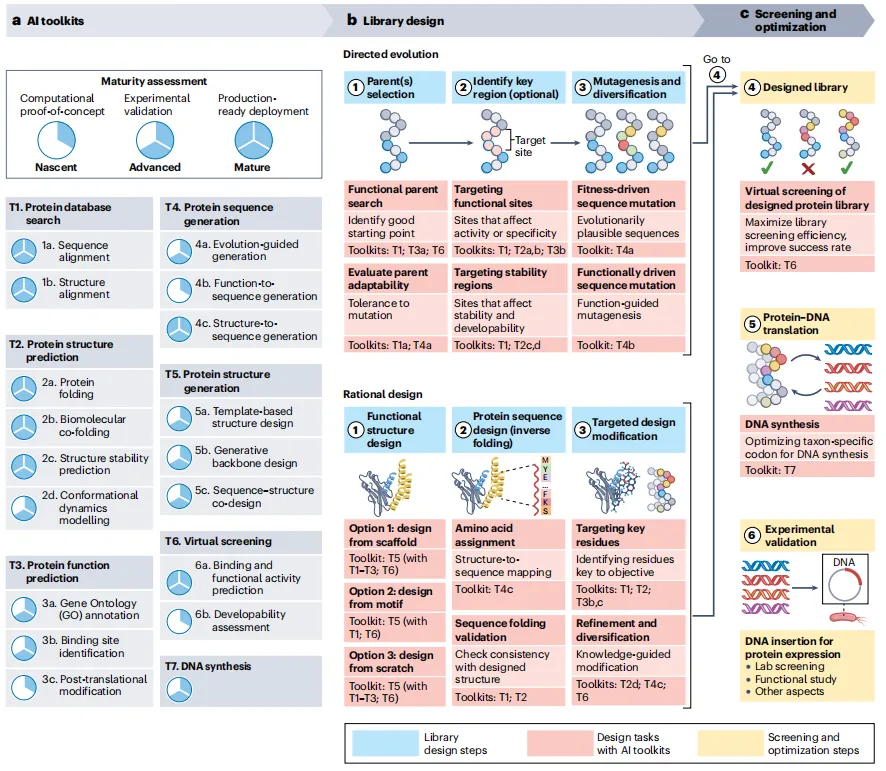
→ 成熟度评估:T1、T2(除T2d)、T6a已属“成熟”,广泛应用于产业;T4a、T5为“先进”,有实验验证;T3c、T4b、T6b仍处“新生”阶段。
第四篇:路线图——从目标到蛋白,步步为营
有了工具,如何串联成工作流?作者给出了清晰的路线图。
定向进化路线:
父本选择:用T1(数据库搜索)和T3a(GO注释)找候选,用T4a(进化引导)评估可进化性。
关键区域定位:用T3b(结合位点)和T2c(稳定性)锁定诱变热点。
诱变与多样化:T4a(进化合理突变)和T4b(功能驱动突变)生成高质量文库。
虚拟筛选:T6a预测结合/活性,T6b评估稳定性/免疫原性。
DNA合成:T7优化密码子。
实验验证:一轮未达标则反馈回步骤3。
理性设计路线:
功能结构设计:三种策略——从现有支架改造、从活性基序构建、从零生成。T5(结构生成)是核心。
序列设计:T4c(结构到序列)进行反向折叠,T2验证折叠正确性。
靶向修饰:T3b/c识别关键残基,T4c多样化和T6优化。4-6同定向进化。
→ 路线图灵活:已有良好父本时可直接从步骤3切入;两大策略可混合使用。
第五篇:实战案例——AI如何“造”出超级蛋白
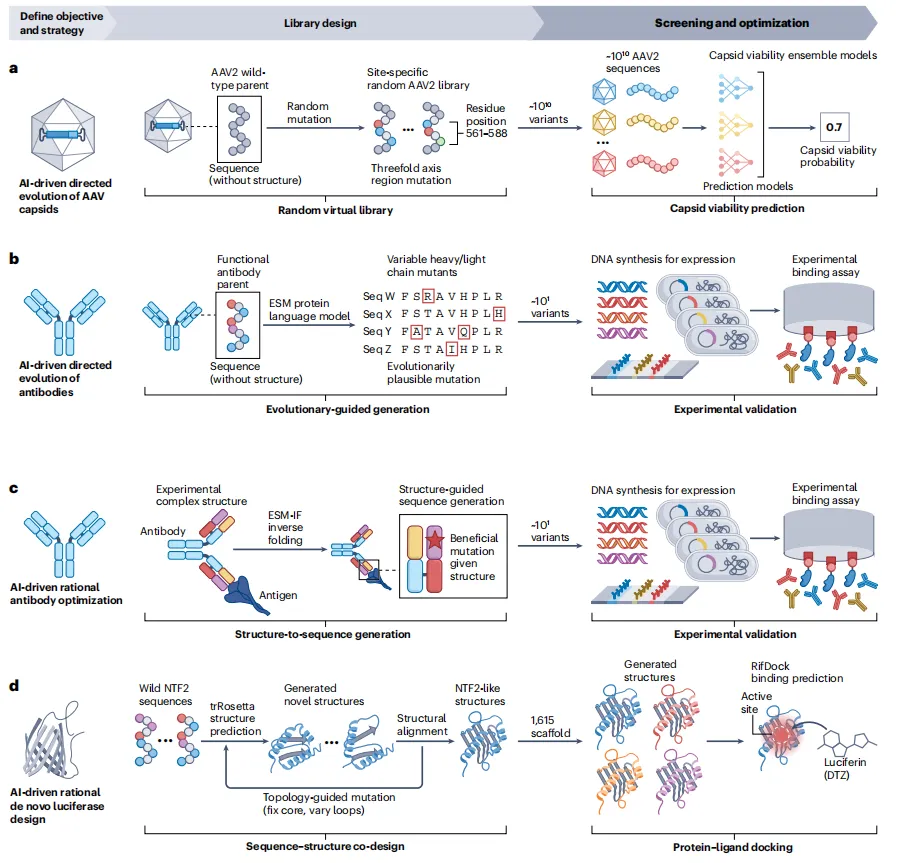
案例1:AAV衣壳的AI定向进化(图5a)传统AAV基因治疗载体难以逃避免疫中和抗体。→ 研究者对AAV2衣壳三倍对称轴附近的28个残基进行随机突变,生成10^10虚拟文库。用定制CNN/RNN模型(T6a)筛选“衣壳存活能力”,最终201,426个候选进入实验,其中110,689个(58.1%)被验证为可存活,部分含有29个突变。传统方法根本无法探索如此规模的序列空间。
案例2:抗体的AI定向进化(图5b)无需结构信息,直接用ESM语言模型(T4a)生成重链和轻链的“进化合理”突变。→ 仅两轮实验(每轮≤20个变体),四种成熟抗体亲和力提升7倍,三种未成熟抗体提升160倍。证明语言模型可高效优化抗体,无需抗原-抗体复合物结构。
案例3:抗体的理性优化(图5c)针对逃逸变异株BQ.1.1和XBB.1.5,研究者用ESM-IF(T4c,结构到序列)对已知抗体-抗原复合物结构生成有益突变。→ 实验验证前30个突变体,亲和力提升37倍。结构信息+反向折叠,精准应对病毒进化。
案例4:从头设计发光蛋白(图5d)目标:设计催化合成底物DTZ的荧光素酶。天然蛋白不结合DTZ。→ 用trRosetta(T5c)“家族级幻觉”生成1,615个新NTF2样骨架,保留核心折叠但自由变化环区。再用RifGen(T2d)采样侧链、RifDock(T6a)打分、ProteinMPNN(T4c)优化序列。→ 实验发现多个活性变体,其中LuxSit熔点>95°C,高效特异催化DTZ发光。这是AI从头设计全新酶功能的里程碑。
结语:AI蛋白设计——未来已来,但挑战仍在 🔭
→ 当前成就:从AAV衣壳到荧光素酶,AI已证明能设计出超越天然功能的蛋白。七大工具包、两条策略、一条路线图,为研究者提供了清晰的操作框架。
→ 待解难题:大型多结构域蛋白、变构网络设计仍具挑战;数据偏差和可解释性不足;实验验证仍是瓶颈。
→ 未来方向:更强大的基础模型(如Evo已尝试全基因组设计)、非天然氨基酸整合、全自动设计-合成-测试闭环。
参考文献:Koh, H.Y., Zheng, Y., Yang, M. et al. AI-driven protein design. Nat Rev Bioeng3, 1034–1056 (2025). https://doi.org/10.1038/s44222-025-00349-8
相关阅读:
《Nature》发表David Baker研究:从头设计迷你蛋白:AI破解GPCR药物研发难题
给MHC“减负”:AI设计的小型化SMART蛋白可溶表达,让T细胞研究更简单
纳米抗体筛选、小鼠单抗筛选、兔单抗筛选、抗体人源化、抗体亲和力成熟、AI抗体设计,欢迎交流咨询。

