 夜雨聆风
夜雨聆风
这是2026年的第18篇文章
( 本文阅读时间:约20分钟 )
前言
这篇文章讲的事情不复杂:我们用两个 Git 仓库 + AI 编码助手 + 几个 Shell 脚本,替代了传统项目管理中至少 80% 的人肉操作——催周报、搬数据、画图表、对齐进展、写汇报。没有搭平台,没有买 SaaS 工具,就是 Markdown + Shell + Python + AI 的朴素组合。
你有没有想过,为什么你的团队每周都在重复这些事情:
催 N 个业务线的同学交周报,催到第三遍还是有人没交 把即时通讯文档里的零散信息搬到某个在线表格里,格式不统一,粒度随意 手动更新一个看板的进度条,更新完发现另一个团队的数据已经过期了 从数据平台上捞一堆 SQL 结果,贴到 PPT 里变成"效能报告" 开周会的时候发现大家看的信息版本不一样
说白了,这些事情的本质就是信息搬运。从人脑搬到文档,从文档搬到看板,从数据仓库搬到图表。每次搬运都有信息损耗、都有延迟、都需要有人盯着——而且这个人通常是团队里技术最好、最不应该做这些事情的人。
我们的做法是:让 AI 做搬运工,人只做输入和决策。
01
全景:两个仓库解决什么问题

两个仓库彼此独立。一个管"进展",一个管"数据"。进展跟踪是定性的(做了什么、卡在哪、下一步是什么),效能度量是定量的(交付了几个需求、代码行数、AI 工具用了多少)。分开管是故意的——把定性和定量混在一起,两边都做不好。
02
业务跟踪仓库:从自由文本到结构化 Dashboard
这件事的本质是什么?
跟踪 N 个业务场景的周进展,其实就三步:收原始信息 → 语义整合到结构化文档 → 生成可视化视图。
传统做法是拉个在线表格,每个业务方负责填一列。问题大家都知道:格式不统一、信息粒度随意、历史不可追溯、可视化靠手工。更要命的是——要求人填结构化数据这件事本身就是反人性的。
2.1三层数据架构
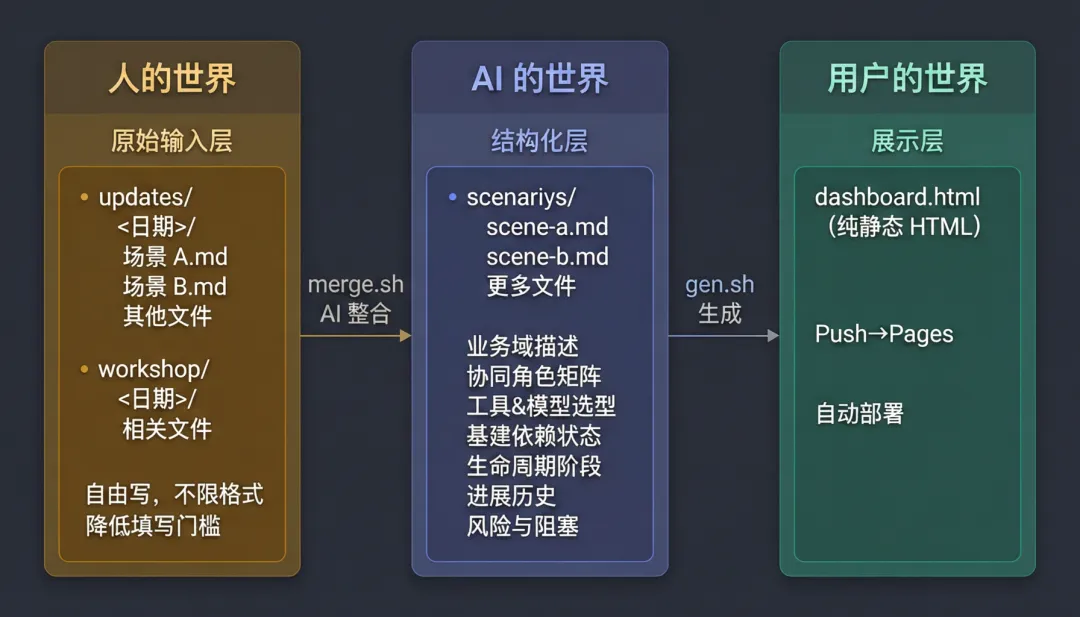
第一层:原始输入——让人说人话
团队成员在 updates/<日期>/ 下按场景建 Markdown 文件,想怎么写就怎么写:
# 周进展更新> 填写人: (花名)> 日期: 2026-05-16> 业务场景: 某仓储场景这周完成了 API 接口全量覆盖,可用率从50%提到65%。知识库云归档已经跑通。参数构造不准的问题还在,大概还有40%的case走不通。下周重点搞 Benchmark V2。
对,就这样。不限格式,不要求结构化,写清楚做了什么、遇到什么问题即可。
这是故意的。降低填写门槛是第一生产力。你让人填 10 个结构化字段,他就不想填。你让人自由写,他反而能写出有价值的信息。而且团队成员只需要维护自己负责的那个场景文件,不需要关心全局视图。
输入来源不止手写一种。我们通过多种 CLI/MCP 工具来降低信息采集的人工成本:
即时通讯文档 MCP:团队成员把进展写在即时通讯文档里(很多人本来就在这里写),通过 MCP Skill 自动读取文档内容(返回 Markdown),不需要手动复制粘贴。发个链接就行。 代码仓库 CLI:通过 a1 repo file view/list直接读取远程仓库的文件内容,不需要本地 clone。场景文件、历史更新、Dashboard 都可以远程读写。数据平台 CLI:通过 maxc query查询大数据平台,获取团队人员信息、协同角色映射等,辅助更新场景文档中的结构化字段。
Workshop 分享记录也是一种输入来源。把线下会议的分享内容搬到 workshop/<日期>/ 下,同样是原始文本不加工。
第二层:AI 语义整合——把自由文本变成结构化文档
每个业务场景有一个标准化的 Markdown 文件,结构固定:

AI 整合的过程封装在 merge.sh 里。这个脚本做的事情很简单:
找到最新(或指定)日期的更新文件夹 收集所有 .md文件拼接成一份 prompt,描述整合规则 交给 AI 编码助手执行
Prompt 的设计非常克制,值得展开说说。核心规则:
最后一条很关键。如果某个业务线这周没交更新,场景文件里会明确标注"(本周未更新周进展)"。不编造、不美化、不用上周的信息凑数。
第三层:Dashboard——纯静态 HTML
一个暗色调的单页 HTML,大概长这样:
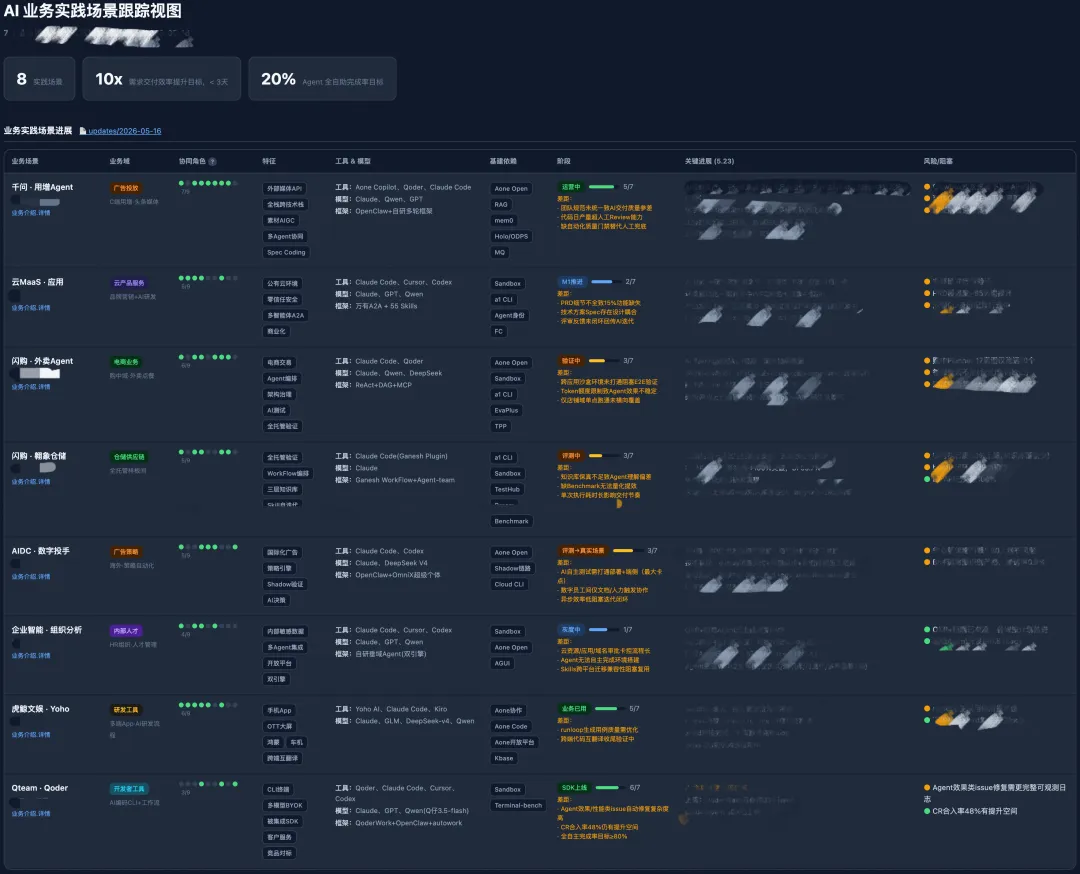
2.2 问题挖掘与依赖协同 Skill
光有 Dashboard 不够。Dashboard 回答的是"各场景走到哪了",但管理者真正关心的是另一组问题:谁卡住了?卡在什么地方?需要什么帮助?该投资什么基建?
所以我们做了另一个 Skill,专门干这件事:从结构化场景文档中挖掘问题,识别依赖阻塞,输出协同优先级判断。
它的工作逻辑是这样的:
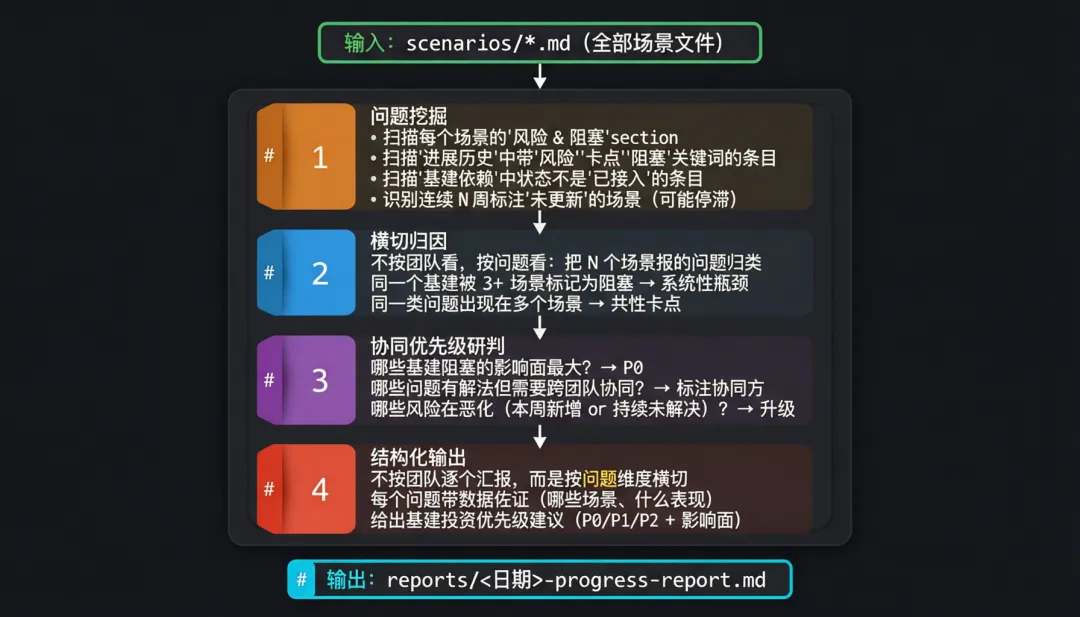
举个实际例子。某一周 AI 横切扫描后发现:N 个场景同时报告了"AI 自主测试验证"相关的卡点——有的是测试用例可执行度低,有的是测试结果不可信赖,有的是测试失败后缺自动归因。如果按传统的"一个团队一个团队汇报"模式,这个信号会淹没在各自的进展列表里。但横切一看,这不是某个团队的问题,而是整个 AI Native 范式的系统性瓶颈。
基于这个判断,Skill 自动把"测试→归因→修复自动联动"标记为 P0 基建优先级,并列出受影响的场景和各自的具体表现。管理者拿到的不是"8 个团队各自做了什么",而是"当前最该投资什么、为什么、影响谁"。
同样的逻辑适用于基建依赖热度的跟踪。当多个场景都依赖同一个基础能力(比如沙箱环境、统一身份服务),这个 Skill 会自动汇总热度和阻塞状态,倒逼基建团队把资源投到影响面最大的方向上。
这个 Skill 的写作原则也值得说:结论先行、数据驱动、避免技术黑话、10 分钟能读完。这些原则全部编码在 Skill 文件里,不在任何人的脑子里。
03
效能度量仓库:从数据仓库到交互式报表
第二个仓库做的事情更硬核:从大数据平台拉数据,跑计算,生成效能报表。如果说业务跟踪仓库解决的是"做了什么"的问题,这个仓库解决的是"做了多少、做得好不好"的问题。
整套数据采集依赖两个关键 CLI 工具:maxc(大数据平台命令行,提交 SQL 查询、等待结果、分页拉取)和 a1(代码平台命令行,管理仓库文件、推送部署产物)。前者负责"拿数据",后者负责"发布结果"。没有写一行后端代码,全靠 CLI 工具 + Python 脚本串联。
3.1 三层度量体系
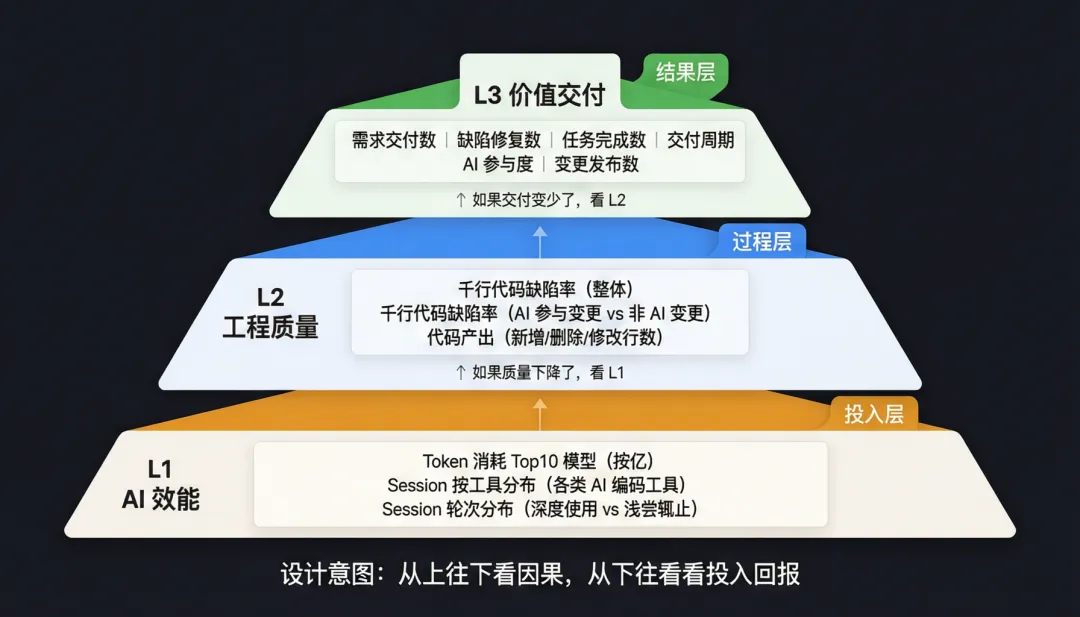
L3 是最终结果:团队产出了什么、快不快。L2 是过程质量:代码质量好不好,AI 参与的变更和人工变更有没有质量差异。L1 是手段投入:AI 工具用了多少、用得深不深。
这个体系的杀手级应用是AI 代码的质量对比。千行缺陷率分 AI 参与 vs 非 AI 参与两条线,让你一眼看出来"AI 写的代码到底比人写的烂还是好"。这个问题以前靠猜,现在靠数据。
3.2 数据源与查询架构
数据从大数据平台的多张表汇聚,覆盖了研发全链路:
数据源矩阵(脱敏后):维度 表数量 关联方式──── ────── ────────需求交付 1 自带部门字段代码提交 1 通过员工工号 IN 员工表变更发布 1 自带部门字段缺陷指标 1 自带部门字段 + 自然周过滤工作项 1 自带部门字段 + 工号关联变更表AI Token消耗 1 通过 user_id IN 员工表商业AI工具 1 通过 user_id IN 员工表内部Agent 1 自带部门字段(需先去重)内部Copilot 1 自带部门字段汇总查询 9 个 + 人员明细查询 5 个 = 共 14 个 SQL 并行提交
# 核心架构(伪代码)class QueryClient:def submit(self, sql) -> job_id:"""提交查询,立即返回 job_id,不阻塞"""return cli_tool('query', sql, '--wait', '0')def wait_result(self, job_id) -> rows:"""等待结果,支持 cursor 分页拉取全量"""all_rows = []while has_more:page = cli_tool('job', 'wait', job_id)all_rows.extend(page.rows)cursor = page.next_cursor # 每次最多100行return all_rows# 执行流程jobs = {}for name, sql in build_all_queries(dept, week):jobs[name] = client.submit(sql) # 14个SQL同时提交results = {}for name, job_id in jobs.items():results[name] = client.wait_result(job_id) # 并行等待# 总耗时 ≈ 最慢的那一个查询,而非14个串行
3.3 最大的坑:没有数据验证就改 Skill,改一次废一次
这套系统跑通的过程中,踩过的坑不少。但回头看,最疼的不是某个 SQL 写错了或者某个字段格式奇葩——那些都是一次性的问题,修了就好了。
真正反复折腾我们的,是 Skill 迭代过程中缺乏验证手段。
什么意思呢?度量系统的核心是一组 SQL 查询 + 数据聚合逻辑 + HTML 渲染。当你想优化某个指标的计算口径、调整数据关联方式、或者新增一个维度的时候,改动往往牵一发动全身。你改了 SQL 的过滤条件,可能导致某个团队的数据突然消失;你调整了 Token 消耗的模型归一化逻辑,可能让数字跟上周报表对不上。
我们实际经历过好几次这样的情况:
- 某次优化了 AI 参与度的关联逻辑——从"直接匹配"改成"通过工号间接关联"。改完以后某个团队的 AI 参与度从 30% 变成了 0%。原因是那个团队的工号在员工表里有特殊状态标记,新逻辑把他们全过滤掉了。发出去的报表当场被质疑。
- 某次调整了缺陷率的统计周期——从日历周改成自然周(周一到周日)。结果因为某张表的日期字段用的是"周日日期 + 时间后缀"的奇葩格式,改完以后缺陷数直接归零。
- 某次新增了一个 AI 工具的 Session 统计——没注意到这张表里同一个 Session 有多行记录,直接
COUNT(*)导致 Session 数膨胀了 3 倍。
每次出问题,都只能 git revert 回滚到上一个已知正确的版本。改了 → 发出去 → 被质疑 → 回滚 → 排查 → 再改 → 再验证,这个循环每次都要浪费半天到一天。
后来我们想明白了:这就是 Harness Engineering 的核心教训——没有"测试治具"的迭代,本质上就是在生产环境上做实验。
解法是给度量系统加了"数据单测"的概念:
改之前必须做的三件事:──────────────────1. 快照基线:把当前版本的输出数据存一份快照(每个团队的 KPI 数字、关键指标的聚合结果)2. 改完后对比:跑同一周的数据,跟基线快照做 diff● 哪些指标变了?变了多少?● 变化是预期的还是意外的?● 有没有某个团队的数据异常消失或膨胀?3. 多周回测:用过去 3-4 周的数据跑一遍确保改动不只在本周数据上正确,而是普遍正确
说白了,这跟写代码一样——你不会在没有测试的情况下重构核心模块。度量系统的 SQL 和聚合逻辑就是"核心模块",每次改动都需要验证手段。没有验证手段的优化不叫优化,叫冒险。
这个教训也适用于业务跟踪仓库那边。AI 整合的 prompt 规则改了之后,如果不拿之前的更新数据重新跑一遍对比结果,你根本不知道新规则会不会导致某些场景的进展历史格式乱掉、风险条目丢失、或者阶段状态被错误更新。
这也是为什么我们现在遵循一个原则:每次 Skill 迭代都是一次带验证的变更,不是随手改个参数。
3.4 多团队配置与门户
整套生成逻辑支持多团队并行。通过一个 Shell 脚本配置所有团队:
# 团队配置(脱敏示例)TEAMS=("team-alpha|部门路径A%|A 团队""team-beta|部门路径B%|B 团队""team-gamma|部门路径C%|C 团队"# ... 目前配置了 8 个团队)# 循环生成for entry in "${TEAMS[@]}"; doIFS='|' read -r slug dept name <<< "$entry"python3 team_weekly_metrics.py --week $WEEK --dept "$dept" \--team-name "$name" --output "public/$slug"done
每个团队生成独立的 index.html(主仪表盘)+ detail.html(人员详情),放到 public/<slug>/ 下。还有一个门户页 public/index.html,卡片式列出所有团队,点击进入各自的报表。
3.5 产出:交互式 HTML 仪表盘
主仪表盘用 Chart.js 渲染,包含:
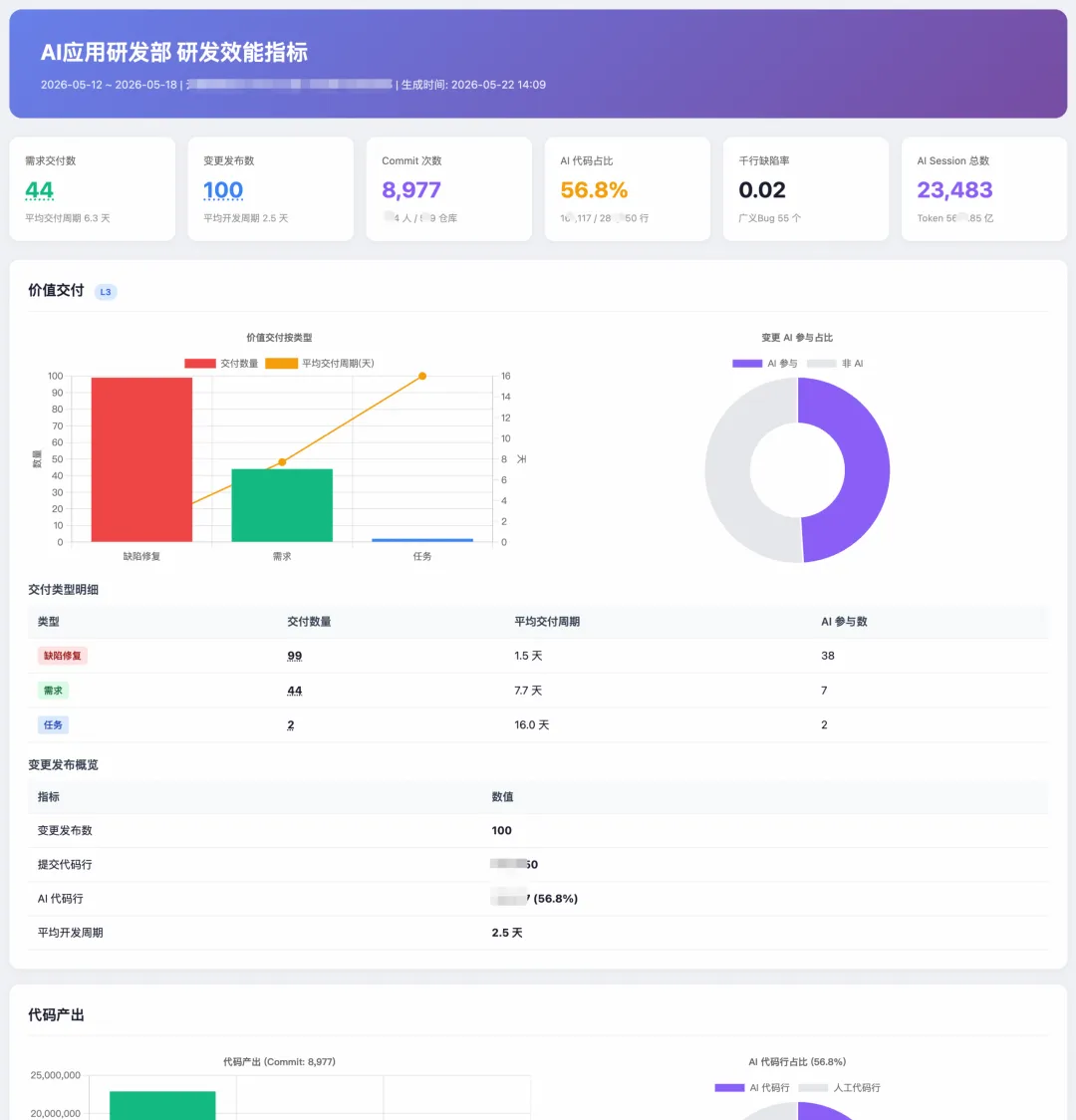
?view=req 直接定位到某个维度。主仪表盘的 KPI 数字和明细表里的数字都是超链接,点击直接跳过去,自动按该维度降序排列。04
技术架构全景
┌─────────────────────────────────────────────────────────────────────┐│ 技术架构全景 ││ ││ 数据输入 处理引擎 产出 & 部署 ││ ──────── ──────── ──────────── ││ ││ ┌──────────┐ ┌──────────────┐ ┌────────────┐ ││ │ 即时通讯 │ ──Skill──→ │ │ │ dashboard │ ││ │ 文档 │ │ │ │ .html │ ││ └──────────┘ │ AI 编码助手 │ ──────→ │ │ ││ ┌──────────┐ │ (语义整合) │ │ report.md │ ││ │ 自由文本 │ ──Git───→ │ │ │ │ ││ │ Markdown │ └──────────────┘ │ scenarios/ │ ││ └──────────┘ └─────┬──────┘ ││ │ ││ ┌──────────┐ ┌──────────────┐ ┌─────▼──────┐ ││ │ 数据仓库 │ │ │ │ │ ││ │ 9张数据表 │ ──SQL───→ │ Python 脚本 │ ──────→ │ index.html │ ││ │ 2个项目 │ │ (并行查询 │ │ detail.html│ ││ └──────────┘ │ 聚合计算 │ │ Chart.js │ ││ │ HTML生成) │ └─────┬──────┘ ││ └──────────────┘ │ ││ ┌─────▼──────┐ ││ ┌──────────────────┐ │ │ ││ │ Skill 文件 │ ← 可版本管理的 SOP │ Git Push │ ││ │ (SKILL.md) │ 定义数据源/步骤/约束/格式 │ → CI/CD │ ││ │ 编码在 Git 仓库中 │ │ → Pages │ ││ └──────────────────┘ └────────────┘ ││ ││ 公共基座:Git + Markdown + 静态HTML + Push-to-Deploy │└─────────────────────────────────────────────────────────────────────┘
05
Skill:把隐性知识变成代码
两个仓库都有一个核心文件叫 SKILL.md。这不是一份普通的文档——它是整个项目管理系统的"灵魂"。
Skill 的本质是什么?它是一份给 AI 编码助手看的结构化 SOP,定义了:
这样做的好处是:工作流不绑定到某个人脑子里。你团队里那个"最了解各业务线进展"的 PM,他脑子里的信息组织方式,现在变成了场景文件的 9 个 section。他每周做的信息整合,变成了 merge.sh + AI prompt。他做的效能汇总,变成了 Python 脚本 + 14 个 SQL。
Skill 文件本身也在 Git 里版本管理。上周整合的规则和这周不一样?看 diff 就知道改了什么。某个场景的文件映射关系变了?commit log 里有记录。
说白了,Skill 就是把项目管理的隐性知识编码成了可执行的代码。只不过这个"代码"的执行引擎不是 Python 解释器,而是 AI 编码助手。
06
为什么这套方案 Work?—— 五个设计决策
决策 1:Git 是唯一的 Source of Truth
所有状态都在 Git 仓库里。Markdown 是数据格式,Git 是版本控制,文件系统是数据库。
每次变更有 commit 记录,可追溯 谁改了什么、什么时候改的, git log一目了然分支/MR 流程天然可用 不依赖任何第三方 SaaS 的可用性
决策 2:降低输入门槛 > 降低处理成本
传统工具要求人按模板填写结构化数据。我们反过来——让人自由写,AI 来结构化。自由文本 → 结构化文档,这恰好是 LLM 最擅长的事情。
填写门槛从"打开某个系统 → 找到对应的表格 → 按字段填写"降低到了"写个 Markdown 文件或发个即时通讯文档链接"。阻力越小,数据质量反而越高——因为人在没有格式束缚的时候会写更多信息。
决策 3:静态 HTML 是最好的 Dashboard
不需要后端,不需要数据库,不需要登录鉴权,不需要运维。一个 HTML 文件用 Chart.js 画图表,谁都能打开,在哪都能看。
部署成本约等于零:cp 一个文件到 build/,push 到 Git,CI 自动分发到 CDN。整个链路没有 npm、没有 webpack、没有 Node.js。五行 YAML 搞定 CI 配置。
决策 4:定性和定量分离
进展跟踪是定性的(做了什么、卡在哪里),效能度量是定量的(交付了多少、质量如何)。两个仓库各管各的,数据源不同,更新节奏不同,消费者也不同。
管理者看进展 Dashboard 了解"发生了什么",看效能仪表盘了解"表现如何"。同一件事的两个面,但不需要混在一起。
决策 5:SQL 即度量定义
所有效能指标的定义就是 SQL 本身。没有 BI 工具里的拖拉拽"指标配置",没有只存在于某个人脑子里的"口径说明文档"。
SQL 在代码仓库里,可以 review、可以 diff、可以回测。你想知道"千行缺陷率到底怎么算的"?看 SQL。你觉得这个指标不对?改 SQL,提 MR,review 通过后下周报表自动用新口径。
这比任何 BI 平台都更透明。
07
从个体实践到横切分析:项目管理的 AI Native 范式
如果只是"用 AI 搬运信息",这个故事不值得讲这么长。真正有意思的地方在于:当你把多个业务场景的进展结构化以后,你可以做横切分析。
传统项目管理是纵向的——每个团队汇报自己的事情,管理者要自己在脑子里做综合判断。但当所有场景的数据都在统一结构的 Markdown 文件里时,AI 可以帮你做横切:
- 基建依赖分析:哪些基础设施被最多团队依赖?哪个基建的阻塞影响面最大?——这直接指导平台投资优先级;
- 协同复杂度对比:哪个场景涉及的角色最多?角色越多意味着协同成本越高,需要更多关注;
- 阶段分布:N 个场景在 7 级生命周期上的分布是什么?有多少已经在"业务使用",有多少还卡在"评测"?;
- 共性风险识别:多个场景同时报告"测试闭环"是卡点,说明这不是个别团队的问题,而是系统性瓶颈;
- 进展趋势:某个场景连续三周标注"本周未更新",是不是需要关注?
这些洞察在传统的"一个个团队汇报"模式下很难浮现。但当数据结构统一后,AI 可以在几秒钟内完成横切分析,产出"关键洞察"——比如"最大系统性瓶颈是 AI 自主测试验证,影响了 N 个场景"。
这才是 AI Native 项目管理真正的杠杆点:不是用 AI 替代人做重复性工作(虽然这也很爽),而是用 AI 做人做不了的横向模式识别。
08
正在进行的实践:对接需求管理和代码仓库
前面讲的这套系统已经跑起来了。但我们也清楚,当前的数据流还可以更好——客观数据可以更多地叠加进来,减少人工输入的成本。
注意,我说的是"叠加"而不是"替代"。这是我们在实践中学到的最重要的一课:项目中遇到什么困难、需要什么帮助、跨团队协同的痛点在哪里——这些信息很难从需求状态变更和代码 Commit 里挖出来,它们本质上是主观判断,必须依赖人的反馈。
但另一方面,"这周交付了几个需求""合了多少个 MR""哪些需求排期延后了"——这些纯客观的事实,确实不需要人来手写。能从系统里自动拿到的信息,就不该让人再说一遍。
8.1 当前在做什么
我们正在通过 CLI 工具把需求管理平台和代码仓库的数据接进来,让 AI 拿到更多客观信息后,再结合人的主观输入生成更完整的周进展。
说实话,这一步没有想象中顺利。实际对接各业务团队的代码仓库和需求空间时,我们发现了一个扎心的现实:很多团队的需求和代码之间关联性很差。需求卡片不关联 MR、Commit message 不带 workitem ID、有的团队甚至需求和代码在不同的组织空间下。
AI 拿到这些"凌乱"的原始数据后,生成的进展信息虽然比没有强,但离"人能直接看懂、不需要修正"还有距离。信息的关联、噪声的过滤、重点的提炼——每一步都需要持续优化 Skill 的 prompt 和数据处理逻辑。
这是一个正在迭代的过程,目前的思路是:
客观数据(自动采集,不需要人写) 主观信息(人补充,但大大精简)─────────────────────────── ──────────────────────────● 需求状态流转事件 ● 这周遇到的核心困难● 代码提交和 MR 合入 ● 需要什么跨团队帮助● 排期变更记录 ● 方案变更的原因和背景● 效能数据(交付周期/AI占比等) ● 下周的重点和优先级调整│ │└──────────┬───────────────────┘▼AI 综合两类信息生成结构化周进展│▼人 Review 确认(10分钟)
核心理念是:客观事实让机器采集,主观判断让人精准表达,AI 负责把两者融合成一份完整的进展。人的输入从"写一大段周进展"变成"回答三两个关键问题"——卡在哪、需要什么帮助、下周重点是什么。
8.2 AI 参与项目管理的三个层次
把我们走过的路和正在走的路放在一起看,AI 在项目管理中的参与可以分三层:
┌─────────────────────────────────────────────────────────────┐│ ││ Level 3: AI 做决策辅助 (远期) ││ ┌───────────────────────────────────────────────────┐ ││ │ ● 基于历史交付数据做工期预测 │ ││ │ ● 识别资源瓶颈和关键路径 │ ││ │ ● 自动生成优先级建议 │ ││ └───────────────────────────────────────────────────┘ ││ ↑ 需要足够多的历史数据积累 ││ ││ Level 2: AI 做信息整合 + 客观数据采集 (优化中) ││ ┌───────────────────────────────────────────────────┐ ││ │ ● 从需求平台/代码仓库采集客观事实 │ ││ │ ● 叠加人的主观反馈,语义整合到结构化文档 │ ││ │ ● 横切分析识别共性风险 │ ││ │ ● 自动生成 Dashboard 和汇报文档 │ ││ └───────────────────────────────────────────────────┘ ││ ↑ 本文讲的主要是这一层 ││ ││ Level 1: AI 做格式转换 + 数据搬运 (已完成) ││ ┌───────────────────────────────────────────────────┐ ││ │ ● 自由文本 → 结构化 Markdown │ ││ │ ● SQL 结果 → 可视化图表 │ ││ │ ● 多数据源 → 统一报表 │ ││ └───────────────────────────────────────────────────┘ ││ │└─────────────────────────────────────────────────────────────┘
Level 1 已经跑通了。Level 2 正在做,关键不是技术难度,而是数据治理——需求和代码的关联质量直接决定了 AI 采集出来的信息能不能用。Level 3 是自然延伸——当 Git 里按周沉淀了半年的场景进展数据,拿来做趋势预测是顺理成章的事。
09
写在最后
AI Native 项目管理这个词听起来很唬人。但你把它拆开看,每一步都是开发者已经会的东西:
会写 Markdown?你就能定义场景文档的结构。 会写 Shell 脚本?你就能串起整个数据采集和生成流程。 会写 SQL?你就能从数据仓库捞出度量指标。 会用 Git?你就天然有了版本管理、协作和部署。
说白了,这套东西没有任何一个技术门槛超过"写一个 CRUD 接口"的难度。没有分布式系统,没有微服务架构,没有任何需要额外学习的框架。一个开发者,一个小时,就能把骨架搭起来。
真正的门槛不在技术,在思路转变——你得相信项目管理本质上是一个信息工程问题,而不是一个流程管理问题。一旦接受了这个设定,用 Git 管状态、用 AI 做整合、用静态 HTML 做可视化,就是顺理成章的事。
之所以 work,不是因为技术多先进,而是因为顺应了工程师的工作习惯,而不是对抗它。
如果你也在纠结要不要买个项目管理工具,或者要不要搭一个数据看板平台——不妨先试试两个 Git 仓库加几个 Shell 脚本。认真的,说不定就够了。
最终成本清单:├─ Git 仓库 × 2 ← 免费├─ Markdown 文件若干 ← 免费├─ Shell 脚本 3 个 ← 几十行代码├─ Python 脚本 1 个 ← ~800行├─ SKILL.md 2 个 ← 工作流定义├─ CI 配置 5 行 YAML ← 免费├─ Pages 部署 ← 免费├─ AI 编码助手 ← 已有│├─ 总计:零额外基建投入└─ 替代了:项目管理工具 + BI平台 + 效能报表系统


