 夜雨聆风
夜雨聆风一、Pipeline编排核心架构
1.1 Pipeline类继承关系

关键源码解析(第28-42行):
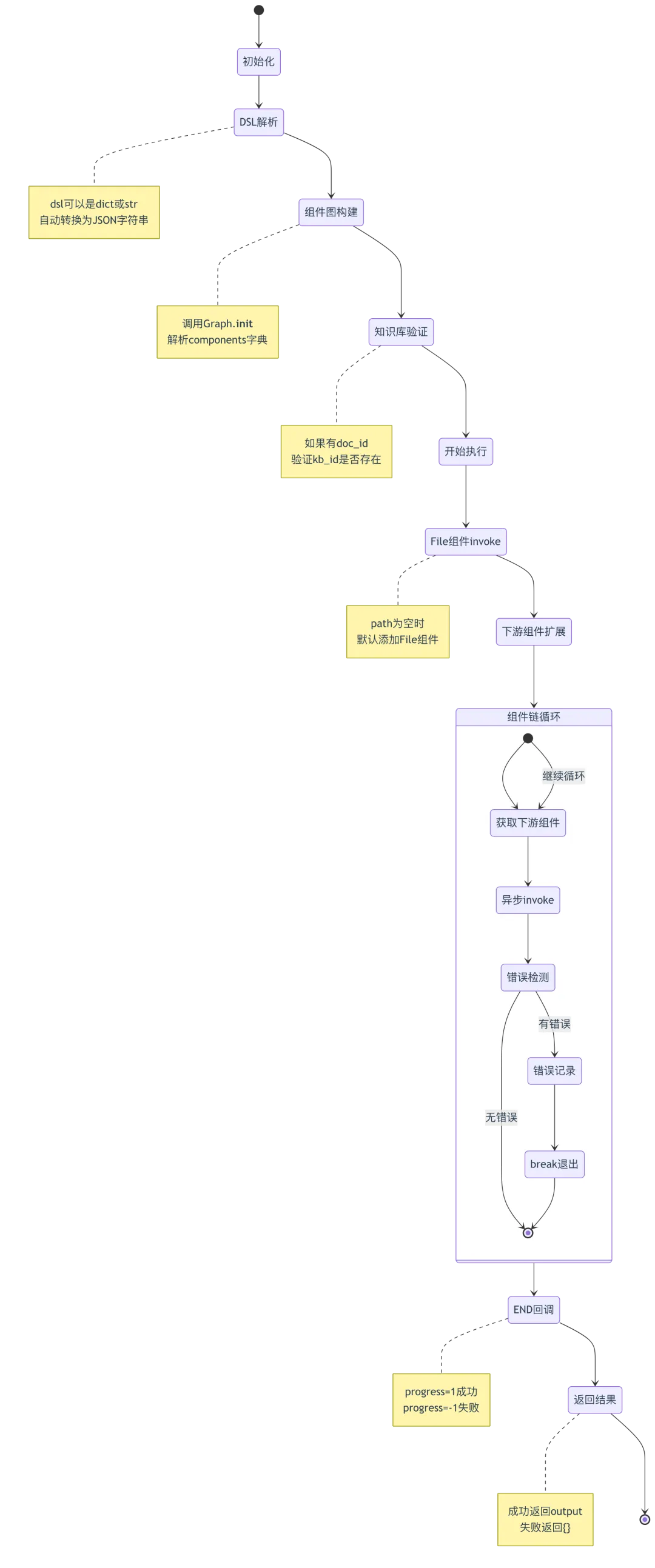
class Pipeline(Graph): # 第28行:继承Graph,获得组件编排能力def __init__(self, dsl: str|dict, tenant_id=None, doc_id=None, task_id=None, flow_id=None):# 第30-31行:DSL可以是字典或字符串,自动转换为JSON字符串if isinstance(dsl, dict):dsl = json.dumps(dsl, ensure_ascii=False)# 第32行:调用父类Graph.__init__初始化组件图super().__init__(dsl, tenant_id, task_id)# 第33-34行:调试文档ID特殊处理(Canvas调试模式)if doc_id == CANVAS_DEBUG_DOC_ID:doc_id = Noneself._doc_id = doc_id # 文档ID(用于文档处理任务)self._flow_id = flow_id # 流程ID(用于日志追踪)# 第37-41行:关联知识库ID,如果文档不属于任何知识库则无效化doc_idself._kb_id = Noneif self._doc_id:self._kb_id = DocumentService.get_knowledgebase_id(doc_id)if not self._kb_id:self._doc_id = None # 文档不属于任何知识库,取消处理
设计意图分析:
- DSL双类型支持
(第30-31行):允许调用者传入字典或字符串,降低接口使用门槛 - 知识库关联验证
(第37-41行):确保文档处理任务必须关联有效知识库,防止无效任务执行 - 调试模式隔离
(第33-34行):Canvas调试使用特殊doc_id,实际处理时需过滤
1.2 进度回调机制(callback)
完整源码解析(第43-105行):
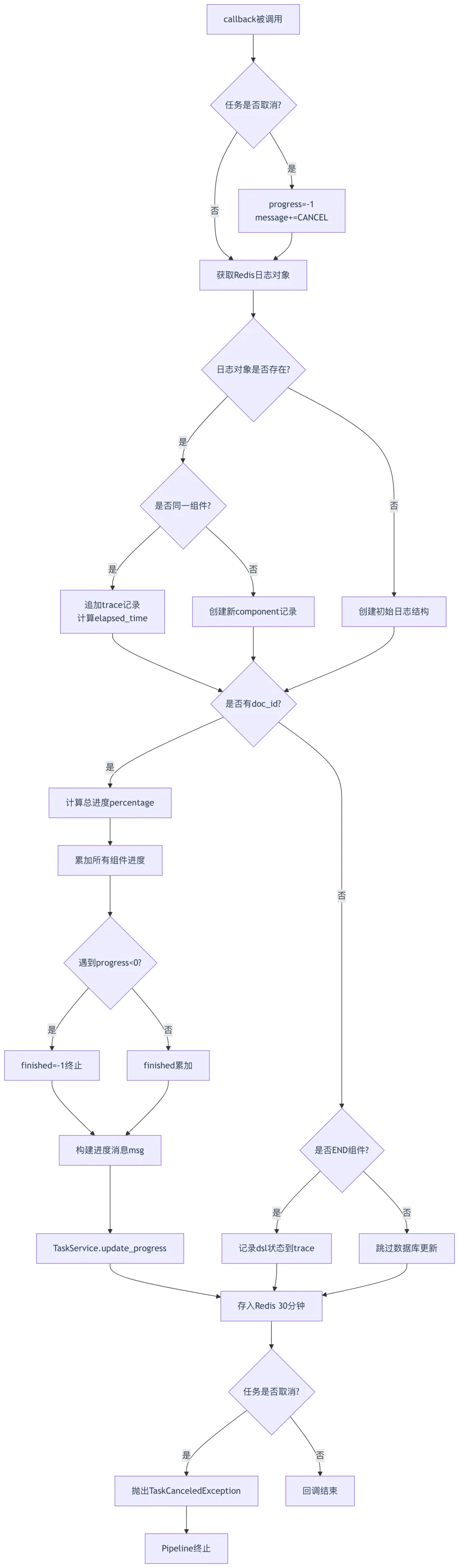
def callback(self, component_name: str, progress: float | int | None = None, message: str = "") -> None:from common.exceptions import TaskCanceledException# 第45行:Redis日志键,格式为"{flow_id}-{task_id}-logs"log_key = f"{self._flow_id}-{self.task_id}-logs"timestamp = timer() # 第46行:获取当前时间戳# 第47-49行:检查任务是否被取消,如果取消则标记进度为-1if has_canceled(self.task_id):progress = -1message += "[CANCEL]"try:# 第51-52行:从Redis获取已有日志对象bin = REDIS_CONN.get(log_key)obj = json.loads(bin.encode("utf-8"))if obj:# 第54-63行:如果是同一组件的后续调用,追加trace记录if obj[-1]["component_id"] == component_name:obj[-1]["trace"].append({"progress": progress, # 进度值(0-1或-1表示错误)"message": message, # 进度消息"datetime": datetime.datetime.now().strftime("%H:%M:%S"),"timestamp": timestamp,"elapsed_time": timestamp - obj[-1]["trace"][-1]["timestamp"], # 计算耗时})else:# 第65-70行:如果是新组件,创建新的component记录obj.append({"component_id": component_name,"trace": [{"progress": progress, "message": message, ...}],})else:# 第72-77行:首次调用,创建初始日志结构obj = [{"component_id": component_name,"trace": [{"progress": progress, "message": message, ...}],}]# 第78-95行:如果是文档处理任务,更新数据库进度if component_name != "END" and self._doc_id and self.task_id:percentage = 1.0 / len(self.components.items()) # 每个组件平均进度占比finished = 0.0# 第81-88行:累加所有组件的进度for o in obj:for t in o["trace"]:if t["progress"] < 0: # 遇到错误,立即终止finished = -1breakif finished < 0:breakfinished += o["trace"][-1]["progress"] * percentage# 第90-95行:构建进度消息并更新数据库msg = ""if len(obj[-1]["trace"]) == 1: # 新组件首次调用msg += f"\n-------------------------------------\n[{self.get_component_name(o['component_id'])}]:\n"t = obj[-1]["trace"][-1]msg += "%s: %s\n" % (t["datetime"], t["message"])TaskService.update_progress(self.task_id, {"progress": finished, "progress_msg": msg})# 第96-97行:如果是END组件且无doc_id,记录最终DSL状态elif component_name == "END" and not self._doc_id:obj[-1]["trace"][-1]["dsl"] = json.loads(str(self))# 第98行:将日志对象存入Redis,有效期30分钟REDIS_CONN.set_obj(log_key, obj, 60 * 30)except Exception as e:logging.exception(e) # 第101行:异常仅记录日志,不中断流程# 第103-104行:如果任务取消,抛出异常终止Pipelineif has_canceled(self.task_id):raise TaskCanceledException(message)
进度回调流程图:
核心技术点:
- Redis日志追踪
(第45、51-52、98行):使用Redis存储执行日志,支持跨进程日志共享,有效期30分钟防止日志堆积 - 时间戳精确计算
(第61行): elapsed_time = timestamp - obj[-1]["trace"][-1]["timestamp"],精确计算每次调用的耗时,用于性能分析 - 进度百分比分配
(第79行): percentage = 1.0 / len(self.components.items()),按组件数量平均分配进度,确保总进度在0-1之间 - 取消检测双保险
(第47-49、103-104行):callback入口和出口都检测取消状态,确保任务能及时终止
1.3 Pipeline异步执行流程(run方法)
完整源码解析(第117-174行):
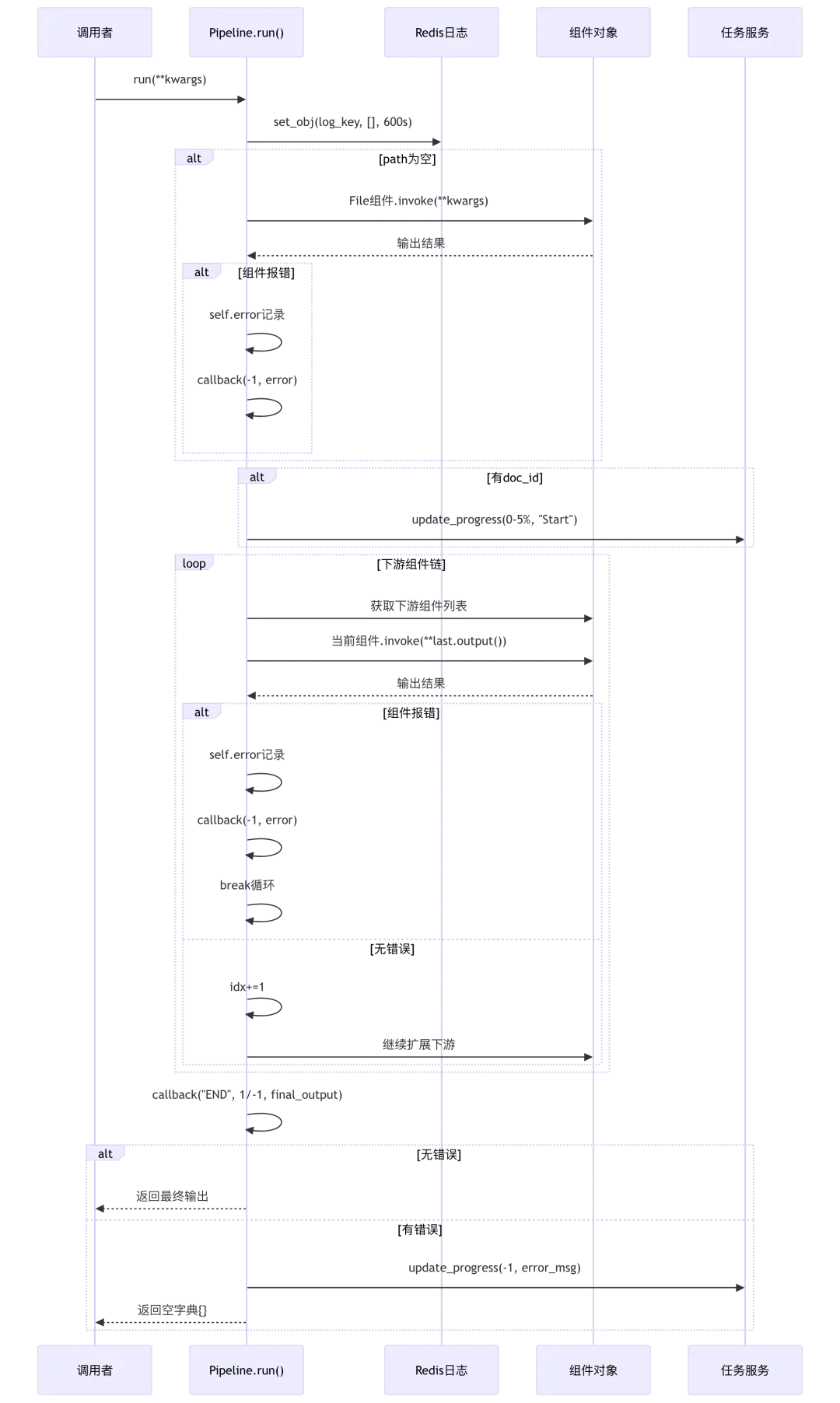
async def run(self, **kwargs):# 第118-122行:初始化Redis日志为空数组,有效期10分钟log_key = f"{self._flow_id}-{self.task_id}-logs"try:REDIS_CONN.set_obj(log_key, [], 60 * 10)except Exception as e:logging.exception(e)self.error = "" # 第123行:清空错误信息# 第124-130行:如果path为空,初始化第一个组件为"File"if not self.path:self.path.append("File") # File组件是默认入口cpn_obj = self.get_component_obj(self.path[0])await cpn_obj.invoke(**kwargs) # 异步调用第一个组件# 第128-130行:如果第一个组件报错,记录错误并回调if cpn_obj.error():self.error = "[ERROR]" + cpn_obj.error()self.callback(cpn_obj.component_name, -1, self.error)# 第132-136行:如果是文档处理任务,更新初始进度(0-5%随机值)if self._doc_id:TaskService.update_progress(self.task_id, {"progress": random.randint(0, 5) / 100.0, # 随机0-5%进度"progress_msg": "Start the pipeline...","begin_at": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")})# 第138-141行:获取当前path最后一个组件,并扩展其下游组件idx = len(self.path) - 1cpn_obj = self.get_component_obj(self.path[idx])idx += 1self.path.extend(cpn_obj.get_downstream()) # 获取下游组件列表# 第143-164行:循环执行下游组件链while idx < len(self.path) and not self.error:last_cpn = self.get_component_obj(self.path[idx - 1]) # 上一个组件cpn_obj = self.get_component_obj(self.path[idx]) # 当前组件# 第147-153行:定义异步invoke函数,传递上一个组件的outputasync def invoke():nonlocal last_cpn, cpn_objawait cpn_obj.invoke(**last_cpn.output()) # 当前组件接收上一个组件的输出# 第155-157行:创建异步任务并执行tasks = []tasks.append(asyncio.create_task(invoke()))await asyncio.gather(*tasks) # 等待任务完成# 第159-162行:检查当前组件是否报错if cpn_obj.error():self.error = "[ERROR]" + cpn_obj.error()self.callback(cpn_obj._id, -1, self.error)break # 报错则终止循环# 第163-164行:更新索引,继续扩展下游组件idx += 1self.path.extend(cpn_obj.get_downstream())# 第166行:调用END回调,记录最终状态(成功progress=1,失败progress=-1)self.callback("END", 1 if not self.error else -1, json.dumps(self.get_component_obj(self.path[-1]).output(), ensure_ascii=False))# 第168-169行:如果无错误,返回最后一个组件的输出if not self.error:return self.get_component_obj(self.path[-1]).output()# 第171-173行:如果错误,更新数据库进度为-1,返回空字典TaskService.update_progress(self.task_id, {"progress": -1,"progress_msg": f"[ERROR]: {self.error}"})return {} # 第174行:错误时返回空字典
Pipeline执行流程图:
关键设计模式:
- 异步组件链式调用
(第147-157行):每个组件异步执行,传递上一个组件的output作为输入,形成流水线 - 动态路径扩展
(第141、164行): self.path.extend(cpn_obj.get_downstream()),根据组件执行结果动态添加下游组件,支持条件分支 - 错误中断机制
(第159-162行):组件报错立即break,防止后续组件执行,节省资源 - 进度随机化
(第134行): random.randint(0, 5) / 100.0,避免所有任务进度同步更新造成数据库压力
1.4 Pipeline完整生命周期
二、Embedding模型集成架构
2.1 Embedding Base抽象类设计
源码位置:rag/llm/embedding_model.py:37-51
class Base(ABC): # 第37行:抽象基类,定义统一接口def __init__(self, key, model_name, **kwargs):"""Constructor for abstract base class.Parameters are accepted for interface consistency but are not stored.Subclasses should implement their own initialization as needed."""pass # 第44行:基类不存储参数,由子类自行实现def encode(self, texts: list): # 第46-47行:文档编码方法raise NotImplementedError("Please implement encode method!")def encode_queries(self, text: str): # 第49-50行:查询编码方法raise NotImplementedError("Please implement encode method!")
设计意图分析:
- 抽象基类不存储参数
(第44行):子类自行决定是否存储key、model_name等参数,避免基类内存浪费 - 双编码方法
(第46-50行): encode(texts: list):批量文档编码,用于索引构建 encode_queries(text: str):单个查询编码,用于检索 分离设计考虑:文档和查询可能使用不同的编码策略(如BGE使用prefix区分)
2.2 BuiltinEmbed内置嵌入模型
源码位置:rag/llm/embedding_model.py:53-89
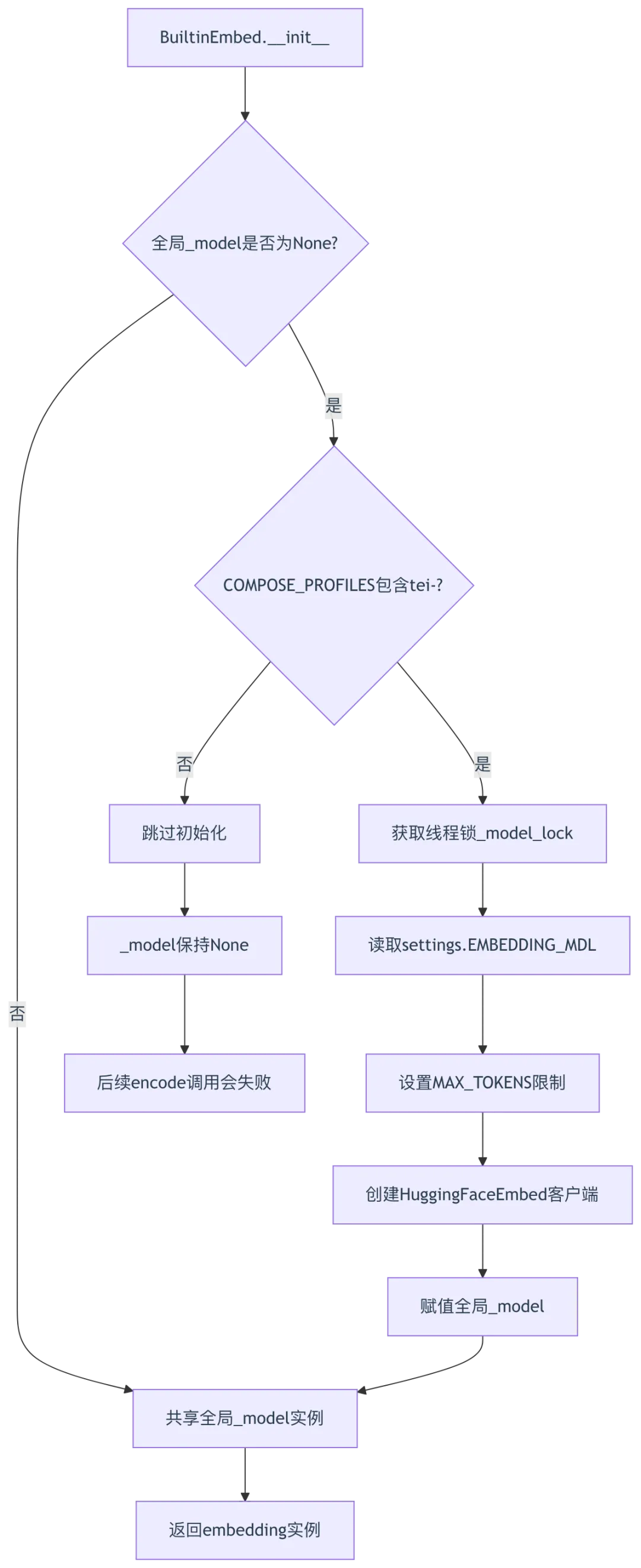
class BuiltinEmbed(Base): # 第53行:继承Base,实现内置模型_FACTORY_NAME = "Builtin" # 第54行:工厂名称标识MAX_TOKENS = {"Qwen/Qwen3-Embedding-0.6B": 30000, "BAAI/bge-m3": 8000, "BAAI/bge-small-en-v1.5": 500} # 第55行:模型token限制映射_model = None # 第56行:全局模型实例(单例)_model_name = "" # 第57行:模型名称_max_tokens = 500 # 第58行:默认token限制_model_lock = threading.Lock() # 第59行:线程锁,保护单例初始化def __init__(self, key, model_name, **kwargs):# 第62-63行:从settings读取配置logging.info(f"Initialize BuiltinEmbed according to settings.EMBEDDING_CFG: {settings.EMBEDDING_CFG}")embedding_cfg = settings.EMBEDDING_CFG# 第64-68行:如果全局模型未初始化且启用TEI服务,创建单例if not BuiltinEmbed._model and "tei-" in os.getenv("COMPOSE_PROFILES", ""):with BuiltinEmbed._model_lock: # 第65行:线程锁保护BuiltinEmbed._model_name = settings.EMBEDDING_MDLBuiltinEmbed._max_tokens = BuiltinEmbed.MAX_TOKENS.get(settings.EMBEDDING_MDL, 500)# 第68行:创建HuggingFace TEI客户端BuiltinEmbed._model = HuggingFaceEmbed(embedding_cfg["api_key"],settings.EMBEDDING_MDL,base_url=embedding_cfg["base_url"])# 第69-71行:每个实例共享全局模型(节省内存)self._model = BuiltinEmbed._modelself._model_name = BuiltinEmbed._model_nameself._max_tokens = BuiltinEmbed._max_tokensdef encode(self, texts: list): # 第73-85行:批量文档编码batch_size = 16 # 第74行:TEI推荐batch sizetoken_count = 0 # 第76行:累计token数ress = None# 第78-84行:分批编码,自动截断超长文本for i in range(0, len(texts), batch_size):embeddings, token_count_delta = self._model.encode(texts[i : i + batch_size])token_count += token_count_delta# 第81-84行:拼接批次结果if ress is None:ress = embeddingselse:ress = np.concatenate((ress, embeddings), axis=0) # NumPy拼接return ress, token_countdef encode_queries(self, text: str): # 第87-88行:查询编码return self._model.encode_queries(text)
单例模式流程图:
关键技术点:
- 单例模式
(第56、64-68行):全局共享模型实例,避免重复加载模型内存,使用 threading.Lock保护多线程初始化 - TEI服务检测
(第64行): "tei-" in os.getenv("COMPOSE_PROFILES", ""),通过环境变量检测是否启用HuggingFace TEI服务 - 批量编码
(第78-84行): batch_size=16符合TEI服务推荐值,使用NumPy拼接批次结果,避免内存碎片 - Token限制映射
(第55行):不同模型token限制差异巨大(30000 vs 500),映射表防止截断错误
2.3 OpenAI Embedding实现
源码位置:rag/llm/embedding_model.py:91-123
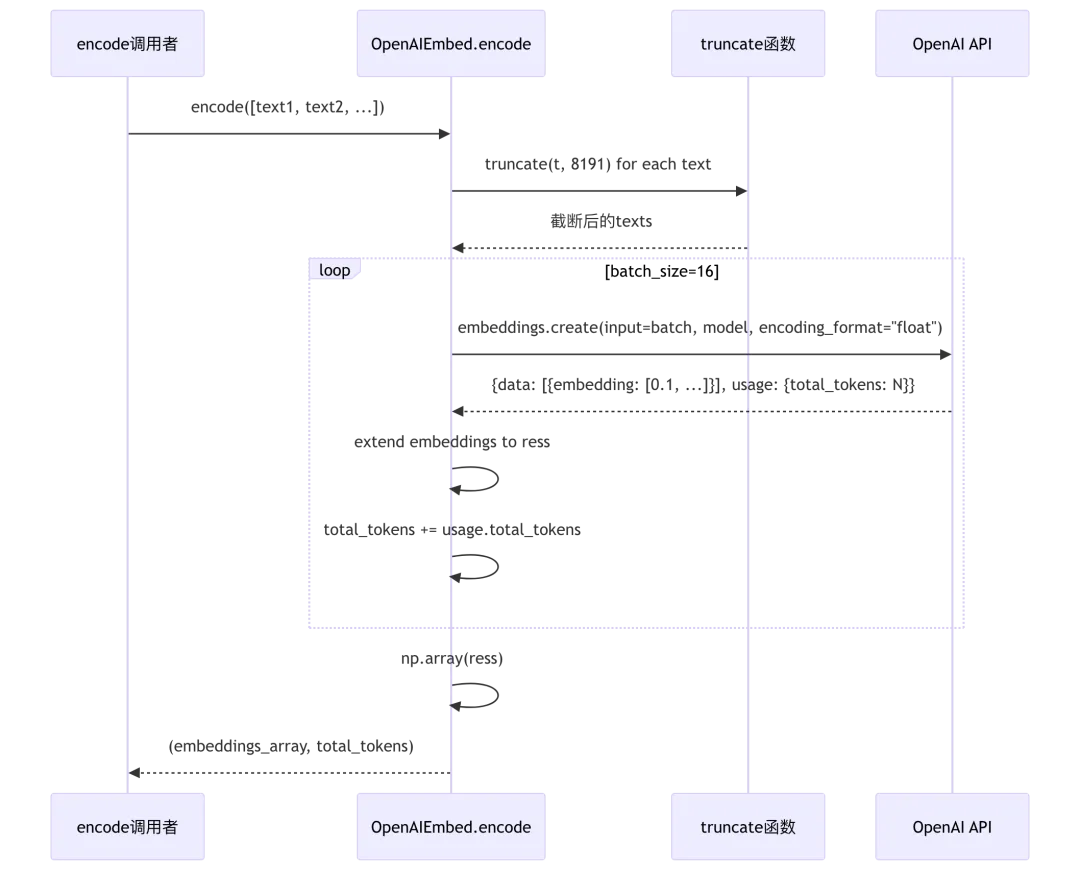
class OpenAIEmbed(Base): # 第91行:OpenAI embedding实现_FACTORY_NAME = "OpenAI" # 第92行:工厂名称def __init__(self, key, model_name="text-embedding-ada-002", base_url="https://api.openai.com/v1"):# 第95-96行:base_url默认为OpenAI官方APIif not base_url:base_url = "https://api.openai.com/v1"# 第97-98行:创建OpenAI客户端self.client = OpenAI(api_key=key, base_url=base_url)self.model_name = model_namedef encode(self, texts: list): # 第100-114行:批量文档编码batch_size = 16 # 第102行:OpenAI batch限制texts = [truncate(t, 8191) for t in texts] # 第103行:截断至8191 tokens(ada-002限制)ress = []total_tokens = 0# 第106-113行:分批调用APIfor i in range(0, len(texts), batch_size):res = self.client.embeddings.create(input=texts[i : i + batch_size],model=self.model_name,encoding_format="float", # 第107行:返回float格式extra_body={"drop_params": True} # 第107行:丢弃不支持参数)try:# 第109-110行:提取embedding和token数ress.extend([d.embedding for d in res.data])total_tokens += total_token_count_from_response(res)except Exception as _e:log_exception(_e, res)raise Exception(f"Error: {res}")return np.array(ress), total_tokensdef encode_queries(self, text): # 第116-122行:查询编码res = self.client.embeddings.create(input=[truncate(text, 8191)],model=self.model_name,encoding_format="float",extra_body={"drop_params": True})try:return np.array(res.data[0].embedding), total_token_count_from_response(res)except Exception as _e:log_exception(_e, res)raise Exception(f"Error: {res}")
OpenAI API调用流程:
关键技术点:
- Token截断
(第103、117行): truncate(t, 8191)符合text-embedding-ada-002的8191 token限制,防止API报错 - float格式强制
(第107行): encoding_format="float"确保返回浮点数组,而非base64编码 - drop_params参数
(第107行): extra_body={"drop_params": True}允许丢弃不支持参数,兼容不同OpenAI版本 - 错误日志记录
(第111-112、120-121行): log_exception(_e, res)记录完整API响应,便于调试
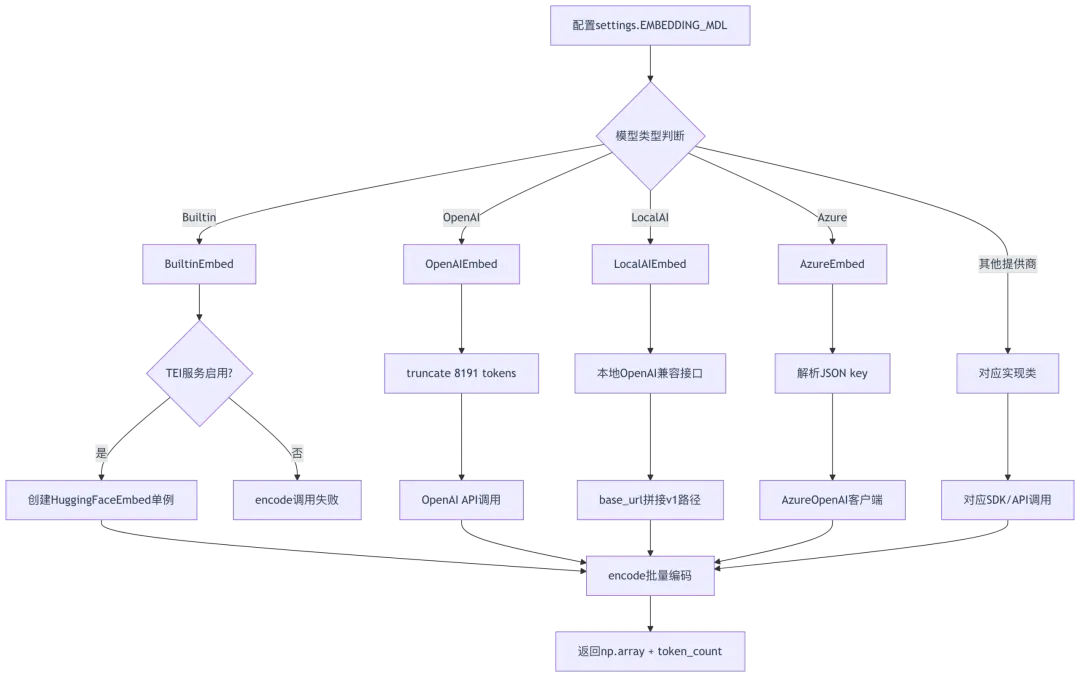
2.4 其他Embedding实现概览
实现类统计表:
设计模式共性分析:
- 工厂模式
(第54、92行): _FACTORY_NAME标识符用于模型工厂选择 - 继承复用
(第165、171、623、687行):多个类继承OpenAIEmbed或LocalAIEmbed,复用基础逻辑 - 重试机制
(第191-196、431-442行):QWenEmbed和MistralEmbed实现retry_max重试,应对API限流 - 批量处理
(第78-84、106-113行):几乎所有实现都采用batch_size分批调用,防止API超时
2.5 Embedding模型选择流程
三、Reranking重排序机制
3.1 Rerank Base抽象类设计
源码位置:rag/llm/rerank_model.py:28-54
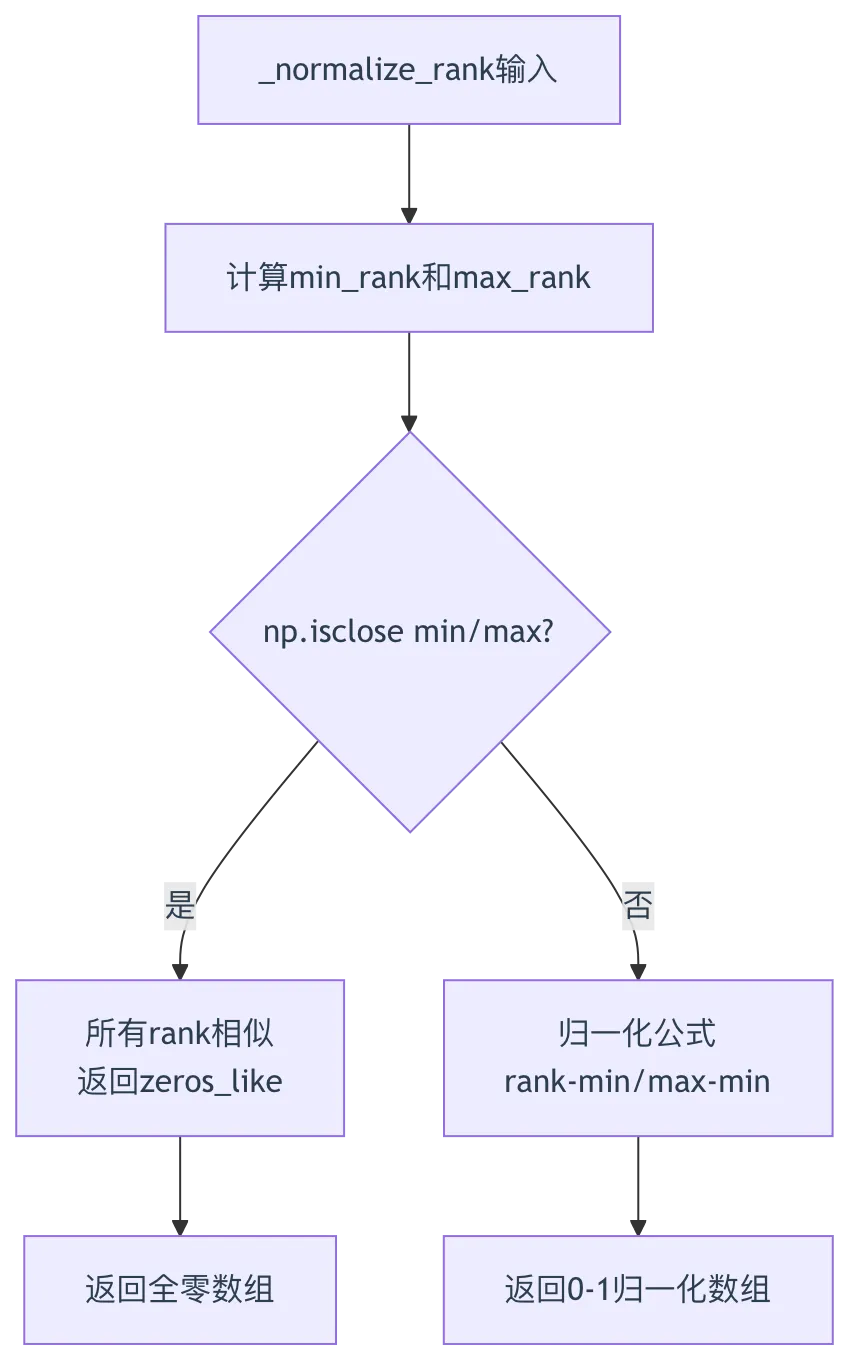
class Base(ABC): # 第28行:抽象基类def __init__(self, key, model_name, **kwargs):"""Abstract base class constructor.Parameters are not stored; initialization is left to subclasses."""pass # 第34行:基类不存储参数def similarity(self, query: str, texts: list): # 第36-37行:相似度计算方法raise NotImplementedError("Please implement encode method!")@staticmethoddef _normalize_rank(rank: np.ndarray) -> np.ndarray: # 第39-53行:归一化方法"""Normalize rank values to the range 0 to 1.Avoids division by zero if all ranks are identical."""min_rank = np.min(rank) # 第45行:最小值max_rank = np.max(rank) # 第46行:最大值# 第48-51行:如果min和max接近(所有rank相似),返回零数组if not np.isclose(min_rank, max_rank, atol=1e-3):rank = (rank - min_rank) / (max_rank - min_rank) # 归一化到0-1else:rank = np.zeros_like(rank) # 全零return rank
归一化逻辑图:
设计意图分析:
- 归一化必要性
(第48-51行):不同rerank模型返回的score范围不同(0-1或-logit),归一化统一到0-1便于后续排序 - 零数组处理
(第51行):所有文本相似度相同时,归一化会导致除零错误,返回零数组避免异常
3.2 Jina Rerank实现
源码位置:rag/llm/rerank_model.py:56-75
class JinaRerank(Base): # 第56行:Jina rerank实现_FACTORY_NAME = "Jina" # 第57行:工厂名称def __init__(self, key, model_name="jina-reranker-v2-base-multilingual", base_url="https://api.jina.ai/v1/rerank"):self.base_url = "https://api.jina.ai/v1/rerank" # 第60行:固定API endpointself.headers = {"Content-Type": "application/json", "Authorization": f"Bearer {key}"} # 第61行:认证头self.model_name = model_namedef similarity(self, query: str, texts: list): # 第64-74行:相似度计算texts = [truncate(t, 8196) for t in texts] # 第65行:截断至8196 tokens# 第66行:构造请求数据data = {"model": self.model_name,"query": query,"documents": texts,"top_n": len(texts) # 返回所有文本的rank}# 第67行:POST请求res = requests.post(self.base_url, headers=self.headers, json=data).json()rank = np.zeros(len(texts), dtype=float) # 第68行:初始化rank数组try:# 第70-71行:解析results数组for d in res["results"]:rank[d["index"]] = d["relevance_score"] # 按索引赋值scoreexcept Exception as _e:log_exception(_e, res)return rank, total_token_count_from_response(res) # 第74行:返回rank和token数
Jina API响应结构:
{"results": [{"index": 0, "relevance_score": 0.95},{"index": 2, "relevance_score": 0.85},{"index": 1, "relevance_score": 0.75}],"usage": {"total_tokens": 1024}}
关键技术点:
- index映射机制
(第70-71行):Jina API返回的results按relevance_score降序排列,但index字段指示原始texts位置,确保rank数组正确映射 - truncate截断
(第65行): truncate(t, 8196)防止超长文本超出Jina API限制 - top_n参数
(第66行): top_n: len(texts)确保返回所有文本的rank,而非仅top N
3.3 Cohere Rerank实现
源码位置:rag/llm/rerank_model.py:232-260
class CoHereRerank(Base): # 第232行:Cohere rerank实现_FACTORY_NAME = ["Cohere", "VLLM"] # 第233行:双工厂名称(Cohere和VLLM共用)def __init__(self, key, model_name, base_url=None):from cohere import Client# 第239-242行:base_url可选,支持自定义endpointclient_kwargs = {"api_key": key}if base_url and base_url.strip():client_kwargs["base_url"] = base_url # 自定义URL(如VLLM本地部署)self.client = Client(**client_kwargs)self.model_name = model_name.split("___")[0] # 第243行:去除___后缀def similarity(self, query: str, texts: list): # 第245-260行:相似度计算token_count = num_tokens_from_string(query) + sum([num_tokens_from_string(t) for t in texts]) # 第246行:token估算# 第247-253行:调用Cohere rerank APIres = self.client.rerank(model=self.model_name,query=query,documents=texts,top_n=len(texts), # 返回所有文本return_documents=False # 不返回文档内容,节省带宽)rank = np.zeros(len(texts), dtype=float) # 第254行:初始化rank数组try:# 第256-257行:解析results数组for d in res.results:rank[d.index] = d.relevance_score # Cohere SDK返回对象属性except Exception as _e:log_exception(_e, res)return rank, token_count # 第260行:返回rank和token数
Cohere与Jina对比表:
3.4 Huggingface本地Rerank
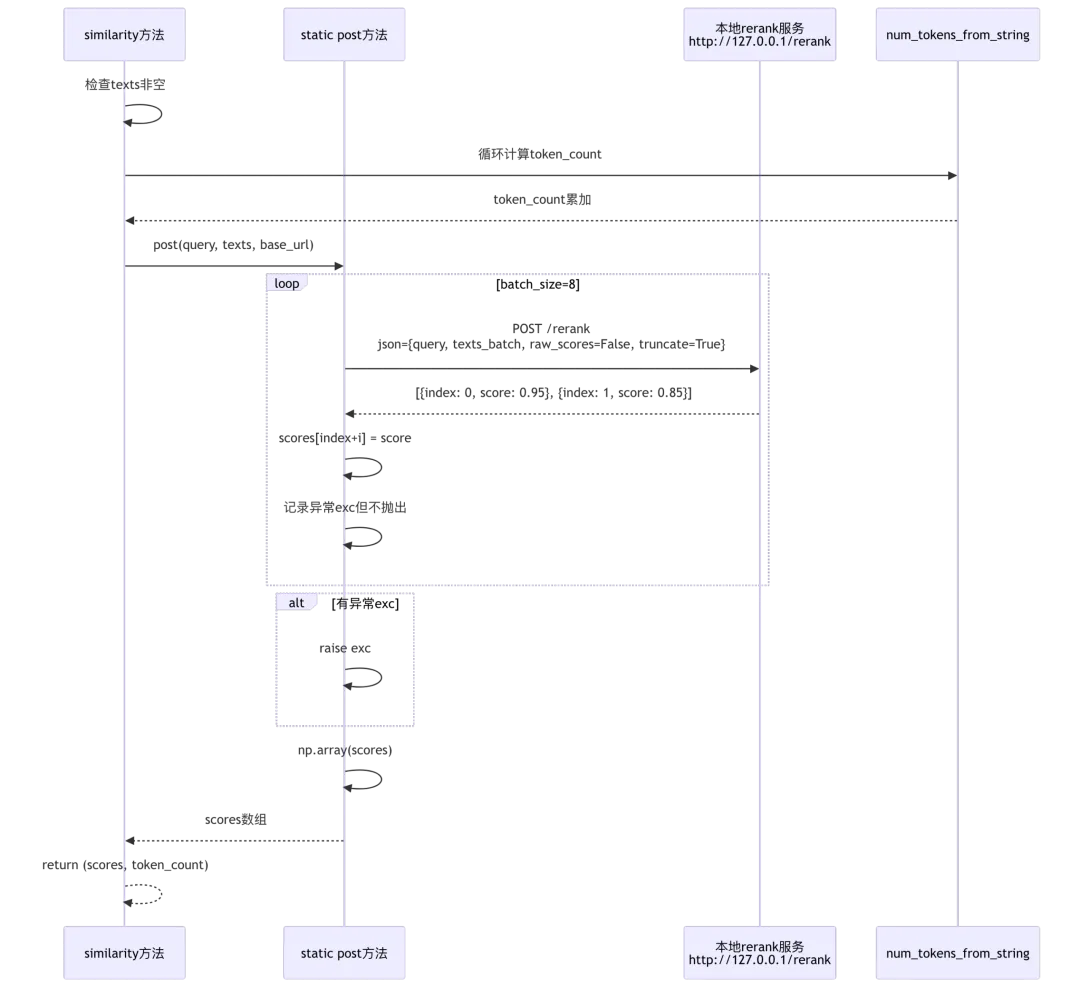
源码位置:rag/llm/rerank_model.py:388-422
class HuggingfaceRerank(Base): # 第388行:本地rerank实现_FACTORY_NAME = "HuggingFace" # 第389行:工厂名称@staticmethoddef post(query: str, texts: list, url="127.0.0.1"): # 第392-409行:静态POST方法exc = Nonescores = [0 for _ in range(len(texts))] # 第394行:初始化scoresbatch_size = 8 # 第395行:批次大小for i in range(0, len(texts), batch_size):try:# 第398-400行:HTTP POST请求本地服务res = requests.post(f"http://{url}/rerank",headers={"Content-Type": "application/json"},json={"query": query,"texts": texts[i : i + batch_size],"raw_scores": False, # 返回归一化score"truncate": True # 自动截断超长文本})# 第402-403行:解析响应并赋值for o in res.json():scores[o["index"] + i] = o["score"] # 注意:batch内index需+offsetexcept Exception as e:exc = e # 记录异常但不立即抛出if exc:raise exc # 第408行:最后抛出异常return np.array(scores) # 第409行:返回scores数组def __init__(self, key, model_name="BAAI/bge-reranker-v2-m3", base_url="http://127.0.0.1"):self.model_name = model_name.split("___")[0] # 第412行:去除后缀self.base_url = base_url # 第413行:本地服务URLdef similarity(self, query: str, texts: list) -> tuple[np.ndarray, int]: # 第415-421行if not texts:return np.array([]), 0token_count = 0for t in texts:token_count += num_tokens_from_string(t) # 第419-420行:本地估算token# 第421行:调用静态post方法return HuggingfaceRerank.post(query, texts, self.base_url), token_count
本地Rerank服务调用流程:
关键技术点:
- batch offset机制
(第403行): scores[o["index"] + i] = o["score"],本地服务返回的index是batch内的相对索引,需要加上batch起始偏移i - 异常延迟抛出
(第404-408行):batch调用过程中记录异常exc但不立即抛出,确保所有batch都尝试执行后再统一抛出 - raw_scores参数
(第400行): raw_scores: False请求服务返回归一化后的score而非原始logit,简化后续处理
3.5 Rerank模型完整对比表
四、完整RAG检索流程集成
4.1 Embedding → Retrieval → Rerank流程
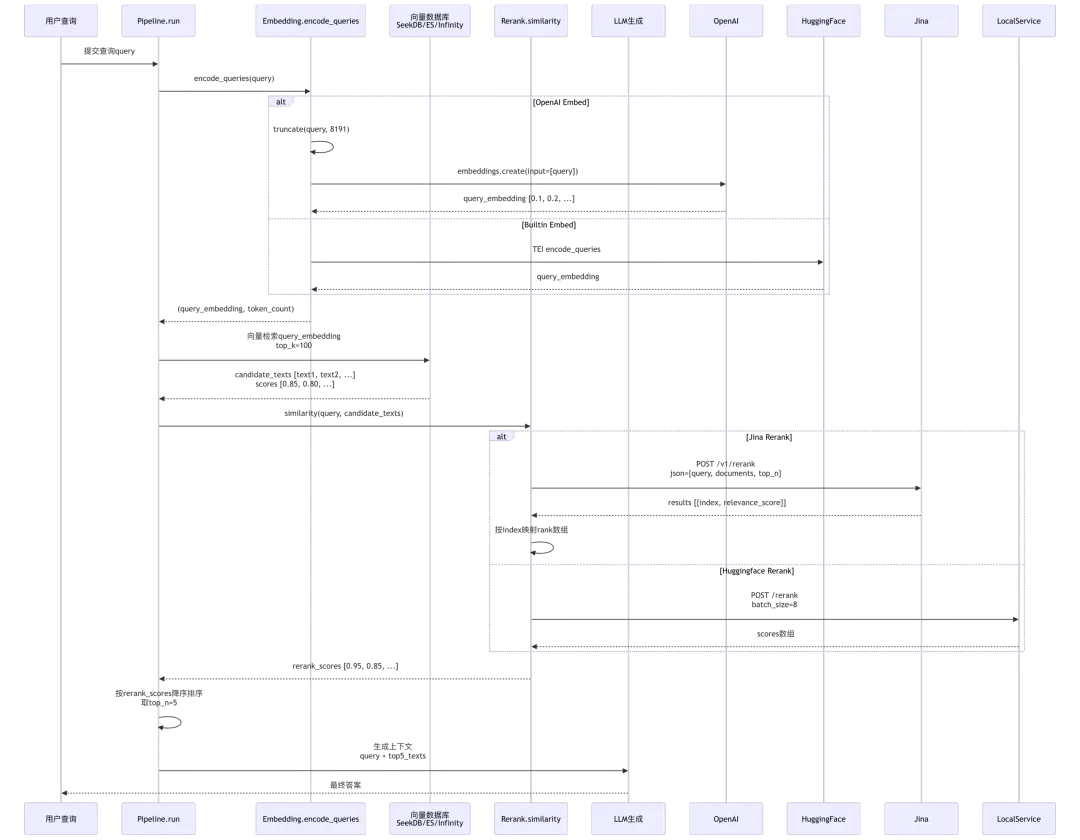
4.2 Pipeline组件编排实例
典型RAG Pipeline DSL结构:
{"components": {"File": {"obj": {"component_name": "File","params": {"path": "/data/document.pdf"}},"downstream": ["Parser"]},"Parser": {"obj": {"component_name": "Parser","params": {"parser_id": "pdf"}},"downstream": ["Embedding"]},"Embedding": {"obj": {"component_name": "Embedding","params": {"model": "BAAI/bge-m3"}},"downstream": ["Retrieval"]},"Retrieval": {"obj": {"component_name": "Retrieval","params": {"top_k": 100, "kb_ids": ["kb_001"]}},"downstream": ["Rerank"]},"Rerank": {"obj": {"component_name": "Rerank","params": {"model": "BAAI/bge-reranker-v2-m3"}},"downstream": ["Generate"]},"Generate": {"obj": {"component_name": "Generate","params": {"llm": "qwen-plus"}},"downstream": ["END"]}}}
Pipeline执行路径图:

五、设计模式与技术决策总结
5.1 核心设计模式统计表
| 单例模式 | _model实例 + threading.Lock保护 | ||
| 抽象基类 | ABCNotImplementedError | ||
| 工厂模式 | _FACTORY_NAME | ||
| 继承复用 | super().__init__(...) | ||
| 模板方法 | |||
| 回调机制 | |||
| 归一化策略 | (rank-min)/(max-min) |
5.2 技术决策对比表
| Embedding调用形式 | |||
| Token截断策略 | |||
| Batch Size选择 | |||
| Rerank归一化 | Base._normalize_rank | ||
| Pipeline错误处理 | |||
| 进度更新策略 | |||
| 日志存储位置 |
5.3 性能优化关键点
Pipeline优化:
- 异步组件调用
(第147-157行): asyncio.create_task(invoke())+asyncio.gather(*tasks),支持并发执行多个组件 - 动态路径扩展
(第141、164行): self.path.extend(cpn_obj.get_downstream()),根据执行结果动态添加下游,避免预加载所有组件 - Redis日志过期
(第98行): REDIS_CONN.set_obj(log_key, obj, 60 * 30),30分钟自动清理防止内存泄漏
Embedding优化:
- 单例模式
(BuiltinEmbed第64-68行):全局共享模型实例,避免重复加载内存开销 - 批量编码
(第78-84行): batch_size=16分批调用,防止API超时和内存溢出 - NumPy拼接
(第84行): np.concatenate((ress, embeddings), axis=0),高效合并批次结果
Rerank优化:
- batch offset机制
(HuggingfaceRerank第403行): scores[o["index"] + i],支持批量调用本地服务 - truncate预处理
(JinaRerank第65行): truncate(t, 8196),提前截断防止API报错和重复调用 - 归一化缓存
(Base第48-51行): np.isclose检测避免重复归一化计算
六、源码行号索引表
6.1 Pipeline核心方法
Pipeline.__init__ | ||
Pipeline.callback | ||
Pipeline.fetch_logs | ||
Pipeline.run |
6.2 Embedding关键实现
Base | __init__ | ||
Base | encode | ||
Base | encode_queries | ||
BuiltinEmbed | __init__ | ||
BuiltinEmbed | encode | ||
OpenAIEmbed | __init__ | ||
OpenAIEmbed | encode | ||
QWenEmbed | encode |
6.3 Rerank关键实现
Base | _normalize_rank | ||
JinaRerank | similarity | ||
CoHereRerank | similarity | ||
HuggingfaceRerank | post | ||
LocalAIRerank | similarity |
七、学习建议与实践路径
7.1 理论学习顺序
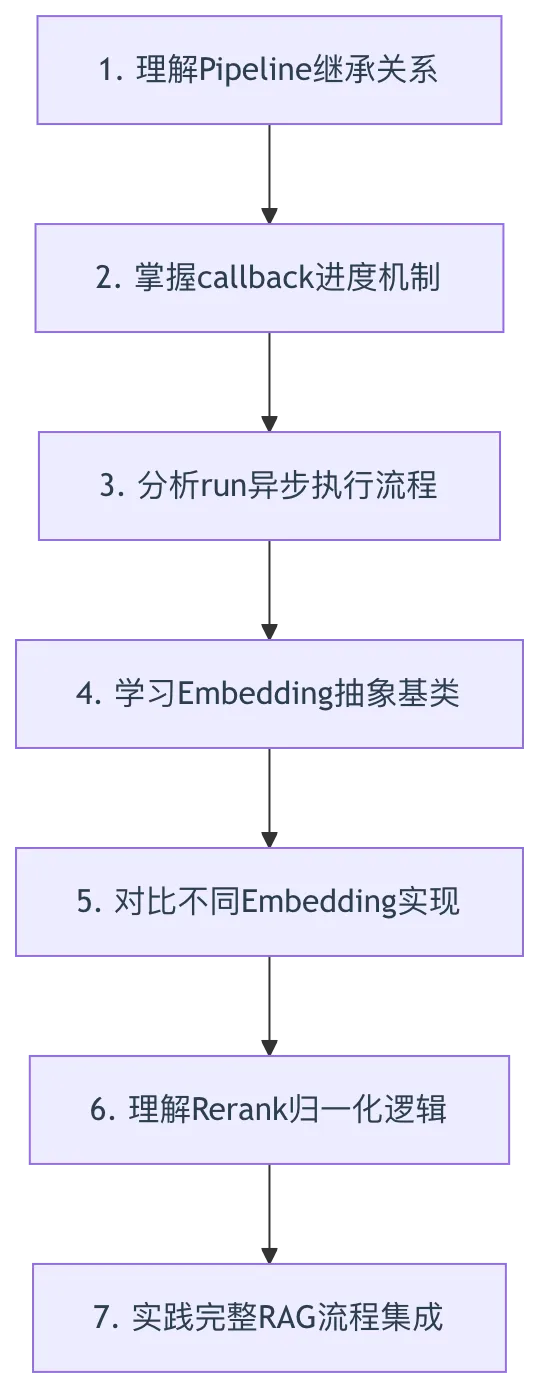
7.2 实践调试建议
调试Pipeline执行流程:
# 在rag/flow/pipeline.py:117添加日志async def run(self, **kwargs):print(f"[DEBUG] Pipeline.run开始,path={self.path}, components={list(self.components.keys())}")# 在第143行循环内添加组件调用日志while idx < len(self.path) and not self.error:print(f"[DEBUG] 执行组件{self.path[idx]},上游组件{self.path[idx-1]}输出={last_cpn.output()}")await cpn_obj.invoke(**last_cpn.output())print(f"[DEBUG] 组件{self.path[idx]}执行完成,error={cpn_obj.error()}")
调试Embedding批量编码:
# 在rag/llm/embedding_model.py:78添加批次日志for i in range(0, len(texts), batch_size):print(f"[DEBUG] Embedding批次{i}-{i+batch_size},texts数量={len(texts[i:i+batch_size])}")embeddings, token_count_delta = self._model.encode(texts[i : i + batch_size])print(f"[DEBUG] 批次embedding形状={embeddings.shape}, token_count={token_count_delta}")
调试Rerank index映射:
# 在rag/llm/rerank_model.py:70添加映射日志for d in res["results"]:print(f"[DEBUG] Rerank结果:index={d['index']}, relevance_score={d['relevance_score']}")rank[d["index"]] = d["relevance_score"]print(f"[DEBUG] Rerank最终rank数组={rank}")
八、常见问题与解决方案
8.1 Pipeline执行错误诊断
问题1:Pipeline报错self._model is None
原因:BuiltinEmbed单例未初始化,TEI服务未启用或settings.EMBEDDING_CFG缺失
解决方案:
# 检查环境变量docker exec ragflow-container printenv COMPOSE_PROFILES# 应输出tei-qwen或tei-bge# 检查settings配置docker exec ragflow-container cat /ragflow/conf/service_conf.yaml | grep EMBEDDING
问题2:Pipeline进度卡在0%
原因:callback方法Redis连接失败或TaskService.update_progress超时
解决方案:
# 在pipeline.py:51添加异常捕获try:bin = REDIS_CONN.get(log_key)except Exception as redis_err:print(f"[ERROR] Redis连接失败:{redis_err}")# 继续执行,不中断Pipeline
8.2 Embedding调用常见错误
问题1:OpenAI Embedding报错text length exceeds 8191
原因:truncate函数未生效或文本包含特殊token
解决方案:
# 在embedding_model.py:103强制截断texts = [truncate(t, 8191) if len(t) > 8191 else t for t in texts]
问题2:QWen Embedding重试耗尽
原因:dashscope API限流或网络超时
解决方案:
# 在embedding_model.py:195增加延迟time.sleep(30) # 从10秒增加到30秒
8.3 Rerank归一化问题
问题1:所有文本rank为0
原因:np.isclose(min_rank, max_rank)判断过严,所有score差异小于1e-3被归零
解决方案:
# 在rerank_model.py:48放宽toleranceif not np.isclose(min_rank, max_rank, atol=1e-6): # 从1e-3改为1e-6rank = (rank - min_rank) / (max_rank - min_rank)
九、扩展阅读与参考资源
9.1 官方文档
- HuggingFace TEI
: https://huggingface.co/docs/text-embeddings-inference - OpenAI Embedding
: https://platform.openai.com/docs/guides/embeddings - Jina Reranker
: https://jina.ai/reranker/ - Cohere Rerank
: https://docs.cohere.com/docs/reranking-guide
9.2 源码关联文件
agent/canvas.py:40 | |
api/apps/canvas_app.py:135 | |
rag/svr/task_executor.py:624 | |
common/token_utils.py | |
common/exceptions.py |
十、总结
本周深度解析了RAGFlow的RAG Pipeline核心架构,包括:
Pipeline编排机制:继承Graph实现组件链式调用,callback机制支持进度追踪和日志记录,run方法异步执行组件并动态扩展下游路径
Embedding模型集成:Base抽象类定义统一接口,BuiltinEmbed单例模式优化内存,OpenAI/LocalAI/QWen等多种实现适配不同提供商,批量编码和token截断防止API错误
Reranking重排序:Base._normalize_rank归一化统一score范围,Jina/Cohere/Huggingface等实现支持云端和本地部署,index映射机制确保rank数组正确性
完整RAG流程:Embedding → Retrieval → Rerank → Generate流水线集成,Pipeline DSL定义组件编排,异步执行和错误处理确保系统稳定性
通过源码逐行解析、流程图可视化、设计模式总结,读者可以深入理解RAGFlow检索增强生成的核心架构,为后续扩展和优化奠定坚实基础。
