 夜雨聆风
夜雨聆风很多 Java 后端同学第一次接触 MCP 时,会自然把它理解成“给大模型调用 API 的新格式”。这个理解不算错,但容易把重点带偏。MCP 的价值不在于把每个接口重新包装一遍,而是让 AI 应用用统一协议发现、描述和调用外部工具;而在企业项目里,真正难的不是连上 MCP Server,而是决定哪些工具可以被模型看到、什么时候能调用、调用结果如何审计。
截至 2026 年 5 月 29 日,Spring AI 的 MCP 支持已经比较工程化:MCP Client Boot Starter 支持多个 MCP 连接,覆盖 STDIO、SSE、Streamable HTTP 等传输方式,并能把 MCP Server 暴露出来的 Tools 集成进 Spring AI 的 Tool Calling 体系。换句话说,MCP 工具可以被转换为 ToolCallbackProvider,再交给 ChatClient 使用。
一个典型调用链可以这样理解:
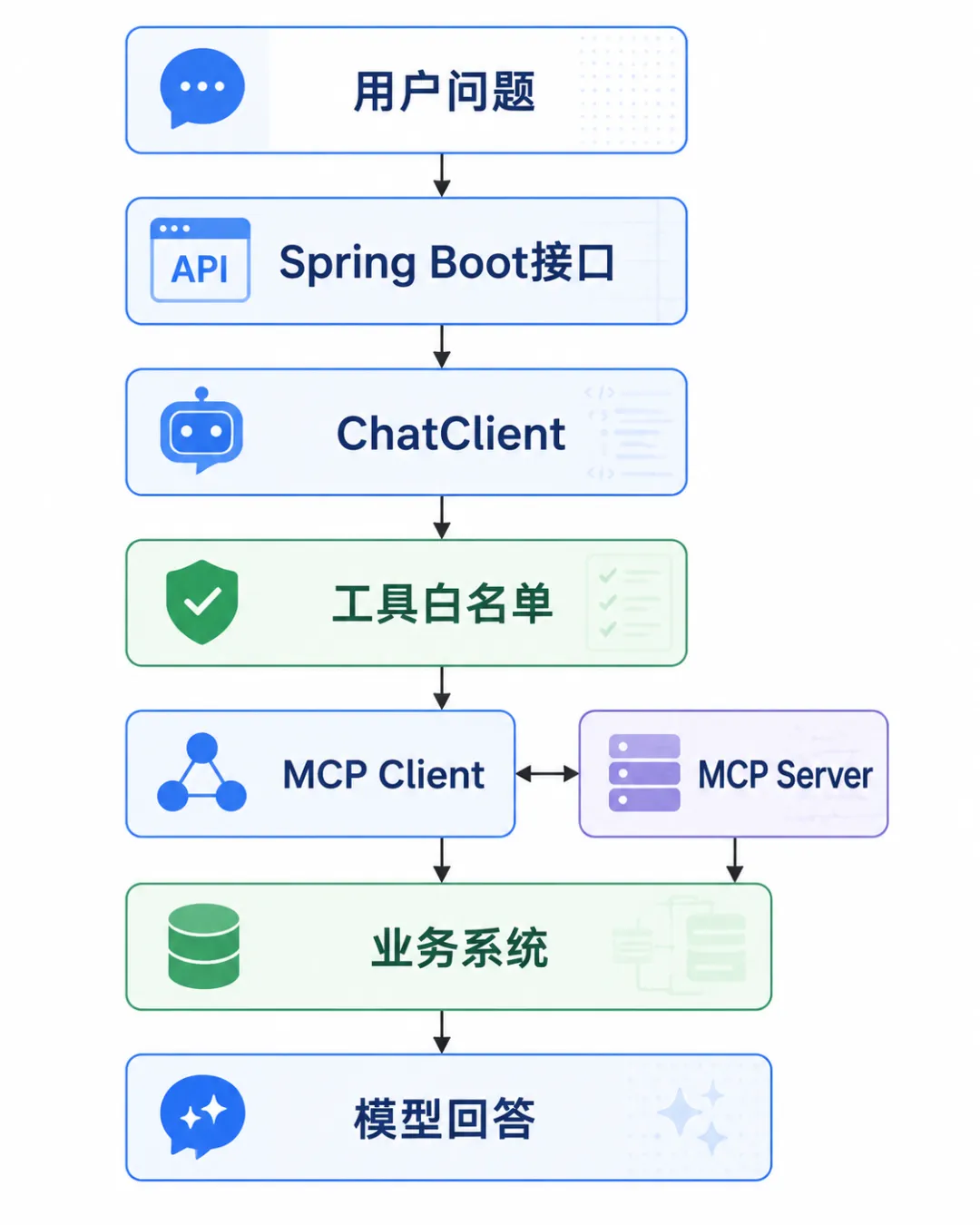
这里最容易犯的错误,是把 MCP Server 上所有工具都默认挂到一个全局 ChatClient 上。这样做开发阶段很爽,演示效果也直接,但生产环境会带来几个问题:工具数量太多会影响模型选择;同名或相似工具会造成误调用;只读问答场景可能意外暴露写操作;不同租户、不同角色本该看到的工具范围也不同。
Spring AI 官方文档也提醒过,默认工具会被同一个 ChatClient.Builder 构建出的客户端共享,适合通用能力,但如果不加控制,也可能在不该出现的场景里暴露出来。企业系统里更稳妥的方式是:MCP 负责连接和工具发现,业务代码负责工具筛选和边界控制。
以一个“客服助手读取 CRM 信息”的场景为例,依赖可以大致这样配置。具体版本建议跟随 Spring AI BOM,下面只展示关键依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-client-webflux</artifactId></dependency>
spring:ai:mcp:client:enabled: truetype: SYNCrequest-timeout: 20stoolcallback:enabled: truestreamable-http:connections:crm:url: http://localhost:8081/mcp
@BeanChatClientchatClient(ChatClient.Builder builder,ToolCallbackProvider mcpTools) {return builder.defaultToolCallbacks(mcpTools).build();}
@ComponentpublicclassMcpToolRegistry {private final SyncMcpToolCallbackProvider mcpToolProvider;publicMcpToolRegistry(SyncMcpToolCallbackProvider mcpToolProvider) {this.mcpToolProvider = mcpToolProvider;}publicToolCallback[] readonlyCrmTools() {Set<String> allowed = Set.of("crm_find_customer","crm_list_recent_orders","crm_query_ticket");returnArrays.stream(mcpToolProvider.getToolCallbacks()).filter(tool -> allowed.contains(tool.getToolDefinition().name())).toArray(ToolCallback[]::new);}}
@RestController@RequestMapping("/ai/customer-service")publicclassCustomerServiceAiController {privatefinal ChatClient chatClient;privatefinal McpToolRegistry toolRegistry;public CustomerServiceAiController(ChatClient.Builder builder,McpToolRegistry toolRegistry) {this.chatClient = builder.build();this.toolRegistry = toolRegistry;}@PostMapping("/ask")public String ask(@RequestBody AskRequest request) {return chatClient.prompt().system("""你是客服辅助助手。只能基于工具返回的客户、订单和工单信息回答。不允许修改客户资料,不允许承诺退款或补偿。""").user(request.question()).toolCallbacks(toolRegistry.readonlyCrmTools()).call().content();}public record AskRequest(String question) {}}
这段代码的重点不是语法,而是边界:当前接口只允许读 CRM,不允许写 CRM。即使 MCP Server 上存在 crm_update_customer、crm_create_refund_ticket 这类工具,也不会暴露给这个对话请求。
MCP 工具设计也要遵循后端接口设计的老原则:名字清晰、职责单一、输入结构稳定、返回值可解释。不要把一个工具设计成 executeSql(sql) 或 callInternalApi(path, body) 这种“万能入口”。它会把权限、审计、参数校验全部推给模型,这是非常危险的。更好的方式是暴露业务语义明确的工具,例如 crm_find_customer、ticket_create_internal_note、order_query_delivery_status。
工具返回值也不要太随意。模型更适合消费结构化、短而明确的数据,而不是几百行日志或完整数据库记录。对于 Java 后端系统,可以在 MCP Server 侧就完成字段裁剪和脱敏,只返回回答所需的最小信息。例如手机号只返回后四位,地址只返回城市和配送状态,内部备注按权限决定是否出现。
还要注意工具调用的可观测性。一次 AI 对话里,用户原始问题、最终回答、模型选择的工具、工具参数、工具耗时、工具返回摘要都应该进入日志或 trace。Spring AI 的 Advisor 机制可以用于增强请求上下文、记录调用链、接入对话记忆或 RAG 上下文。MCP 解决的是“怎么连接工具”,Advisor 更适合处理“请求前后如何治理”。
在安全上,不要把 MCP 当成天然可信的内部协议。HTTP 型 MCP Server 需要正常的认证授权;STDIO 型工具要特别谨慎,避免把用户输入拼接到命令行;跨系统工具要校验租户、用户角色和数据权限。MCP 官方规范已经把授权作为 HTTP 传输的重要部分,Spring AI 也提供了 MCP Client Security 相关支持,但这些只能提供基础能力,不能代替业务权限模型。
这也是我对 Spring AI + MCP 落地的判断:MCP 让工具接入更标准,Spring AI 让它更容易进入 Spring Boot 工程体系,但生产可用性取决于你有没有把工具当成后端接口来治理。工具白名单、权限校验、参数验证、审计日志、超时控制、结果脱敏,这些老问题不会因为接了大模型就消失,反而会变得更重要。
