 夜雨聆风
夜雨聆风AIOps 的数据底座
没有指标、日志、链路和事件,AI 只能猜。有了数据底座,日志助手、告警降噪和 RCA 才有证据。
事情是这样的。
上一章我们已经造了一个会出故障的小系统。
它有网关,有订单服务,有缓存,有数据库。它可以慢,可以报 500,可以数据库超时,也可以 CPU 飙高。
这件事做完以后,很多人会有一个很自然的冲动,那是不是可以开始接 AI 了?
比如把报错丢给 AI,让它分析原因。把一堆告警丢给 AI,让它总结事件。把日志丢给 AI,让它告诉我们下一步查什么。
这个方向当然没错。
但说真的,在真正动手之前,我们还差一个东西。
数据底座。
我这里说的数据底座,不是大数据平台,也不是一上来就搭一套很重的监控体系。对初学 AIOps 的人来说,数据底座先不用想得那么吓人。
它更像一套现场证据。
系统现在是否健康,要有指标。刚才到底发生了什么,要有日志。一次请求经过了哪些服务,要有链路追踪。谁在什么时候做了什么变更,要有事件记录。
这些东西看起来很基础,甚至有点老生常谈。但你只要真的做过故障处理,就会知道,很多线上排障卡住,不是因为人不聪明,也不是因为 AI 不够强。
是因为现场证据太少。
没有数据,AI 只能猜。
有了数据,AI 才能分析。
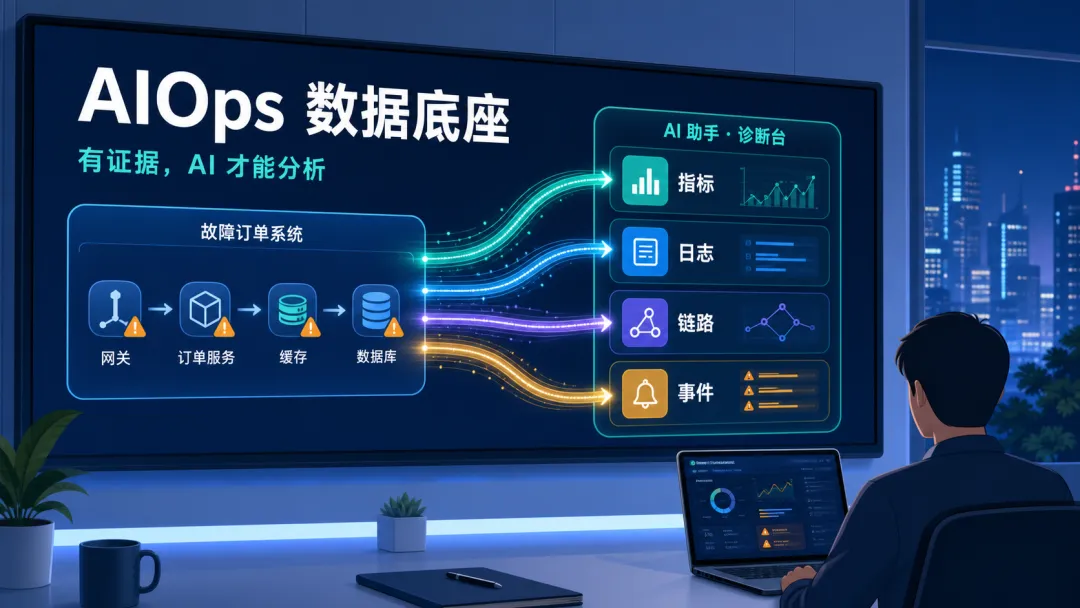
◆ 数据底座不是为了好看
很多公司刚开始做监控的时候,会先追求大屏。
CPU 曲线,内存曲线,接口 QPS,错误率,数据库连接数,Redis 命中率。一堆图铺满一个大屏,看起来很有科技感。
但真正出故障的时候,值班的人盯着大屏,心里想的往往不是这个大屏真酷。
他想的是,哪个服务先出的问题?影响了哪些接口?刚才有没有发版?这条错误日志和那条告警是不是同一件事?我现在应该先重启服务,还是先查数据库?
这时候你就会发现,数据底座的价值不在于展示。
它的价值在于还原现场。
线上故障其实很像案发现场。服务不会主动站出来说,我就是根因。数据库不会自己承认,我刚才慢查询把上游拖死了。网关也不会告诉你,我只是被上游拖累了,不要把锅扣我头上。
你只能通过证据往回推。
指标告诉你,系统状态什么时候开始异常。日志告诉你,程序在那个时间点具体打印了什么。链路追踪告诉你,一次请求从入口到出口,中间卡在了哪里。事件告诉你,在异常发生前后,人和系统做过什么动作。
这些证据放在一起,才可能拼出一条故障时间线。
对 AI 来说也是一样。
AI 并不会凭空拥有你们系统的现场知识。你不给它证据,它只能根据互联网上常见的故障套路回答你。
它会说,可能是数据库压力高,可能是缓存穿透,可能是线程池耗尽,可能是网络抖动。
这些话听着都对。
但没有证据支撑的时候,都不能直接用于决策。
所以我们在做 AIOps 的时候,第一步不是问 AI 能不能分析。
第一步应该问,系统有没有把该留下的证据留下来。
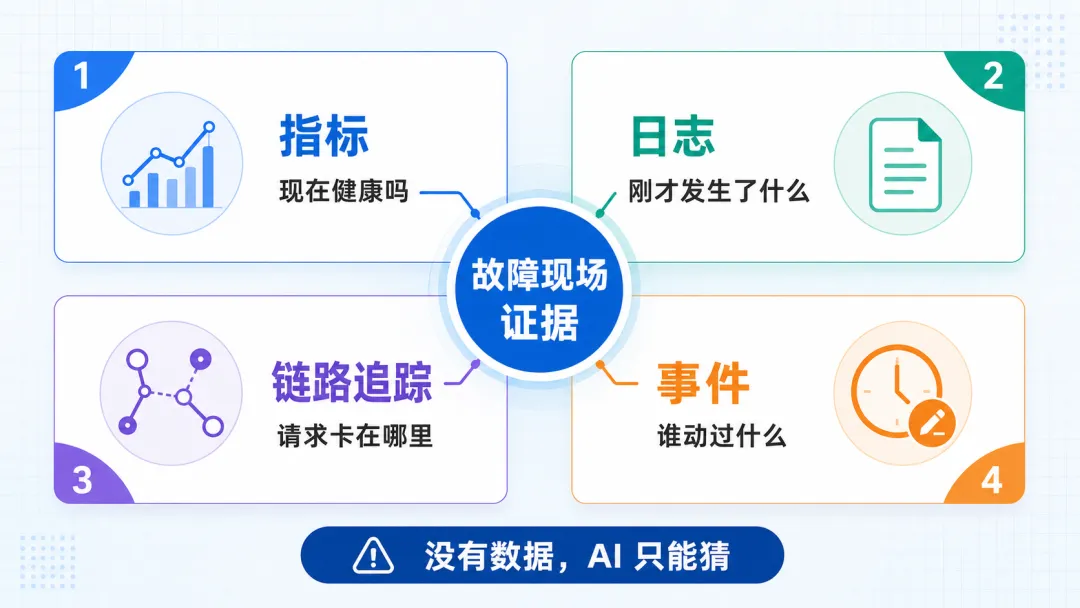
◆ 指标,看系统现在健不健康
先说指标。
指标解决的是一个最基础的问题,系统现在是否健康。
一个接口到底慢不慢,不能只靠用户说感觉卡。一个服务到底有没有压力,不能只靠运维说看起来还行。一个数据库到底是不是瓶颈,不能只靠开发说我本地没问题。
你需要一组可以连续观察的数字。
比如接口请求量,每秒有多少请求进来,突然变多还是突然变少。
比如接口延迟,平均耗时是多少,P95 是多少,P99 是多少。
这里稍微解释一下,P95 的意思不是平均值。它表示 95% 的请求都比这个值快,剩下 5% 的请求比它慢。
为什么这个指标重要?
因为平均值经常会骗人。
假设 100 个请求里,95 个请求 100 毫秒返回,5 个请求 10 秒才返回。平均下来可能看着还没那么吓人,但那 5 个用户已经炸了。
运维现场里,很多体验问题就是这样。
不是所有请求都慢,而是一小部分请求非常慢。
所以我们要看 P95、P99,要看错误率,要看超时数,要看资源使用率。
CPU、内存、磁盘 IO、网络流量、数据库连接数、缓存命中率,这些都属于指标。
指标的特点是,它不一定告诉你刚才发生了什么细节,但它能告诉你状态变了。
比如上一章那个订单系统,平时下单接口 P95 延迟是 120 毫秒。突然从 10 点 03 分开始,P95 升到 3 秒,错误率从 0.1% 升到 8%,数据库连接数打满。
光看这组指标,你还不能直接断定根因。
但你已经知道,现场不正常了。
你也知道,异常大概从什么时候开始。
这对排障非常关键。
因为故障处理的第一步,不是写结论。
是圈定时间和范围。
什么时候开始?影响哪些服务?是所有接口都慢,还是只有下单接口慢?是所有实例都异常,还是某一台机器异常?
指标就负责回答这些问题。
对 AI 来说,指标可以变成一个很好的输入。你可以把某个时间窗口里的关键指标整理出来,让 AI 帮你总结异常模式。
它可以告诉你,错误率上升和数据库连接数打满几乎同时发生,接口延迟随后升高,CPU 没有明显变化。
注意,这时候 AI 才开始像助手。
因为它不是在猜一个泛泛的可能原因。
它是在读一组真实指标。
◆ 日志,看刚才到底发生了什么
指标告诉你状态变了,但它不告诉你细节。
细节通常藏在日志里。
很多运维同学对日志非常熟,甚至可以说,传统排障里最常见的动作就是查日志。服务报错了,先看日志。接口 500 了,先看日志。任务失败了,先看日志。
但这里有一个问题。
日志太多了。
一套稍微正常一点的系统,每天产生的日志量都很吓人。访问日志、应用日志、错误日志、数据库日志、网关日志、系统日志,一层套一层。
人在排障的时候,其实不是在阅读日志。
人在做的是筛选。
先筛时间,再筛服务,再筛请求 ID,再筛错误级别,再从一堆普通信息里找到真正异常的那几行。
这也是为什么日志分析会成为最适合入门的 AI 运维场景。
因为 AI 很适合做文本总结和模式识别。
但前提是,日志本身要有基本质量。
如果你的日志只有一句 error happened,AI 再强也没办法分析。如果你的日志里没有时间、没有服务名、没有错误码、没有请求 ID、没有关键参数,AI 只能继续猜。
好的日志不需要一开始就很高级,但至少要能回答几个问题。
什么时间发生的?哪个服务打印的?发生在哪个接口或任务里?错误类型是什么?有没有请求 ID 或 trace ID 可以串起来?有没有关键上下文,比如用户 ID、订单 ID、商品 ID、数据库语句类型?
注意,这里不是让你把所有敏感数据都打印出来。
真实生产环境里,日志必须注意脱敏和权限。
我们现在讲的是学习项目,但也要养成这个意识。
日志要能帮助排障,但不能变成泄密源。
回到订单系统。
假设下单接口报 500。一条有价值的日志,应该让你看到,是哪个商品 ID 触发了异常,是库存扣减失败,还是数据库查询超时,是代码抛了空指针,还是依赖服务返回了错误。
这时候 AI 才有东西可以读。
你把一段日志交给 AI,它可以帮你提炼关键异常,合并重复错误,按时间线整理发生过程,给出可能排查方向。
但它做这些事的时候,依赖的不是魔法。
依赖的是日志里留下的证据。
◆ 链路追踪,看请求经过了哪些服务
指标告诉你状态,日志告诉你细节。
但在微服务系统里,还有一个很麻烦的问题。
一次请求会经过很多服务。
用户点了一次下单按钮,背后可能经过网关、订单服务、库存服务、支付服务、优惠券服务、数据库、缓存、消息队列。
当用户说下单慢的时候,你不能只看订单服务自己的日志。因为慢可能不在订单服务本身,它可能卡在库存服务,也可能卡在数据库,也可能是某个第三方接口拖慢了整条链路。
链路追踪解决的就是这个问题。
它关心的不是某一个服务单独怎么样,而是一次请求从入口到出口,中间经过了哪些节点,每个节点耗时多少,有没有报错。
你可以把它理解成一次请求的行程记录。
请求从网关进来,花了 20 毫秒。到订单服务,花了 80 毫秒。查缓存,2 毫秒。缓存没命中,查数据库,2800 毫秒。订单服务等待数据库返回以后,又处理了 40 毫秒。最后网关返回给用户,总耗时 3 秒。
这条链路一出来,很多事情就清楚了。
你不再只是笼统地说下单慢。
你能看到慢在哪个环节。
这对 AIOps 很重要。
因为根因分析最怕的就是只看表面。
网关报超时,不等于网关是根因。订单服务报错,不等于订单服务是根因。告警最多的地方,也不一定是最早出问题的地方。
链路追踪可以帮你把请求路径展开。
它让 AI 不只是看一个孤立错误,而是看到错误在系统里的传播过程。
当然,初学阶段不一定要一上来就接 OpenTelemetry、Jaeger、SkyWalking 这些完整方案。
如果你开发基础还不强,可以先在实验系统里做一个简化版。每次请求生成一个 request_id,网关、订单服务、缓存访问、数据库访问都把这个 request_id 打到日志里,每个环节记录开始时间、结束时间、耗时和状态。
这样你就能在日志里拼出一条简单链路。
这不是企业级链路追踪,但它已经能帮助你理解链路追踪的核心思想。
学习 AIOps,一开始最怕的不是简陋。
最怕的是跳过理解,直接堆工具。
◆ 事件,看谁在什么时候动过什么
还有一种数据,经常被初学者忽略。
事件。
这里的事件,不是第 10 章里要讲的 Incident 事件中心,而是更基础的变更和操作记录。
谁在什么时候发布了新版本?谁改了配置?谁扩容了实例?谁重启了服务?谁调整了数据库参数?谁打开了故障注入开关?
这些都应该被记录下来。
为什么它重要?
因为故障和变更之间,经常有关系。
很多线上事故并不是系统无缘无故坏了,而是某个变更之后开始异常。
新版本发布后,错误率上升。配置调整后,连接池不够用了。缓存策略改变后,数据库压力上来了。定时任务上线后,某个时间点 CPU 飙高。
你做过运维就知道,排障时有一个很常见的问题。
刚才有人动过什么吗?
这句话听起来很朴素,但非常关键。
如果没有事件记录,就只能靠群里问。谁刚才发版了?谁改配置了?谁重启了?有人记得吗?
这种排障方式太依赖人。
人在线,可能问得到。人不在线,就断了。人记错了,方向就偏了。
所以 AIOps 的数据底座里,一定要有事件。
在我们的学习项目里,事件可以先做得很简单。
每次触发故障注入,记录一条事件。每次修改配置,记录一条事件。每次模拟发布,记录一条事件。
事件里至少包括时间、操作者、动作类型、目标对象和备注。
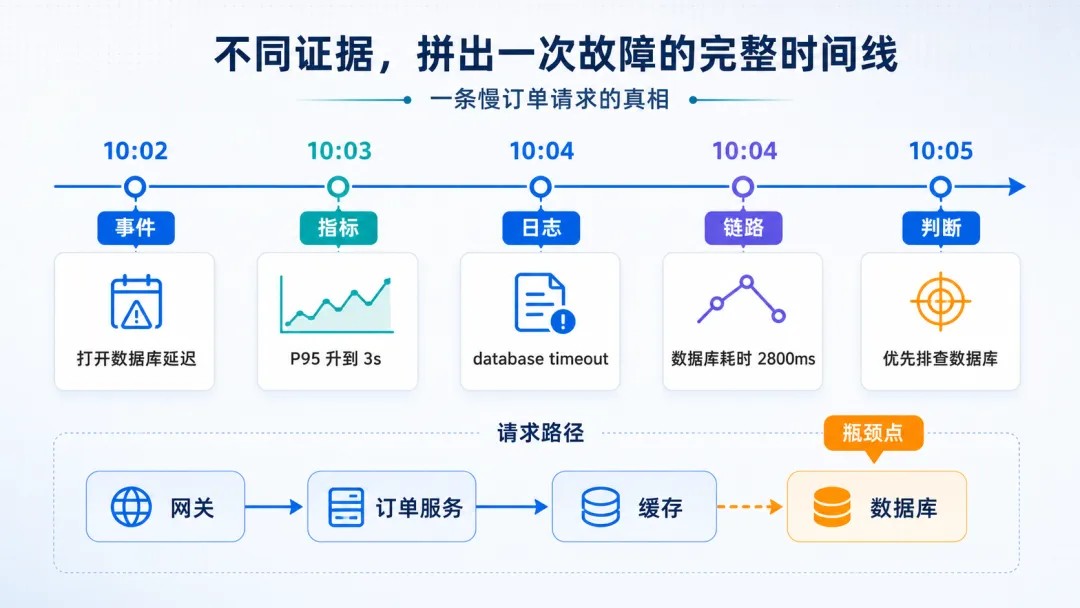
比如 10 点 02 分,admin 打开数据库延迟开关,目标是订单服务的数据库查询,备注是模拟慢查询。
然后 10 点 03 分,接口延迟上升。10 点 04 分,网关超时增加。10 点 05 分,告警触发。
这几条放在一起,AI 就可以帮你整理出一条更像样的时间线。
它会发现,异常不是凭空出现的,它发生在某个变更之后。
这就是事件的价值。
它把人的动作和系统状态连起来。
◆ 四类数据要能串起来
指标、日志、链路追踪、事件,单独看都有价值。
但真正有威力的时候,是它们能串起来。
比如我们模拟一次数据库超时。
事件记录里显示,10 点 02 分打开数据库延迟开关。
指标里显示,10 点 03 分下单接口 P95 延迟开始上升,数据库连接数接近上限。
日志里显示,订单服务大量出现 database timeout。
链路追踪里显示,请求主要耗时集中在数据库查询阶段。
这时候你再让 AI 分析,它的回答就会完全不一样。
没有这些数据时,它只能说可能是数据库问题。
有了这些数据后,它可以说,从时间线看,数据库延迟注入事件发生在 10 点 02 分,随后下单接口延迟和数据库连接数异常上升,订单服务日志出现大量超时,链路耗时集中在数据库查询阶段,因此数据库访问异常是更高优先级的候选原因。
这才叫分析。
它不是拍脑袋。
它有证据。
当然,即使这样,AI 也不能替你最终拍板。
它给的是候选原因和排查建议。
人还要验证。
比如你要关闭故障开关,看指标是否恢复。你要查数据库慢查询,看是否真的存在异常 SQL。你要确认是不是只有某个商品或某类请求受影响。
这就是我们后面会反复强调的边界。
AI 可以帮你整理证据,提出假设,生成报告,推荐下一步。
但最终判断要回到系统和证据。
◆ 初学阶段,先做一个小底座
说到这里,有些读者可能会有压力。
指标、日志、链路追踪、事件,听起来是不是又要搭一堆东西?
Prometheus,Grafana,Loki,ELK,OpenTelemetry,Jaeger,SkyWalking,Kafka。
光听名字就开始累了。
我建议你先别急。
学习阶段,不要一上来就追求企业级。
我们可以分三步走。
第一步,先把日志打好。让每个关键请求都有 request_id,让关键错误有明确错误类型,让重要操作有上下文。这一步最直接,也最适合接第 6 章的日志分析助手。
第二步,把核心指标暴露出来。至少有请求量、错误率、接口耗时、CPU、内存、数据库连接数这几类。你可以用成熟组件,也可以先用简单接口返回模拟指标。
第三步,补上简化链路和事件记录。先把 request_id 串起来,把每个环节耗时记录下来,把故障注入、配置修改、模拟发布这些动作记录成事件。
这样,你的小系统就从会出故障,升级成了会留下故障证据。
这个变化非常重要。
因为从这一刻开始,AI 才不再是陪你聊天。
它开始有机会成为运维助手。
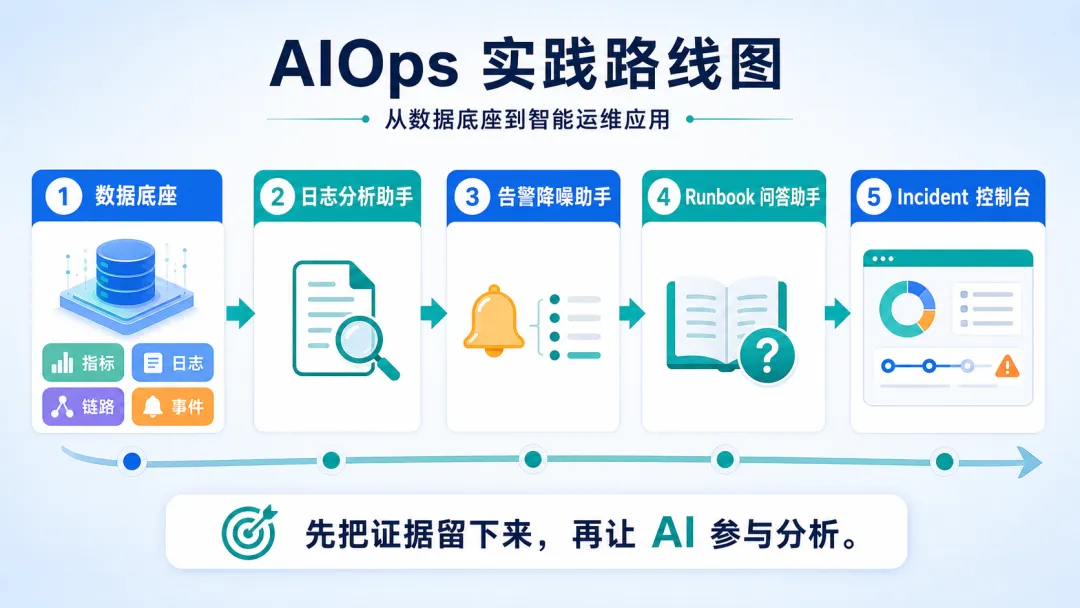
◆ 这章不炫,但它是地基
第三篇我们会做三个最容易落地的 AIOps 实战。
日志分析助手。
告警降噪助手。
Runbook 问答助手。
你会发现,它们看起来是三个项目,但底层都离不开数据。
日志分析助手需要高质量日志。告警降噪助手需要指标和告警数据,还需要知道这些告警之间有没有时间关系、服务关系和依赖关系。Runbook 问答助手需要故障现象、服务名称、错误类型和历史处理文档之间能对应起来。
再往后,根因分析、Incident 事件中心、自动化执行、人审机制,也都不是凭空长出来的。
它们都是在数据底座上继续往上搭。
所以第 5 章看起来不像一个炫酷项目。
它更像打地基。
地基这件事不性感。
但没有地基,后面的智能化都会飘。
很多人做 AIOps 做不下去,不是因为不会调模型。
是因为数据没整理好。
日志没有结构,指标没有口径,事件没有记录,链路串不起来。
这时候 AI 再强,也只能写一篇漂亮的猜测报告。
而我们要做的,不是漂亮猜测。
是能被验证的分析。
这一章你只需要带走一个判断。
AIOps 的起点不是 AI。
是数据。
下一章,我们就从最容易落地的一块开始。
让 AI 读日志。
不是读一段孤零零的报错,而是读我们这个小系统真正留下来的现场记录。
当日志里有时间、有服务、有请求 ID、有错误类型、有上下文,AI 的分析能力就会一下子从泛泛建议,变成像样的排查助手。
这也是我们第一个实战项目的入口。
日志分析助手。
