 夜雨聆风
夜雨聆风“ 模达卓越,智启未来”

www.modatech.com.cn / www.modatech.cn

“ 模达卓越,智启未来”
 模达科技
模达科技
www.modatech.com.cn / www.modatech.cn

国内外大模型发展如火如荼,近期有哪些值得关注的新闻?一起看看吧!
国际篇
INTERNATIONAL NEWS
2万亿美元的火星船票,SpaceX开启人类史上最大IPO
SpaceX即将于6月12日登陆纳斯达克(股票代码SPCX),启动人类史上最大IPO——募资700–750亿美元,估值高达1.75–2万亿美元。表面看是“火星梦想”的高光时刻,实则是一场与时间赛跑的融资突围:2025年私募融得的200亿美元已基本烧完,2026年一季度现金流再度吃紧。
公司业务呈“一盈两亏”格局:星链是唯一盈利支柱,2025年营收113.9亿美元、利润44.2亿;而xAI和航天持续巨亏——2025年xAI亏损63.6亿,星舰研发等投入超30亿美元;三年累计未弥补亏损达126.9亿美元。更严峻的是增长放缓:星链用户增速降至4.2%,ARPU跌至66美元;星舰单次发射成本仍高达4.2亿美元(目标<1.2亿),成功率仅45%;xAI营收32亿,距500亿目标需年均增长98.5%。

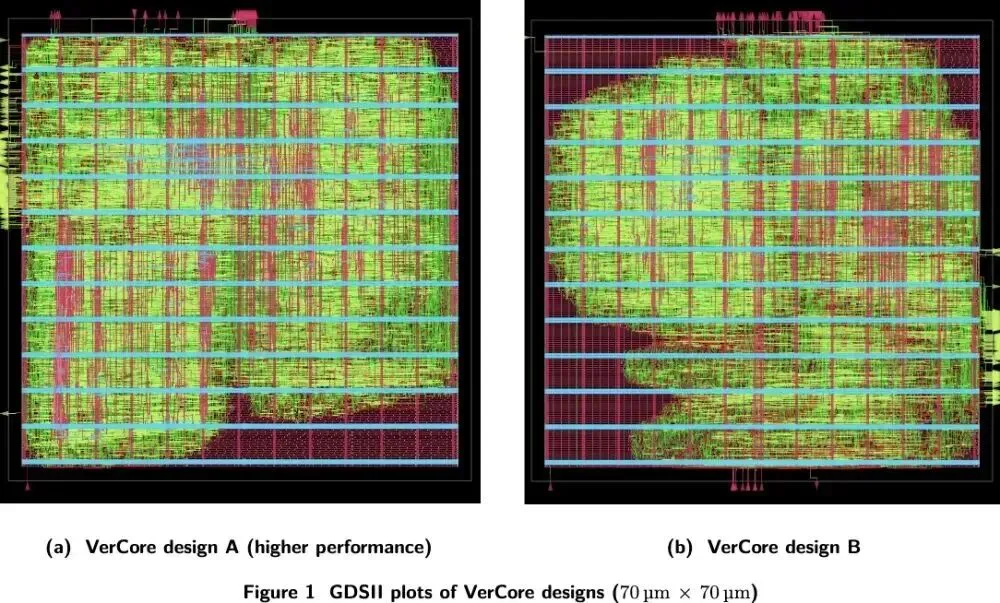
AI首次独自跑完芯片设计!219词进7nm图纸出,工程师全程没碰键盘
Verkor公司近日发布了一项突破性进展:其AI系统“Design Conductor”仅用12小时,就将一段219词的英文需求描述(如“设计一颗RV32I+ZMMUL、5级流水线、目标1.6GHz的RISC-V CPU”)自动转化为7nm工艺(ASAP7 PDK)下可交付流片的GDSII版图——全程零人工干预。
生成的CPU“VerCore”面积仅2809 μm²,主频1.48GHz,CoreMark跑分3261(约相当于2011年Intel Celeron SU2300),虽无缓存、未流片,但意义不在性能,而在首次打通从自然语言到物理版图的全栈AI设计闭环。该系统并非单一大模型,而是一个由多个专业子Agent协同的LLM编排框架,能自主完成需求分析、RTL编码、仿真调试(甚至写Python脚本比对波形定位bug)、时序收敛与布局布线。
图源:网络
一个月的活一周干完!英伟达世界模型训练速度飙升400%
英伟达推出的具身智能世界动作模型DreamZero,是通往AGI的关键一步:它以视频为学习原料,“先理解世界如何变化,再决定如何行动”,在RoboArena和MolmoSpaces两大机器人基准上双双登顶。相比传统VLA模型(如π0.5),其任务成功率提升超2倍,泛化性、跨机器人本体适配能力显著更强。但代价高昂——训练需8张H100 GPU连续运行25天,算力与显存压力巨大。
为破局,无问芯穹联合清华推出强化学习框架RLinf,对DreamZero训练全链路重构。实测显示:训练吞吐最高提升近4倍——5B模型达4.4 samples/sec/gpu(原仅1.1),14B模型加速2.7倍;更关键的是,Loss曲线稳定、任务成功率峰值达96.68%,精度零损失。1个月的训练,现在1周搞定。
图源:网络
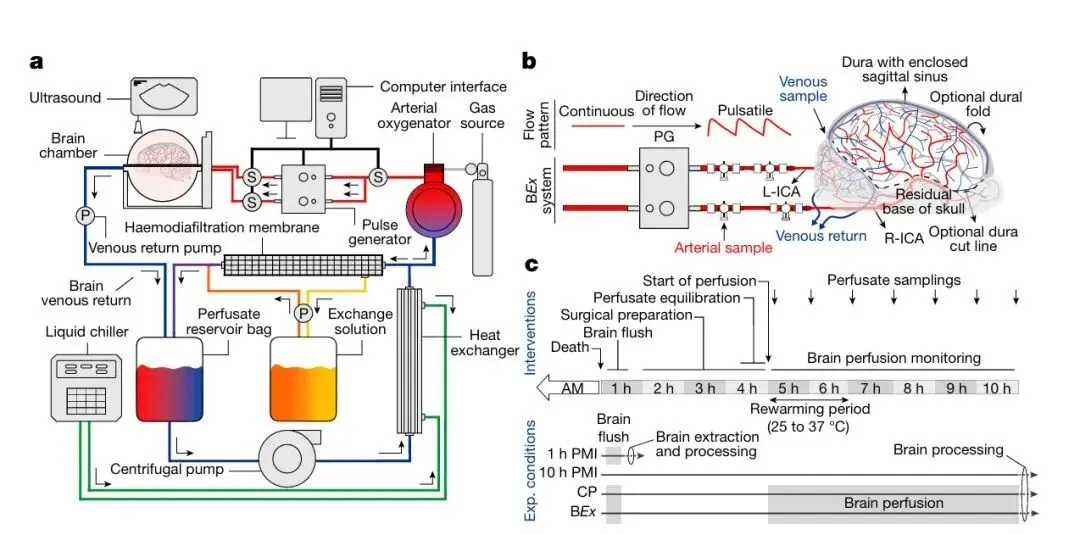
700多个死者的大脑,正在药物测试中被重新“复活”
美国初创公司Bexorg开发了一项突破性技术——“BrainEx”系统,能在人去世后24小时内,通过灌注特制液体维持离体人脑的基本生理功能。截至目前,该公司已用该技术处理超700颗捐献者大脑,每颗平均维持约24小时,并全程使用丙泊酚等麻醉剂抑制神经电活动,确保无意识、无痛觉。
这项技术源于耶鲁团队2019年在猪脑上的开创性研究,现升级至人脑应用,核心目标是破解神经药物研发难题:传统小鼠模型预测准确率低,类器官又缺乏真实衰老与疾病背景。而这些“活体人脑”保留了捐献者60–80年的遗传、环境与病理信息,使药物测试更贴近真实人体反应——实验显示,某帕金森病候选药在人脑上仅需原定剂量的1/20即生效,为研发节省约1年时间。


AI爱因斯坦快了,工业革命100倍冲击 !Clark预言2028跨越奇点
Anthropic联合创始人Clark与DeepMind CEO Hassabis罕见同步发出预警:AI正以远超预期的速度逼近“奇点”。Clark基于数百项实证数据指出,2028年底前AI实现递归自我改进的概率超60%——即AI能自主设计、训练并迭代出更强的自身。
他给出明确时间表:12个月内助力诺奖级科学发现;18个月内诞生AI全权运营、年营收数百万美元的公司;2年内双足机器人规模化进入工地。Hassabis则锚定AGI将在2029–2031年间落地,其社会冲击力相当于“工业革命×100”——不是百年渐进,而是十年剧变。二者共识在于:AI已从“工具”转向“研发主体”,AlphaFold曾一夜折叠2亿蛋白质,Mythos发现数千零日漏洞(远超前代500个),印证“AI正在加速AI自身进化”。

图源:网络

国内篇
DOMESTIC NEWS
DeepSeek V4价格打骨折,巨头抢着入场,梁文锋:目标是AGI
DeepSeek近期动作频频,引发AI圈高度关注。公司宣布DeepSeek-V4-Pro API永久降价:输入缓存命中价仅0.025元/百万Token,输出价6元,均为原价的1/4,凸显其“普惠AI”初心。与此同时,DeepSeek正推进约700亿元人民币的首轮融资,投前估值达450亿美元,或成中国AI史上最大单轮融资。
宁德时代、京东、网易等巨头已介入洽谈——尤其宁德时代这一“电池巨头”的入场耐人寻味:它正大力布局数据中心储能,而DeepSeek已在内蒙古自建数据中心,双方在绿色能源与算力基建上形成战略协同。创始人梁文锋明确表示:不以短期盈利为目标,坚持开源路线,全力冲刺通用人工智能(AGI)。

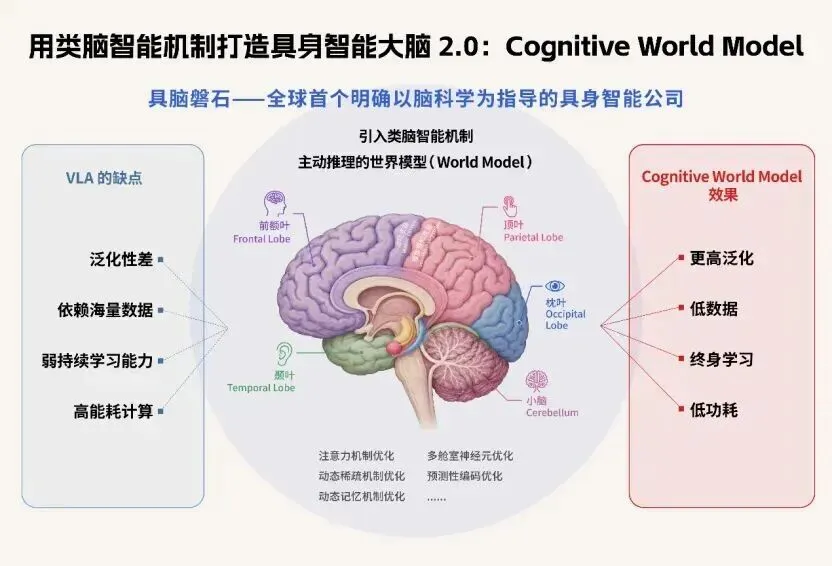
华为前具身大脑一号位创业,用认知科学造世界模型,获亿元级融资
2026年,AI正从“能看会动”迈向“真懂世界”。过去主流的VLA模型虽已在仓储分拣等简单场景落地,但一换环境就“卡壳”——要靠大量人工示范、难泛化、没记忆、不会推演后果。行业共识正在转向更底层的“机器人大脑”:世界模型。
华为前“具身大脑一号位”朱森华创立的具脑磐石,获亿元级融资,专注打造“认知世界模型”——不是模拟画面,而是让机器人像人一样思考:抓杯子会不会倒?绕障碍哪条路更稳?它借鉴认知神经科学,构建五层能力:从3D感知、物理规律建模,到交互试错、抽象预测,最终实现主动推理+终身学习。团队兼具华为盘古具身大模型经验与脑科学博士背景直击四大落地难点:低数据依赖、强跨场景泛化、长期记忆、端侧低功耗。
蚂蚁灵波论文被机器人顶会RSS 2026接收,让机器人边推演、边行动
蚂蚁灵波科技联合港科大等机构研发的机器人新模型LingBot-VA,近日被国际机器人顶会RSS 2026录用——该会议全球每年仅接收约15%投稿,含金量极高。简单说:它让机器人“学会预测未来”。传统机器人靠指令执行动作,而LingBot-VA能边看(视频输入)、边推演(预测环境变化)、边行动(生成动作),像人一样“先想再做”。
其核心是“因果世界建模”——严格按时间顺序,用前序观察和动作预测下一步状态,避免胡乱脑补。实测表现亮眼:在仿真平台RoboTwin 2.0的50个双臂任务中,成功率高达92.0%(Easy)和91.1%(Hard);在LIBERO基准达98.5%;真实机器人场景下,仅用50条示范数据,成功率就比业界基线π0.5提升超20个百分点。

华为提出“τ定律”:芯片比的不再是“谁更小”,而是“谁更快”
5月25日,华为芯片负责人何庭波在国际会议上发布“τ(tāo)定律”,主张用“时间缩微”替代传统的“几何缩微”。过去60年,芯片进步靠的是把晶体管越做越小(如3nm、5nm),这就是摩尔定律。但如今,制程微缩已近物理极限,“纳米”数字更多是营销标签,实际性能提升越来越难。
τ代表电路中的“时间常数”,反映信号传输延迟。华为认为,真正的瓶颈不是尺寸,而是信号跑得够不够快。为此,他们提出“逻辑折叠”技术:将原本平铺的电路关键部分上下堆叠,用极短的垂直连接代替长距离导线,大幅降低延迟——相当于在不升级光刻机的情况下,让芯片跑出更先进制程的速度。
这一思路已在华为新一代Kirin 2026芯片中局部应用,目标是实现“等效2nm”性能,预计2026年秋季上市。
当然,τ定律目前还是一个技术提案,面临EDA工具、良率控制等挑战。但它为受制于先进设备封锁的厂商打开了一条新路:当“做小”走不通,就让信号“跑得更快”。
芯片竞赛,正从空间维度转向时间维度。

华为发布AI DC数据基础设施全栈方案,加速行业智能化跃升

图源:网络
>>>>>>END<<<<<<
模达科技AI前沿,与您一起见证智能科技的蓬勃发展!
文章仅代表我司观点,请您甄别借鉴。


模达科技公众号
微信号 : modatechsub
扫码关注我们。
