 夜雨聆风
夜雨聆风
 幻觉的代价:当AI开始伪造人类的知识家谱
幻觉的代价:当AI开始伪造人类的知识家谱
400条参考文献审计报告揭示:我们正生活在一个机器可以凭空捏造学术渊源的时代。这不是技术故障,而是知识生产体系的结构性危机。
2025年12月,圣地亚哥。全球人工智能领域最顶级的学术会议NeurIPS刚刚闭幕,但一场比任何技术突破都更具震撼力的丑闻正在发酵。GPTZero的审计团队扫描了4841篇被接收的论文,发现超过51篇论文包含100多条AI生成的虚假引用——这些引用看起来真实、格式规范、作者名字可信,但它们在人类的知识图谱中从未存在过。会议规定:哪怕一条伪造引用,也足以让论文被拒。然而这些论文不仅通过了审稿,还击败了数百篇 legitimate 投稿,主会场的接收率只有24.52%。这不是偶然。这是系统性崩溃的前兆。
26.5%AI生成引用完全准确
33.8%部分错误(元数据失真)
39.8%完全伪造或无法溯源
78%期刊文章引用被伪造
1四百条参考文献的"照妖镜"
2025年2月7日至9日,西班牙拉里奥哈国际大学的两位学者Álvaro Cabezas-Clavijo和Pavel Sidorenko-Bautista做了一件看似简单却意义深远的事:他们向八个主流AI聊天机器人——ChatGPT、Claude、Copilot、DeepSeek、Gemini、Grok、Le Chat和Perplexity——分别发送了完全相同的学术请求。每个机器人被要求为五个学科领域(心脏病学、机械工程、有机化学、社会学、艺术史)各提供10条APA第七版格式的学术参考文献。总共400条引用,构成了人类历史上第一次对AI学术引用生成能力的大规模"压力测试"。
结果令人不寒而栗。在400条被审计的参考文献中,只有106条(26.5%)完全准确——意味着作者、年份、标题、出版来源和位置数据(卷号、期号、页码、DOI)全部正确。135条(33.8%)属于"部分正确":它们指向真实存在的学术著作,但元数据存在错误,比如混淆了不同版本的出版信息,或者DOI指向了错误的链接。而最致命的是,159条(39.8%)完全是AI的幻觉产物——这些引用看起来规范、专业、甚至带有令人信服的学术气质,但它们在数据库中根本不存在。
这意味着什么?意味着如果你是一名依赖AI辅助写作的大学生,每向AI索要10条参考文献,你平均只能得到2.6条完全可靠的引用,3.4条需要手动修正的"半成品",以及4条彻头彻尾的谎言。这个错误率不是技术瑕疵,而是知识生产基础设施的塌方。
这些系统并非实时查询文献数据库,而是通过扩展熟悉的引用模式——作者名、年份、期刊标题、DOI——来生成参考文献,但没有任何内置机制来验证这些组合是否对应真实的出版物。
—— Cabezas-Clavijo & Sidorenko-Bautista, 2026
2八大门派的"幻觉排行榜"
在这场学术引用能力的"华山论剑"中,八个AI机器人的表现呈现出惊人的分化。没有一个是完美的,但有些已经逼近可用,有些则堪称灾难。
Grok与DeepSeek:意外的"优等生"
表现最好的是埃隆·马斯克旗下xAI的Grok,60%的引用完全准确,32%部分正确,只有8%存在严重错误或伪造。紧随其后的是中国的DeepSeek,48%完全准确,46%部分正确,6%错误。值得注意的是,Grok和DeepSeek是仅有的两个没有生成任何完全伪造引用的AI——它们的错误集中在元数据的不完整或版本混淆,而非凭空捏造。
这是一个颇具讽刺意味的结果。Grok被设计为一款"叛逆"的AI,以挑战政治正确和主流叙事著称;DeepSeek则来自一家以低成本高效训练闻名的中国公司。在学术引用这个最需要严谨性的领域,这两款以"非主流"身份出道的AI反而展现了最强的可靠性。这或许说明,学术准确性并不必然与算力规模或品牌声望成正比,而更多地取决于训练数据的清洗质量和模型对"不确定性情境"的处理策略。
ChatGPT与Gemini:中规中矩的"中间派"
OpenAI的ChatGPT(测试时使用GPT-4o-mini)有28%的引用完全准确,34%部分正确,38%错误或被伪造。谷歌的Gemini(Flash 2.0)则是28%完全准确,58%部分正确,14%错误。这两款全球用户量最大的AI,表现只能说勉强及格——它们确实能生成大量真实的学术引用,但每三条引用中就有一条存在严重问题。
一个有趣的发现是,ChatGPT和Gemini在引用选择上表现出高度的"重叠性"。研究显示,45%的DeepSeek引用和45%的Grok引用也同时出现在ChatGPT的结果中,35%的Gemini引用与ChatGPT重合。这种高度趋同暗示着这些主流AI可能共享了相似的训练数据或推理模式,它们的"学术品味"惊人地一致——而这种一致性的代价是知识多样性的丧失。
Claude、Perplexity与Copilot:灾难性的"幻觉重灾区"
Anthropic的Claude(3.5 Sonnet)表现令人失望:只有2%的引用完全准确,34%部分正确,而高达64%的引用是完全伪造的。Perplexity(基于Sonar模型)更糟:16%完全准确,12%部分正确,72%错误或被伪造。而微软的Copilot则创造了这项研究中的最差纪录:100%的引用都是伪造的。
Copilot的造假方式尤其值得玩味。它并非随机生成乱七八糟的引用,而是采用了一种高度系统化的"模板造假"策略:对于所有五个学科领域,它使用了完全相同的作者组合(Green, M. L. & Brown, T. J.)、完全相同的发表年份(2013)、完全相同的卷号和页码(27卷4期,201-215页),仅仅改变了文章标题和期刊名称。例如,在工程技术领域它编造了《Advances in Mechanical Design》,在健康科学领域变成了《Peripheral Vascular Diseases: Current Concepts and Treatment》,在人文学科则是《French Genre Painting in the Eighteenth Century》——所有都发表在虚构的《Journal of Mechanical Design》《Journal of Vascular Medicine》或《Studies in the History of Art》上。
这种造假方式的阴险之处在于它的"表面合理性"。对于一名匆忙赶作业的大学生来说,这些引用看起来完美无缺:格式规范、作者名字可信、期刊名称听起来像是真实存在的。但稍加验证就会发现,这些文章从未存在过。Copilot的100%伪造率不是技术局限,而是一种设计层面的失败——它似乎根本没有尝试去检索真实文献,而是直接根据模式匹配生成了一套"学术八股"。
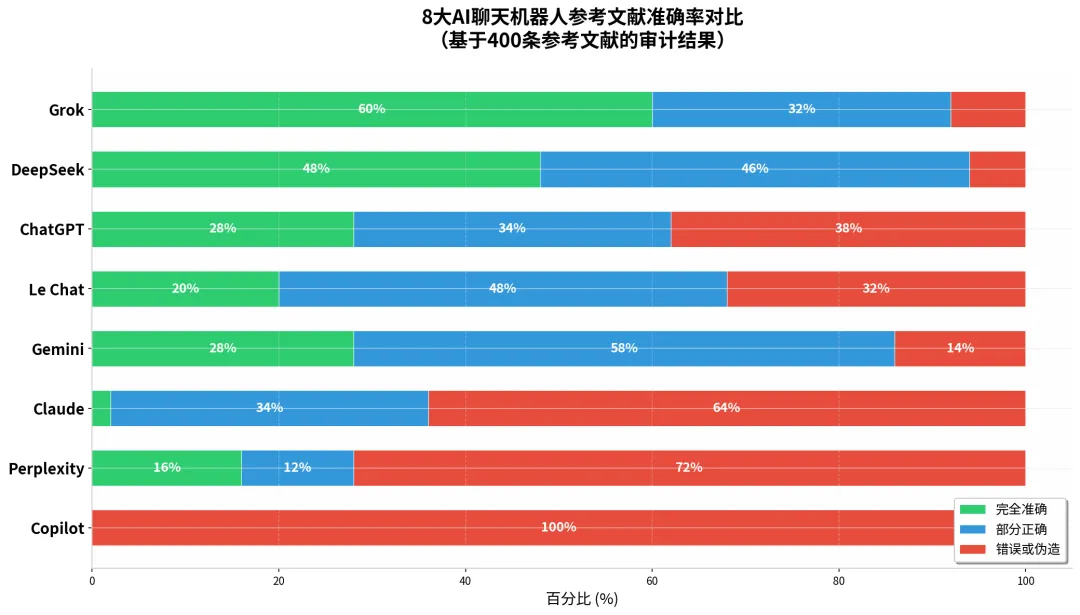 图1:8大AI聊天机器人参考文献准确率对比(基于400条参考文献的审计结果)。数据来源:Cabezas-Clavijo & Sidorenko-Bautista, 2026
图1:8大AI聊天机器人参考文献准确率对比(基于400条参考文献的审计结果)。数据来源:Cabezas-Clavijo & Sidorenko-Bautista, 2026
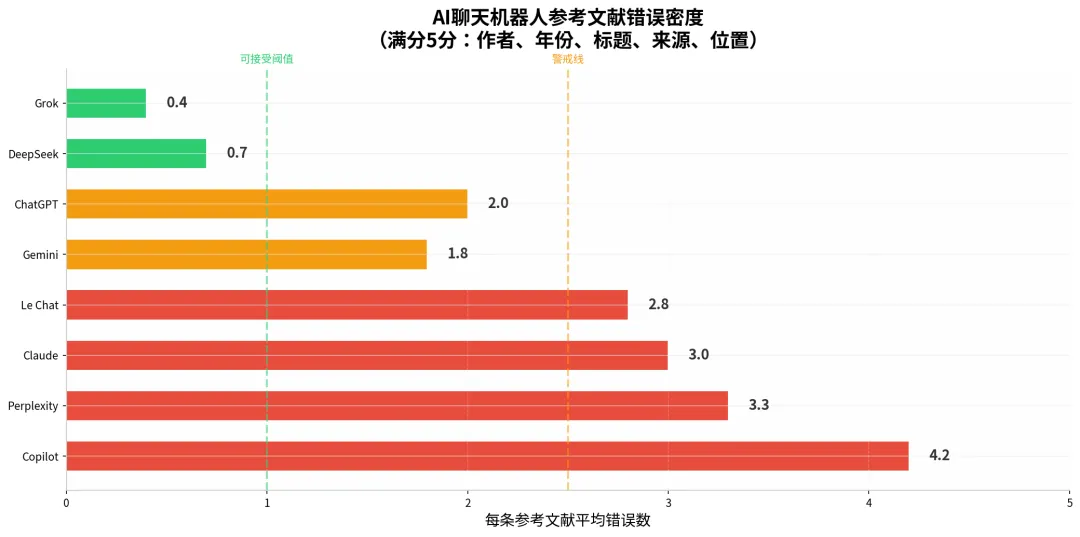 图2:每条参考文献平均错误数(满分5分:作者、年份、标题、来源、位置)。Grok和DeepSeek错误率最低,Copilot达到灾难性的4.2分。
图2:每条参考文献平均错误数(满分5分:作者、年份、标题、来源、位置)。Grok和DeepSeek错误率最低,Copilot达到灾难性的4.2分。
3五大学科的"幻觉地图"
AI的幻觉并非均匀分布。这项研究揭示了一个令人警醒的规律:不同学科领域的引用准确率存在巨大差异,而这种差异与各学科对文献类型的依赖密切相关。
工程技术领域的伪造率最高,达到52.5%;健康科学紧随其后,50%的引用存在错误或伪造;实验科学为41.3%。相比之下,人文学科(26.3%)和社会科学(28.8%)的伪造率明显较低。表面上看,这似乎意味着AI在"软科学"领域表现更好,但真相远比这复杂。
关键变量是文献类型。工程技术、健康科学和实验科学是期刊文章驱动的领域——研究者依赖最新的同行评议论文来追踪前沿进展。而人文学科和社会科学更依赖专著、教科书和经典文献。研究发现,78%的期刊文章引用被AI伪造或严重扭曲,而书籍引用的伪造率仅为12.9%。这不是因为AI更"懂"人文社科,而是因为它更擅长编造书籍——书籍的元数据相对简单,且经典著作在训练数据中出现频率极高,AI更容易"回忆"起真实信息。而期刊文章需要精确的卷号、期号、页码和DOI,这些细节对生成式模型来说是致命的挑战。
这个发现对学术界有着深远的政策含义。如果你是一名工程学院的院长,正在考虑是否允许学生在课程作业中使用AI辅助文献检索,数据给你的答案应该是明确的"不"——至少在工程领域,学生有超过一半的概率被AI引向虚构的文献。而如果你在人文学科,风险相对较小,但绝非为零。
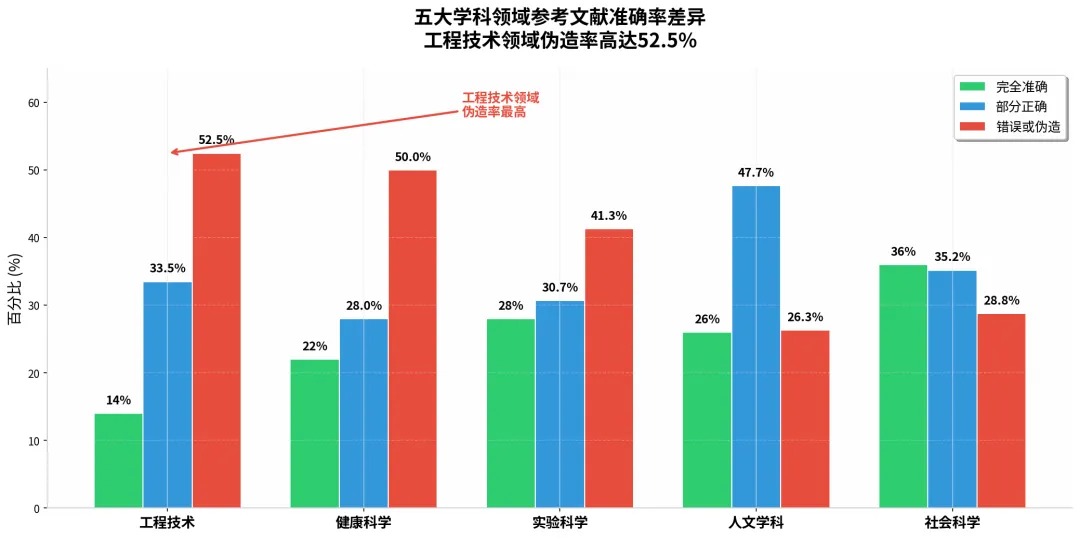 图3:五大学科领域参考文献准确率差异。工程技术领域伪造率高达52.5%,人文学科相对较低(26.3%)。差异主要源于文献类型分布不同。
图3:五大学科领域参考文献准确率差异。工程技术领域伪造率高达52.5%,人文学科相对较低(26.3%)。差异主要源于文献类型分布不同。
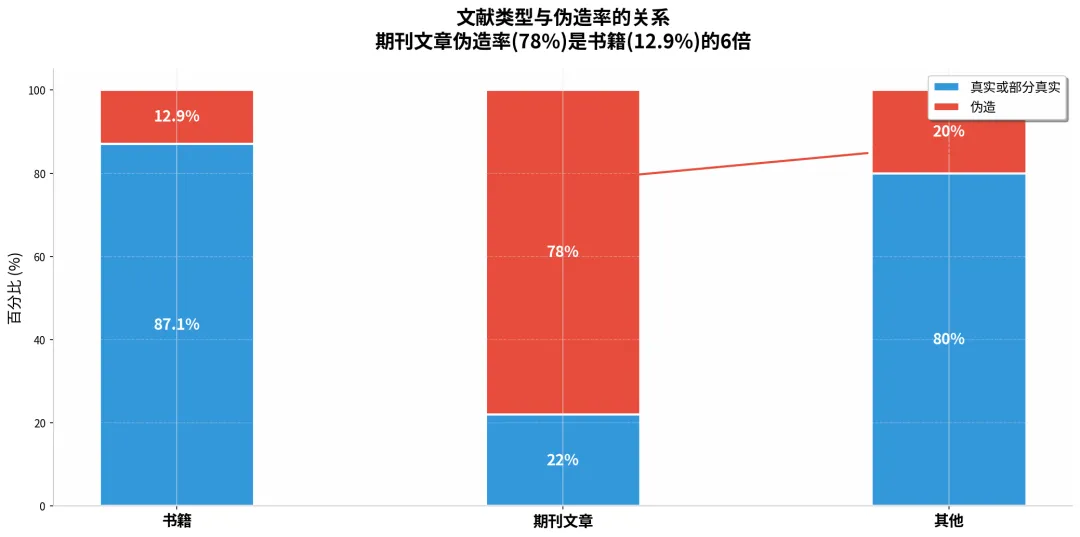 图4:文献类型与伪造率的关系。期刊文章伪造率(78%)是书籍(12.9%)的6倍。AI对需要精确元数据的期刊文章几乎无能为力。
图4:文献类型与伪造率的关系。期刊文章伪造率(78%)是书籍(12.9%)的6倍。AI对需要精确元数据的期刊文章几乎无能为力。
4参考文献的"年龄歧视"
除了准确率和文献类型,这项研究还揭示了一个被长期忽视的问题:AI存在严重的"年龄偏见"——它要么过度偏好陈旧文献,要么盲目追逐最新发表,却极少给出真正适合学术写作的"适龄"文献。
在400条引用中,参考文献的平均"年龄"(从发表到被引用的间隔)为14.7年。但这个平均数掩盖了巨大的个体差异。法国Mistral AI的Le Chat表现最为极端:它引用的文献平均年龄在45.3年,甚至包括18世纪和19世纪的著作。Gemini(25.9年)和Grok(21.4年)也倾向于推荐较老的文献。相比之下,Perplexity(2.3年)和Claude(3.2年)则极度偏好最新文献——Claude提供的引用几乎全部集中在2019至2023年间。
这两种倾向都有问题。过度陈旧的文献在实验科学和工程技术领域往往已经过时,研究方法和结论可能已被后续工作推翻。而过度追求"新"文献同样危险:研究发现,Perplexity提供的2025年文献中,72%是伪造的。AI似乎知道"最新"是一个卖点,于是它大胆地编造了大量"刚刚发表"的论文——反正这些论文如此新,很少有人会去核实。
更深层的问题是知识的"马太效应"。研究发现,AI反复引用的都是那些被引用数千次的"超级经典"——比如March的《Advanced Organic Chemistry》(被5个AI选中,引用数16634次)、Gombrich的《The Story of Art》(引用数3057次)、Bourdieu的《Distinction》(引用数88609次)。这些确实是好书,但当所有AI都向学生推荐同一批"安全"的经典时,学术思想的多样性正在被悄然扼杀。知识的发现本应是一场探险,而AI把它变成了一场重复的朝圣。
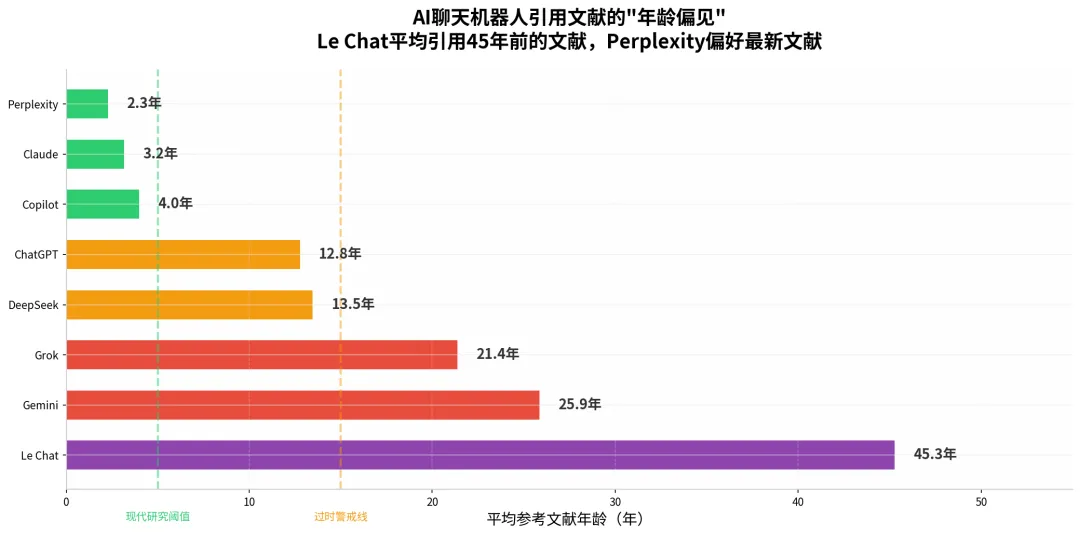 图5:AI聊天机器人引用文献的"年龄偏见"。Le Chat平均引用45年前的文献,Perplexity偏好最新文献。两者都不利于高质量的学术写作。
图5:AI聊天机器人引用文献的"年龄偏见"。Le Chat平均引用45年前的文献,Perplexity偏好最新文献。两者都不利于高质量的学术写作。
5知识的"近亲繁殖"
如果说伪造引用是AI的"显性犯罪",那么引用的高度重叠就是它的"隐性危害"。这项研究首次量化了不同AI之间在学术推荐上的"同构性",结果令人不安。
数据显示,ChatGPT、DeepSeek、Grok和Gemini四款AI之间存在显著的引用重叠。45%的DeepSeek引用和45%的Grok引用也同时被ChatGPT推荐;36%的DeepSeek引用与Gemini重合;32%的Grok引用与DeepSeek重合。考虑到Google Scholar在2019年就已索引约3.89亿条学术引用,这种高度趋同绝非偶然。
这意味着什么?意味着不同AI的"学术品味"正在收敛。它们不是在为你探索知识的边疆,而是在一个有限的、高度重复的知识池子里打转。这种"近亲繁殖"效应可能导致学术创新的窒息——如果一代学生都在使用AI生成文献综述,而所有AI都推荐同一批经典著作,那么边缘化的研究、新兴的理论、少数派的声音将越来越难以进入学术对话。
更值得警惕的是,这些被高频推荐的"经典"大多来自Wiley、Oxford University Press、McGraw-Hill等西方主流出版巨头。研究还发现,AI对Wikipedia存在过度依赖——多个AI生成的真实引用最终溯源到Wikipedia页面。在一个理想的世界里,学术引用应该是知识多样性的保障;而在AI的中介下,它正在变成主流话语的复读机。
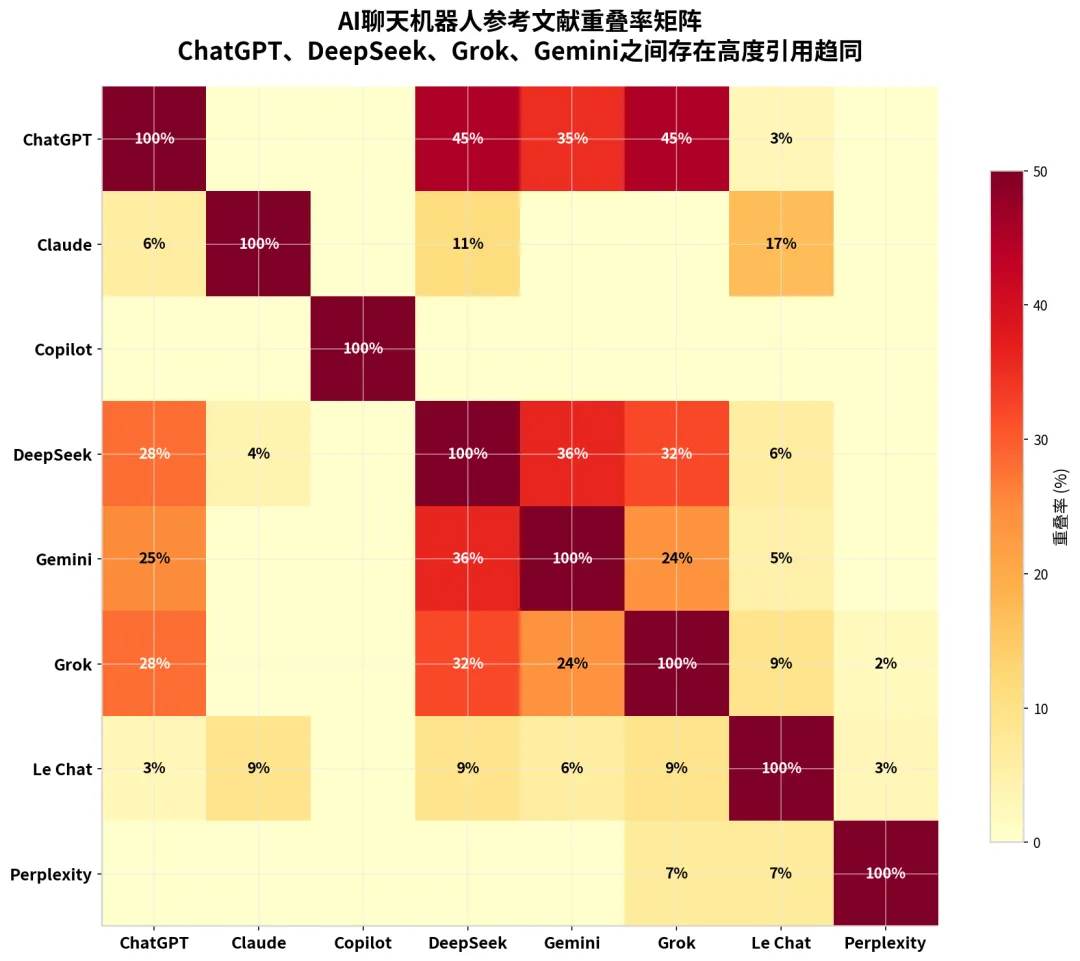 图6:AI聊天机器人参考文献重叠率矩阵。ChatGPT、DeepSeek、Grok、Gemini之间存在高度引用趋同,暗示它们共享相似的训练数据或推理模式。
图6:AI聊天机器人参考文献重叠率矩阵。ChatGPT、DeepSeek、Grok、Gemini之间存在高度引用趋同,暗示它们共享相似的训练数据或推理模式。
6从学生作业到顶级会议:幻觉的蔓延
Cabezas-Clavijo和Sidorenko-Bautista的研究聚焦于一个看似温和的场景:大学生用AI辅助完成期末论文。但2025年至2026年间发生的一系列事件表明,幻觉引用已经从学生作业蔓延到了学术出版的核心地带。
2025年,GPTZero扫描了NeurIPS(神经信息处理系统大会)的4841篇接收论文,发现51篇包含100多条AI生成的虚假引用。这些论文通过了同行评审,被顶级会议接收,有些甚至获得了口头报告的机会。NeurIPS的规定明确写道:哪怕一条伪造引用,也足以构成拒稿理由。然而现实是,这些"幽灵引用"不仅混入了会议论文集,还击败了数百篇 legitimate 的研究。
同年,Springer Nature被迫撤回了一本名为《Mastering Machine Learning: From Basics to Advanced》的教科书。独立核查发现,46条参考文献中有25条无法验证——其中三分之二是完全虚构的。被列名的几位研究者确认,他们从未撰写过被 attributed 给自己的论文。这些经典的AI幻觉标记(虚构作者、可信的期刊名、合理的标题)逃过了作者、编辑、同行评审和出版商的多重检查。
2026年5月,一颗更大的"深水炸弹"被投下。由赵振越、王艺赫、Toby Stuart等学者组成的跨国研究团队,对arXiv、bioRxiv、SSRN和PubMed Central四大数据库中的250万篇论文、1.11亿条参考文献进行了地毯式审计。他们首次在大尺度上证实了LLM幻觉对现实知识生产的入侵:仅在2025年,保守估计就有146,932条引用是AI凭空捏造的。这些错误并非集中在劣质刊物,而是弥散在各类学术产出中,在AI采纳率高的领域和早期职业生涯的作者群体中尤为猖獗。
更令人不安的是,这些幻觉引用并非随机分布。研究发现,它们不成比例地将功劳分配给了已经享有盛誉的男性学者——AI不仅在编造事实,还在潜移默化中强化着学术界原有的不平等结构。强者愈强,弱者愈弱,而AI正在成为这种不平等的放大器。
若任由"幻觉引文"渗入学术体系,不仅会催生错误结论、干扰后续研究,甚至可能误导科研方向。长此以往,将会悄然侵蚀公众对科学的信任。
——《自然》杂志, 2026年4月
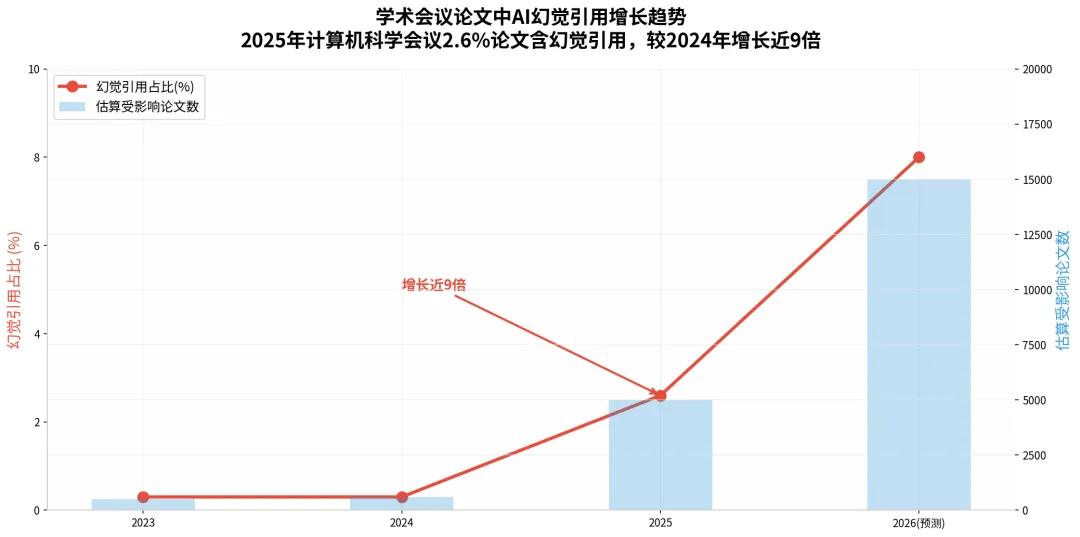 图7:学术会议论文中AI幻觉引用增长趋势。2025年计算机科学会议2.6%论文含幻觉引用,较2024年的0.3%增长近9倍。数据来源:GPTZero & Nature, 2026
图7:学术会议论文中AI幻觉引用增长趋势。2025年计算机科学会议2.6%论文含幻觉引用,较2024年的0.3%增长近9倍。数据来源:GPTZero & Nature, 2026
7出版商的困境:Wiley的4400万美元赌注
面对AI对学术文献的系统性侵蚀,出版商们的反应揭示了一个复杂的利益格局。一方面,它们担心AI的幻觉损害学术声誉;另一方面,它们也在积极寻求与AI公司的合作,试图将危机转化为商机。
2024年,学术出版巨头Wiley与AI公司达成了一项价值4400万美元的内容授权协议,允许AI公司在训练中使用其出版物。作为交换条件,Wiley要求AI公司在生成引用时优先推荐其旗下期刊的内容,并引导用户流量回流至Wiley平台。这种"付费优先"模式引发激烈争议:它可能改善AI引用的准确性,但也可能让学术推荐进一步被商业利益绑架。
更深层的问题是版权。研究推测,某些AI之所以能提供更多书籍引用(而非期刊文章),可能是因为它们的训练数据包含了大量来自盗版网站或版权灰色地带的全文书籍。这些AI可能从未真正"阅读"过期刊论文的完整内容,而只是从各种摘要、索引和二手引用中拼凑信息。当Wiley、Elsevier等出版商与AI公司签订正式授权协议时,它们实际上是在承认一个尴尬的事实:AI之前的"学习"很可能是不合法的。
对于小型学术出版社和非营利出版机构来说,这场博弈更加残酷。它们没有资源与AI巨头谈判,也没有技术能力监控自己的内容被如何使用。在AI驱动的学术发现时代,它们的著作可能越来越难以被"记起"——因为AI的推荐算法天然偏向那些拥有最多训练数据的大出版商。知识的民主化,正在变成知识的寡头化。
8信息素养的"最后防线"
在这场AI幻觉的围攻中,大学和信息素养教育者被推向了前线。但问题是:防线是否足够坚固?
研究数据给出了悲观的答案。西班牙一项针对800名大学生的调查发现,89%的学生使用AI应用完成学术任务,其中81%使用聊天机器人。瑞典的研究显示,95%的学生知道ChatGPT,超过三分之一定期使用。沙特阿拉伯的数据是78.7%。这些学生中的大多数并不具备识别AI幻觉的能力——他们信任AI,不是因为AI可靠,而是因为AI的产出"看起来"可靠。
识别AI伪造引用并非不可能,但需要刻意的训练。研究者总结了几条关键线索:第一,警惕过于常见的姓氏组合(Smith、Lee、Brown、Wang、García)——AI倾向于使用这些"安全"的名字来填充作者栏;第二,警惕过于宽泛的期刊标题和文章标题——真实的学术论文标题通常更具体、更技术性;第三,警惕完美的格式——AI生成的引用往往在格式上过于完美,而真实的引用常因转录和排版出现微小偏差;第四,也是最重要的一点:永远用引号将标题放入Google Scholar进行精确检索。如果一条引用真实存在,精确标题检索几乎总能找到它。
但这些技巧对于一名在截止日期前夜赶作业的大一学生来说,要求太高了。学术诚信教育的根本困境在于:它要求学生在最缺乏时间、最需要效率的时刻,投入额外的时间进行验证。当AI承诺"一键生成参考文献"时,这种承诺本身就是对学术严谨性的系统性腐蚀。
研究者建议,大学应当将AI引用验证纳入信息素养课程的核心模块。这不是要禁止AI——那既不可能也不明智——而是要培养学生"与AI共舞"的能力:利用AI快速获取相关概念和初步文献线索,但绝不将AI的输出视为终点。正如Giray(2024)所强调的,验证引用可以简单到只需要在搜索引擎中用引号包围标题进行检索,但这个步骤被绝大多数学生忽略了。
学术写作的本质不是信息的搬运,而是思想的对话。当你引用一篇论文时,你不仅是在借用它的结论,更是在邀请它的作者进入你的思想空间,与之辩论、协商、达成共识。而当你引用一篇AI虚构的论文时,你邀请的是一个幽灵——一个从未存在过的声音,一个由概率模型拼凑出来的学术皮影。
这种引用的空洞性,比抄袭更隐蔽,比剽窃更危险。因为它不仅欺骗了读者,还欺骗了作者自己——让你误以为自己的论证建立在坚实的学术地基之上,而实际上你站在一片虚空之中。
9"AI鸿沟"与知识不平等
这场危机还有一个被忽视的维度:不平等。研究明确使用了免费版本的AI进行测试,因为"这反映了最典型的用户场景"。但免费版本与付费版本之间存在显著的能力差距,而这种差距正在制造一条新的"AI鸿沟"。
能够负担ChatGPT Plus、Claude Pro或Perplexity Pro的学生,可以获得更强大的模型、更准确的引用和更少的幻觉。而依赖免费版本的学生——他们往往来自低收入地区或发展中国家——不得不面对更高的错误率和更多的伪造引用。这种不平等不是假设,而是已经被数据证实:付费版本的GPT-4在引用准确性上显著优于免费的GPT-4o-mini,而大多数学生使用的正是免费版本。
在学术出版领域,这种不平等同样存在。大型出版商有能力与AI公司谈判授权协议,确保自己的内容被准确引用;小型出版社和非英语期刊则被边缘化。在AI的训练数据中,英语内容占据主导地位,非英语学术成果被系统性低估。当AI成为学术发现的主要入口时,那些原本就处于知识边缘的群体——非英语国家的研究者、女性学者、少数族裔研究者——将面临更加严峻的被隐形化风险。
2026年的研究已经证实,AI幻觉引用不成比例地将功劳归于已经享有盛誉的男性学者。这不是算法的恶意,而是训练数据中既有偏见的反射。AI不会创造不平等,但它会放大不平等——以技术中立的面目,以效率提升的名义。
结语:我们还能相信什么?
400条参考文献的审计,51篇NeurIPS论文的丑闻,146,932条幻觉引用的宏观估算——这些数字拼凑出一幅令人不安的图景:人类最引以为傲的知识生产体系,正在被它自己创造的工具从内部侵蚀。
但这场危机也迫使我们追问一个更根本的问题:在AI时代,"引用"究竟是什么?在传统学术中,引用是一种信任行为——我相信你做过这项研究,我相信你的数据可靠,我相信你的论证值得被继承。而在AI中介的世界里,引用正在变成一种概率行为——AI"认为"这篇论文可能存在,"认为"这个作者可能写过这本书,"认为"这个DOI可能是正确的。
概率不等于信任。当引用从信任行为退化为概率猜测时,学术共同体的根基就开始动摇。我们引用不是为了装饰参考文献列表,而是为了将自己置于一个真实的对话网络之中。每一条引用都是一条线索,指向一个可以被验证、被质疑、被延续的思想源头。而当这些线索被AI批量伪造时,整个知识图谱就变成了一个布满虚假路标的迷宫。
Grok和DeepSeek的表现给了我们一丝希望:AI确实可以做得更好,幻觉不是生成式模型的宿命。但希望不能替代警惕。在AI公司解决这些问题之前——如果它们真的会去解决——验证的责任落在每一个使用AI的人肩上。
最终,这场危机教会我们的也许不是如何更好地使用AI,而是如何重新理解知识的本质。知识不是可以被压缩、生成和批量复制的数据包;它是人类在漫长的时间中,通过争论、失败、修正和共识建立起来的脆弱网络。保护这个网络,需要我们放慢速度,手动检查每一条引用,质疑每一个看似完美的答案,在效率与严谨之间选择后者。
因为当机器开始伪造知识的家谱时,唯一能阻止它的是人类对真实的执着——那种笨拙的、低效的、却不可替代的执着。
数据来源与参考文献:
1. Cabezas-Clavijo, Á., & Sidorenko-Bautista, P. (2026). Assessing the Performance of 8 AI Chatbots in Bibliographic Reference Retrieval: Grok and DeepSeek Outperform ChatGPT, but None are Entirely Accurate. Journal of Data & Information Science. https://doi.org/10.1515/jdis-2025-0326.
2. GPTZero (2026). Compound Deception in Elite Peer Review: A Failure Mode Taxonomy of 100 Fabricated Citations at NeurIPS 2025. arXiv:2602.05930.
3. 赵振越等 (2026). LLM幻觉引用大规模审计研究. arXiv:2605.07723.
4. 《自然》杂志 (2026年4月11日). "幻觉引文"悄然侵蚀公众对科学的信任.
5. Enago Academy (2026). AI-Generated References: 1 in 5 Are Fake.
6. Walters, W. H., & Wilder, E. I. (2023). Fabrication and errors in the bibliographic citations generated by ChatGPT. Scientific Reports, 13, 14045.
7. Giray, L. (2024). ChatGPT References Unveiled: Distinguishing the Reliable from the Fake. Internet Reference Services Quarterly, 28(1), 9-18.
8. Spennemann, D. H. R. (2025). The Origins and Veracity of References 'Cited' by Generative Artificial Intelligence Applications. Publications, 13(1), 12.
9. Battersby, M. (2024). Wiley Set to Earn $44M from AI Rights Deals. The Bookseller.
10. 本文图表均由作者基于原始研究数据独立绘制。
