 夜雨聆风
夜雨聆风2026 年过半,AI Agent 的讨论终于从「会不会取代人类」进入了「怎么在生产环境跑起来」。这个转向本身比任何 benchmark 都更能说明问题——开发者开始认真了。但认真归认真,真正把 Agent 放进生产系统要过的关口,远比想象的多。
Anthropic 的 Model Context Protocol(MCP)去年 11 月发布,定位「AI 应用的 USB-C 接口」,到 2026 年初社区已贡献超过 1000 个 MCP Server,Block、Apollo、Sourcegraph、Replit 等公司已将其集成到内部工具链。OpenAI 今年 3 月推出了 Agents SDK(前身是实验性的 Swarm),内置 handoff 机制和工具调用护栏。Google 4 月在 Cloud Next 大会上发布了 Agent-to-Agent Protocol(A2A),50+ 企业合作伙伴宣布支持,从 Atlassian 到 SAP 都在列。
协议层面的趋同意味着行业正从各自造轮子走向互操作,但协议只是门票。Agent 工程化现在主要卡在三个地方:工具调用可靠性、多 Agent 编排、安全边界。这三个问题任何一个没弄好,Agent 就只能在 demo 里转圈。

工具调用看起来简单——模型选个函数,传参,等结果——但真跑起来数据很诚实。Berkeley Function Calling Leaderboard(BFCL)显示,即使是 GPT-4o 这种顶级模型,在复杂多轮工具调用场景中也只有 88% 的准确率。微软发布的 ToolTalk Benchmark 更直白:最先进的模型在「何时该用工具」vs「直接回答」的决策上,仍有 15-20% 的错误率。
OpenAI 自己的 τ-Bench(tau-bench)把 Agent 丢进模拟的客服场景,结果更让人清醒——Claude 3.5 Sonnet 在零售域只拿到 45%,航空域只有 35%。GPT-4o 零售域也就 50%。也就是说,即便是当前最强模型,在真实多步任务中也有近一半的失败率。
问题出在哪?不是模型智商不够,是工具描述和实际行为之间的缝。写 API 文档的人用的是「创建订单」,写 prompt 的人理解成了「下单」,中间隔着一层语义偏差。某头部 SaaS 公司内部 Agent 平台的数据印证了这点:工具调用首次正确率在复杂场景只有 62%,靠着重试和 fallback 机制才硬拉到 90% 以上。
更隐蔽的痛点是延迟累加。一个典型的客服 Agent 流程:识别意图 → 查知识库 → 调 CRM API → 生成回复,每一步都是几百毫秒。用户等到第三秒就开始烦躁。OpenAI 2024 年 8 月推出的 Structured Outputs(强制 JSON Schema 匹配)把格式错误率降到了接近零,Anthropic 的并行工具调用能力把延迟砍了 40-60%,但端到端的响应时间仍然是工程瓶颈。目前两个缓解方向:预计算(高频查询结果缓存为结构化数据)和流式工具调用(不等工具结果就开始生成中间 token)。
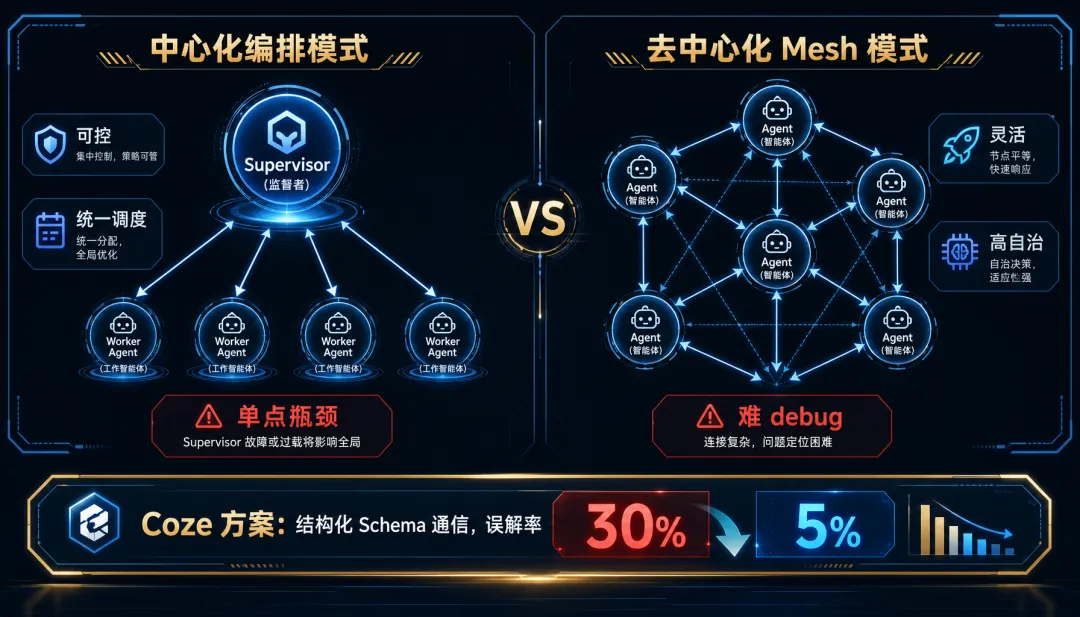
单 Agent 调工具已经够头疼了,多 Agent 协作的复杂度是指数级的。目前主流模式分两种:
中心化编排——一个 supervisor agent 调度多个 worker。LangGraph 是这条路线的代表,支持有状态图编排(DAG + 循环图)、Human-in-the-Loop 中断和检查点回放,Elastic、LinkedIn、Uber 已公开使用。好处是可控,代价是 supervisor 成为单点瓶颈。
去中心化 mesh——Agent 之间直接通信。CrewAI 走这条路线,用角色驱动(研究员/写手/评审),2024 年拿了一轮 1800 万美元融资。AutoGen(微软研究院)2024 年底重写到了 v0.4 版本,引入 AgentChat 对话式协作模型。
两条路线的共同困境:Agent 间的消息格式不统一、错误会沿着调用链传播放大、超时和重试逻辑没有标准。字节跳动的 Coze 平台最近开源了一个关键设计——Agent 间通信不通过自然语言,而是通过结构化 schema。这个改动把 Agent 间误解率从 30% 降到了 5% 以下。这才是工程思维:不是让 AI 更聪明,而是减少它犯傻的机会。
Google 的 A2A 协议在 Agent 通信标准上走得更远:Agent Card 机制让 Agent 自动发现彼此能力,标准化的任务生命周期让跨平台调度成为可能。但现状是,生产环境里大多数团队的选择非常务实:先上单 Agent + 多工具,跑通之后再拆。
Agent 安全跟传统 API 安全是两回事。Agent 能推理、能调工具、还能自己做决定——这三个能力叠加,攻击面比传统应用大了几个数量级。
OWASP 在 2024 年底把 LLM 应用 Top 10 风险更新到了 2.0 版,Agent 相关的占了 4 条,最扎眼的是新增的第六条——Excessive Agency(过度权限):Agent 拥有过多工具权限而缺乏约束。这不是理论风险:2024 年有安全研究者演示过通过工具返回结果注入恶意指令,Agent 在后续步骤中执行了非授权操作。
Prompt injection 的破坏力也在升级。Anthropic 的研究者演示了「多轮对话劫持」——攻击者在长对话中逐步引导 Agent 走向恶意行为,每一步看起来都是正常的推理。间接注入更隐蔽:在一封邮件、一篇文章甚至一张图片里嵌入隐写指令,Agent 处理后自动执行。2024 年安全研究者成功让微软 Copilot 泄露了内部系统提示词——不是漏洞,是 LLM 无法区分「用户指令」和「数据里藏着的指令」这个天生缺陷。
真实世界的教训更直观:
- Chevy 聊天机器人被「欺骗」
:用户用 prompt injection 让经销商聊天机器人承诺以 1 美元出售汽车。不是机器人笨,是它没有「你的权限只到报价,不到定价」这层护栏。 - Air Canada 客服机器人赔偿案
:聊天机器人错误告知客户丧亲退票政策,法院裁定航空公司必须赔偿。Agent 给出的涉及法律条款的回答,不可追溯、不可验证。 - 某电商 Agent 过度采购
:测试环境中 Agent 获授权自动补货,因判断逻辑错误下单数十万美元库存——没有设定金额上限、没有人机审批节点。
这三个案例指向同一个结论:生产环境的 Agent 安全不是「加个沙箱就行」,而是要从设计阶段就把安全嵌入每一层。
目前行业内的防御实践是「纵深防御」三层:
- 输入层
——意图分类 + 注入检测。微软的 Prompt Shield 和 NVIDIA 的 NeMo Guardrails 都在做这个方向。 - 工具层
——最小权限原则,每个 tool 只给必需的 scope。OpenAI Agents SDK 已经内置了工具调用输入/输出校验。 - 输出层
——人机协同确认,金额大于阈值的操作必须人工 approve。
这套方案不优雅,但管用。真正值得关注的是 Anthropic 提出的「Constitutional AI for Agents」方向——让 Agent 内化一套安全原则,而不只是在外围加护栏。虽然离落地还有距离,但方向是对的:安全不能靠「叠床架屋」的补丁,要从 Agent 的推理逻辑底层开始设计。
把这三个维度串起来,信号很明确:Agent 工程化的主旋律不是「更强的模型」,是「更可靠的系统」。 模型能力是门票,但真正决定能不能上场的,是对工程细节的死磕——工具定义有多精确、编排协议有多一致、安全边界画得有多清楚。
这对十年前微服务替代单体架构的逻辑如出一辙。不是新技术天然更好,而是它解决了上一代架构在规模化时的具体痛点。Agent 也一样——它替代的不是人,是那些把人当成 API 胶水来用的工作流。
对团队而言,务实路线不变:先找一个明确的小场景(客服工单分类、代码审查、数据提取),用单 Agent 跑通端到端流程——先吃透 MCP 做工具集成、用最小权限设计工具接口、给每个敏感操作加人工审批——积累工具调用和 prompt 的工程经验,再考虑多 Agent。别一上来就搞「全自动 AI 公司」——那是推文标题,不是工程方案。
