 夜雨聆风
夜雨聆风开源神器MinerU:PDF一键秒变docx,Markdown,数据处理必备
• 你是不是也曾对着一个排版精美的PDF叹气? • 想把里面的表格、公式、图文无损地提取出来,结果复制粘贴后格式全乱,OCR识别更是错漏百出,尤其是面对学术论文里的复杂公式,简直是一场灾难。 • 别急,今天给大家介绍一位“数据清洁工”——MinerU。它不仅能一键将PDF、网页转化为干净的Markdown,docx或JSON格式,而且完全开源、免费。
MinerU是什么?
• 简单说,MinerU是一款高质量的数据提取工具,专为大语言模型(LLM)的预训练、微调和RAG(检索增强生成)而生。 • 它由OpenDataLab开发并开源,在GitHub上已狂揽超过2万颗星,是开发者圈子里公认的“提数神器”。 • 它的核心使命就一个:将非结构化数据(比如PDF、网页),转化为结构化、干净的高质量语料,让你的AI模型“吃”得更健康,“消化”得更好。
为什么它这么牛?四大核心亮点
• 市面上PDF转文本工具千千万,MinerU凭什么脱颖而出?
1. 真正的“格式还原大师”
• 它不只是提取文字,而是真正“读懂”了文档的布局。 • 删繁就简:自动剔除页眉、页脚、页码、脚注等“干扰项”,让文本更纯粹。 • 元素保留:无论是多级标题、段落、列表,还是复杂的表格,都能精准识别并保留其原有结构。 • 格式转换:输出为标准的Markdown格式,不仅人能读得舒服,机器也能轻松解析。
2. 复杂公式识别,一击即中
• 学术党、科研狗的福音!MinerU对数学公式、化学结构式的识别能力,堪称一绝。 • 它能够精准识别行内公式和行间公式,并将其无损转化为LaTeX格式。你再也不用对着截图敲半天“ 𝐸 = 𝑚𝑐2”了,它直接帮你搞定。
3. 表格提取,智能“断行”
• 遇到跨页的大表格怎么办?MinerU很聪明,它能自动识别并合并跨页表格。同时,对于那些单元格内需要换行的复杂内容,它也能准确判断,不会把一个单元格拆得七零八落。
4. 全链路处理,一站式解决
• 从PDF文档解析,到内容提取,再到格式转换和质量清洗,MinerU提供了一条完整的流水线。它甚至对乱码也做了专门优化,大大提升了最终数据的可用性。
它到底能干什么?应用场景
• 大模型训练数据准备:快速将海量的内部PDF文档、电子书、网页,转化为高质量的训练或微调语料。 • 知识库与RAG应用:构建企业级知识库时,用它来做文档解析的“前哨站”,能让AI回答得更精准,同时完整保留引文来源。 • 学术研究:写综述、做调研时,批量提取论文中的关键信息、数据和公式,效率倍增。 • 个人知识管理:将收藏的优质长文、报告转存为结构化的Markdown笔记,构建你的第二大脑。
如何快速上手?
• 是不是很心动?上手也超级简单。 • 在线体验:想先试试效果?没问题。直接访问MinerU的在线页面,上传文件,几秒钟就能看到转换结果,所见即所得。
https://mineru.net/client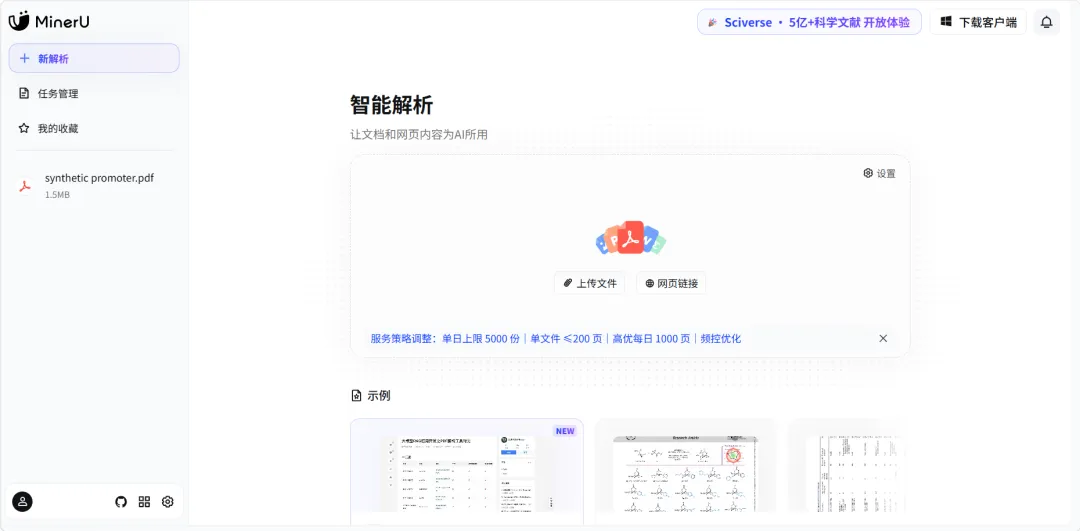
• 上传文件后点击右上角下载即可得到你想要的格式 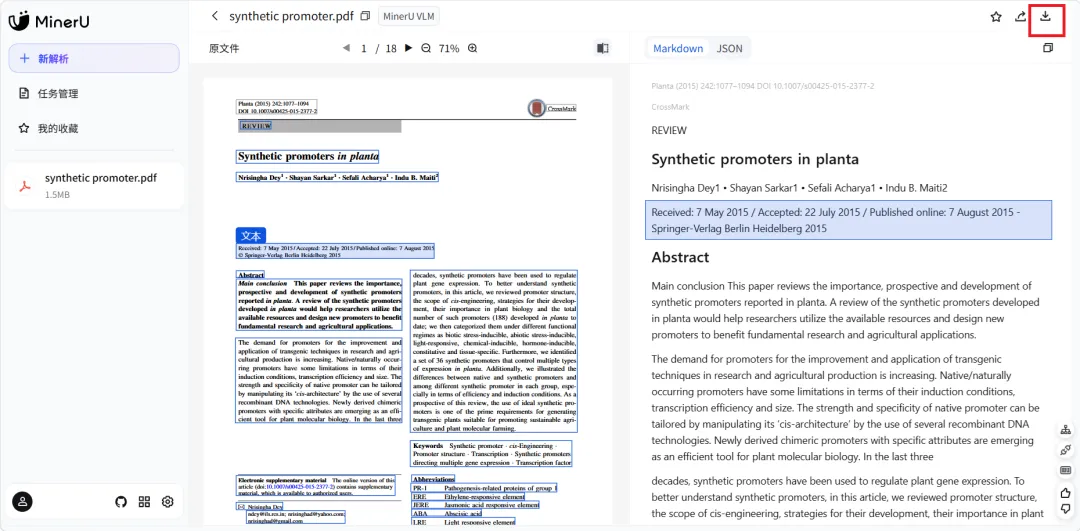
• 本地部署:对于注重数据隐私、需要批量处理的用户,可以把它部署到自己的服务器上。官方提供了详细的文档,一行命令就能安装,对开发者极其友好。 • Claude code使用: 在CLI安装MinerU skill即可
# 安装 Skill(无需 API Key,免费使用 flash-extract 模式)npx skills add tanis90/pdf-converter-mineru• 在AI狂飙突进的时代,高质量的数据越来越成为稀缺资源。MinerU就像一把精密的数据手术刀,帮你把杂乱的“信息矿石”精炼成“数据黄金”。 • 这么好用的工具,还是开源免费的,确定不试试吗?
