 夜雨聆风
夜雨聆风

01
前言
如果说传统 OCR 解决的是“把字识别出来”,那么现在的文档解析模型,已经开始解决更复杂的问题:表格怎么还原?公式怎么识别?图表怎么理解?印章怎么定位?扫描件歪了、拍糊了、光照不均,还能不能稳?
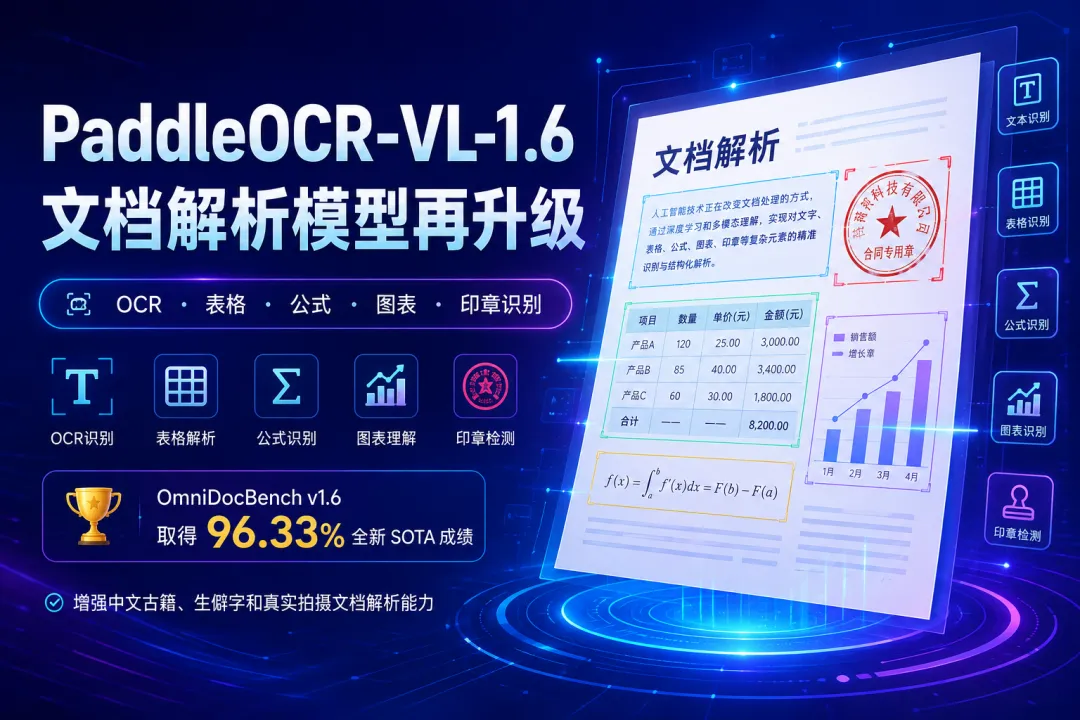
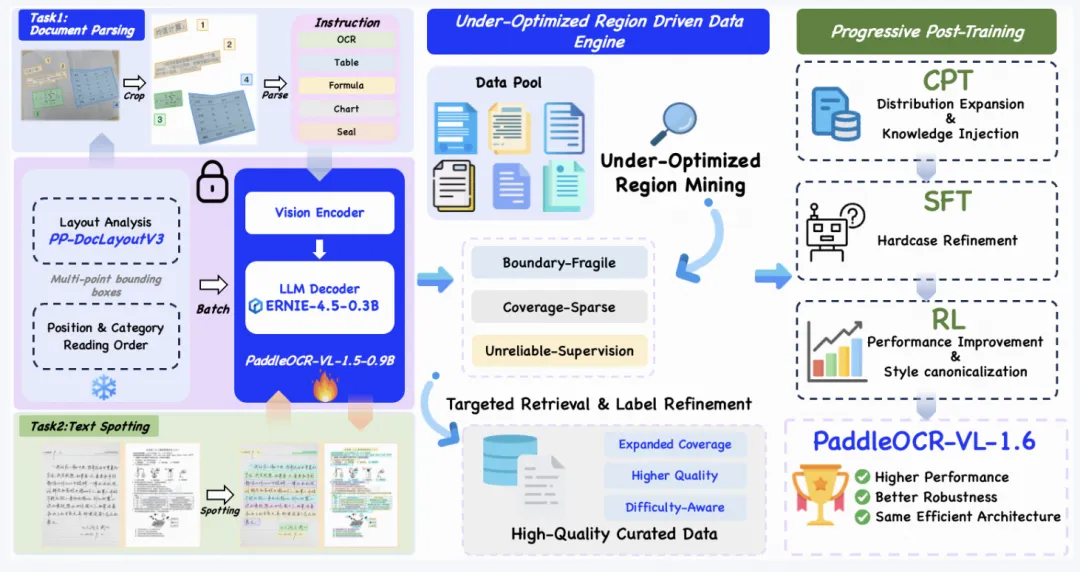
最近,飞桨 PaddlePaddle 发布了 PaddleOCR-VL-1.6,这是一款面向文档解析场景的轻量级视觉多模态模型。相比上一代 PaddleOCR-VL-1.5,新版本重点升级了数据优化和后训练策略,在复杂版面、中文文档、表格、公式、图章等任务上进一步增强。
更关键的是,它并不是一个“只能看简单文字截图”的 OCR 工具,而是更接近一个面向真实文档场景的视觉语言模型。
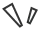
02
PaddleOCR-VL-1.6 到底升级了什么?
PaddleOCR-VL-1.6 的核心升级可以概括为两点:
1️⃣ 区域感知的数据优化框架。简单理解,就是模型会识别上一版本表现不够稳定的区域,然后对这些薄弱环节进行针对性增强。比如复杂表格、低质量扫描件、特殊中文字符、图章区域等,不再是“一锅炖式训练”,而是哪里薄弱补哪里。
2️⃣ 渐进式后训练方案。新版本引入精选数据选择和强化学习,通过分阶段优化,让模型在文档解析任务上的表现更加稳定。
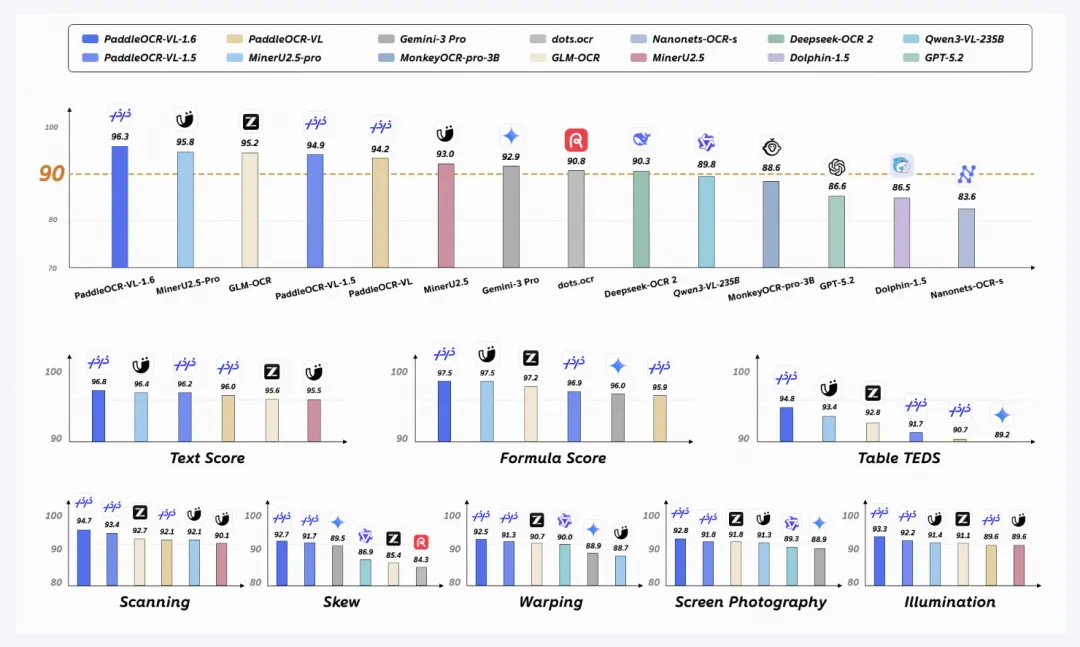
根据官方介绍,PaddleOCR-VL-1.6在OmniDocBench v1.6 上取得了96.33% 的成绩,并刷新了OmniDocBench v1.5和Real5-OmniDocBench的相关记录。对于文档解析模型来说,这个成绩说明它不只是“能用”,而是在复杂文档理解方向继续往前推了一步。
03
它能做什么?
很多人一听 OCR,就以为只是把图片里的文字提取出来。但 PaddleOCR-VL-1.6 的定位明显更大,它覆盖的是“文档解析”而不只是“文字识别”。它主要支持以下能力:
1️⃣ 文本识别与定位
普通文档、截图、扫描件、拍照文档中的文字区域识别,是它的基础能力。相比传统 OCR,它更适合处理复杂排版和多语言内容。
2️⃣ 表格识别
表格是文档解析里最让人头疼的部分。普通 OCR 经常能识别文字,却还原不了表格结构。PaddleOCR-VL-1.6 对表格识别进行了增强,适合财务报表、实验数据表、合同附件、统计报表等场景。
3️⃣ 公式识别
科研论文、教材、技术文档里经常有公式。传统 OCR 识别公式容易“断句式翻车”,而 PaddleOCR-VL-1.6 针对公式识别能力进行了优化,更适合论文解析和学术资料处理。
4️⃣ 图表识别
很多报告不只是文字,还有柱状图、折线图、饼图等可视化内容。PaddleOCR-VL-1.6 支持图表识别,能够帮助模型理解文档中的结构化视觉信息。
5️⃣ 印章/图章检测
对合同、证明材料、政务文件、票据类文档来说,印章区域非常关键。新版本在印章与图章检测方面也有增强,这对企业文档审核和自动归档很实用。
6️⃣ 中文古籍与生僻字识别
这是它比较有特色的地方。PaddleOCR-VL-1.6 对中文古籍文档和中文生僻字识别有明显提升,说明它不只是偏英文场景,也更适合中文复杂文档处理。
04
适用领域
1. 企业合同与档案管理
合同里有正文、表格、签章、日期、附件说明等内容。PaddleOCR-VL-1.6 可以用于合同解析、关键字段提取、印章检测、条款结构化,为合同审核系统、企业档案管理系统提供底层能力。
2. 财务票据与报表处理
发票、收据、财务报表、对账单,经常存在表格密集、格式不统一、扫描质量参差不齐的问题。这类场景非常适合用文档解析模型提升录入效率。
3. 科研论文与教材解析
论文中常见公式、表格、图表和多栏排版。PaddleOCR-VL-1.6 对公式和表格识别能力更友好,可用于论文知识库构建、文献结构化、教材内容提取等方向。
4. 政务与法律文档数字化
政务表单、证明材料、法律文书通常结构复杂,且包含签章、编号、日期、表格等信息。如果需要做自动归档、检索、分类、审核,它可以作为文档理解基础模型使用。
5. 古籍、历史文献与中文资料整理
中文古籍和生僻字识别是很多 OCR 工具的难点。PaddleOCR-VL-1.6 在这方面的增强,让它更适合文化资料数字化、地方志整理、历史文献解析等场景。
6. AI 知识库与 RAG 文档预处理
很多企业做知识库时,最大的问题不是大模型不会回答,而是文档内容没有被正确解析。PaddleOCR-VL-1.6 可以作为 RAG 前置解析工具,把 PDF、图片、扫描件中的内容转成 Markdown 或 JSON,方便后续切分、检索和问答。
05
硬件推荐
虽然 PaddleOCR-VL-1.6 属于轻量级文档解析模型,但“轻量”不等于随便一台电脑都能流畅跑,尤其是涉及批量 PDF、高清图片和复杂页面解析时,硬件配置会直接影响速度和稳定性。
1. 体验测试配置
适合个人学习、功能验证、小批量图片解析。推荐配置:
# CPU:8 核以上# 内存:16GB 起步# 显卡:NVIDIA 8GB 显存以上# 存储:至少预留 20GB 空间# 系统:Linux 优先,Windows 可尝试,macOS 建议使用 Docker
适合用途:单张图片 OCR、文档解析 Demo、API 调用测试、模型能力评估。
2. 中等业务配置
适合企业内部工具、少量并发、批量文档处理。推荐配置:
# CPU:12 核以上# 内存:32GB 起步# 显卡:NVIDIA RTX 3060 12GB、RTX 4060 Ti 16GB、RTX 4070 及以上# 存储:SSD 500GB 以上# 部署方式:Docker + PaddleOCR 官方方式
适合用途:合同批量解析、票据识别、表格识别、企业知识库文档预处理。
3. 高性能生产配置
适合高并发、批量 PDF、在线文档解析平台。推荐配置:
# CPU:16 核以上# 内存:64GB 或更高# 显卡:NVIDIA RTX 4090、L40S、A100、H100 等# 显存:24GB 起步,越高越适合复杂页面和并发任务# 推理方式:建议使用 vLLM 推理服务加速# 部署方式:Docker + GPU Server + API 服务化
适合用途:企业级文档解析平台、SaaS 文档识别服务、大规模知识库构建、自动化审核系统。
4. macOS 用户注意
官方说明中提到,macOS 用户建议使用 Docker 配置环境。如果是 Apple Silicon 芯片设备,可以用于轻量测试和接口开发,但如果要做高性能推理,仍然建议使用 NVIDIA GPU 服务器。
一句话总结:Mac 适合开发调试,NVIDIA GPU 更适合正式部署。
06
模型下载
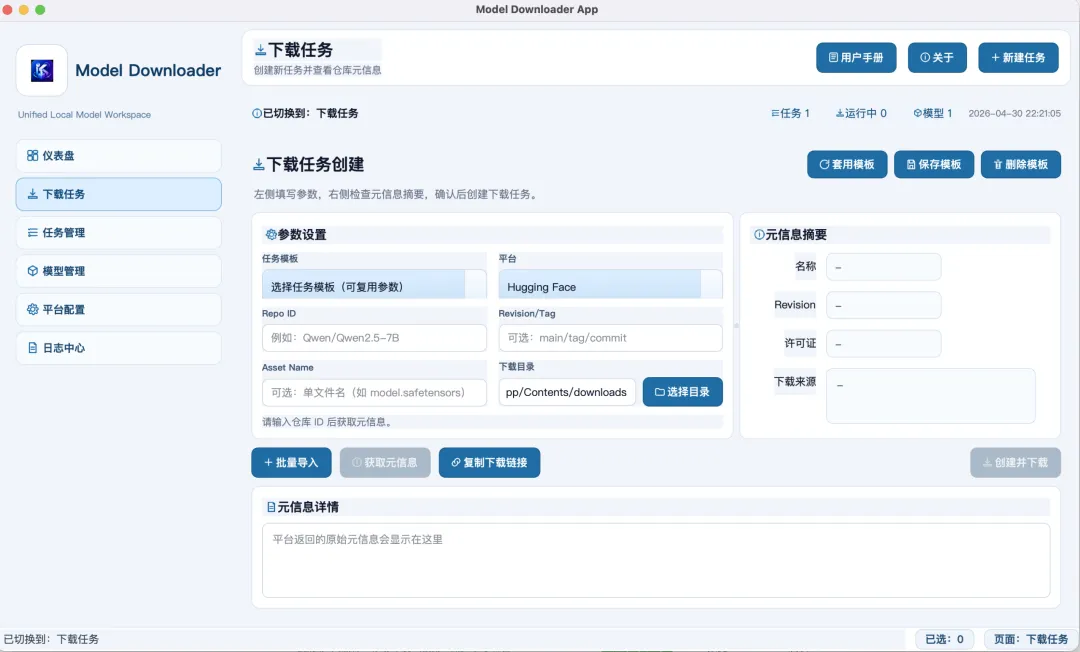
1️⃣ 打开model-downloader-app;
2️⃣ 创建下载任务;
3️⃣ 选择开源模型平台;
4️⃣ 输入repo id

文档解析正在从“识别文字”进入“理解文档”的阶段。如果你正在做合同审核、票据识别、企业知识库、论文解析或自动化办公系统,PaddleOCR-VL-1.6 很值得关注。本文将从模型亮点、适用场景、硬件推荐和部署方式几个方面,带你快速看懂这个新版本到底强在哪里。



往期推荐
ACE-Step 1.5:开源音乐生成模型,把“写歌、作曲、演唱”搬到本地电脑
Marlin-2B:一款面向视频结构化理解的轻量级开源模型
糊视频先别删:这套视频超分模型权重库,可以接入 ComfyUI 工作流使用
用数据预测音乐流行趋势:从歌曲热度到艺人增长
杭州二手房开源数据集:从房源表格里看懂城市居住样本


