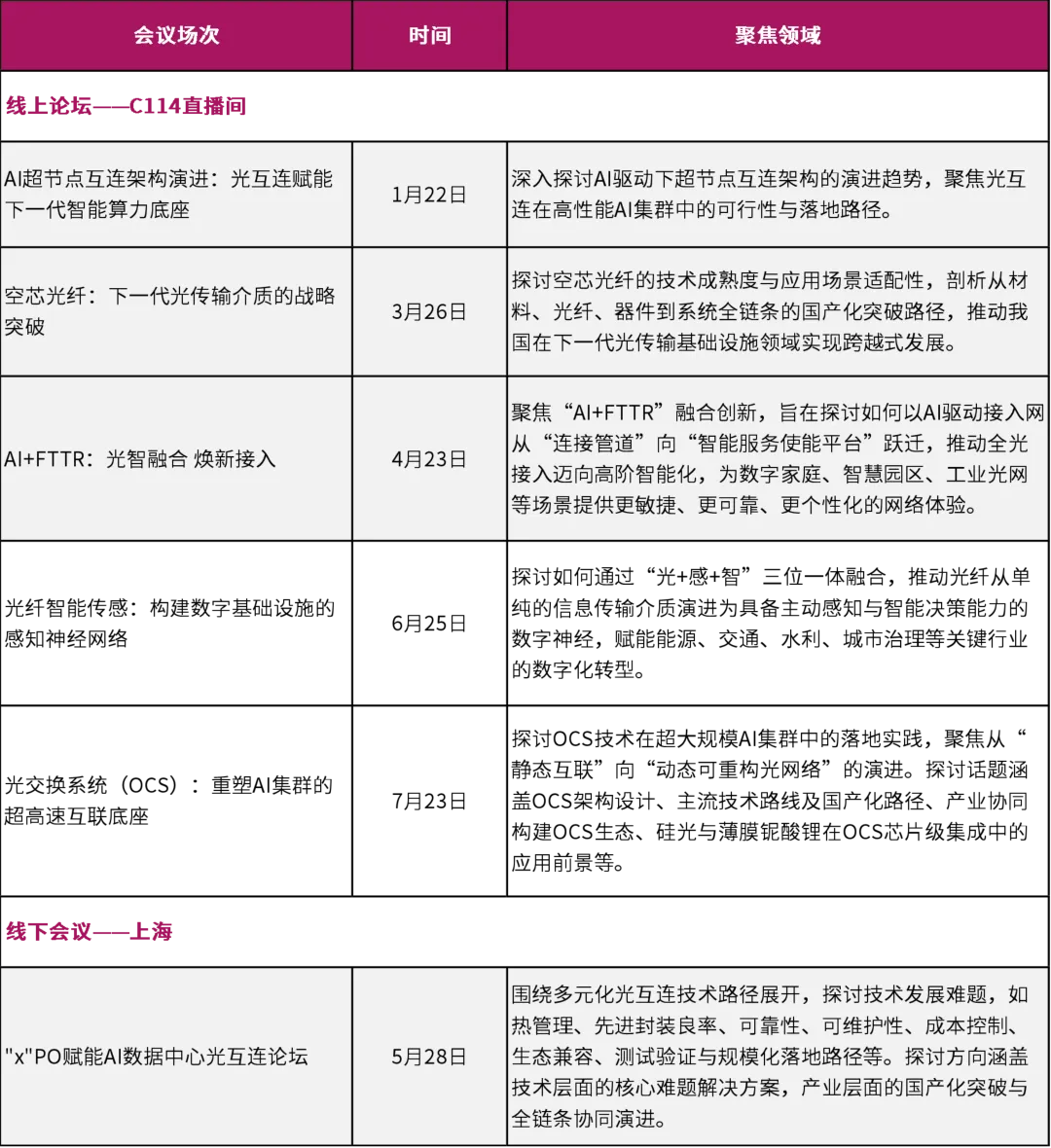
随着AI大模型参数规模突破万亿级,对芯片算力的需求呈指数级增长。数据显示,每两年模型参数增长约100倍,芯片算力提升3.3倍,而互连速度仅增长1.4倍——算力与互连能力严重不匹配,直接导致AI集群内部通信瓶颈,大量算力被浪费,实际有效算力远低于理论线性增长。因此,光互连的核心使命,就是打破这堵“算力墙”,释放芯片全部潜能。在AI时代,光互连的角色也发生了根本转变。从机架间配套设施转变为深入服务器内部、连接GPU与GPU、芯片与芯片的核心技术底座。当前业界正积极探索以CPO为核心,LPO、NPO、XPO并行发展的多元技术路径。杨睿援引LightCounting的预测指出,到2030年CPO将成为高速光互连市场的核心架构。台积电专为CPO打造的硅光+3D封装一体化平台COUPE已于2025年完成生产验证,并与英伟达、博通锁定合作。其中,英伟达Quantum-X交换机提供115.2T总带宽,博通Tomahawk 6交换芯片集成16个6.4T硅光引擎,容量达102.4T。2026年5月,台积电官宣COUPE on Substrate(基板级 CPO)进入量产,标志着CPO从概念走向商用,也意味着CPO的元年到来。但该平台仍面临光耦合损耗高、热管理压力大、3D堆叠良率低及制造成本高昂等挑战。
 夜雨聆风
夜雨聆风