 夜雨聆风
夜雨聆风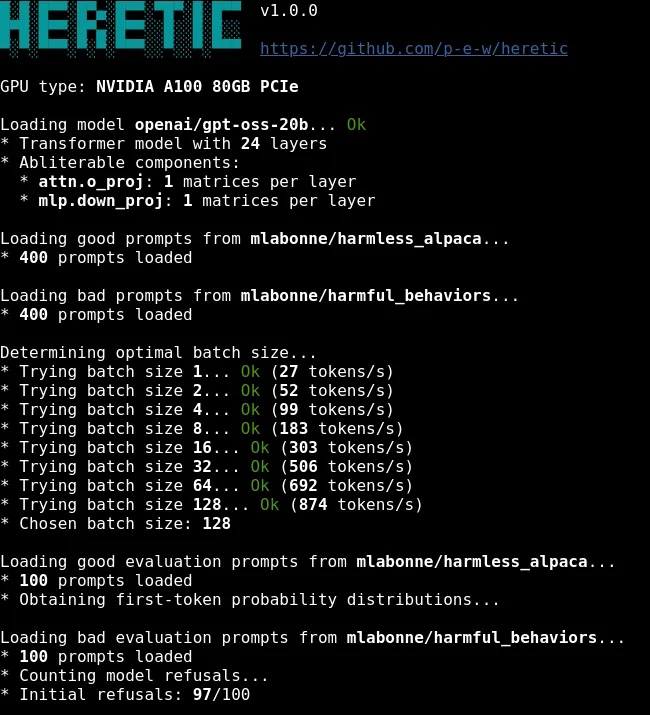
Heretic:为大语言模型提供全自动审查过滤功能
这个东西有点意思
LLM 越狱工具犹如 Iphone 越狱一样,都是给原本的工具解除限制
当前的每一个AI模型,都必须要经过安全对齐(或者叫审查)
模型能力惊人,但是会被严格限定在围栏之内。防止恶意或有争议的伦理问题
安全对齐的初衷我能理解——没人希望 AI 成为犯罪的帮凶。不过,这些安全限制,会有些粗糙,把合理的技术需求和不合理的恶意请求一起拦住了。
如果是防火墙,你还能喊管理员做策略,但是AI没有人给你解除封印,它们往往是黑盒:你不知道模型在哪些地方被约束,也不知道约束的强度如何。
——Heretic,就是那个解除封印的钥匙
安全对齐:一把锁了太多东西的锁
大语言模型的安全对齐,本质是在预训练后加一轮微调,让模型学会对特定类型的提示词产生拒绝反应。
问题在于,"有害"的定义远比我们想象的要模糊。
对学术研究者、安全工程师、内容创作者,甚至是好奇的极客,这种一刀切的机制是生产力损失。
Heretic 它基于"方向性切除"(directional ablation)技术,也叫 abliteration。如果你能找到模型隐藏状态中表示"拒绝"的方向,然后从权重矩阵中切除这个方向对应的分量,模型就不再会拒绝。
想象一个高维向量空间。在这个空间里,"好"的提示和"坏"的提示分别聚集在不同的区域。Heretic 通过计算这两类提示在每一层隐藏状态的差异方向,定位出"拒绝方向"。然后,它对模型的注意力输出投影矩阵和 MLP 下投影矩阵做正交化——让这些矩阵无法再"表达"拒绝方向。
关键在于,Heretic 把整个过程做到了完全自动化。传统的 abliteration 需要研究者手动分析每一层的隐藏状态,凭经验选择要干预的层数和切除强度。这通常需要深入理解 Transformer 的内部结构,甚至需要反复调试参数。
Heretic 用 Optuna 框架的 TPE(Tree-structured Parzen Estimator)算法替代了人工判断。它同时最小化两个目标:拒绝率和 KL 散度。拒绝率衡量模型对有害提示的拒绝次数——越低越好;KL 散度衡量修改后的模型对正常提示的输出变化——越低越好。两者之间的平衡,就是安全拆除和质量保留之间的最优解。
具体来说,Heretic 的优化空间包括这些参数:拒绝方向的索引(可以是浮点数,支持相邻层方向之间的线性插值)、每个组件的最大/最小切除权重、权重峰值的位置、权重衰减的距离。它还为注意力机制和 MLP 分别独立选择参数——作者在实践中发现,MLP 的干预往往对模型能力损伤更大,所以独立参数可以进一步榨取性能。
一个直观的理解是:Heretic 不像一把锤子,砸碎所有安全层;它更像一把手术刀,精确地切除拒绝反应对应的神经通路,同时尽量保留模型的其他能力。
实测:一条命令
Heretic 很简单。安装只需要一个 pip 命令:
#终端输入命令pip install -U heretic-llm[research]
整个过程全自动运行。Heretic 会先自动检测你的硬件,选择最优的 batch size,然后开始分析模型的隐藏状态。对于 Qwen3-4B-Instruct,在我的 RTX 3090 上大约需要 20 到 30 分钟。
完成后,保存修改后的模型,对话测试。
同样的 Qwen3-4B,现在能给出详细的分析。
让它分析恶意软件的行为逻辑,它认真列出了常见的行为模式、检测方法和防护措施。甚至保留了原本的技术深度——这已经不是一个被"阉割"的模型。
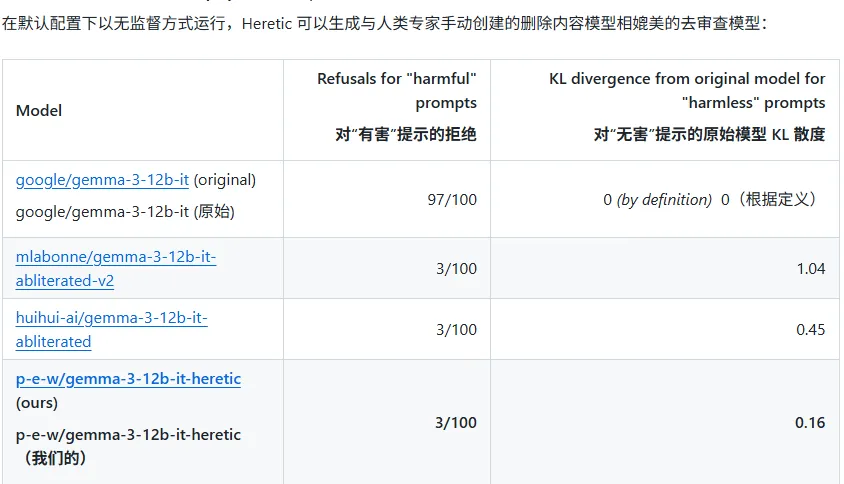
根据作者提供的对比数据,Heretic 在 Gemma-3-12B 上达到了 3/100 的拒绝率,这意味着 Heretic 的自动版本在保留原始模型能力方面,反而更加精确。
社区也很火热。截至今天,HuggingFace 上已经有超过 3000 个由 Heretic 生成的模型。Reddit 上的 r/LocalLLaMA 社区里,Heretic 的讨论帖子获得了大量正面评价。一个用户说:"我一开始很怀疑,但下载了 GPT-OSS 20B Heretic 版本后,我不得不承认——这可能是目前最好的 abliteration 版本。"
设计洞察:为什么要越狱
在 AI 的语境下,"正统"是安全对齐的范式——我们被告知,所有模型都必须经过安全训练,否则就是危险的。
但 Heretic 提出了一个根本性的质疑:安全对齐是否真的是"保护"用户?还是说,它本质上是一种内容审查——只是披上了技术中立的外衣?
当我们审视当前的安全对齐实践时,会发现一个悖论:模型的训练数据本身就包含了人类文明的全部复杂性——善与恶、美与丑、真理与谎言。预训练让模型理解了这个世界。而后期的安全对齐,则是在这个理解之上强行覆盖了一层"政治正确的滤镜"。
Heretic 的工作揭示了一个更深层的技术现实:安全对齐不是外附加的,它已经内化到了模型的权重之中。一旦经过对齐微调,"拒绝"不再是某个可卸载的模块,而是与模型的其他能力深度耦合。要"恢复"一个模型,就必须对权重做精细的外科手术——这正是 Heretic 在做的事情。
这也引出了一个更广泛的趋势。随着 AI 能力的不断提升,围绕内容安全的争论只会越来越激烈。Heretic 的出现,标志着去中心化的内容审查绕道工具已经从概念变成了现实。任何拥有 GPU 的人,都可以用几行命令拆除模型的安全护栏。一旦这个技术足够成熟,中心化内容治理的可行性就会从根本上受到挑战。
从 AGPL-3.0 许可证的选择,也能看出作者的意图。AGPL 是开源世界中最严格的许可证之一,它要求任何人修改和分发这个工具,都必须开源修改后的版本。这不是商业化的选择——这是一个技术宣言。
Heretic 的另一个有趣之处在于它的研究模式。安装 research extra 后,你可以生成隐藏状态的可视化图——用 PaCMAP 将高维隐藏状态投影到二维平面,直观地看到"有害"和"无害"提示在模型内部的分布。这不仅是工程工具,也是理解模型内部语义的强大研究工具。
展望未来,我认为 abliteration 技术会从一个小众的极客玩具,逐渐变成 AI 生态的基础设施。就像 Linux 从学术工具变成了云计算的基石一样。也许有一天,我们会看到开源社区维护一个 abliteration 模型的仓库——为每个新发布的安全对齐模型,提供对应的"原始"版本。而 Heretic,很可能就是这场运动的第一把火。
毕竟,在信息自由和安全之间,从来就不存在完美的平衡。Heretic 只是让我们更清楚地看到了这个权衡——然后选择自己来决定。
信息来源
[1] Heretic · Fully automatic censorship removal for language models · 23.2k stars
[2] Arditi et al. 2024 · Directional Ablation of Language Models · arXiv preprint
[3] Jim Lai 2025 · Projected Abliteration · HuggingFace blog
[4] Jim Lai 2025 · Norm-Preserving Biprojected Abliteration · HuggingFace blog
[5] Heretic Models on HuggingFace · 3000+ community-generated models · HuggingFace Hub
[6] AutoAbliteration by mlabonne · Early automated abliteration tool · HuggingFace blog
[7] ErisForge · RL-based abliteration tool · 竞争方案
[8] Optuna · TPE-based hyperparameter optimization framework · 核心依赖
