 夜雨聆风
夜雨聆风“近期将连续发布《从OpenClaw源码分析小龙虾是如何工作的?》,本系列一共十篇文章。 主题为:概览与调试环境搭建->Gateway中央控制器->Session管理分析->提示词上下文分析->ReAct原理与源码分析->定时任务与心跳机制->记忆系统分析->Skill 体系分析->Channel 系统分析->自我进化机制。
第7篇:记忆系统分析
一、记忆功能介绍
OpenClaw 的记忆系统是其智能进化能力的核心,用于记住用户的偏好、历史决策、重要事实,并在后续对话中主动召回。
二、整体功能架构
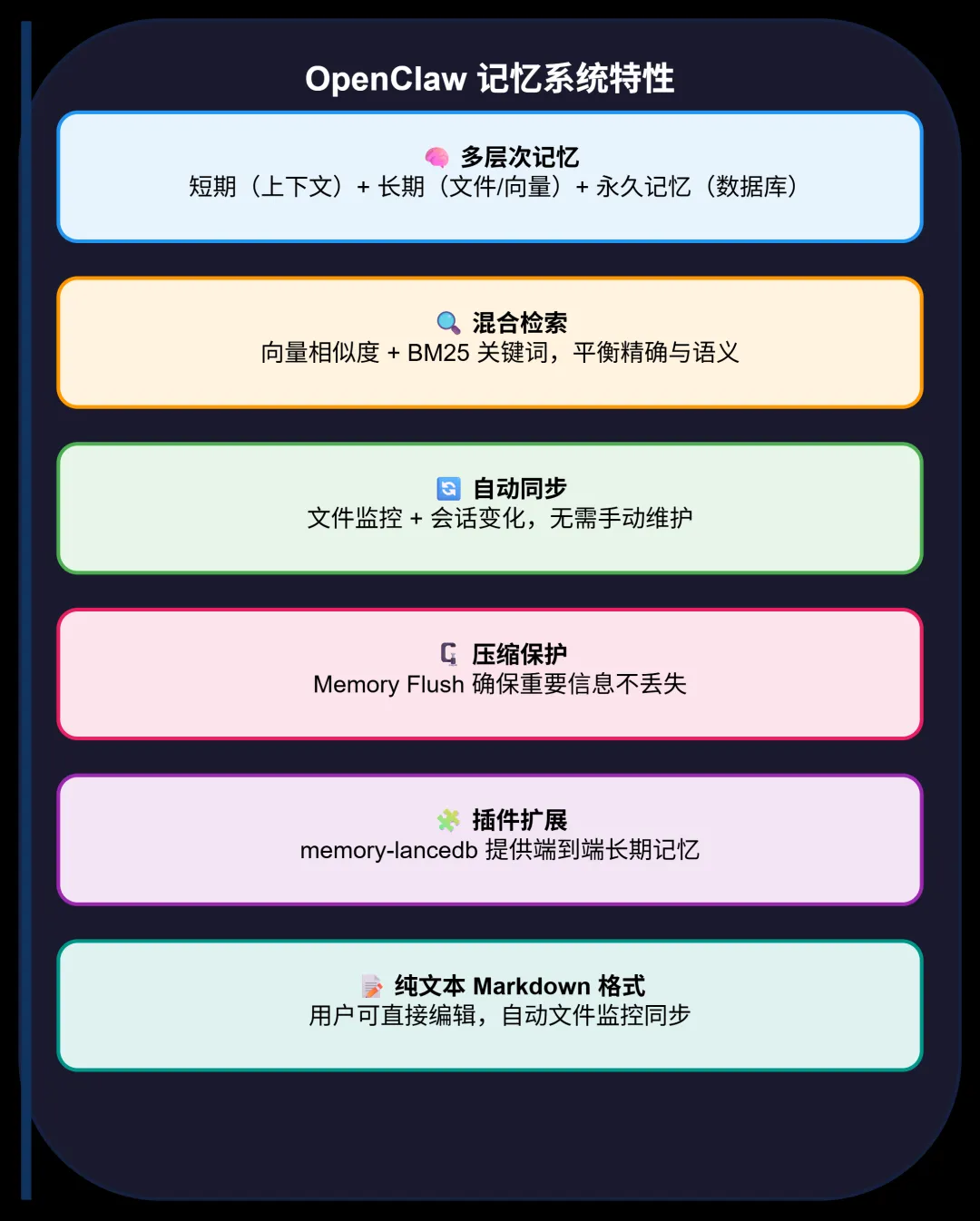
OpenClaw 的记忆系统采用了分层存储 + 向量检索的混合架构。
持久化存储 - 将重要信息保存到磁盘文件(MEMORY.md)。 语义检索 - 通过向量相似度快速定位相关内容。 上下文注入 - 在对话中自动召回相关记忆。 自动管理 - 压缩时自动将短期记忆刷写到长期存储。
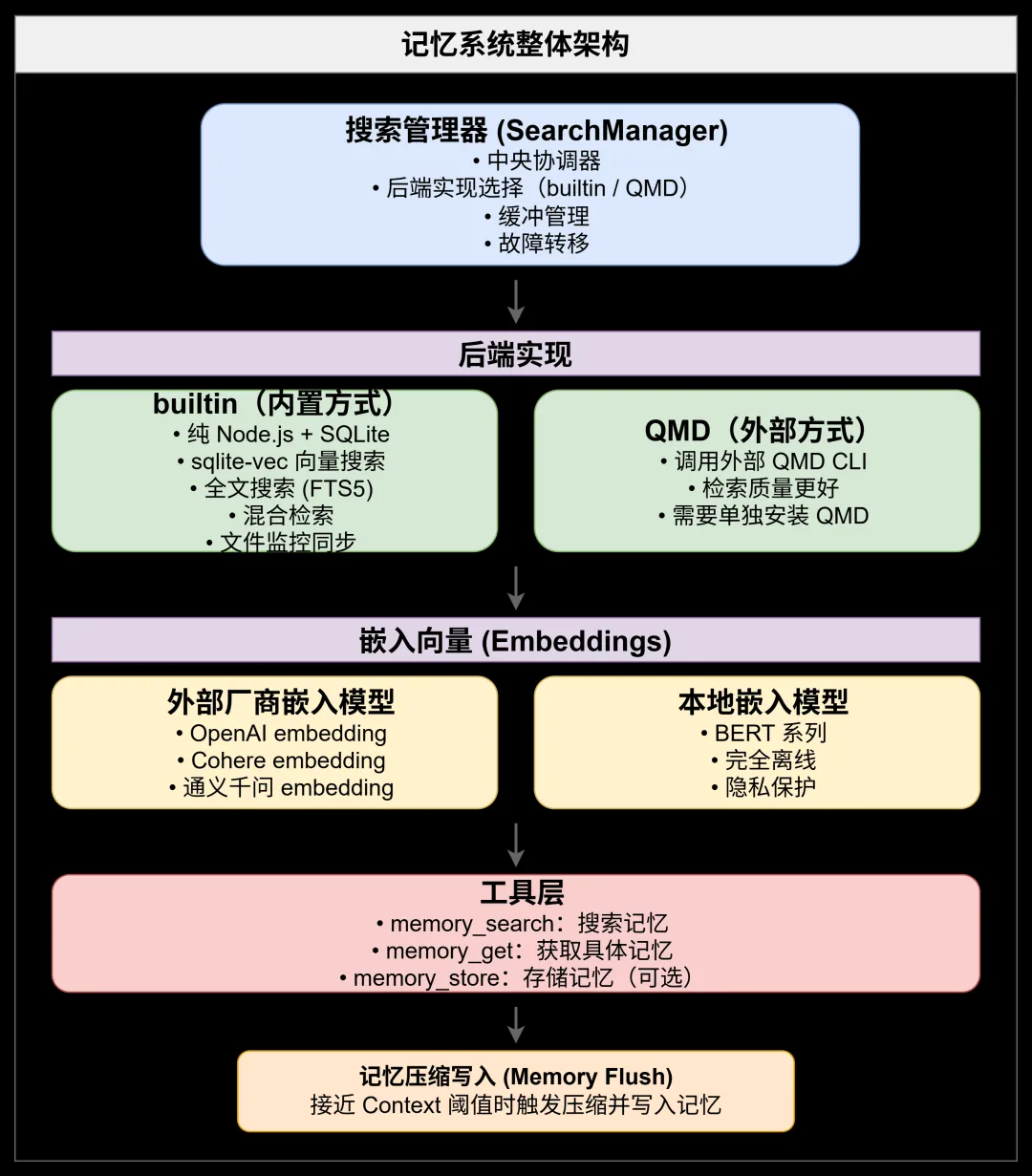
搜索管理器:负责整个记忆系统的中央协调器,负责后端实现选择、缓冲管理和故障转移等。 后端实现:包括内置方式和QMD方式 内置方式是纯nodejs sqlite集成,实现sqlite-vec 向量搜索、全文搜索、混合检索、文件监控同步功能。 QMD方式是调用外部QMD CLI,检索质量更好。 嵌入向量:支持外部厂商嵌入模型和本地嵌入模型。 插件:记忆搜索、获取、存储等相关工具。 记忆压缩写入:接近context阈值时触发压缩并写入记忆。
三、记忆处理流程
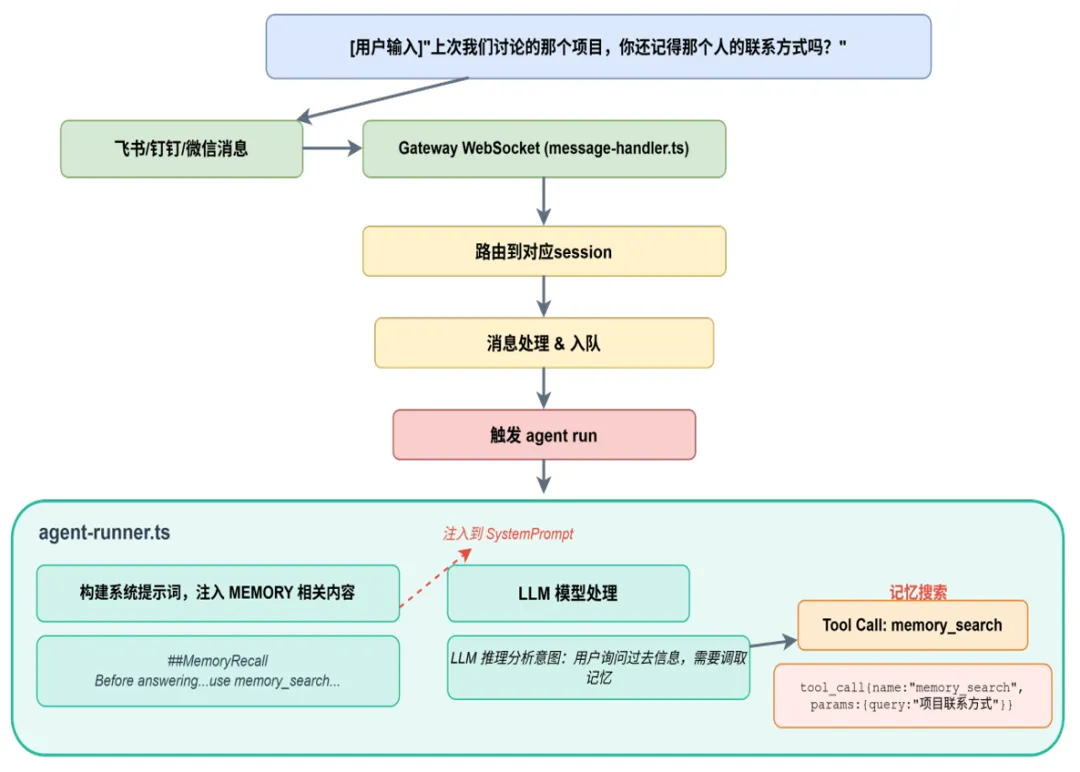
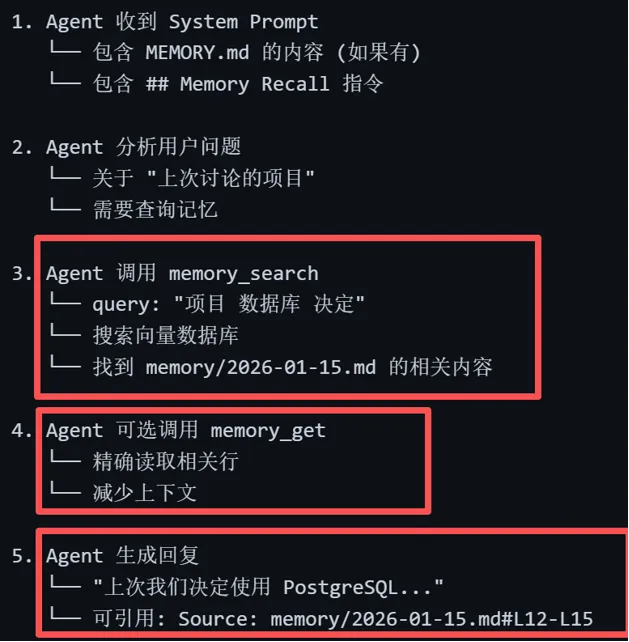
让我们通过一个具体的用户请求,追踪记忆系统的完整处理流程。
微信输入“上次我们讨论的那个项目,您还记得那个人的联系方式吗?”。 通过websocket进到gateway并路由到相应session。 进入队列进行消息处理。 构建系统提示词,包括memory内容。 调用LLM模型推理,返回需要调取记忆,调用memory_search工具。 pi-agent执行tool调用,传入query参数为“项目 联系方式”
四、记忆的提示词注入
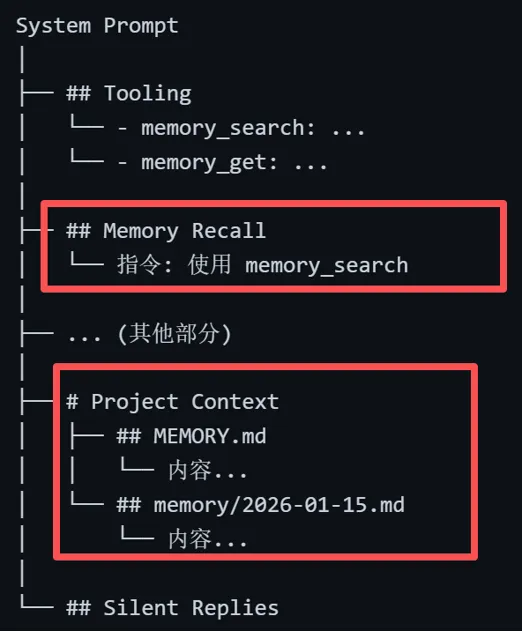
记忆内容通过两种方式注入到系统提示词中:
4.1 静态注入 —— MEMORY.md
MEMORY.md 或 memory.md 的内容自动注入到系统提示词的 Project Context 部分。
# Project Context...## MEMORY.md这是一个重要的长期记忆文件,内容如下:# 用户偏好记录## 联系方式- 项目A负责人:张三,电话 138****0000,邮箱 zhangsan@example.com- 项目B负责人:李四,电话 139****0001,邮箱 lisi@example.com## 技术决策- 2026-05-15:决定使用 TypeScript 重构前端- 2026-05-20:选择 PostgreSQL 作为主数据库## 用户偏好- 喜欢简洁的回答风格- 不喜欢长篇大论,优先给结论- 工作日上午 10-11 点不方便回复4.2 动态注入 —— Memory Recall
memory/*.md 的所有记忆文件,通过 Memory Recall 指令告知模型需要动态搜索:
## 记忆召回在回答任何关于先前工作、决策、日期、人员、偏好或待办事项的问题之前:先对 MEMORY.md 和 memory/*.md 执行 memory_search;然后使用 memory_get 仅提取需要的行。如果在搜索后置信度仍然较低,应说明自己已进行过查阅。引用规范:如果能帮助用户核实记忆片段,请附上出处(格式:Source: <文件路径#行号>)。4.3 两种注入方式对比
| 触发方式 | ||
| 内容大小 | ||
| 适用场景 | ||
| 用户可编辑 | ||
| 检索方式 |
五、三种检索算法
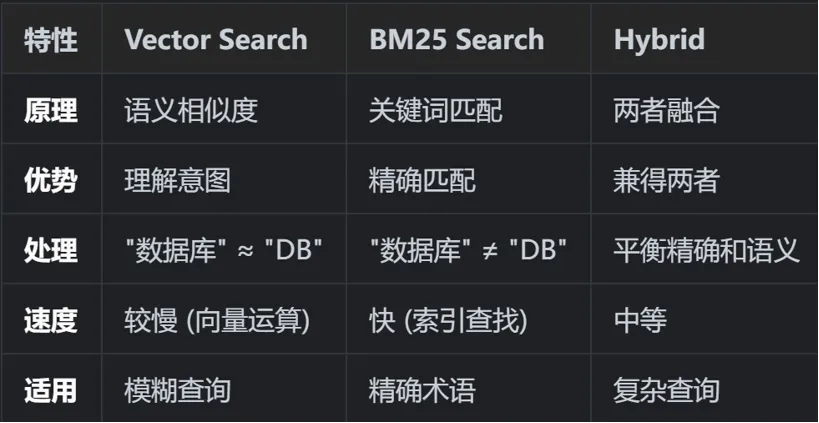
OpenClaw 实现了 hybrid(混合检索) 算法,结合向量相似度和 BM25 关键词匹配。
5.1 Hybrid 检索核心逻辑
得分score = vectorWeight * vectorScore + textWeight * textScore
默认权重: vectorWeight=0.7, textWeight=0.3
融合步骤:
1. 收集向量搜索 Top-N 结果 2. 收集 BM25 搜索 Top-N结果 3. 按 id 合并结果 4. 计算加权分数 5. 按分数降序排序 6. 应用 minScore 过滤 7. 返回 Top-maxResults
5.2 检索算法对比
六、索引同步机制
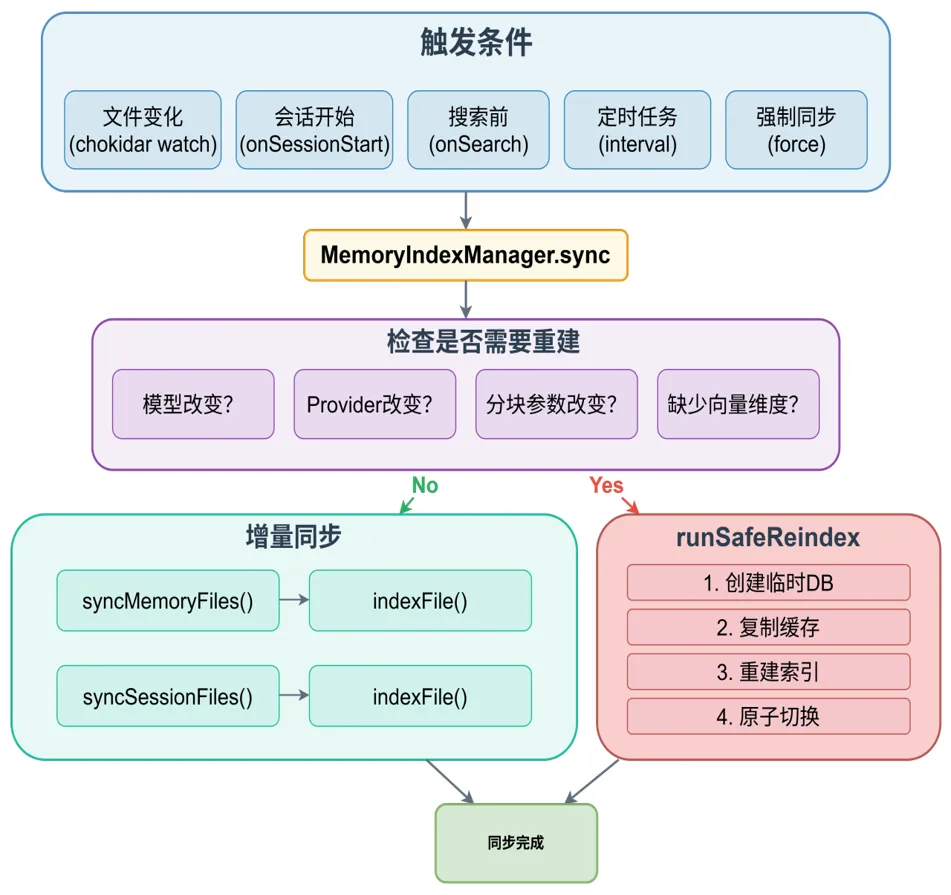
OpenClaw 会在以下情况触发索引同步:
| 文件监控 | sync.onFileChange | |
| 会话开始 | sync.onSessionStart | |
| 搜索前 | sync.onSearch | |
| 定时任务 | sync.intervalMinutes | |
| 手动触发 | openclaw memory sync |
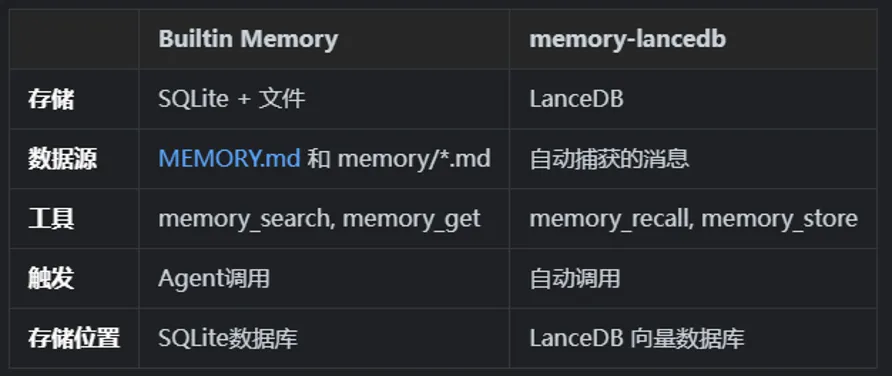
七、builtin vs LanceDB
Openclaw提供了builtin和LanceDB两种记忆存储后端,可通过配置切换。
builtin采用sqlite+vec存储,LanceDB插件采用LanceDB实现,两者可以通过配置进行选择。 LanceDB是一个开源的向量数据库,用于存储和检索高维向量数据。

| 依赖 | ||
| 向量维度 | ||
| 检索速度 | ||
| 混合检索 | ||
| 适用规模 |
八、记忆的四层分级机制
Openclaw可以认为有四层记忆机制:
上下文记忆,生命周期是单次会话中,因为历史对话都会带入提示词。主要受模型输入长度限制。 压缩记忆,生命周期是超出指定长度的多次会话期间,将信息压缩后再加到提示词中,并且会保存到sqlite中。 文件记忆,持久化存储在MEMORY.md和memory/*.md中,由agent+人工手动维护。 持久记忆,与文件记忆类似,由agent自动维护,记录了个人偏好、决定、实体、事实等关键信息。

九、总结
核心特性:多层次记忆 + 混合检索 + 自动同步 + 压缩保护 整体架构:搜索管理器 → 后端实现 → 嵌入向量 → 工具层 混合检索:向量权重 70% + BM25 权重 30%,平衡语义和精确 索引同步:文件监控、会话开始、搜索前、定时任务、手动触发 两种后端:builtin(开箱即用)vs LanceDB(高性能大规模) 四层记忆:上下文 → 压缩 → 文件 → 持久,满足不同场景需求
