 夜雨聆风
夜雨聆风概述
本周深入分析 RAGFlow 的数据库架构和服务层设计。RAGFlow 采用 Peewee ORM 作为数据库抽象层,支持 MySQL、PostgreSQL、OceanBase、SeekDB 等多种数据库。服务层遵循 Active Record 模式,通过 CommonService 基类提供统一的 CRUD 操作接口。
核心文件
api/db/db_models.py- 数据模型定义与数据库连接池 api/db/services/common_service.py- 服务层基类 api/db/services/knowledgebase_service.py- 知识库服务 api/db/services/document_service.py- 文档服务 其他 20+ 服务类
一、数据库连接池架构
1.1 多数据库支持设计
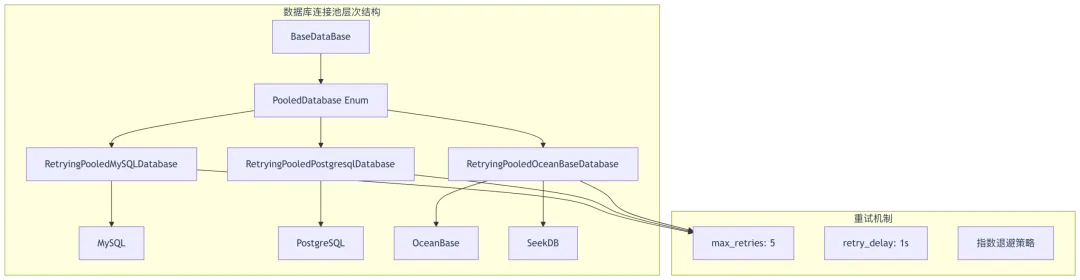
1.2 连接池核心实现
源码位置: api/db/db_models.py:244-315
class RetryingPooledMySQLDatabase(PooledMySQLDatabase):def __init__(self, *args, **kwargs):self.max_retries = kwargs.pop("max_retries", 5)self.retry_delay = kwargs.pop("retry_delay", 1)super().__init__(*args, **kwargs)def execute_sql(self, sql, params=None):for attempt in range(self.max_retries + 1):try:return super().execute_sql(sql, params)except (OperationalError, InterfaceError) as e:error_codes = [2013, 2006] # 连接丢失错误码error_messages = ['', 'Lost connection']should_retry = ((hasattr(e, 'args') and e.args and e.args[0] in error_codes) or(str(e) in error_messages) or(hasattr(e, '__class__') and e.__class__.__name__ == 'InterfaceError'))if should_retry and attempt < self.max_retries:logging.warning(f"Database connection issue (attempt {attempt+1}/{self.max_retries}): {e}")self._handle_connection_loss()time.sleep(self.retry_delay * (2 ** attempt)) # 指数退避else:logging.error(f"DB execution failure: {e}")raisereturn None
设计决策分析:
_handle_connection_loss() |
1.3 数据库类型适配
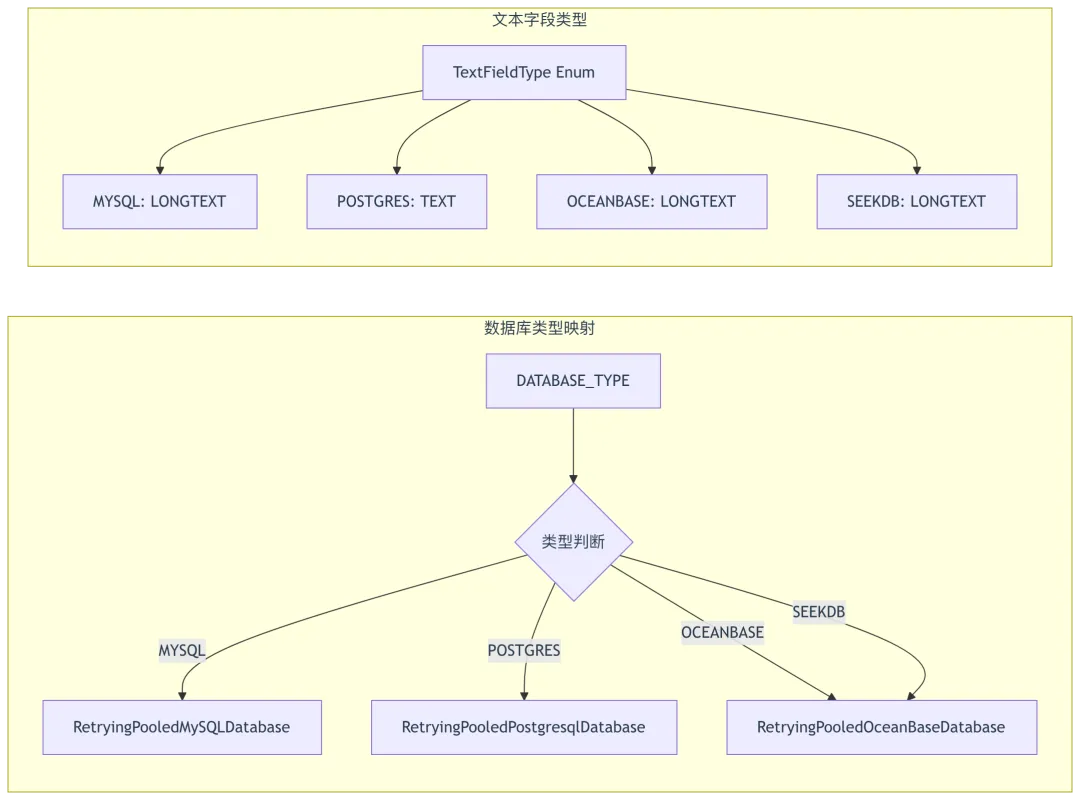
源码位置: api/db/db_models.py:49-57
classTextFieldType(Enum):MYSQL = "LONGTEXT"OCEANBASE = "LONGTEXT"SEEKDB = "LONGTEXT"POSTGRES = "TEXT"class LongTextField(TextField):field_type = TextFieldType[settings.DATABASE_TYPE.upper()].value
二、自定义字段类型
2.1 字段类型继承层次
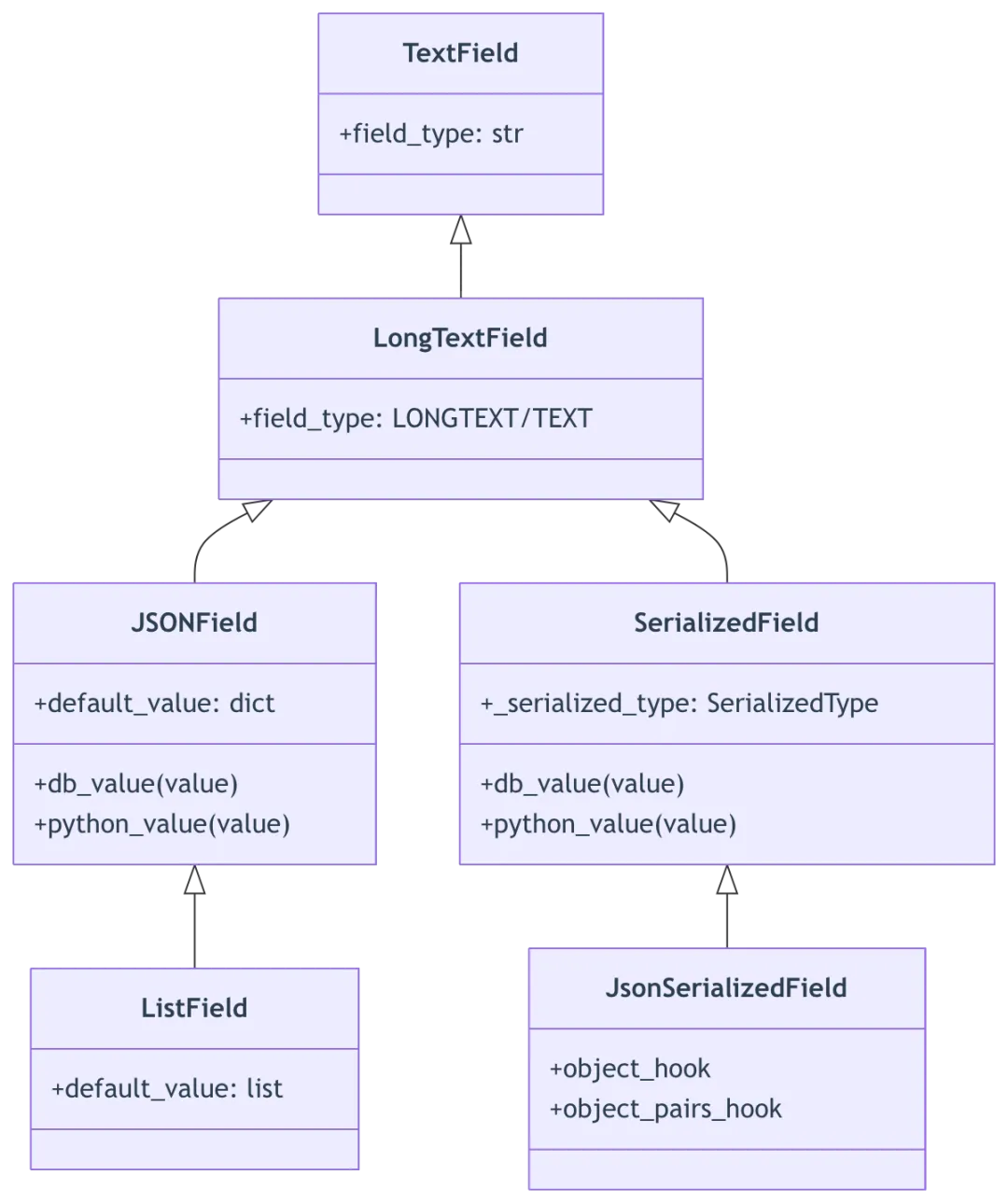
2.2 JSONField 实现
源码位置: api/db/db_models.py:60-76
class JSONField(LongTextField):default_value = {}def __init__(self, object_hook=None, object_pairs_hook=None, **kwargs):self._object_hook = object_hookself._object_pairs_hook = object_pairs_hooksuper().__init__(**kwargs)def db_value(self, value):if value is None:value = self.default_valuereturn json_dumps(value)def python_value(self, value):if not value:return self.default_valuereturn json_loads(value, object_hook=self._object_hook,object_pairs_hook=self._object_pairs_hook)
使用示例:
class Knowledgebase(DataBaseModel):parser_config = JSONField(null=False,default={"pages": [[1, 1000000]],"table_context_size": 0,"image_context_size": 0})kb_ids = JSONField(null=False, default=[])
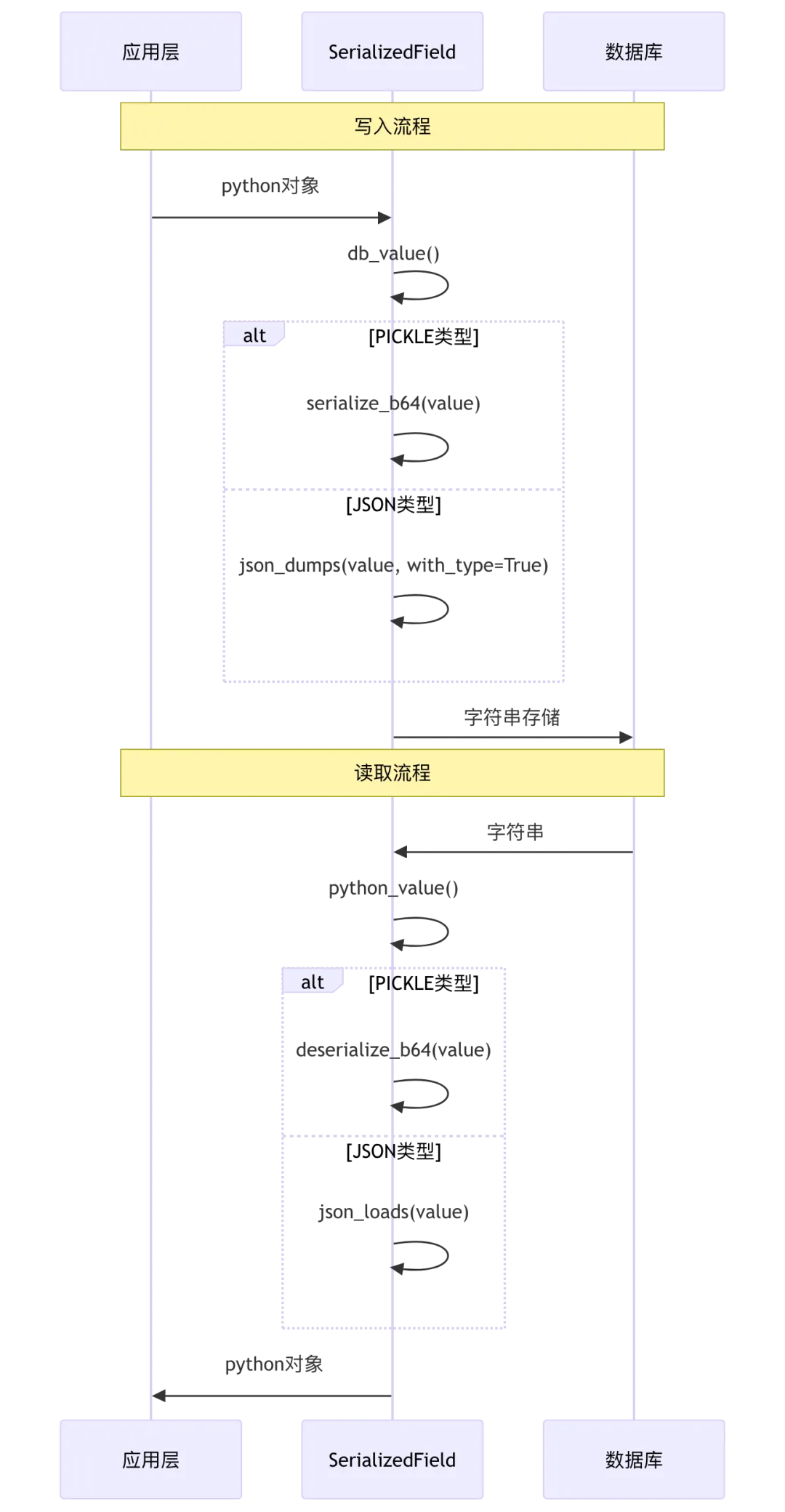
2.3 SerializedField 序列化策略
三、BaseModel 基类设计
3.1 模型基类功能矩阵

3.2 时间戳自动填充机制
源码位置: api/db/db_models.py:214-236
class BaseModel(Model):create_time = BigIntegerField(null=True, index=True)create_date = DateTimeField(null=True, index=True)update_time = BigIntegerField(null=True, index=True)update_date = DateTimeField(null=True, index=True)@classmethoddef _normalize_data(cls, data, kwargs):normalized = super()._normalize_data(data, kwargs)if not normalized:return {}normalized[cls._meta.combined["update_time"]] = current_timestamp()for f_n in AUTO_DATE_TIMESTAMP_FIELD_PREFIX:if {f"{f_n}_time", f"{f_n}_date"}.issubset(cls._meta.combined.keys()):if cls._meta.combined[f"{f_n}_time"] in normalized:timestamp = normalized[cls._meta.combined[f"{f_n}_time"]]if timestamp is not None:normalized[cls._meta.combined[f"{f_n}_date"]] = \timestamp_to_date(timestamp)return normalized
自动时间戳字段前缀:
AUTO_DATE_TIMESTAMP_FIELD_PREFIX = {"create", "start", "end", "update","read_access", "write_access"}
3.3 查询构造器
源码位置: api/db/db_models.py:174-212
@classmethoddef query(cls, reverse=None, order_by=None, **kwargs):filters = []for f_n, f_v in kwargs.items():attr_name = "%s" % f_nif not hasattr(cls, attr_name) or f_v is None:continueif type(f_v) in {list, set}:f_v = list(f_v)if is_continuous_field(type(getattr(cls, attr_name))):# 范围查询if len(f_v) == 2:lt_value, gt_value = f_v[0], f_v[1]if lt_value is not None and gt_value is not None:filters.append(cls.getter_by(attr_name).between(lt_value, gt_value))elif lt_value is not None:filters.append(operator.attrgetter(attr_name)(cls) >= lt_value)elif gt_value is not None:filters.append(operator.attrgetter(attr_name)(cls) <= gt_value)else:# IN 查询filters.append(operator.attrgetter(attr_name)(cls) << f_v)else:# 等值查询filters.append(operator.attrgetter(attr_name)(cls) == f_v)if filters:query_records = cls.select().where(*filters)if reverse is not None:if not order_by:order_by = "create_time"if reverse is True:query_records = query_records.order_by(cls.getter_by(f"{order_by}").desc())elif reverse is False:query_records = query_records.order_by(cls.getter_by(f"{order_by}").asc())return [query_record for query_record in query_records]else:return []
查询示例:
# 等值查询users = User.query(email="test@example.com")# 范围查询docs = Document.query(create_time=["2024-01-01", "2024-12-31"])# IN 查询kbs = Knowledgebase.query(tenant_id=["tenant1", "tenant2"])# 排序docs = Document.query(kb_id="kb123", reverse=True, order_by="update_time")
四、数据库锁机制
4.1 分布式锁设计
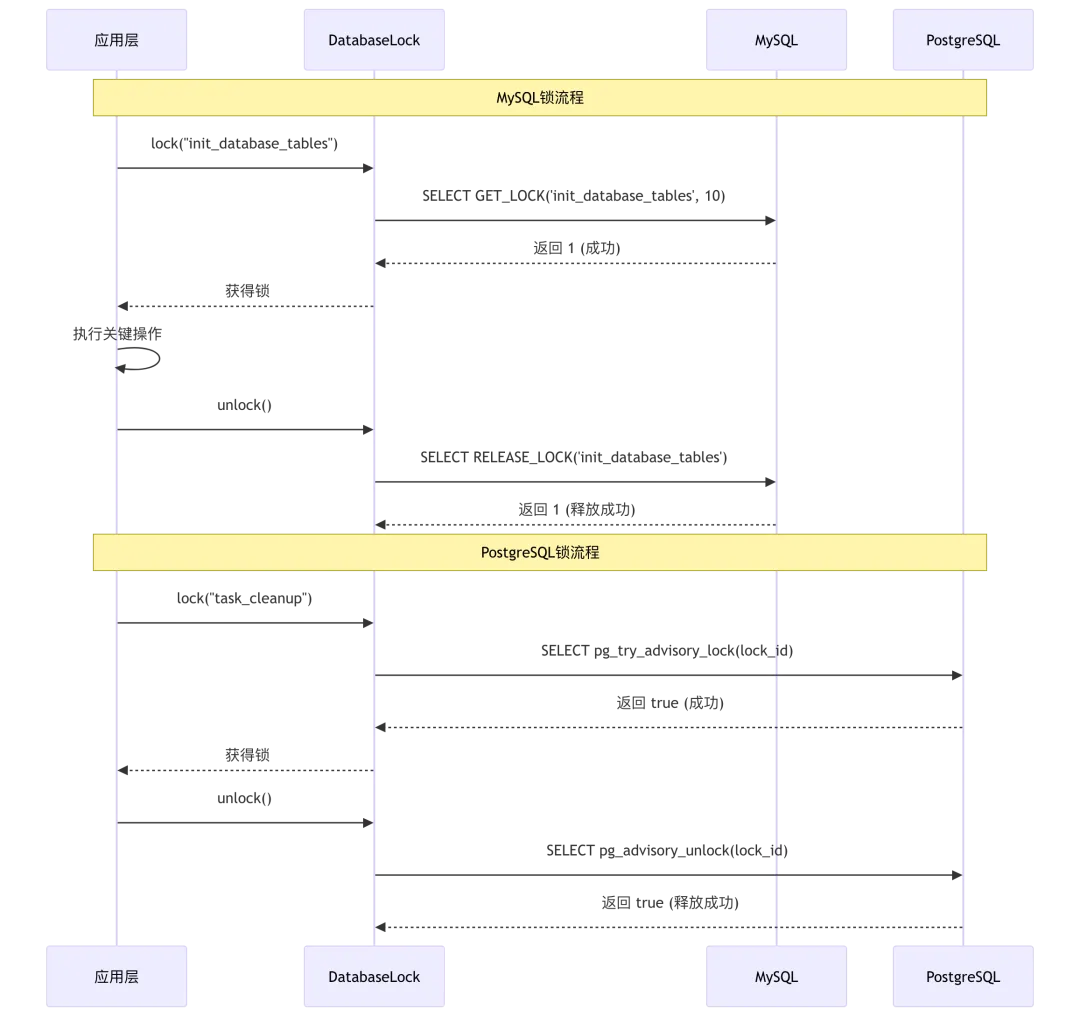
4.2 锁实现对比
MySQL 锁实现 (api/db/db_models.py:594-638):
class MysqlDatabaseLock:def __init__(self, lock_name, timeout=10, db=None):self.lock_name = lock_nameself.timeout = int(timeout)self.db = db if db else DB@with_retry(max_retries=3, retry_delay=1.0)def lock(self):cursor = self.db.execute_sql("SELECT GET_LOCK(%s, %s)",(self.lock_name, self.timeout))ret = cursor.fetchone()if ret[0] == 0:raise Exception(f"acquire mysql lock {self.lock_name} timeout")elif ret[0] == 1:return Trueelse:raise Exception(f"failed to acquire lock {self.lock_name}")@with_retry(max_retries=3, retry_delay=1.0)def unlock(self):cursor = self.db.execute_sql("SELECT RELEASE_LOCK(%s)",(self.lock_name,))ret = cursor.fetchone()if ret[0] == 0:raise Exception(f"mysql lock {self.lock_name} was not established")elif ret[0] == 1:return Trueelse:raise Exception(f"mysql lock {self.lock_name} does not exist")
PostgreSQL 锁实现 (api/db/db_models.py:547-591):
class PostgresDatabaseLock:def __init__(self, lock_name, timeout=10, db=None):self.lock_name = lock_name# 使用 MD5 哈希生成锁 IDself.lock_id = int(hashlib.md5(lock_name.encode()).hexdigest(), 16) % (2**31 - 1)self.timeout = int(timeout)self.db = db if db else DB@with_retry(max_retries=3, retry_delay=1.0)def lock(self):cursor = self.db.execute_sql("SELECT pg_try_advisory_lock(%s)",(self.lock_id,))ret = cursor.fetchone()if ret[0] == 0:raise Exception(f"acquire postgres lock {self.lock_name} timeout")elif ret[0] == 1:return True
4.3 锁装饰器模式
# 上下文管理器用法with DB.lock("init_database_tables", 30):init_database_tables()# 装饰器用法@DB.lock("init_database_tables", 30)def init_database_tables(alter_fields=[]):# 表初始化逻辑pass
五、核心数据模型
5.1 数据模型关系图
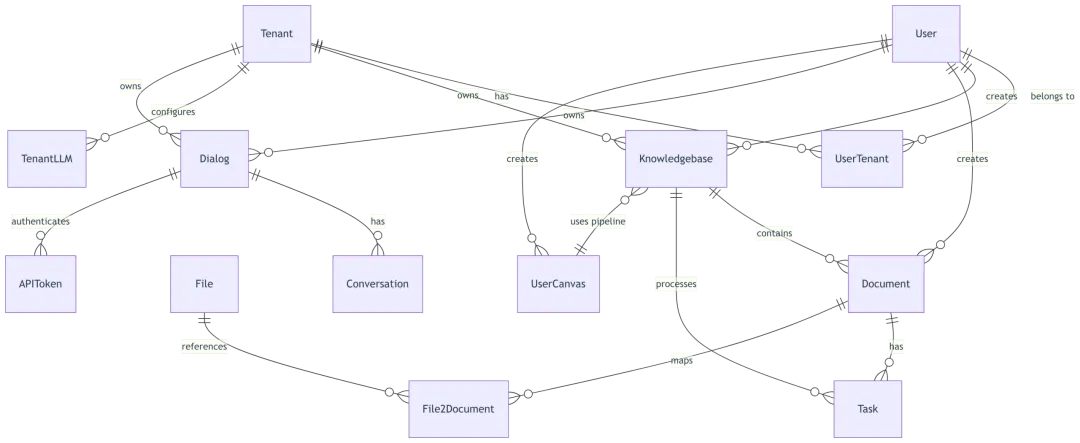
5.2 用户与租户模型
User 模型 (api/db/db_models.py:707-733):
class User(DataBaseModel, AuthUser):id = CharField(max_length=32, primary_key=True)access_token = CharField(max_length=255, null=True, index=True)nickname = CharField(max_length=100, null=False, index=True)password = CharField(max_length=255, null=True, index=True)email = CharField(max_length=255, null=False, index=True)avatar = TextField(null=True)language = CharField(max_length=32, null=True, default="Chinese", index=True)color_schema = CharField(max_length=32, null=True, default="Bright", index=True)timezone = CharField(max_length=64, null=True, default="UTC+8\tAsia/Shanghai", index=True)last_login_time = DateTimeField(null=True, index=True)is_authenticated = CharField(max_length=1, null=False, default="1", index=True)is_active = CharField(max_length=1, null=False, default="1", index=True)is_anonymous = CharField(max_length=1, null=False, default="0", index=True)login_channel = CharField(null=True, index=True)status = CharField(max_length=1, null=True, default="1", index=True)is_superuser = BooleanField(null=True, default=False, index=True)def get_id(self):jwt = Serializer(secret_key=settings.SECRET_KEY)return jwt.dumps(str(self.access_token))
Tenant 模型 (api/db/db_models.py:736-751):
class Tenant(DataBaseModel):id = CharField(max_length=32, primary_key=True)name = CharField(max_length=100, null=True, index=True)public_key = CharField(max_length=255, null=True, index=True)# 默认模型配置llm_id = CharField(max_length=128, null=False, index=True)embd_id = CharField(max_length=128, null=False, index=True)asr_id = CharField(max_length=128, null=False, index=True)img2txt_id = CharField(max_length=128, null=False, index=True)rerank_id = CharField(max_length=128, null=False, index=True)tts_id = CharField(max_length=256, null=True, index=True)parser_ids = CharField(max_length=256, null=False, index=True)credit = IntegerField(default=512, index=True)status = CharField(max_length=1, null=True, default="1", index=True)
5.3 知识库与文档模型
Knowledgebase 模型 (api/db/db_models.py:843-877):
class Knowledgebase(DataBaseModel):id = CharField(max_length=32, primary_key=True)avatar = TextField(null=True)tenant_id = CharField(max_length=32, null=False, index=True)name = CharField(max_length=128, null=False, index=True)language = CharField(max_length=32, null=True, default="Chinese", index=True)description = TextField(null=True)# Embedding 模型embd_id = CharField(max_length=128, null=False, index=True)# 权限控制permission = CharField(max_length=16, null=False, default="me", index=True)created_by = CharField(max_length=32, null=False, index=True)# 统计信息doc_num = IntegerField(default=0, index=True)token_num = IntegerField(default=0, index=True)chunk_num = IntegerField(default=0, index=True)# 检索参数similarity_threshold = FloatField(default=0.2, index=True)vector_similarity_weight = FloatField(default=0.3, index=True)# 解析器配置parser_id = CharField(max_length=32, null=False, default=ParserType.NAIVE.value, index=True)pipeline_id = CharField(max_length=32, null=True, index=True)parser_config = JSONField(null=False, default={"pages": [[1, 1000000]],"table_context_size": 0,"image_context_size": 0})pagerank = IntegerField(default=0, index=False)# 后台任务graphrag_task_id = CharField(max_length=32, null=True, index=True)graphrag_task_finish_at = DateTimeField(null=True)raptor_task_id = CharField(max_length=32, null=True, index=True)raptor_task_finish_at = DateTimeField(null=True)mindmap_task_id = CharField(max_length=32, null=True, index=True)mindmap_task_finish_at = DateTimeField(null=True)status = CharField(max_length=1, null=True, default="1", index=True)
Document 模型 (api/db/db_models.py:880-905):
class Document(DataBaseModel):id = CharField(max_length=32, primary_key=True)thumbnail = TextField(null=True)kb_id = CharField(max_length=256, null=False, index=True)# 解析配置parser_id = CharField(max_length=32, null=False, index=True)pipeline_id = CharField(max_length=32, null=True, index=True)parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})# 文件信息source_type = CharField(max_length=128, null=False, default="local", index=True)type = CharField(max_length=32, null=False, index=True)name = CharField(max_length=255, null=True, index=True)location = CharField(max_length=255, null=True, index=True)size = IntegerField(default=0, index=True)suffix = CharField(max_length=32, null=False, index=True)# 处理状态token_num = IntegerField(default=0, index=True)chunk_num = IntegerField(default=0, index=True)progress = FloatField(default=0, index=True)progress_msg = TextField(null=True, default="")process_begin_at = DateTimeField(null=True, index=True)process_duration = FloatField(default=0)# 运行状态run = CharField(max_length=1, null=True, default="0", index=True)status = CharField(max_length=1, null=True, default="1", index=True)created_by = CharField(max_length=32, null=False, index=True)
六、服务层架构
6.1 服务类继承体系
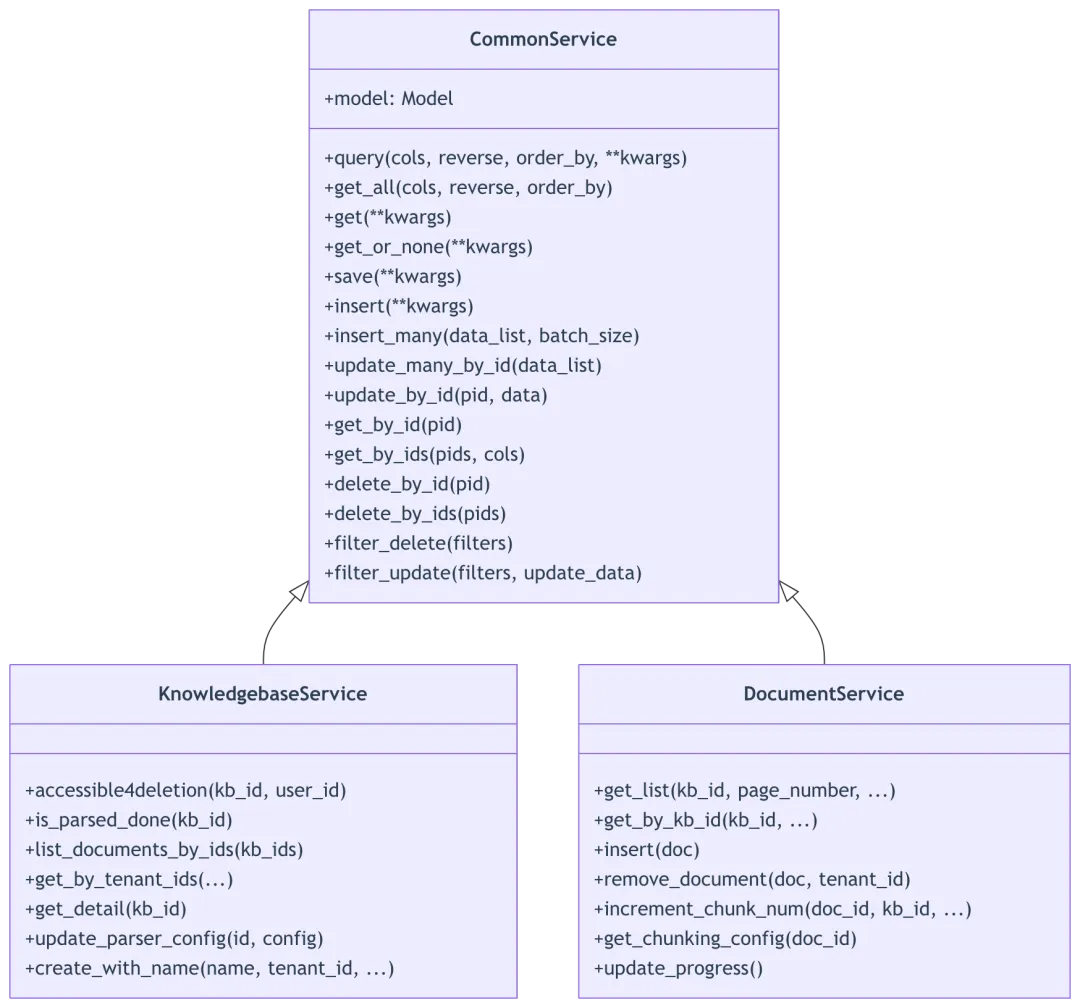
6.2 CommonService 基类详解
源码位置: api/db/services/common_service.py:37-357
核心方法分析
查询方法 (common_service.py:51-99):
class CommonService:model = None@classmethod@DB.connection_context()def query(cls, cols=None, reverse=None, order_by=None, **kwargs):"""执行数据库查询,支持列选择和排序"""return cls.model.query(cols=cols, reverse=reverse, order_by=order_by, **kwargs)@classmethod@DB.connection_context()def get_all(cls, cols=None, reverse=None, order_by=None):"""获取所有记录"""if cols:query_records = cls.model.select(*cols)else:query_records = cls.model.select()if reverse is not None:if not order_by or not hasattr(cls.model, order_by):order_by = "create_time"if reverse is True:query_records = query_records.order_by(cls.model.getter_by(order_by).desc())elif reverse is False:query_records = query_records.order_by(cls.model.getter_by(order_by).asc())return query_records
插入方法 (common_service.py:156-203):
@classmethod@DB.connection_context()def insert(cls, **kwargs):"""插入新记录,自动生成 ID 和时间戳"""if "id" not in kwargs:kwargs["id"] = get_uuid()timestamp = current_timestamp()cur_datetime = datetime_format(datetime.now())kwargs["create_time"] = timestampkwargs["create_date"] = cur_datetimekwargs["update_time"] = timestampkwargs["update_date"] = cur_datetimesample_obj = cls.model(**kwargs).save(force_insert=True)return sample_obj@classmethod@DB.connection_context()def insert_many(cls, data_list, batch_size=100):"""批量插入记录"""current_ts = current_timestamp()current_datetime = datetime_format(datetime.now())with DB.atomic():for d in data_list:d["create_time"] = current_tsd["create_date"] = current_datetimed["update_time"] = current_tsd["update_date"] = current_datetimefor i in range(0, len(data_list), batch_size):cls.model.insert_many(data_list[i : i + batch_size]).execute()
更新方法 (common_service.py:227-240):
@classmethod@DB.connection_context()@retry_db_operationdef update_by_id(cls, pid, data):"""通过 ID 更新记录"""data["update_time"] = current_timestamp()data["update_date"] = datetime_format(datetime.now())num = cls.model.update(data).where(cls.model.id == pid).execute()return num@classmethod@DB.connection_context()def update_many_by_id(cls, data_list):"""批量更新记录"""timestamp = current_timestamp()cur_datetime = datetime_format(datetime.now())for data in data_list:data["update_time"] = timestampdata["update_date"] = cur_datetimewith DB.atomic():for data in data_list:cls.model.update(data).where(cls.model.id == data["id"]).execute()
6.3 重试装饰器设计
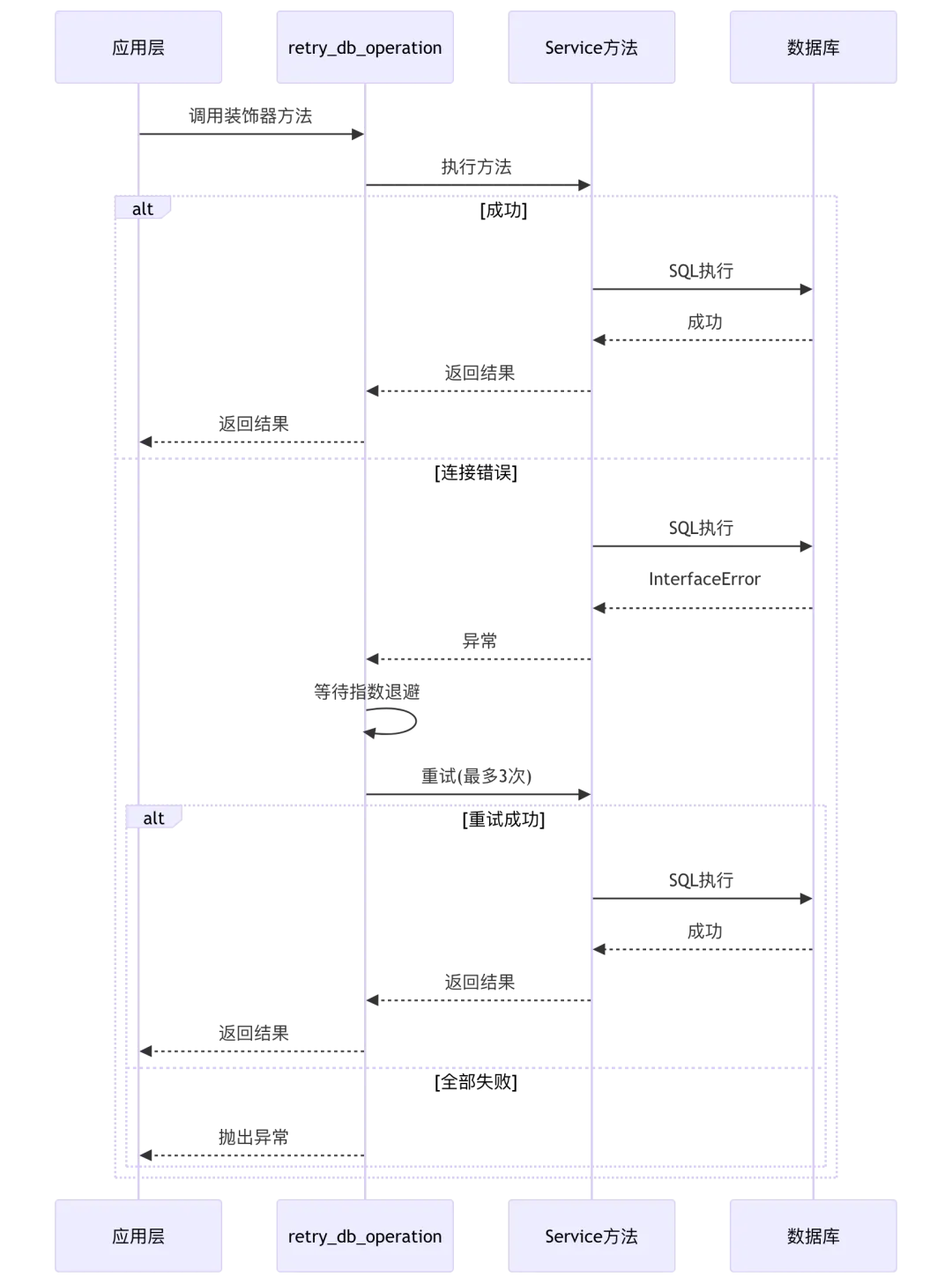
源码位置: common_service.py:25-35
def retry_db_operation(func):@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=1, min=1, max=5),retry=retry_if_exception_type((InterfaceError, OperationalError)),before_sleep=lambda retry_state: print(f"RETRY {retry_state.attempt_number} TIMES"),reraise=True,)def wrapper(*args, **kwargs):return func(*args, **kwargs)return wrapper
七、KnowledgebaseService 深度解析
7.1 知识库服务核心功能

7.2 文档解析状态检查
源码位置: knowledgebase_service.py:85-117
@classmethod@DB.connection_context()def is_parsed_done(cls, kb_id):"""检查知识库中所有文档是否解析完成"""from common.constants import TaskStatusfrom api.db.services.document_service import DocumentService# 获取知识库信息kbs = cls.query(id=kb_id)if not kbs:return False, "Knowledge base not found"kb = kbs[0]# 获取所有文档docs, _ = DocumentService.get_by_kb_id(kb_id, 1, 1000, "create_time", True, "", [], [])# 检查每个文档的解析状态for doc in docs:# 正在解析中if doc['run'] == TaskStatus.RUNNING.value or \doc['run'] == TaskStatus.CANCEL.value or \doc['run'] == TaskStatus.FAIL.value:return False, f"Document '{doc['name']}' in dataset '{kb.name}' is still being parsed."# 未解析且无分块if doc['run'] == TaskStatus.UNSTART.value and doc['chunk_num'] == 0:return False, f"Document '{doc['name']}' in dataset '{kb.name}' has not been parsed yet."return True, None
7.3 解析器配置深度更新
源码位置: knowledgebase_service.py:294-321
@classmethod@DB.connection_context()def update_parser_config(cls, id, config):"""更新知识库解析器配置(深度合并)"""e, m = cls.get_by_id(id)if not e:raise LookupError(f"dataset({id}) not found.")def dfs_update(old, new):"""深度更新嵌套配置"""for k, v in new.items():if k not in old:old[k] = vcontinueif isinstance(v, dict):assert isinstance(old[k], dict)dfs_update(old[k], v)elif isinstance(v, list):assert isinstance(old[k], list)old[k] = list(set(old[k] + v)) # 列表去重合并else:old[k] = vdfs_update(m.parser_config, config)cls.update_by_id(id, {"parser_config": m.parser_config})
配置合并示例:
# 原配置old_config = {"pages": [[1, 100]],"table_context_size": 0,"raptor": {"enabled": True, "max_depth": 3}}# 新配置new_config = {"pages": [[1, 200]],"image_context_size": 512,"raptor": {"max_depth": 5}}# 合并结果merged_config = {"pages": [[1, 200]], # 覆盖"table_context_size": 0, # 保留"image_context_size": 512, # 新增"raptor": {"enabled": True, "max_depth": 5} # 深度合并}
7.4 知识库创建流程
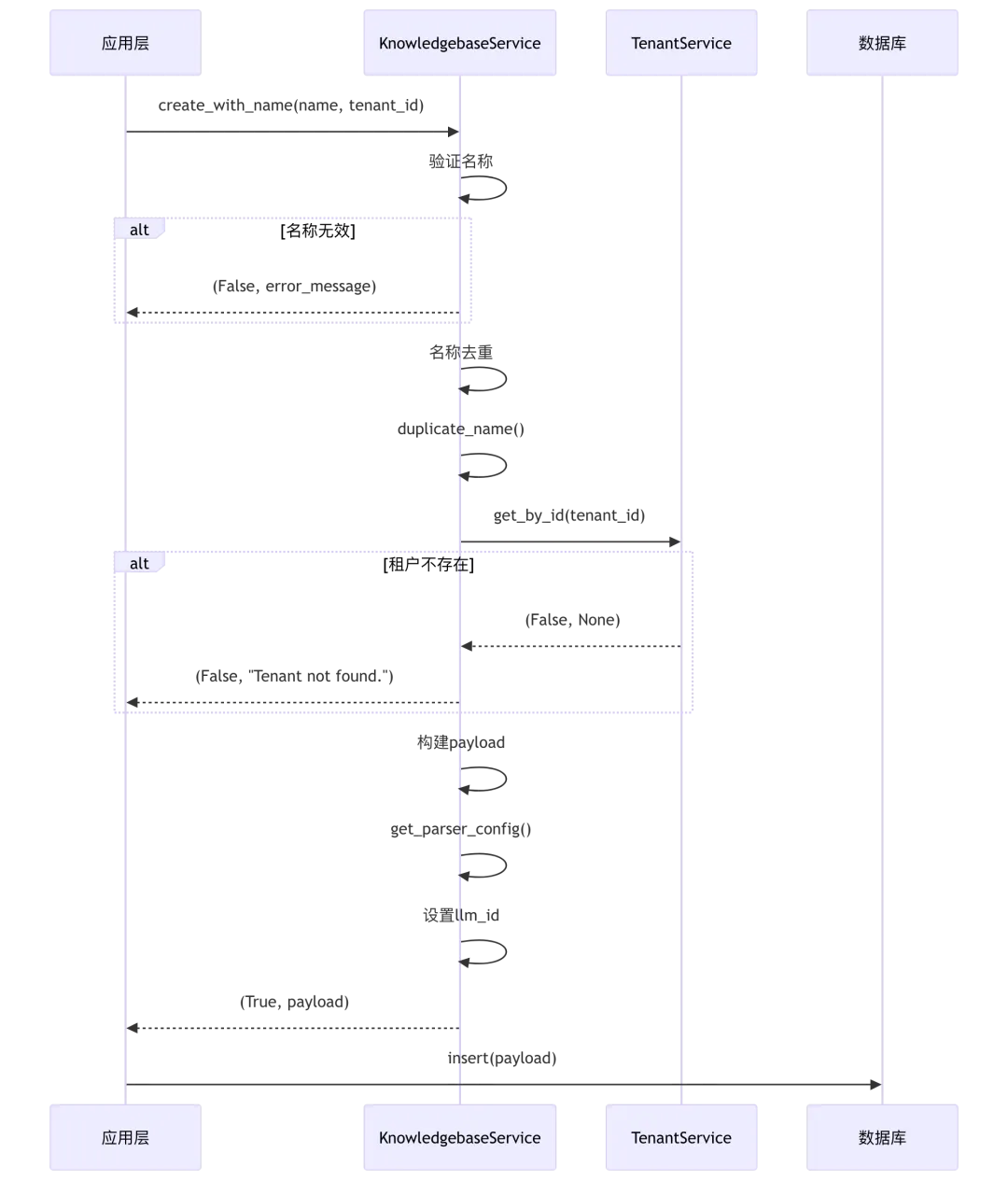
源码位置: knowledgebase_service.py:374-430
@classmethod@DB.connection_context()def create_with_name(cls, *, name: str, tenant_id: str, parser_id: str | None = None, **kwargs):"""创建知识库(包含验证和默认配置)"""# 验证名称if not isinstance(name, str):return False, get_data_error_result(message="Dataset name must be string.")dataset_name = name.strip()if dataset_name == "":return False, get_data_error_result(message="Dataset name can't be empty.")if len(dataset_name.encode("utf-8")) > DATASET_NAME_LIMIT:return False, get_data_error_result(message=f"Dataset name too long")# 名称去重dataset_name = duplicate_name(cls.query,name=dataset_name,tenant_id=tenant_id,status=StatusEnum.VALID.value,)# 验证租户ok, _t = TenantService.get_by_id(tenant_id)if not ok:return False, get_data_error_result(message="Tenant not found.")# 构建 payloadkb_id = get_uuid()payload = {"id": kb_id,"name": dataset_name,"tenant_id": tenant_id,"created_by": tenant_id,"parser_id": (parser_id or "naive"),**kwargs}# 设置解析器配置payload["parser_config"] = get_parser_config(parser_id, kwargs.get("parser_config"))payload["parser_config"]["llm_id"] = _t.llm_idreturn True, payload
八、DocumentService 深度解析
8.1 文档服务功能矩阵

8.2 文档删除复杂流程
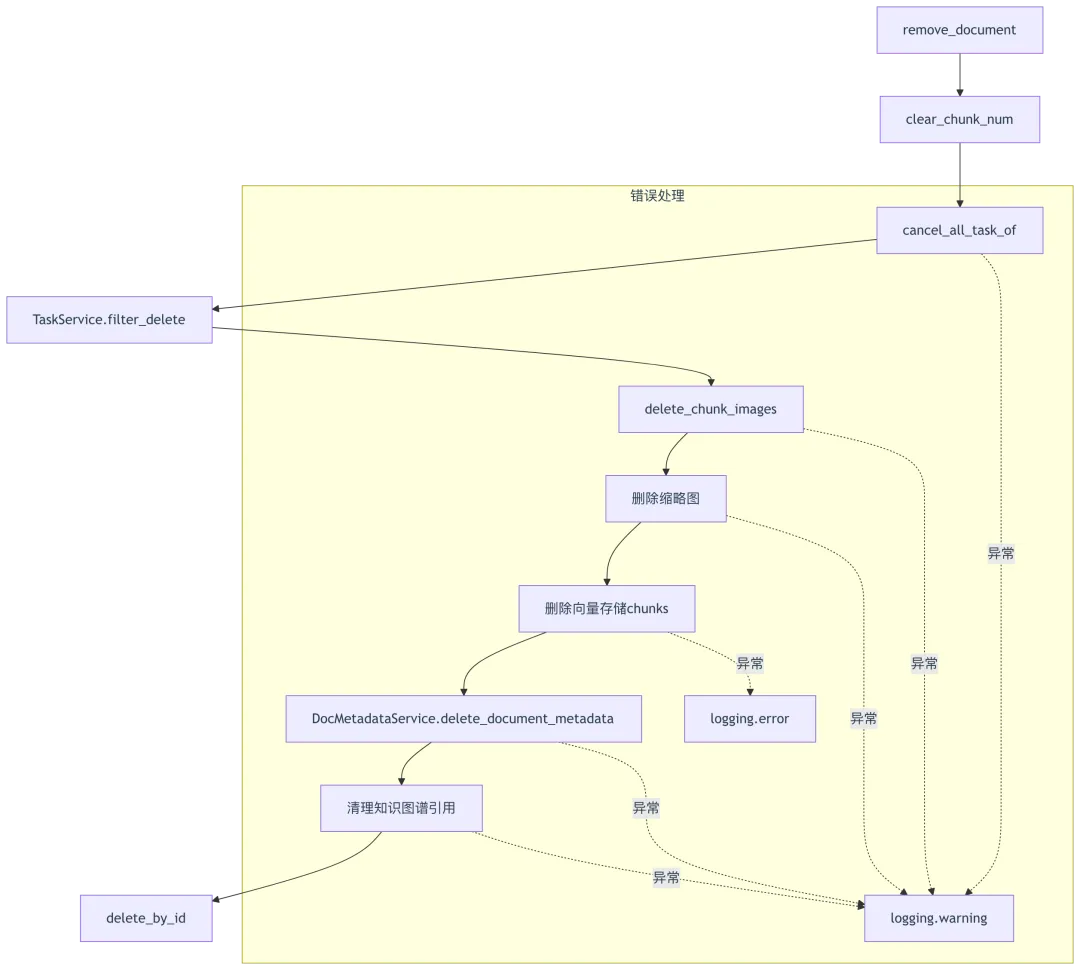
源码位置: document_service.py:360-422
@classmethod@DB.connection_context()def remove_document(cls, doc, tenant_id):"""删除文档及其所有关联数据"""from api.db.services.task_service import TaskService, cancel_all_task_of# 清空分块计数cls.clear_chunk_num(doc.id)# 取消所有运行中的任务try:cancel_all_task_of(doc.id)logging.info(f"Cancelled all tasks for document {doc.id}")except Exception as e:logging.warning(f"Failed to cancel tasks for document {doc.id}: {e}")# 删除数据库任务try:TaskService.filter_delete([Task.doc_id == doc.id])except Exception as e:logging.warning(f"Failed to delete tasks for document {doc.id}: {e}")# 删除分块图片try:cls.delete_chunk_images(doc, tenant_id)except Exception as e:logging.warning(f"Failed to delete chunk images for document {doc.id}: {e}")# 删除缩略图try:if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):if settings.STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):settings.STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)except Exception as e:logging.warning(f"Failed to delete thumbnail for document {doc.id}: {e}")# 删除向量存储中的chunks(关键操作)try:settings.docStoreConn.delete({"doc_id": doc.id},search.index_name(tenant_id), doc.kb_id)except Exception as e:logging.error(f"Failed to delete chunks from doc store for document {doc.id}: {e}")# 删除文档元数据try:DocMetadataService.delete_document_metadata(doc.id)except Exception as e:logging.warning(f"Failed to delete metadata for document {doc.id}: {e}")# 清理知识图谱引用try:graph_source = settings.docStoreConn.get_fields(...)if len(graph_source) > 0 and doc.id in list(graph_source.values())[0]["source_id"]:settings.docStoreConn.update(...)settings.docStoreConn.delete(...)except Exception as e:logging.warning(f"Failed to cleanup knowledge graph for document {doc.id}: {e}")return cls.delete_by_id(doc.id)
8.3 进度同步机制
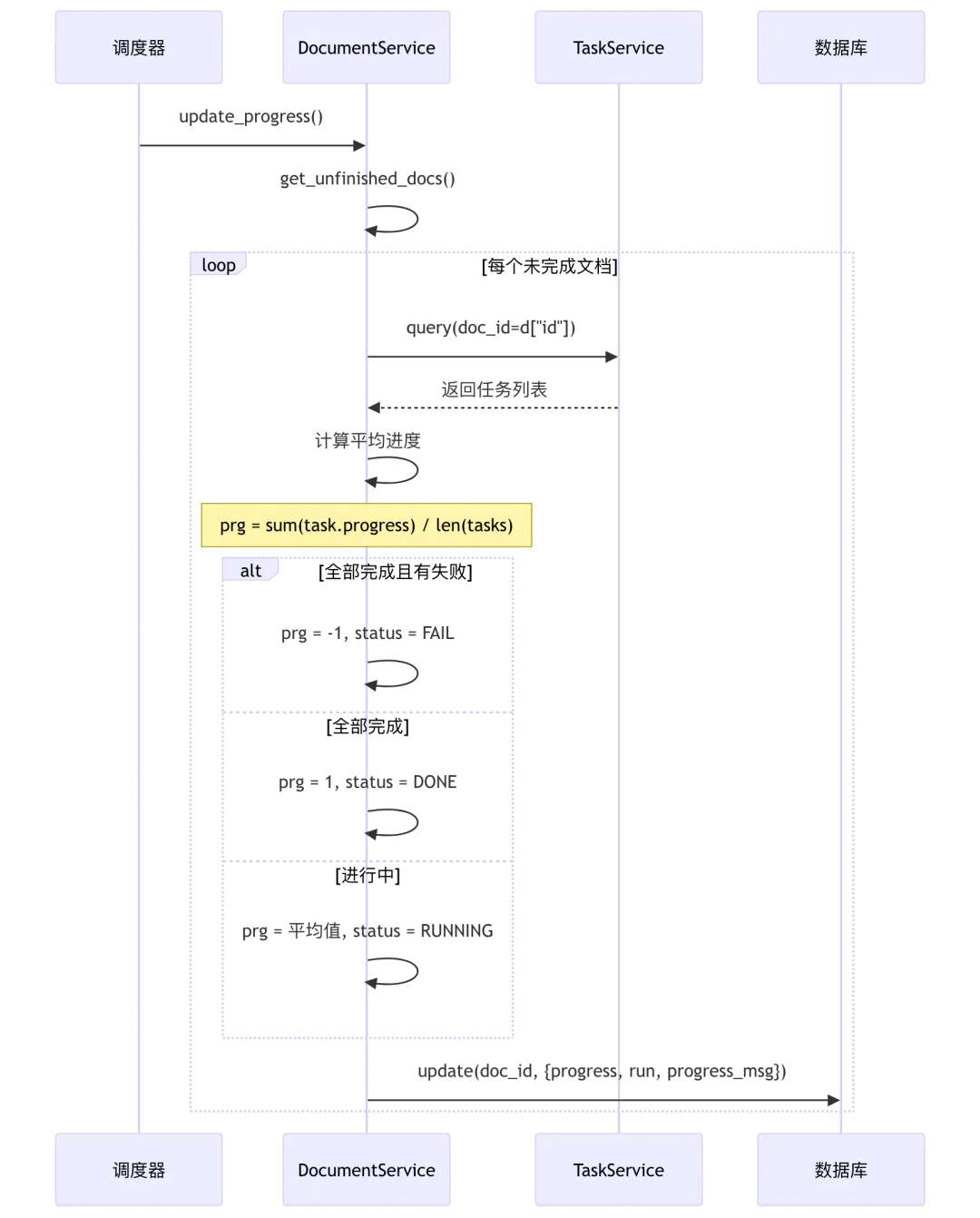
源码位置: document_service.py:755-828
@classmethod@DB.connection_context()def _sync_progress(cls, docs: list[dict]):"""同步文档进度"""from api.db.services.task_service import TaskServicefor d in docs:try:tsks = TaskService.query(doc_id=d["id"], order_by=Task.create_time)if not tsks:continuemsg = []prg = 0finished = Truebad = 0e, doc = DocumentService.get_by_id(d["id"])status = doc.runif status == TaskStatus.CANCEL.value:continuedoc_progress = doc.progress if doc and doc.progress else 0.0special_task_running = Falsepriority = 0for t in tsks:task_type = (t.task_type or "").lower()if task_type in PIPELINE_SPECIAL_PROGRESS_FREEZE_TASK_TYPES:special_task_running = Trueif 0 <= t.progress < 1:finished = Falseif t.progress == -1:bad += 1prg += t.progress if t.progress >= 0 else 0if t.progress_msg.strip():msg.append(t.progress_msg)priority = max(priority, t.priority)prg /= len(tsks)if finished and bad:prg = -1status = TaskStatus.FAIL.valueelif finished:prg = 1status = TaskStatus.DONE.value# 特殊任务进度冻结逻辑freeze_progress = special_task_running and doc_progress >= 1 and not finishedmsg = "\n".join(sorted(msg))begin_at = d.get("process_begin_at")if not begin_at:begin_at = datetime.now()cls.update_by_id(d["id"], {"process_begin_at": begin_at})info = {"process_duration": max(datetime.timestamp(datetime.now()) - begin_at.timestamp(), 0),"run": status}if prg != 0 and not freeze_progress:info["progress"] = prgif msg:info["progress_msg"] = msgif msg.endswith("created task graphrag") or \msg.endswith("created task raptor") or \msg.endswith("created task mindmap"):info["progress_msg"] += "\n%d tasks are ahead in the queue..." % get_queue_length(priority)else:info["progress_msg"] = "%d tasks are ahead in the queue..." % get_queue_length(priority)info["update_time"] = current_timestamp()info["update_date"] = get_format_time()(cls.model.update(info).where((cls.model.id == d["id"])& ((cls.model.run.is_null(True)) | (cls.model.run != TaskStatus.CANCEL.value))).execute())except Exception as e:if str(e).find("'0'") < 0:logging.exception("fetch task exception")
8.4 文档统计信息
源码位置: document_service.py:856-909
@classmethod@DB.connection_context()def knowledgebase_basic_info(cls, kb_id: str) -> dict[str, int]:"""获取知识库文档统计信息"""# 取消的文档数cancelled = (cls.model.select(fn.COUNT(1)).where((cls.model.kb_id == kb_id) & (cls.model.run == TaskStatus.CANCEL)).scalar())# 下载的文档数downloaded = (cls.model.select(fn.COUNT(1)).where(cls.model.kb_id == kb_id,cls.model.source_type != "local").scalar())# 完成数、失败数、处理中数row = (cls.model.select(# finished: progress == 1fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == 1, 1)], 0)), 0).alias("finished"),# failed: progress == -1fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == -1, 1)], 0)), 0).alias("failed"),# processing: 0 <= progress < 1fn.COALESCE(fn.SUM(Case(None,[(((cls.model.progress == 0) | ((cls.model.progress > 0) & (cls.model.progress < 1))), 1),],0,)),0,).alias("processing"),).where((cls.model.kb_id == kb_id)& ((cls.model.run.is_null(True)) | (cls.model.run != TaskStatus.CANCEL))).dicts().get())return {"processing": int(row["processing"]),"finished": int(row["finished"]),"failed": int(row["failed"]),"cancelled": int(cancelled),"downloaded": int(downloaded)}
九、设计模式总结
9.1 Active Record 模式
RAGFlow 服务层采用 Active Record 模式,每个服务类对应一个数据模型:
class KnowledgebaseService(CommonService):model = Knowledgebase # 绑定模型# 服务方法直接操作模型@classmethoddef get_detail(cls, kb_id):return cls.model.select(*fields).where(...)
优势:
简单直观,易于理解 减少代码重复 便于测试和维护
9.2 装饰器模式
数据库操作通过装饰器增强功能:
@DB.connection_context() # 连接上下文管理@DB.lock("init_database_tables", 30) # 分布式锁@retry_db_operation # 重试机制def init_database_tables(alter_fields=[]):pass
9.3 模板方法模式
CommonService 定义了 CRUD 操作的骨架,子类通过重写特定方法定制行为:
class CommonService:@classmethoddef insert(cls, **kwargs):# 模板方法:固定流程if "id" not in kwargs:kwargs["id"] = get_uuid()timestamp = current_timestamp()kwargs["create_time"] = timestamp# ... 子类可重写特定步骤return cls.model(**kwargs).save(force_insert=True)
十、性能优化策略
10.1 批量操作优化
# 批量插入(分批次)@classmethoddef insert_many(cls, data_list, batch_size=100):with DB.atomic(): # 事务包装for i in range(0, len(data_list), batch_size):cls.model.insert_many(data_list[i : i + batch_size]).execute()# 批量查询(分块)@classmethoddef filter_scope_list(cls, in_key, in_filters_list, filters=None, cols=None):in_filters_tuple_list = cls.cut_list(in_filters_list, 20) # 每次查询20条res_list = []for i in in_filters_tuple_list:query_records = cls.model.select().where(getattr(cls.model, in_key).in_(i), *filters)res_list.extend([query_record for query_record in query_records])return res_list
10.2 索引策略
所有关键字段都添加了索引:
class Knowledgebase(DataBaseModel):tenant_id = CharField(max_length=32, null=False, index=True) # 索引name = CharField(max_length=128, null=False, index=True) # 索引embd_id = CharField(max_length=128, null=False, index=True) # 索引create_time = BigIntegerField(null=True, index=True) # 索引
10.3 连接池配置
pool_config = {'max_retries': 5, # 最大重试次数'retry_delay': 1, # 初始重试延迟}database_config.update(pool_config)
