 夜雨聆风
夜雨聆风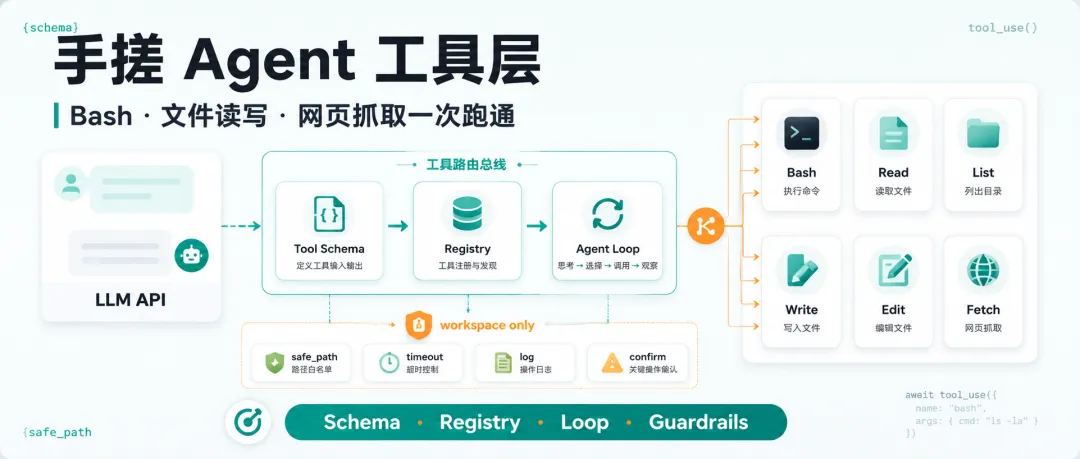
很多人第一次写 AI Agent,最后都会写成一个“带记忆的聊天壳”:接模型、读用户输入、把上下文塞回去,然后等模型回话。
这当然能跑,但没什么用。因为它只能“说”,不能“做”。
真正的 Agent 起点,不是换更强模型,也不是把 Prompt 写得更玄,而是给它一组能被调用的工具:跑命令、读文件、列目录、写文件、改文件、抓网页。只要这层搭起来,一个玩具聊天壳就开始变成可以操作电脑的执行系统。
这篇原文是一个“从零搭 Agent Harness”系列里的工具调用篇,发布时间是 2026-05-31,但最近仍在 Hacker News 上保持较高讨论热度。它适合拿来拆成一套更直接的实战路线:不依赖现成 Agent 框架,先把工具调用这层最小骨架写明白。
别再把 Agent 想成聊天框:没有工具,它什么都干不了
最小 Agent Harness 通常只有四块:
这套东西能回答问题,但它不能真正改变环境。
你问它“帮我读一下项目里有哪些文件”,如果没有工具,它只能猜。你让它“把结果写到 summary.md”,如果没有文件写入工具,它也只能嘴上说“已经完成”。
工具调用解决的就是这个断点:让模型从文本生成,进入可执行动作。
一个工具可以很简单,比如一个 Python 函数;也可以很复杂,比如一个 MCP Server、一个 HTTP API、一个数据库查询入口。关键不在形式,而在三件事:
这就是工具调用 Agent 的底层骨架。
先做 6 个基础工具,Agent 才算真正“有手”
如果你要写一个最小可用的本地 Agent,我建议先做这 6 个工具:
run_bash | ||
read_file | ||
list_files | ||
write_file | ||
edit_file | ||
fetch_url |
这里面最危险的是 run_bash。它很强,因为模型会用终端做很多事;它也很吓人,因为一旦权限失控,模型同样能删文件、改配置、跑未知脚本。
所以第一版可以让它跑,但别裸跑。至少要先限制工作目录、记录日志,并在危险命令上加人工确认。
下面给一个简化版工具定义思路:
这段代码不是生产级安全方案,只是最小骨架。真正上线前,run_bash 必须继续收紧,比如禁用 rm -rf、限制网络、限制环境变量、限制最大输出,甚至放进沙箱。
工具函数不够,还要把 Schema 喂给模型
模型不会自动知道你写了哪些 Python 函数。你必须把工具描述成它能理解的 Schema。
结构大概长这样:
写 Schema 时别省描述。很多工具调用失败,不是模型“笨”,而是 Schema 太含糊。
比如 edit_file 只写“edit a file”,模型很容易直接传一大段新文件内容。你要明确告诉它:这是局部替换,只替换第一个匹配片段;如果没找到旧文本,就会失败。
工具描述越具体,Agent 越少瞎猜。
用注册表把“模型想调用”变成“系统真执行”
有了工具函数和 Schema,还差一层注册表。
模型返回的不是 Python 函数调用,而是一个结构化请求:
你要把这个请求路由到真实函数:
这层看起来很普通,但它是工具调用 Agent 的安全边界。后面你要加日志、权限、确认、重试、超时、脱敏,基本都会加在这里。
我不建议把工具函数直接暴露给模型。中间一定要有一个可控执行层。
把工具塞进 Agent Loop,真正的执行闭环才开始
Agent Loop 的核心逻辑可以拆成四步:
伪代码大概是这样:
不同模型 SDK 的字段名会不一样,但思路一样:模型提出工具请求,程序执行工具,再把执行结果喂回去。
这一步跑通后,你的 Agent 就不再只是“回答”。它可以开始做事。
第一条测试任务:抓网页,再写成文件
别一上来就让 Agent 改项目代码。第一条测试任务最好可控一点:
一个正常工具调用链应该长这样:
如果它没先抓网页就直接写总结,说明模型在猜。
如果它抓了网页但写文件失败,说明文件工具或路径权限有问题。
如果它把内容写到了奇怪位置,说明 safe_path() 和工具描述还不够硬。
这类测试的价值在于,它能同时验证三件事:
fetch_url 和 write_file | |
别急着做复杂任务。工具调用层没稳,后面加规划、记忆、多 Agent 都是在堆风险。
真正的坑:工具越强,越要先设计刹车
从零手搓 Agent 很容易让人上头。跑通 run_bash 的那一刻,你会觉得它突然“活了”。
但这里千万别省安全设计。
至少补上这几类护栏:
尤其是 write_file 和 run_bash。这两个工具一旦给出去,Agent 就有了真实副作用。你可以让它用,但不能让它悄悄用。
我的建议是:第一版先让它“能做”,第二版立刻让它“可控”,不要等出事后再补。
总结:从聊天壳到 Agent,中间只差一个可控工具层
这篇教程最有价值的地方,不是某段代码多复杂,而是把 Agent 的核心拆得很干净:
只要这条链路跑通,你就能理解大多数 Agent 框架在底层做什么。
Claude Code、Codex、Cursor、Hermes Agent 当然更完整,但它们绕不开同一件事:模型必须知道有哪些工具,系统必须安全执行工具,执行结果必须回到上下文。
所以,别只停在“调 API”。自己手搓一遍工具调用 Agent,你会更清楚 Agent 为什么强,也会更清楚它为什么危险。
参考资料:
