 夜雨聆风
夜雨聆风1. 执行摘要与产业背景
在物理人工智能(Physical AI)与具身智能(Embodied AI)的发展进程中,核心瓶颈长期聚焦于两个维度:第一,现实世界高保真、多边缘场景训练数据的极度匮乏;第二,感知、认知与动作生成系统在传统架构中的极度割裂。2026年6月1日,NVIDIA 推出的 Cosmos 3 基础模型系列在架构层面系统性地回应了上述技术诉求。
Cosmos 3 被定义为专为物理 AI 设计的全模态(Omnimodal)世界模型。该系统摒弃了以往将视觉语言模型(VLM)、视频生成器、物理模拟器和动作策略模型作为独立模块进行串联的传统范式,转而采用统一的混合 Transformer(Mixture-of-Transformers, MoT)架构,在单一的神经网络前向传递过程中,实现对文本、图像、视频、音频及连续动作轨迹的联合处理与生成。
这种架构上的统一,使得 Cosmos 3 能够直接对物理环境的动态变化、因果关系和几何拓扑进行原生理解与模拟,从而将物理 AI 的训练、闭环仿真与策略评估周期从数月压缩至数天。为了推动从实验室研究到工业级落地的转化,该项目在 Linux 基金会的 OpenMDW-1.1 授权协议下,全面开源了模型权重、训练配方、合成数据集、数据清洗管道及自动化评估框架。本报告将客观、详尽地剖析 Cosmos 3 的底层算法机制、软硬件基础设施、工程落地范式及其在行业基准中的性能表现与技术局限。
2. 核心架构:混合 Transformer (MoT) 与多模态统一机制
Cosmos 3 的底层算法创新集中于其首创的混合 Transformer(MoT)架构。在传统的视频世界模型中,通常面临“不变性与可变性张力”(Invariance-Variance Tension)的矛盾:推理与理解任务需要提取高度抽象、抗干扰的不变特征,而高保真视频与物理模拟生成则需要保留高度细粒度的可变视觉细节。MoT 架构通过结构解耦与联合注意力机制,在单一骨干网络中化解了这一矛盾。
2.1 双塔层级结构 (Dual-Tower Layer Structure)
MoT 架构在每个 Transformer 层内部配置了针对不同模态与运行模式的专属专家参数,形成了物理上共享骨干、逻辑上并行的双塔结构。
推理塔 (Reasoner Tower - 自回归流): 构成了系统的“认知中枢”。该塔采用视觉语言模型(VLM)标准的自回归(Autoregressive, AR)序列处理机制。其核心任务是通过“下一个Token预测”(Next-token prediction)来解析输入文本、图像与视频的多模态上下文,建立物理实体的空间关系、运动轨迹的因果逻辑及时间连续性。
生成塔 (Generator Tower - 去噪扩散流): 构成了系统的“模拟中枢”。该塔采用去噪扩散(Denoising Diffusion, DM)序列机制。在接收到初始条件后,通过迭代去噪过程合成具有物理常识的像素级视频帧、环境音频及高维动作空间轨迹。
2.2 双流联合注意力机制 (Dual-Stream Joint Attention)
为防止双塔各自为战导致生成结果偏离物理逻辑,Cosmos 3 引入了双流联合注意力机制(Dual-Stream Joint Attention)。传统的跨注意力(Cross-Attention)机制通常是将文本提示的静态嵌入单向注入扩散模型;而 Cosmos 3 的联合注意力机制允许自回归推理分支与扩散生成分支在每个 Transformer 层级进行双向的动态信息交换。
这种设计确保了生成过程的强条件约束:推理塔对物理规律、物体恒常性和动作语义的深刻理解,被直接作为向导信号(Guidance)注入生成塔。因此,系统能够显著抑制生成模型常见的“物理常识幻觉”(如物体无故穿透、反重力漂浮),使得输出的视频或动作轨迹严格遵循现实世界的物理准则。
2.3 模态编码与连续隐空间 (Continuous Latent Space)
在输入端,Cosmos 3 必须将异构的数据类型映射到统一的表征空间中。
视觉与空间理解: 采用视觉 Transformer(ViT)架构对输入的图像和视频帧进行编码,提取密集的语义特征以供空间与物理推理。
视觉生成与量化: 为了提高生成塔的重建效率,系统使用了 Cosmos Tokenizer。该分词器利用变分自编码器(VAE)将原始高维像素数据映射为连续隐变量。根据技术文档披露,其量化前的连续隐空间张量形状为 (1, 6, 3, 64, 64),其中通道数
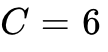 对应于 FSQ(Finite Scalar Quantization)层级,这种结构兼顾了极高的压缩率与细节保真度。
对应于 FSQ(Finite Scalar Quantization)层级,这种结构兼顾了极高的压缩率与细节保真度。动作轨迹与动力学: 机器人关节的运动学和动力学动作,通过领域感知的向量化技术处理为 1D 列表(JSON格式),随后投影入共享的隐空间,使模型能够在视觉表征与机械控制信号之间建立精确映射。
3. 全模态能力矩阵与系统运行拓扑
基于 MoT 架构,Cosmos 3 能够通过配置输入/输出张量组合,在一次前向传递中动态切换其物理 AI 功能节点。
3.1 推理模式:多模态物理理解
在推理模式下,模型依托自回归塔接收文本、图像或视频输入,输出结构化文本。其典型应用拓扑包括:
物理合理性验证: 分析给定的监控视频或合成数据,判断其中发生的物理碰撞、抛物线运动或刚体动力学是否符合自然规律。
空间基准与任务规划 (Spatial Grounding & Task Planning): 在复杂的 3D 具身环境中(如工厂车间),解析环境布局并为自主移动机器人(AMR)输出详尽的步骤级自然语言动作指令。
时序事件定位与因果预测: 在长时序视频流中精准定位特定异常动作,并基于当前帧推断环境的下一秒物理状态。
3.2 生成模式:物理世界仿真与合成数据生成 (SDG)
在生成模式下,扩散塔被激活,模型可执行如下转换以构建闭环数字孪生测试床:
文本/图像/视频到视频 (T2V/I2V/V2V): 给定初始帧或文本描述,生成具备时间连贯性的未来物理世界演化视频。这对于生成自动驾驶的长尾边缘场景(如罕见的极端车祸、恶劣天气下的光影变化)至关重要。
多条件控制生成: 借助 Cosmos Transfer 系统的 ControlNet 与 MultiControlNet 集成,模型能够接收深度图(Depth)、全景分割(Segmentation)、激光雷达点云(LiDAR)及高精地图(HDMap)等多种空间控制信号,在保持原有物理结构的前提下进行环境纹理、光照的域迁移(Domain Transfer)或天气数据增强。
3.3 世界-动作模型与机器人策略建模
将动作(Action)纳入统一模态,使 Cosmos 3 直接具备了作为闭环控制系统核心计算单元的能力。它能够原生求解动力学的基础方程:
前向动力学模型 (Forward Dynamics Model): 预测方程为
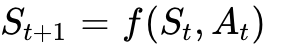 。输入当前视觉状态与机器人即将执行的动作序列,模型输出该动作执行完毕后的未来视频帧。该能力被广泛用于模型预测控制(MPC)和无碰撞轨迹仿真。
。输入当前视觉状态与机器人即将执行的动作序列,模型输出该动作执行完毕后的未来视频帧。该能力被广泛用于模型预测控制(MPC)和无碰撞轨迹仿真。逆向动力学模型 (Inverse Dynamics Model): 推断方程为
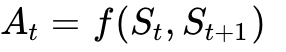 。给定起始帧和目标结果帧,模型逆向推导需要何种动作轨迹才能实现该状态转换。这是具身智能中模仿学习(Behavioral Cloning)和专家轨迹抽取的关键。
。给定起始帧和目标结果帧,模型逆向推导需要何种动作轨迹才能实现该状态转换。这是具身智能中模仿学习(Behavioral Cloning)和专家轨迹抽取的关键。视觉-语言-动作策略 (VLA Policy): 直接摄取第一人称(Egocentric)摄像头画面与任务提示,实时输出低延迟的机器人控制指令,实现端到端的控制论闭环。
4. 模型矩阵与硬件级规范限制
为了适应从数据中心的大规模合成数据生成,到边缘设备严格的实时控制延迟要求,Cosmos 3 序列被战略性地划分为不同参数量级的变体。
表 1:Cosmos 3 模型变体与硬件部署要求矩阵
模型变体 | 总参数量 | 推理塔参数 | 生成塔参数 | 目标硬件微架构与部署场景 | 核心应用范式 |
Cosmos 3 Super | 64B | 32B | 32B | 数据中心级:NVIDIA Hopper (H100/H200), Blackwell (GB200) | 大规模物理合成数据生成(SDG)、离线强化学习环境模拟、极高保真度物理常识推理。 |
Cosmos 3 Nano | 16B | 8B | 8B | 工作站级:NVIDIA RTX PRO 6000 | 高效实时具身智能推理、机器人视觉运动控制闭环、工厂级边缘视频流并发分析。 |
Cosmos 3 Edge | ~4B | 暂缺 | 暂缺 | 嵌入式与单板计算机:NVIDIA Jetson Thor | (即将发布)具备极低延迟要求和功耗限制的移动机器人实体端侧实时推理控制。 |
4.1 张量输入限制与边界条件
混合 Transformer 必须在有限的显存中处理庞大的时空上下文,Cosmos 3 Super 设定的架构极限和建议输入参数如下:
文本流: 上限 4096 个 Token。
视频与图像流: 支持 256p, 480p, 720p 分辨率,兼容 16:9, 4:3, 1:1, 3:4, 9:16 等非标高宽比。对于视频输入,最大支持 5 帧密集上下文,为保证时间感受野,官方推荐采样帧率为 4 fps。
音频流: 最大支持 0.5 秒的环境声学上下文。
动作轨迹流: 动作序列长度支持 16 至 400 个视频帧对应的时间跨度。
5. 训练数据体系与合成数据生成 (SDG) 引擎
世界模型的泛化能力与遵循物理法则的能力,从根本上受制于其预训练语料库的广度与质量。Cosmos 3 的底层预训练数据集总规模达到 13 亿个多模态数据点,涵盖了 393 个独立的子数据集,数据采集时间跨度从 2024 年持续至 2026 年。这其中包含了海量的无监督自然视频、文本对、环境音频以及极其昂贵的机器人真实遥操作(Teleoperation)动作轨迹。
然而,物理 AI 研发的核心痛点在于真实数据中严重缺乏极端情况(长尾场景)。为了突破真实数据的获取瓶颈,Cosmos 3 本身被设计为强大的合成数据生成(SDG)引擎。为加速开源社区研究,NVIDIA 在 Hugging Face 平台上同步释放了 6 个经过高度清洗与标注的合成物理环境数据集:
表 2:开源物理 AI 合成数据集 (Physical AI SDG Datasets)
数据集名称 | 领域聚焦 | 数据集特性与物理标定维度 |
SDG-RobotSim (Embodied-Robot-Scenes) | 机器人学 | 包含人形机器人与机械臂在不同纹理与光照环境下执行复杂抓取、装配与避障任务的合成仿真数据。 |
SDG-PhyxSim (Physical-Interaction-Scenes) | 物理定律计算 | 源自 Isaac Sim 的绝对物理正确数据。涵盖破碎球撞击、多米诺骨牌倒塌、塔状物崩塌等场景,带有精确的逐对象速度向量(Velocity)和质心位移(Center-of-mass displacement)的地面真实标注。 |
Spatial-Reasoning | 空间感知 | 构建了复杂的 3D 几何拓扑空间,专门用于训练和评估模型的空间关系映射与深度理解能力。 |
Digital-Human-Scenes | 生物力学 | 包含高质量的合成人类动作捕捉数据,用于自动驾驶中行人意图预测及智能空间中的人机工程学交互分析。 |
Autonomous-Driving-Scenarios | 自动驾驶 | 自动驾驶多视角仿真数据,模拟极端光照、天气突变及动态交通流干扰。 |
Warehouse-Operations-Scenes | 工业自动化 | 仓储物流环境下的合成数据,聚焦于多智能体路径冲突、工业危害检测及安全合规性分析。 |
6. 训练配方与分布式优化机制
将视觉解码器、自回归 VLM 和扩散模型在一个架构下联合优化,构成了极端的工程挑战,因为它们的基础学习目标和权重对齐状态存在本质差异。Cosmos Framework 提供了全套的微调与预训练开源脚本。
6.1 预训练与监督微调 (SFT) 的梯度下降策略
根据技术报告与相关文献,Cosmos 3 在视觉辅助解码器的自监督预训练和后续的 SFT 阶段,采用了一套严格的超参数调度策略。
优化器与内存管理: 模型训练广泛采用 8-bit Adam 或 AdamW 优化器以大幅度压缩优化器状态在 GPU 显存中的占用。设置
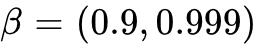 ,
,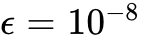 。
。学习率调度: 基础学习率(Learning Rate)通常被设定在
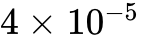 到
到 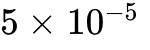 的狭窄区间内,并配合 100 步的线性预热(Warm-up)。在使用梯度下降和 Focal Loss 应对不平衡数据时,学习率可能采取指数衰减策略。
的狭窄区间内,并配合 100 步的线性预热(Warm-up)。在使用梯度下降和 Focal Loss 应对不平衡数据时,学习率可能采取指数衰减策略。批处理与序列长度: 在训练视频扩散生成时,标准批次大小(Batch Size)配置为 64。对于机器人动作轨迹,为了匹配 Droid 和 Bridge 等开源数据集的统计特征,训练的最大帧数被分别截断为 33 帧或 49 帧,以优化分布式计算时的负载均衡。
6.2 强化学习与 SFT 的过拟合风险控制
Cosmos RL 框架专门用于物理 AI 的分布式策略展开(Policy Rollout)与强化学习。然而,在长周期的 SFT 阶段,MoT 架构面临显著的过拟合风险。工程实测表明,虽然 SFT 能在初期迅速提升生成视频的色彩质量与美学质感,但过度的 SFT 会导致模型向静态美学坍缩,进而导致“指令遵循能力”(Prompt-following ability)退化,以及物理运动连贯性的严重破坏。因此,训练过程需依赖严格的提前停止(Early Stopping)策略和大规模评估矩阵来实施正则化干预。
7. 数据工程与自动化评估基础设施
物理世界模型对预训练数据的纯净度要求极高。为此,生态系统中部署了两大关键的自动化引擎。
7.1 Cosmos Curator:Ray-架构的流式数据清洗
Cosmos Curator 是一个基于 Ray 分布式框架(Cosmos-Xenna)构建的 GPU 加速视频流式清洗引擎。它不仅负责传统的解码与切片,还集成了复杂的异常值剔除算法。系统通过提取视频的表征轨迹(Embedding Trajectories),并运用基于时序的 K-均值聚类(Time Series K-Means),结合 Soft-DTW(动态时间规整)距离度量,在百亿规模的数据集中自动化筛除损坏帧、物理逻辑断裂和运动模糊的劣质视频数据。
7.2 Cosmos Evaluator:机器级合成数据质量核查
人工标注和评分无法应对海量合成视频的质量验证需求。Cosmos Evaluator 提供了一个全自动的微服务 REST API 框架,利用大语言模型和视觉基础模型对生成结果进行结构化评分。
幻觉检验 (Hallucination Check): 提取原始视频与生成视频的光流和运动掩码进行像素级比对,侦测生成视频中是否出现了本不该存在的“幻觉”运动物体,或丢失了关键的实体特征。
障碍物一致性核验 (Obstacle Check): 评估生成视频中的交通基础设施、车辆和行人的位置坐标,是否与世界模型的预期物理状态(Ground Truth)发生偏移。
VLM 预设验证 (VLM Preset Check): 使用辅助 VLM 交叉验证生成的场景是否严格遵循了用户输入的地理约束、时间约束及天气约束条件。
8. 推理部署与 Cosmos Cookbook 行业应用范式
模型的商业价值最终取决于其在推理期的计算效率与场景适配度。
8.1 vLLM-Omni 与 EVS 吞吐优化
在 Python 原生研发环境中,开发者可直接调用 Hugging Face Diffusers 库中的 Cosmos3OmniPipeline 进行开发,模型支持在 BF16 精度下运行。但对于数据中心级生产环境,NVIDIA 提供了基于 vLLM 构建的 vLLM-Omni 推理栈。
该引擎集成了分页注意力(Paged Attention)、连续批处理(Continuous Batching)和张量并行(Tensor Parallelism)技术。面对视频推理时海量 Token 导致显存溢出的问题,vLLM-Omni 独创了高效视频采样 (Efficient Video Sampling, EVS) 技术。EVS 在视频块(Chunk)级别运行,通过动态计算余弦相似度,仅保留包含显著时空变化的最独特块,并修剪掉视觉冗余块。这一机制大幅降低了输入 VLM 的 Token 数量,使得 Cosmos 3 Nano 即便在显存受限的 GPU 上也能实现极高的推理吞吐率。同时,模型支持降级为 4-bit 浮点精度,进一步提供高达 2 倍的推理加速。
8.2 Cosmos Cookbook:行业微调解决方案库
Cosmos Cookbook 作为一个开源的范例仓库,为开发者提供了如何将基础模型迁移至具体物理环境的操作手册。其涵盖的核心应用范式包括:
自动驾驶领域的 CARLA Sim2Real: 自动驾驶模拟器(如 CARLA)的原始画面缺乏真实世界的纹理和光照质感。开发者通过微调 Cosmos Transfer 组件,将 CARLA 的语义分割图和深度图作为控制信号输入,直接渲染出具备照片级真实感(Photorealistic)且符合物理碰撞逻辑的罕见交通异常视频,用于训练自动驾驶感知系统。
机器人领域的 GR00T-Dreams: 这是针对人形机器人的端到端数据合成管道。通过在真实的机器人演示数据(如 GR1 数据集)上对 Cosmos Predict 进行 SFT 后训练,模型可以凭空合成大规模的机器人作业轨迹,随后交由 Cosmos Reason 充当“视频评委(Video Critic)”进行拒绝采样(Rejection Sampling),筛选出合规的轨迹。
外科学领域的动作仿真: 医疗领域严禁在活体上试错。通过微调 Cosmos,使其成为条件动作化的手术仿真器(Action-conditioned surgical simulator),外科手术机器人的控制策略可以在这个逼真的生成世界中进行无限制的安全评估。
智能制造与仓储安全: 在传统物流环境中,零样本(Zero-shot)部署 Cosmos Reason 对监控视频流进行并发处理,实现对工人违规操作、安全帽佩戴情况及潜在坠物危险的自动化侦测与逻辑推理。
9. 物理 AI 核心能力与基准测试表现 (Benchmarks)
在评估物理世界模型时,传统的视觉质量指标(如 FID, FVD)已无法全面反映模型对物理法则的掌握程度。Cosmos 3 经历了业界最严苛的物理验证套件的洗礼,在多个排行榜中实现了对开源竞品的全面压制,甚至在核心指标上逼近或超越了专有闭源大模型。
表 3:Cosmos 3 核心基准测试表现体系
评测维度 | 基准测试套件 | 评估机制与 Cosmos 3 的表现地位 |
视觉与物理推理 | VANTAGE-Bench | 首个针对真实世界固定摄像头(仓储、交通、智能空间)视觉语言模型理解能力的基准。Cosmos 3 Super (32B) 与 Nano (8B) 均在其参数量级中取得开源系统第一。 |
异常检测与时空逻辑 | TAR (Traffic Anomaly Reasoning) | 专门评估交通录像中异常事件的侦测与归因推理能力。Cosmos 3 领跑该榜单,并被确立为 2026 年 AI City Challenge Track 3 的官方标杆基准。 |
物理定律保真度 | Physics-IQ | 摒弃视觉表象,专门测试模型对重力、碰撞动量转移、流体动力学等底层物理定律的理解。Cosmos 3 克服了隐式记忆模型的局限,在开放权重模型中位列第一。 |
高质量世界生成 | Artificial Analysis | 综合性的全球 AI 模型生成质量榜单。Cosmos 3 在“文本到图像”与“图像到视频”双赛道摘得开源领域桂冠,展现出卓越的美学与结构一致性。 |
机器人动作与控制 | R-Bench / PAI-Bench | R-Bench 评估生成机器视频的任务完成度与执行完整性;PAI-Bench 则跨领域评估自动驾驶与机器人的视频生成与理解。Cosmos 3 实现了 SOTA。 |
泛化策略执行 | RoboLab / RoboArena | 测试任务通用型机器人的策略执行。搭载了 Cosmos 3 Nano-Policy-DROID 检查点的系统在此项闭环仿真中夺得最佳策略模型称号。 |
10. 系统局限性与潜在失效模式 (Failure Modes)
客观而言,尽管 Cosmos 3 确立了新的技术基准线,但由于混合 Transformer 架构内自回归与扩散模型的内生数学局限性,它在极端的长视界和高复杂度任务中依然存在特定的失效模式。
10.1 生成伪影与时空一致性崩塌
生成塔在长时间维度的外推生成中容易产生系统性误差积累。
状态与动作漂移 (Action-State Drift): 当模型作为前向动力学模型执行超长序列动作的预测时,微小的像素级预测误差会在自回归迭代中呈指数级放大。这最终会导致视频后半段的物理状态发生扭曲(例如机器人关节逐渐形变脱臼,或目标物体的几何结构扭曲)。
物体恒常性丧失 (Temporal Inconsistency): 在脱离短程上下文窗口后,模型可能“遗忘”被短暂遮挡的物体,导致背景元素或运动实体发生突兀的消失或凭空生成。
音视频时间轴失步 (A/V Desynchronization): 尽管原生支持音频,但针对高度瞬态的物理交互(如金属撞击的瞬间),视频帧的形变与音频脉冲在时间轴上实现毫秒级的绝对同步仍面临挑战。
10.2 认知幻觉与逻辑阻断
推理塔在处理极高复杂度信息熵的输入时,同样暴露出缺陷。
底层机制的误判: 面对表面纹理相似但内部拓扑复杂的场景,模型有时会误推因果关系、隐藏空间的几何结构或视频中人类意图的走向。
长上下文坍塌: 当输入极端冗长且结构复杂的长篇文本提示,并夹杂多帧快速运动的视频片段时,模型可能陷入认知过载,输出自相矛盾的解释或彻底“幻觉”出源数据中不存在的实体特征。
物理精度与视觉美学的对抗: 物理 AI 要求必须严谨遵循包围盒(Bounding Box)和动力学规律,这有时迫使生成模型在局部舍弃摄影级的光影美感与艺术张力。这种“为求物理正确而牺牲视觉华丽”的现象,是工业级应用中必须妥协的特性。
11. 法理框架、知识产权与 Cosmos 联盟生态
AI 基础模型的广泛商用面临极其严峻的法律挑战,Cosmos 3 在开源合规路径上做出了历史性的范式转移。
11.1 OpenMDW-1.1 授权协议的法理突破
长期以来,学术界与工业界习惯使用传统的开源软件(OSI)协议(如 Apache 2.0 或 MIT)来发布模型权重。然而,这些协议诞生于代码时代,专门针对“源代码”和“目标代码”设计。神经网络模型的核心资产——权重(Weights)、偏置(Biases)与参数矩阵,在法理上属于“数据结构(Data)”而非“软件代码”。将软件协议生搬硬套到数据之上,导致了数据隐私、道德约束与知识产权归属的巨大法律真空与灰色地带。
为了彻底解决这一痛点,NVIDIA 联合 Linux 基金会,将 Cosmos 3 (以及 Isaac GR00T, Nemotron 等家族模型)的许可框架全面迁移至专为模型开放框架(Model Openness Framework, MOF)制定的 OpenMDW-1.1 (Open Model, Data and Weights) 协议。该宽容性许可协议构建了一个严密的统一法理框架,明确界定并分类授权了 AI 释放的三个核心组件:
代码资产: 模型架构、训练脚本与推理代码,适用 OSI 认可的协议逻辑。
数据资产: 模型参数权重、数据集、评估元数据,适用具备数据特定考量的开发协议。
文档资产: 技术报告、模型卡片(Model Cards),以类似知识共享的规则管理。
这一协议的采用,使得商业公司、机器人初创团队和自动驾驶车企能够在一个单一、明确的、以模型为中心的合规性框架下,自由地训练、修改、商业再分发 Cosmos 3 的各项资产,彻底清除了将模型推向生产环境的法律定时炸弹。
11.2 产业聚变:Cosmos 联盟 (Cosmos Coalition)
基础设施的成功依赖于生态标准的统一。NVIDIA 在发布 Cosmos 3 的同时,宣布成立了面向全球的 Cosmos 联盟 (Cosmos Coalition)。该联盟的创始成员汇聚了全球顶尖的 AI 实验室与具身智能开拓者,包括 Agile Robots, Black Forest Labs, Generalist, LTX, Runway 以及 Skild AI。
Cosmos 联盟的核心主旨是抵制物理 AI 研究领域的碎片化(Fragmentation)趋势。通过在开放、共享的技术栈内协作,联盟成员承诺共同贡献基础模型权重、研究成果及评估标准化技术;并依托共享的庞大算力基础设施,加速跨平台互操作性标准的制定。目前,不仅是联盟创始成员,包括三星、LG 电子、斗山机器人以及理想汽车等跨国巨头,均已在自主系统与视觉 AI 应用中规模化部署了 Cosmos 平台技术。
12. 结论
Cosmos 3 全模态世界模型的问世,标志着物理人工智能的底层技术架构发生了一次断代式的跃进。该系统以极为优雅的混合 Transformer (MoT) 双塔架构与联合注意力机制,从根源上消解了视觉认知模型与去噪生成模型之间的结构性鸿沟,成功将语义理解的不变性与像素生成的可变性熔铸于同一计算图之中。
通过针对性发布的 64B Super 到适配端侧推理的 Edge 级变体矩阵,辅以极大降低显存壁垒的 vLLM-Omni 推理栈及全面的合成数据生成 (SDG) 库,Cosmos 3 系统性地击穿了长期制约具身智能与自动驾驶产业的数据匮乏与长尾仿真痛点。
尽管在超长视界预测状态漂移与认知信息熵过载等前沿领域,目前的深度学习数学范式仍展现出其固有局限性,但 Cosmos 3 所奠定的闭环世界仿真架构、通过 OpenMDW-1.1 协议肃清的商业化法理障碍,以及 Cosmos 联盟所凝聚的行业标准力量,已经为构建下一代能够深度感知、精准模拟并与现实物理世界无缝交互的自主代理网络,夯实了不可逆转的技术与生态地基。
