 夜雨聆风
夜雨聆风承接上一篇《资深前端:不内卷、不躺平,我的 AI 转型稳健进阶规划》,本篇复盘我转型第一阶段的知识落地成果。按照既定成长路线,我完成机器学习与深度学习底层理论系统化自学,抛开前端长期只做页面开发、接口调用的固有思维,从算法逻辑根源补齐 AI 知识短板,为后续全栈落地大模型、端侧 AI 项目筑牢地基。
一、首阶段知识复盘:逐层搭建 AI 基础知识体系
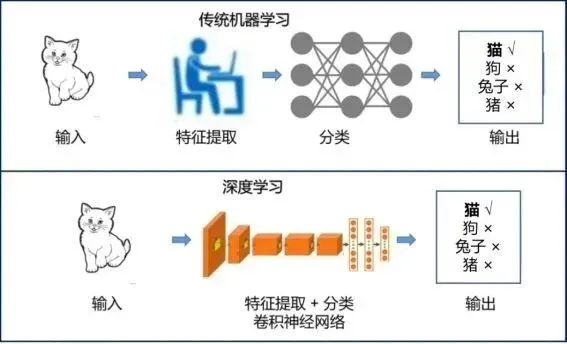
依托自身规划的学习脉络,本轮学习完整覆盖机器学习分类逻辑、神经网络整套原理、深度学习工程落地三大板块内容:
1. 厘清机器学习三大核心学习范式,锚定算法落地业务逻辑
系统梳理监督学习、无监督学习、半监督学习三类主流算法逻辑与落地边界。
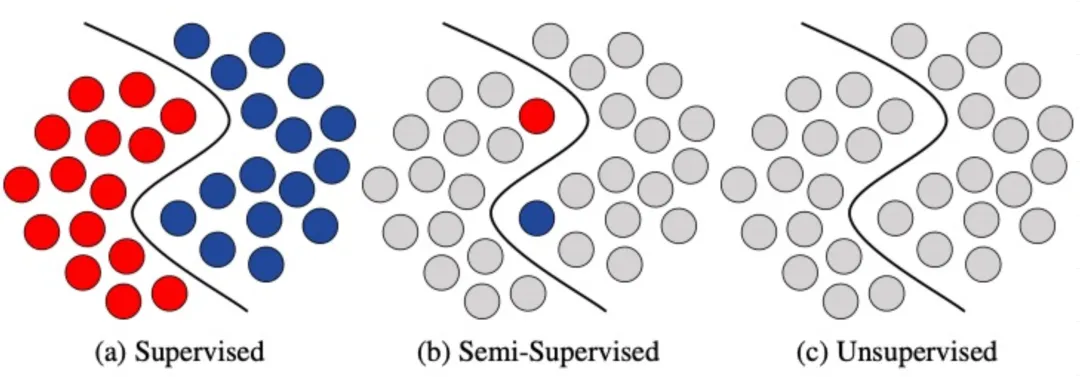
- 监督学习:掌握带标注数据集的训练逻辑,理解分类、回归类算法的适用场景,结合过往前端做过的智能表单、用户行为预测、产品推荐等业务,打通算法逻辑和前端业务的关联,明白市面上智能化前端产品背后的数据训练逻辑;
- 半监督学习:熟悉少量标注数据搭配海量原始数据的训练方案,理解当下企业低成本落地 AI 产品的主流思路,契合中小厂 AI 产品轻量化落地的行业现状。
- 无监督学习:吃透无标签数据的聚类、降维原理,对应用户分群、内容智能归类等产品场景,跳出前端视角看懂平台用户画像类功能的底层实现;
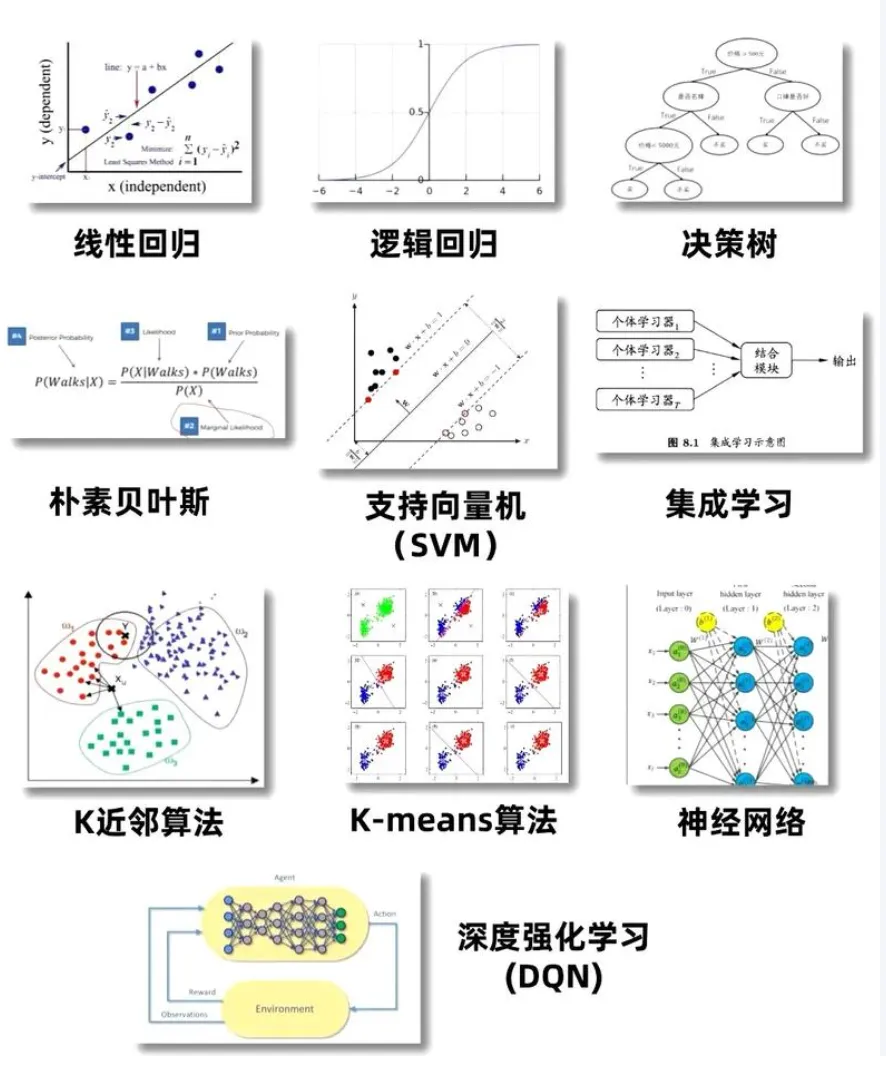
十大机器学习算法
过往做前端开发时,我只能对接现成 AI 接口做页面封装,如今可以从数据训练角度,预判一项 AI 功能能否落地、适配哪种数据方案。
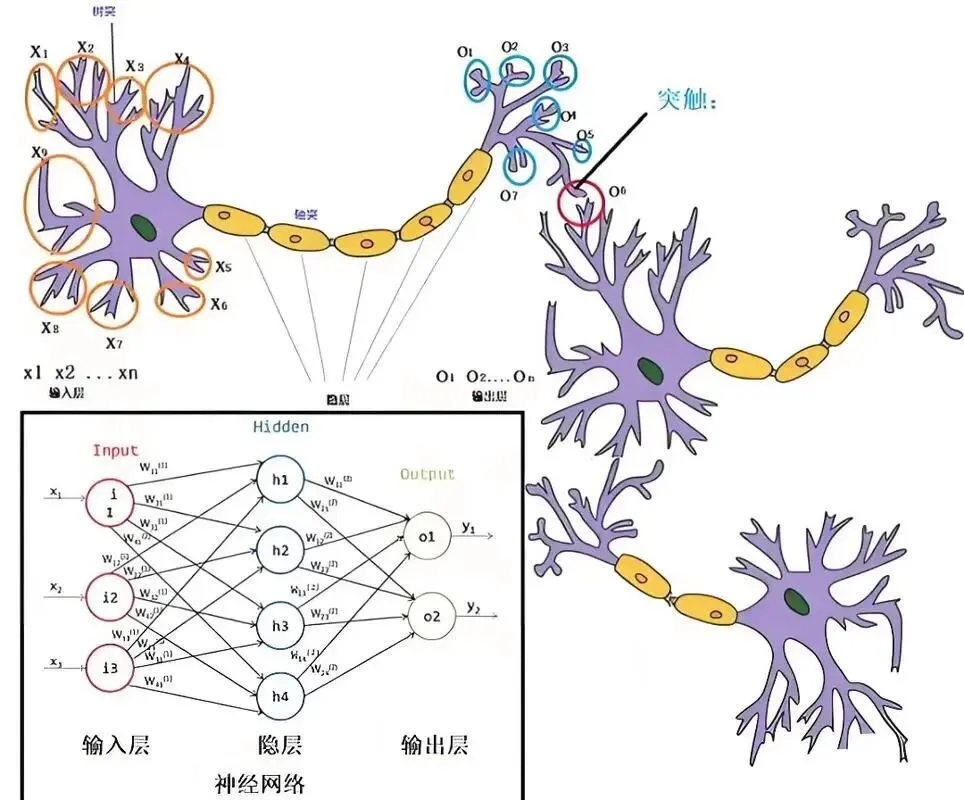
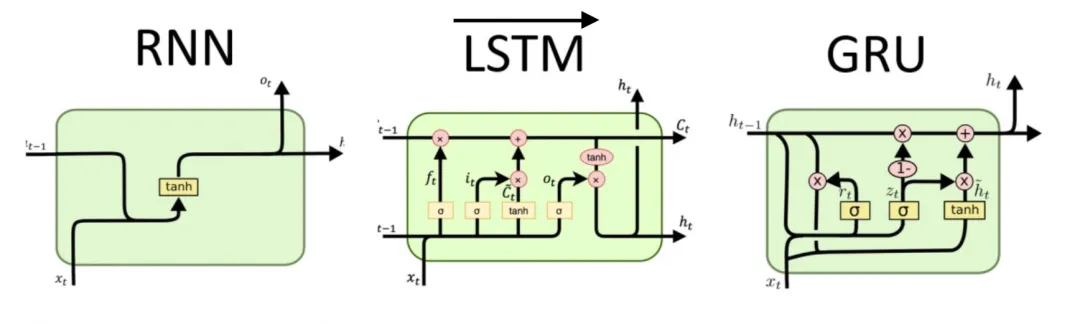
2. 深挖神经网络全链路原理,搞懂 AI 模型的运行本质
这是本阶段学习的核心重点,完整吃透神经网络从最小单元到训练迭代的整套逻辑:
从单个神经元的运行规则入手,逐一吃透 Sigmoid、ReLU 等主流激活函数的作用、优劣与选型场景;顺着网络运行逻辑,理清前向传播、反向传播整套运算机制,搞懂模型如何正向输出预测结果、如何依靠损失反向更新权重参数,彻底解开模型训练收敛、Loss 下降的底层原理。
3. 熟悉深度网络架构与深度学习生态,衔接前端工程优势
一方面拆解经典深度神经网络的架构设计思路,理解不同网络结构的设计目的与适配场景;另一方面梳理当下主流深度学习框架生态,摸清 PyTorch、TensorFlow 等工具的定位与适用方向。
一些经典的深度神经网路架构包括卷积神经网络 (CNN)、循环神经网络 (RNN)等。
卷积神经网络 (CNN)是利⽤卷积层和池化层构建层级化的特征提取器。
卷积:提取局部特征
池化层:逐步减⼩特征图的空间尺⼨


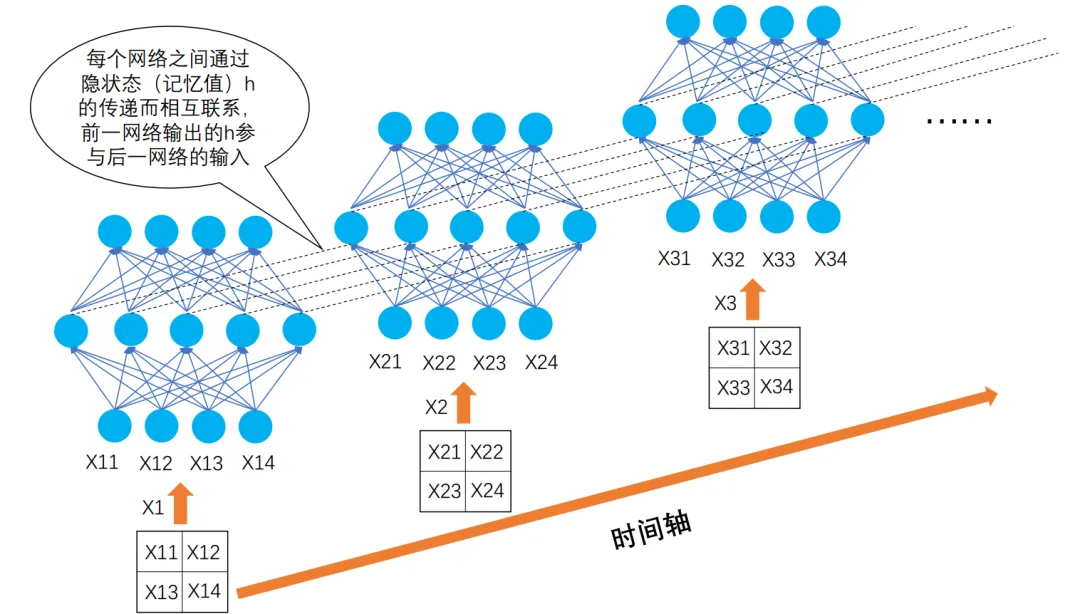
循环神经网络 (RNN)是处理序列数据(文本、语音、时间序列),利用隐藏状态传递历史信息。
关于深度学习框架,什么是深度学习框架?它提供了一套用于构建、训练和部署深度学习模型的软件库和工具。
为什么需要框架?隐藏底层复杂性(如自动微分、GPU 计算),提供丰富的预定义层、优化器、损失函数等,预训练模型,提供模型导出、转换和部署工具。
一些主流深度学习框架:
PyTorch:凭借其灵活性和研究社区的喜爱,在 LLM 研发中占据主导地位。并且在学术界和研究领域比较普及。
TensorFlow (2.x):引入 Eager Execution (动态图),整合 Keras。在工业界仍有大量应用,但 LLM 前沿研究声量相对减弱。生态依然强大。
JAX:Google 出品,面向高性能数值计算和机器学习研究。特点:函数式编程风格,强大的自动微分、自动向量化(vmap)、并行化(pmap)。优势:在 TPU 上表现优异,适合大规模模型研究和训练。常与 Flax/Haiku (神经网络库) 配合使用。
关于核心生态组件(训练) - Hugging Face Transformers:
已成为事实上的大模型“操作系统”/核心枢纽。
支持 PyTorch, TensorFlow, JAX 后端。
极大降低了使用、分享和训练大模型的门槛。
在大模型时代,需要了解 CNN、RNN 等深度神经网络架构,及之后需要专项学习的 Transformer 网络架构,也要掌握一些主流深度学习框架和 Hugging Face 分布式训练核心生态库。在了解深度学习底层技术的基础上,能够使用框架生态实现模型训练、推理、应用服务。
作为前端开发者,我的核心优势在工程落地,弄懂框架生态后,顺利打通「算法模型→模型导出→前端部署」的链路逻辑,找准自身 AI 全栈的差异化切入点。
二、贴合稳健转型规划:为何优先深耕理论,暂缓项目速成?
遵循我此前定下的不内卷、不躺平的转型原则,刻意避开当下 “几天速成 AI、上手做项目” 的浮躁路线,优先夯实底层理论有三点核心考量:
- 当下环境转型容错率有限,拒绝碎片化学习当下职场环境试错成本高,零散学提示词、跟风调用大模型,只能做浅层 Demo,无法支撑跳槽 AI 全栈岗位。系统化吃透底层理论,后续学习大模型、RAG、Agent 开发时能举一反三,大幅压缩后续实战的试错周期。
- 扬长避短,打造前端专属 AI 竞争力
纯算法岗位学历、数学内卷严重,普通前端又困在页面 CRUD 的同质化竞争里。我的转型定位是懂 AI 底层原理 + 擅长前端工程落地,既能看懂算法侧方案、协同调优模型,又能独立完成模型浏览器部署、AI 产品全栈开发,瞄准大厂 AI 前端、全栈开发稀缺岗位。 按阶段稳步推进成长 按照整体进阶规划,理论地基已经搭建完毕,下一阶段正式开启大模型体系化学习。

三、致想转型 AI 的前端同行:稳扎稳打远胜于急于求成
不少前端被行业内卷裹挟,盲目跟风速成 AI,最后浅尝辄止半途而废。结合我现阶段自学心得给出两点务实建议:
转型优先从机器学习分类、基础算法逻辑入门,循序渐进过渡到神经网络,遵循知识递进规律,不要一上来直接啃大模型; 立足自身前端技能优势,不必死磕高深数学对标算法工程师,走AI 理论 + 前端工程落地的全栈路线,最大化发挥已有职场积累。
