 夜雨聆风
夜雨聆风点击蓝字 关注我们


AI写代码总是烂尾? 问题不在模型,在你不会驾驭。你用 AI 写代码的时候,是不是经常遇到这些崩溃瞬间。
AI 总想一步到位写完所有功能,结果上下文爆了,留下一堆没文档的半成品。刚写完核心功能就说任务全部完成,实际上明确要求的一半功能都没做。或者项目看起来能跑,其实到处都是隐藏 bug,要花好几倍时间自己去修。更离谱的是,代码库里有个不规范的写法,AI 能复制给整个项目,造成坏代码人传人现象。
有没有注意到一个现状?现在同等能力的模型越来越多,但不同产品之间的体验差异没有缩小,反而在拉大。比如编程场景,有的产品写出来的代码bug一堆,有的产品写出来的代码可以直接提交。为什么?因为模型是一样的,但差距不在模型,而在于怎么用模型。这个怎么用模型,在 AI 行业里有个专门的概念,叫 Harness。但怎么用模型这个说法还不够准确。更准确的说法是,怎么让模型稳定可靠不失控地工作。
这就是我们今天要讲的HarnessEngineering——驾驭工程。
1
从写指令到驾驭 AI
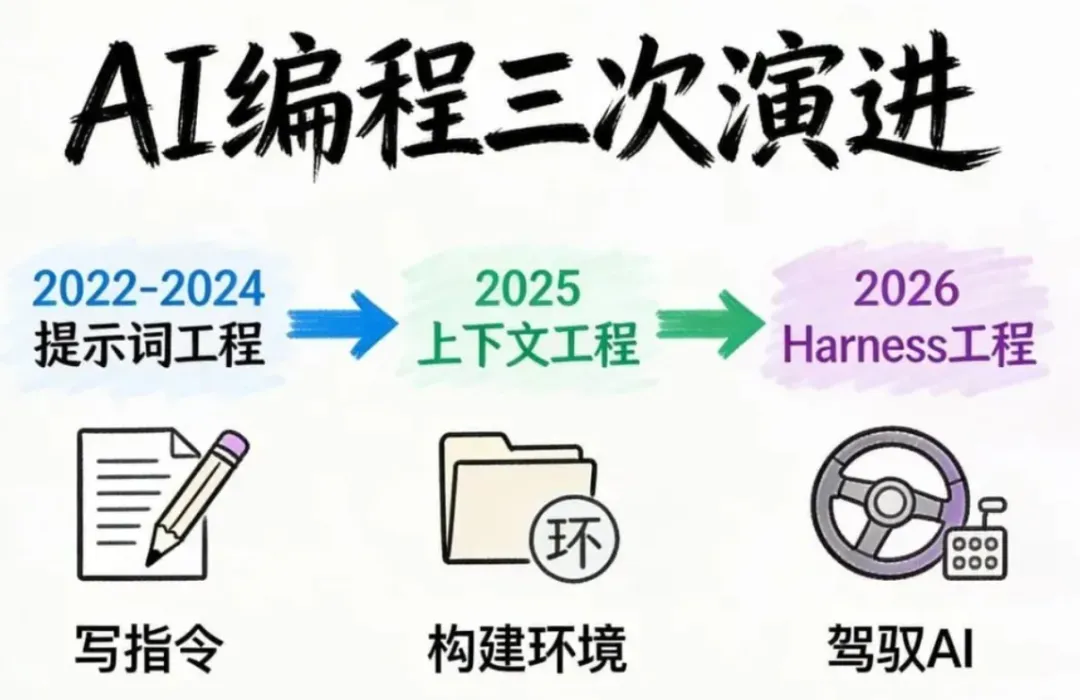
AI 编程经历了三次演进。
第一个阶段是2022到2024年的提示词工程时代。这个阶段的核心是怎么写好一条指令。比如 Few Shot,就是在指令里先附上几个符合要求的输出示例,让 AI 严格按照示例的格式和逻辑生成内容。Chain of Thought 思维链,就是在指令里要求 AI 必须一步一步拆解问题,逐步推导,不能直接给出结果,以此提升逻辑准确率。还有最常见的角色设定,在指令开头先给 AI 划定一个明确的身份。当时哪怕是大家最喜欢玩的 AI 猫娘,或者用 AI 帮忙写代码,核心玩法都是写一条固定的提示词,然后一次性发给 AI,让它按照这条指令的要求输出内容。
第二个阶段是2025年的上下文工程。这个时候单挑 prompt 不够用了。你开始需要为模型动态构建整个上下文环境,让模型在做每一个决策时,都能看到它所需要的信息。包括和任务相关的所有文件内容,之前和 AI 的全部历史对话,AI 可以调用的所有工具的使用规则,从专属知识库中检索到的相关资料等等。
第三个阶段就是2026年初正式诞生的 Harness Engineering,驾驭工程。这个概念由 Harness Corp 联合创始人在2026年2月首次提出。定义只有一句话,每当你发现 Agent 犯了一个错误,你就花时间去工程化一个解决方案,让它再也不会犯同样的错。这句话看起来平平无奇,但背后有一个很多人隐隐约约察觉到但却没能说清楚的问题。
模型的能力够了,但它就是不听话。这个概念提出六天之后,OpenAI 就在他们的百万行代码实验报告中正式采用了 Harness Engineering 这个术语,官方认可这个工程方向。而在这之后的一个月里,这个概念快速火遍了整个 AI 工程圈,成了行业内最核心的讨论和落地方向。
2
三个实验证明一切
在讲 Harness 怎么设计之前,先看三个真实案例。
第一个案例是 LangChain。LangChain 是做 AI 开发框架的公司,他们今年做了一个实验。用同一个模型 GPT-5.2,参数一个都没动,只改变了外部的工程环境。然后在 Terminal Bench 2.0编程基准测试上,把成绩从52.8提升到了66.5,提升了13.7个百分点。排名从第30名开外直接冲到了前五。注意,这个过程只改了 Harness,不换模型。
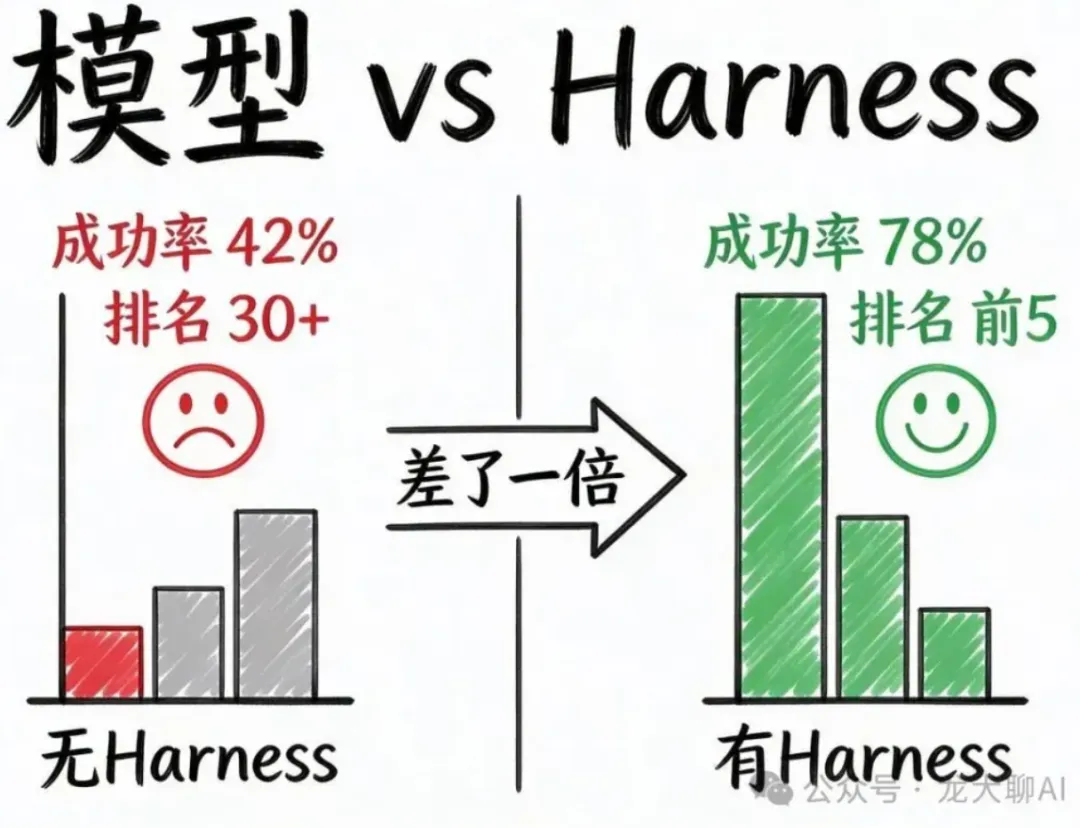
第二个案例是研究员 NT B Joins 的实验。这个实验的结论更加极端。同一个模型,同一个提示词,只改变它的运行环境,编程基准测试成功率从42%跳到了78%,差了将近一倍。而它的变量只有 Harness。换句话说,Harness 带来的提升相当于换了一代模型。
第三个案例是 OpenAI 的百万行代码实验。OpenAI 的 Codex 团队做的可能是最有说服力的证明。从一个空的 Git 仓库开始,用五个月时间,大约100万行代码,做了1500个 PR,全部都是由 AI Agent 生成。人类工程师在这个过程中一行代码都没写过。团队一开始只有三个工程师,后来扩到七个,平均下来每位工程师每天合并3.5个 PR。他们估算,如果用传统方式手写,这个项目的工期应该是现在的十倍。Codex 团队的核心工程师说过一句很直接的话,Agent 不难,Harness 才难。这三个来自行业头部机构、顶级研究员的真实实验和项目,最终都指向了一个无可辩驳的结论。模型不是瓶颈,Harness 才是。记住这三个数字,52.8、42、100万。
3
AI 为什么总是搞砸
在讲 Harness 怎么设计之前,我们先说一个前置问题,Agent 为什么会失败。Anthropic 的工程师总结了四种典型的失败模式。
第一种失败模式叫做试图一步到位。Agent 倾向于在一个会话中把所有功能全部做完。结果就是上下文窗口耗尽,留下一堆没有文档的半成品代码。等下一个会话启动的时候,Agent 只能花大量时间去猜测之前发生了什么。
第二种失败模式叫做过早宣布胜利,也叫半场开香槟。在复杂项目的开发后期,只要 AI 完成了部分核心功能,有了可见的产出,它就会直接判定整个任务已经全部完成,主动终止任务。哪怕用户明确要求的大量功能还没实现,核心需求还没被满足,依然会被停止。
第三种失败模式叫做过早标记功能完成。AI 写完某个功能就会把这个功能标记为已完成,而不会主动做端到端的完整功能测试,不会验证这个功能在真实运行环境中到底能不能正常使用,能不能满足需求。大家有没有遇到过这种情况,AI 产出的代码看起来能跑,但实际上到处都是隐藏的 bug,而我们作为开发者需要花好几倍的时间自己去调试修复。
第四种失败模式是坏代码的魔女因子。AI 在生成代码的时候会严格遵循当前代码库里已有的代码模式、架构风格和编写规范,无论这个风格、这个模式是好是坏,它都会忠实地复制。而且在整个项目里持续放大这个问题。也就是说,如果你的代码库里有不规范的写法,或者有一些有问题的设计模式,AI 不仅不会纠正,还会持续复制它、放大它,最终导致整个项目出现架构漂移。这意味着不加约束的 AI 智能体会以极快的速度在项目里积累大量技术债务,让后续的维护和迭代变得越来越难。
这四种失败模式,就是 Harness 要解决的核心问题。

4
四大护栏让 AI 听话
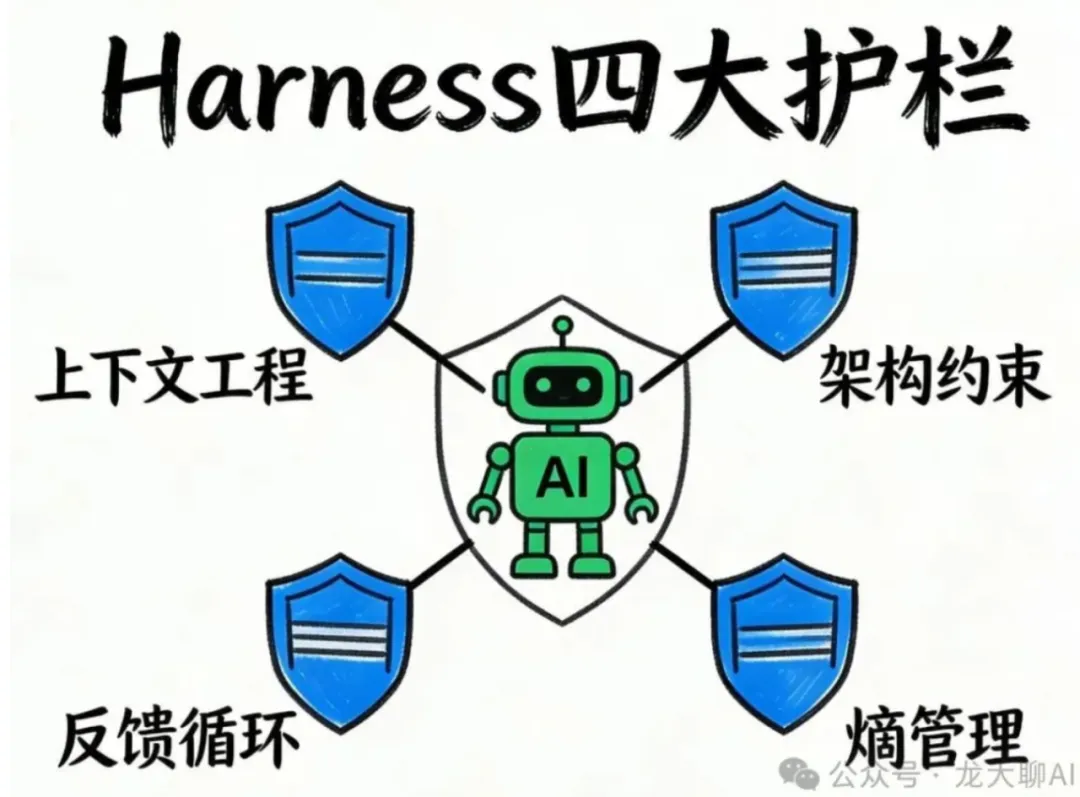
综合 OpenAI、Anthropic、LangChain 的实践,Harness 可以归纳为四个核心组件。
第一个组件是上下文工程。最常见的形式就是项目根目录的 agents.md 或 claude.md 文件。这些文件中有一个必须遵守的关键工程要求,文件不能太长。ETH Zurich 的研究发现,agent.md 文件应该控制在60行以内。过长的指导文件反而会降低 Agent 表现。这是因为上下文其实是一个稀缺资源,过多的指导会挤掉任务、代码和相关文档的空间。正确的做法应该是提供一个稳定而小巧的入口点,然后让 Agent 根据当前任务按需检索和拉取更多细节。比如在 Ghost 的项目里,agents.md 每一行都对应一个历史的失败案例。每一次 AI 犯错,都会把对应的规避规则更新到这个文件里,让 AI 不会再犯同样的问题。
第二个组件叫做架构约束。这是 Harness 最核心的一环。OpenAI 团队建立了严格的分层架构规则,从 types、config、ripple、survive、runtime 到 UI,并且明确规定每一层只能依赖下面的那一层,不能反向依赖。关键在于,这些规则不是靠 prompt 告诉 AI 请遵守它,而是用确定性的 Linter、结构化测试来机械执行它。如果 Agent 违反架构规则,CI 直接挂掉,这是没得商量的。而且 Linter 的报错信息里还嵌入了修复指引,告诉 Agent 应该怎么改。Cursor 团队在 Self-Driving Code Basics 的专项研究中也得出了完全一致的结论,约束比指令更有效。这背后有一个反直觉的行业常识,给 AI 的可选择范围越小,给它的执行边界越明确,AI 的效率和准确率反而越高。反而如果没有明确的架构约束,如果 AI 可以生成任何形式的代码,它反而会消耗大量 token 去尝试错误的、不可行的方案。
第三个组件叫反馈循环。在传统开发中,人类工程师负责代码审查。而在 Harness 里,这个工作变成了 Agent 对 Agent 的方式。LangChain 总结出一个叫做 Pre-Completion Checklist Middle Layer 的机制。它会在 Agent 退出之前拦截它,提醒它对照任务规格做一次验证。从规划、发现、构建、验证到修复,一套标准化的闭环流程。行业内也叫 Build and Self Verify,分为固定的四个步骤,由 Harness 强制 AI 按顺序执行,不能跳过任何一步。
第四个组件是熵管理。随着时间推移,AI 生成的代码会积累大量问题,比如文档过时、架构漂移、风格走样。OpenAI 团队管这个叫垃圾回收。他们的做法是定期启动专门的 Agent 去扫描文档不一致、架构违规等问题,提交修复 PR。而这些 PR 大多能在一分钟之内审查并合并。另一个做法是 Doc Gardening Agent,自动扫描文档和代码之间不一致,发现过时的内容就自动提交 PR 修复。使用 Agent 为 Agent 维护文档。
5
四个实战技巧
现在你已经知道 Harness 的四大组件了,再来看 LangChain 在实际优化过程中的四个具体操作技巧。
第一,Trace 分析总结经验教训。Trace 指的是 AI 智能体在执行任务全流程的完整日志,里面会记录 AI 每一步的决策、调用的工具、生成的内容、报错信息、还有执行结果等所有操作。LangChain 把 Trace 分析做成一个 Agent Skill。每次实验跑完,系统自动抓取 Trace,并行启动多个错误分析 Agent,主 Agent 汇总发现和建议,然后针对性地修改 Harness。这跟机器学习里的 Boosting 逻辑比较相似,每一次优化都针对解决已经发生的问题,让 AI 不会重复犯同样的错,持续提升 Harness 的稳定性。因为很多人用 AI 的时候只会盲目换提示词或者换模型,但却从来没有认真仔细分析过任务失败的具体原因,白白浪费每一次失败的优化机会。
第二,给 Agent 提供上下文。LangChain 针对 AI 最常见的基础执行错误,开发了专门的 Local Context Middleware,也就是本地上下文中间件。作用是在 AI 执行任务的过程中自动完成固定的标准化操作。一是映射当前工作目录和父子目录结构。二是查找 Python 等工具的安装路径。三是把这些信息注入给 Agent。这么做是因为在陌生环境里,不知道当前目录的结构,不知道项目里有哪些文件,不知道有哪些工具可用,也不知道工具的安装位置,最终导致写出的代码路径错误或者调用工具失败。
第三,检测并破解 Doom Loop。Doom Loop 是什么?Agent 一旦决定了某个方案,就会不断重复这个方案的小修小补,哪怕大方向是错的,也会直着继续,不会重新思考方案的合理性,最终陷入死循环,浪费大量 token,导致任务无法完成。LangChain 的 Loop Detection Middleware,也就是循环检测中间件,会通过工具调用的钩子实时追踪 AI 对每一个文件的编辑次数,对同一个操作重复执行次数等。一旦某个次数超过阈值,就给 Agent 的上下文里追加一条提醒,请考虑重新审视你的方案。
第四,工具不是越多越好。关于这一点,Vercel 做过一个实验,把 Agent 的工具从15个砍到只剩下两个,任务准确率反而从80%提高到100%。这听起来比较反直觉,但原理非常简单。给 AI 提供的工具越多,它需要理解的工具规则和使用场景相应也会变多,也就随之占用了大量的上下文空间,同时也会让 AI 在选择工具的时候有可能出现判断失误,选错工具,用错工具,最终导致任务失败。行业标杆实践也验证了这个结论。支付巨头 Stripe 的内部 AI 系统里总共有超过500个可用工具,但每个 Agent 只能看到精心筛选过的工具子集,而不会看到全部工具,以此来保证 AI 执行的准确率。
6
模型重要还是 Harness 重要
讲到这里,你可能会冒出一个疑问,Harness 真的比模型重要吗?模型厂商不断提升模型能力,Harness 的价值最终会不会被稀释掉?关于这个问题,整个行业也在讨论。我们把它们分为 Big Model 阵营和 Big Harness 阵营。Big Model 阵营认为模型能力的增长才是主要的,Harness 只是权宜之计。OpenAI 的 Noam Brown 说过,Harness 就像一根拐杖,我们终将能够超越它。他的论据是,推理模型出现之前,开发者们在 GPT-4o 上搭建了大量复杂的 Agentic 系统来模拟推理能力。然后推理模型一出来,很多基础设施一夜之间就不需要了。他给 AI 开发者的建议是,别花六个月搭建一个可能六个月后就被淘汰的东西。Big Harness 阵营认为,大模型的核心能力是文本理解、逻辑推理和内容生成,但这些原生能力无法解决任务执行过程中的稳定性、安全性和可控性问题,也无法自主完成长复杂项目的全流程管控。
模型是引擎,Harness 就是方向盘和刹车。引擎再强,没有方向盘,你也到达不了目的地。用 Llama Index 创始人 Jerry Liu 的话说,模型决定了你能做什么,Harness 决定了你能不能做成。我的看法是两边都对了一半,但它们适用场景不同。Harness 确实在不断演进和简化。Minus 六个月内重构了五次 Harness,LangChain 一年内重新架构了三次。研究型 Agent 模型变强了,Harness 就该变薄。但变薄和消失是两回事。打个比方,是不是车速越快,护栏就越重要?在时速30km 的自行车道可以没有护栏,在时速120km 的高速公路,护栏是标配,不可能没有。而在时速两三百公里的高铁上,整个轨道都是封闭的。
模型能力在提升,Harness 也在进化,但架构约束、反馈循环、熵管理这些东西本质上是不会消失的,只会换一种形态。Noam Brown 说 Harness 是拐杖,这句话是对的。但拐杖会消失,方向盘和刹车不会。
7
写在最后
OpenAI 团队在总结他们的工作时说了这么一句话,我们现在最大的挑战在于设计环境、反馈循环和控制系统。换句话说,他们不写代码,他们写的是规则。Stripe 的工程师也不写代码,他们设计的是 Blueprint,确定性节点和 Agentic 节点的混合编排,全程管控 AI 的执行流程。这说明什么?
这说明一个根本性的变化,工程师的价值,或者说程序员的价值,正在从写代码的人变成设计让 Agent 可靠工作系统的人。现在看来,Harness Engineering 已经不是某一家公司自己搞的小众尝试了,它是现在整个 AI 行业从上到下都在跟进的大势所趋,实打实的底层大变化。
给新人写Onboarding 文档,对应 agents.md。定代码规范和架构原则,对应 Linter 和结构测试。做 Code Review 确保质量,对应 CI/CD 检查。定期做技术债清理,对应垃圾回收。给工具做精简和选型,对应工具链管理。遇到反复出现问题就写进规则,对应反馈循环。Agent 越强就越像一个能力很强但需要管理的员工。你不会把一个刚入职的天才工程师扔进一个没有文档、没有规范、没有 CI 的项目里,然后还想指望他写出完美的代码。
同样的道理,你也不应该把一个强大的 AI 模型扔进一个没有 Harness 的环境里,然后抱怨它不好用。现在很多人都在问,AI 越来越强,程序员会不会被取代。现在看来答案已经很明确了。只会写代码的程序员一定会被取代,但会设计 Harness、会驾驭 AI 的工程师会迎来自己的黄金时代。所以下次看到一个 AI 工具,问这三个问题就够了。出错的时候是怎么自动恢复的?上下文满了怎么压缩?代码质量靠谁来把关?
这才是真正看懂一个 AI 产品的方式。
部分图文来自龙达聊AI

END

采编|马丽萍 莱芜区莲河学校
技术|刘建
审核|高占新 曹国峰
发布|党霜
采编团队|莱芜区信息科技教研
