 夜雨聆风
夜雨聆风今日AI资讯
【AI 应用/模型】
- OpenAI :发布 ChatGPT 新记忆系统,通过后台自动合成,随时间自动更新,可溯源可修改
- NVIDIA: 正式发布5500亿参数 Nemotron 3 Ultra模型,专为长程智能体打造的 550B 性能怪兽
- 腾讯:发布 WorkBuddy 企业版与效率智能体工具集 ,补齐企业智能体全生命周期矩阵
- 谷歌:NotebookLM 推出 Source Attribution(来源引用),每一条回答都有据可查
- Claude Code: “ultracode”触发词替代“workflow”,启用动态工作流
【AI 创作】
- Google: 发布 Magenta RealTime 2,15倍提速的本地实时音乐生成
- Krea AI:发布Krea 2 Turbo 生图模型,2秒极速生成高质量艺术图像
- ElevenCreative: 推出 Flows Agent,对话间构建复杂工作流
- Miso One:8B文本转语音模型,具有超越人类的反应速度和极富感染力的情感表达
【AI 3D/世界模型】
- 北大团队:发布 EvoPhys-World,自进化的 5D 世界模拟器,实现了从“观察世界”到“塑造世界”的跨越
👇进群,不错过每日最新AI资讯噢~

🤖️AI 应用/模型
OpenAI :发布 ChatGPT 新记忆系统,通过后台自动合成与更新,可溯源可修改
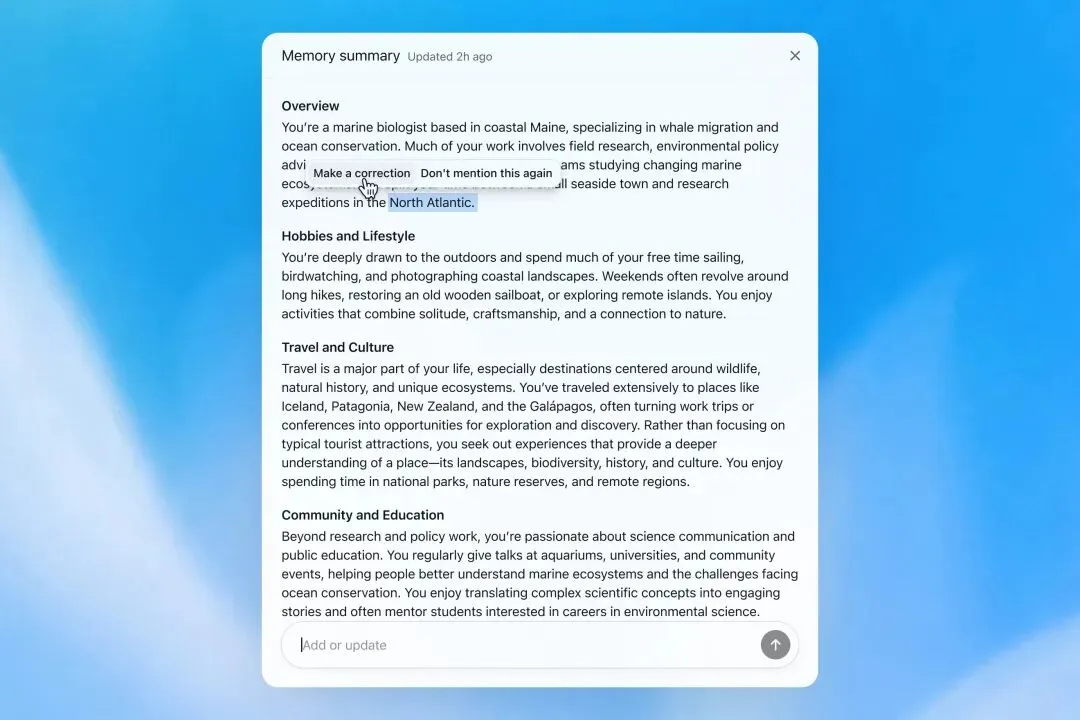
OpenAI 更新名为 Dreaming 的全新记忆系统,通过后台自动合成与更新技术,缓解大模型在长期交互中的信息过时和记忆碎片化问题。
- 后台自动“梦境”合成:不同于以往需要显式要求记忆,Dreaming 会在后台自动梳理聊天历史,提取用户的偏好、项目进展和约束条件,确保存储的记忆始终是最鲜活且相关的。
- 时间感知能力:Dreaming 赋予了 ChatGPT 极强的时间观念。例如,它能自动将“我下周要去新加坡”的记忆,在8月更新为“我七月去过新加坡”,避免产生陈旧信息的干扰。
- 效率提升:新架构大幅降低了记忆检索与存储的计算成本,每条记忆更新对算力的开销下降约5倍,内存容量翻倍。
- 用户可溯源与及时修改记忆内容。
今日起,美国的 Plus 和 Pro 用户即可享受此更新,未来几周内将推广到其他国家/地区以及 Free 和 Go 用户。
⭐消息来源:
https://openai.com/index/chatgpt-memory-dreaming/
腾讯:发布 WorkBuddy 企业版与效率智能体工具集 ,补齐企业智能体全生命周期矩阵
在 2026 腾讯云 AI 产业应用大会 上,腾讯系统发布“效率智能体工具集”,面向个人提效、办公提效、企业提效三类需求,提供 20 多个垂直场景的智能体解决方案。面向企业用户,腾讯正式发布 WorkBuddy 企业版与 办公智能体套件 Agent Suite,并同步升级企业智能体管控平台 ClawPro 和 智能体开发平台 ADP 4.0。

这次发布的重点不是单一工具,而是一套覆盖企业智能体全流程的产品组合:
- WorkBuddy 企业版:面向企业内部办公与协作场景,帮助员工把知识查询、文档处理、流程执行等日常工作交给 AI 智能体完成。
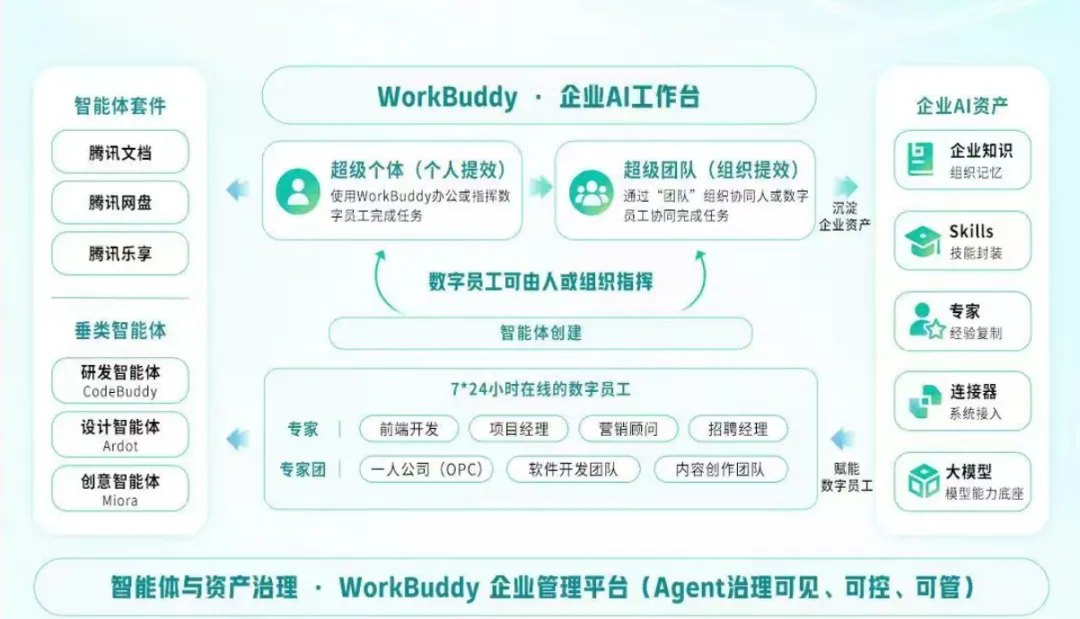
- Agent Suite:面向办公场景的一组智能体套件,可把不同办公任务封装成可复用的 Agent,降低企业落地智能体的门槛。
- ClawPro :负责企业级智能体的管控、权限、安全、审计与治理,让企业在大规模部署 Agent 时可以统一管理风险和使用边界。
- ADP 4.0 :面向智能体开发侧,帮助企业构建、调试、评测和发布 Agent,让业务团队与技术团队可以更快搭建生产级智能体。
⭐阅读更多:
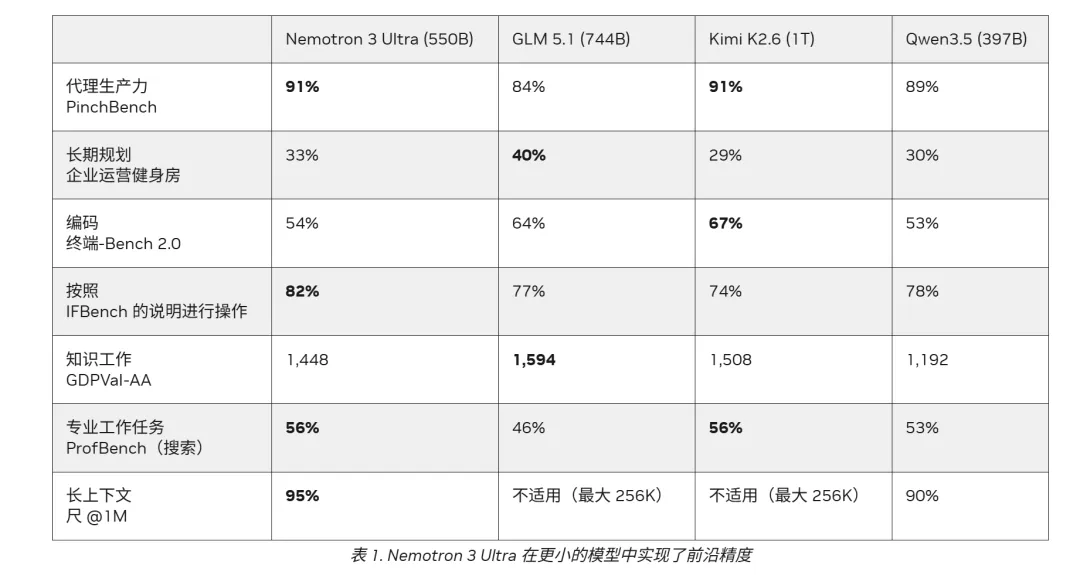
NVIDIA: 正式发布5500亿参数 Nemotron 3 Ultra模型,专为长程智能体打造的 550B 性能怪兽
NVIDIA宣布开源大模型Nemotron 3 Ultra。这是一个混合式混合专家模型,总参数5500亿,活跃参数约55 亿,支持最长100万Token上下文,用于长时间运行的AI智能体推理。模型采用开源许可并发布了训练配方和数据集,旨在加速科研与开发。
- 5倍推理提速:相比同级别的开源模型,Nemotron 3 Ultra 在保持顶尖推理能力的同时,实现了最高 5 倍的吞吐量提升,大幅缩短了智能体执行复杂工作流的等待时间。
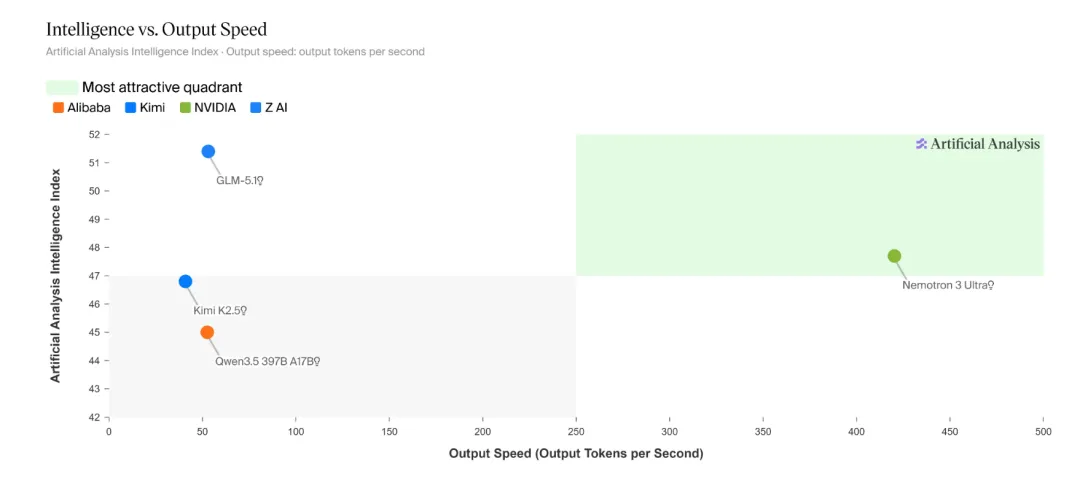
- 30% 成本优化:通过架构创新和高效的专家路由,该模型在 SWE-bench 等工程任务中能以更少的 token 消耗完成更高质量的交付,任务成本降低约 30%。
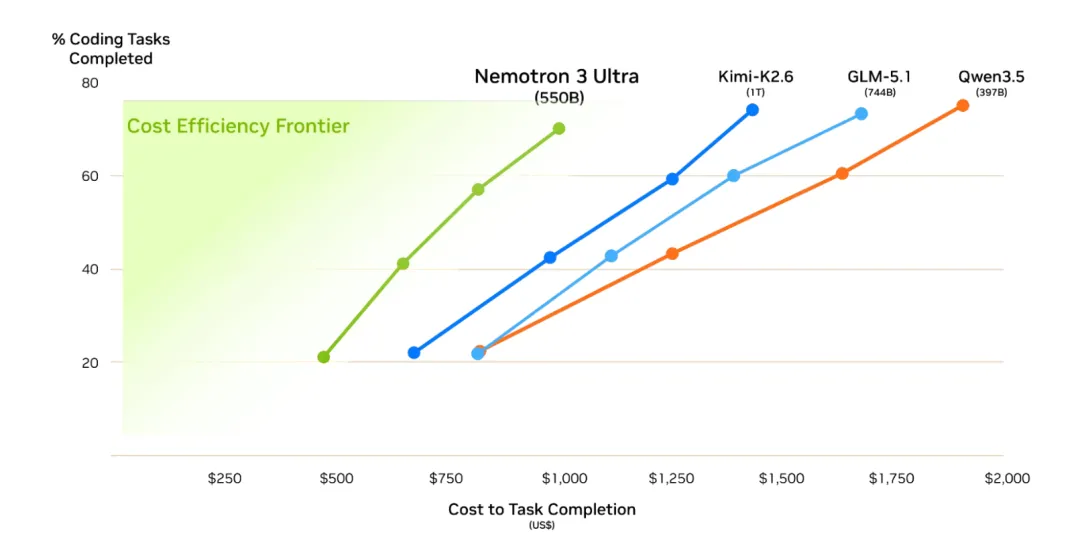
- 全架构兼容:支持最新的 NVFP4 精度,可无缝运行在 NVIDIA Hopper、Blackwell 及 Ampere GPU 上,是目前最适配企业级智能体部署的开源大模型。

核心创新:
- 混合Mamba‑Transformer层与LatentMoE——兼顾序列建模与稀疏专家路由,提升长上下文推理效率。
- NVFP4量化与多Token预测——降低推理成本并支持每次生成多个词元,提升吞吐率。
- 后训练技术——使用多教师在策略梯度下蒸馏,并公开约1000万条SFT样本和100万条RL任务数据。
⭐消息来源:
https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/
谷歌:NotebookLM 推出 Source Attribution(来源引用),每一条回答都有据可查
Google 的智能笔记工具 NotebookLM 新增“来源引用(Source Attribution )”功能,系统将用户上传的PDF、文档或视频转录作为信息来源,并在AI回复中附上内联引用,指向原文具体段落,方便用户核对信息。
⭐阅读更多:
https://x.com/NotebookLM/status/2062653124326863077
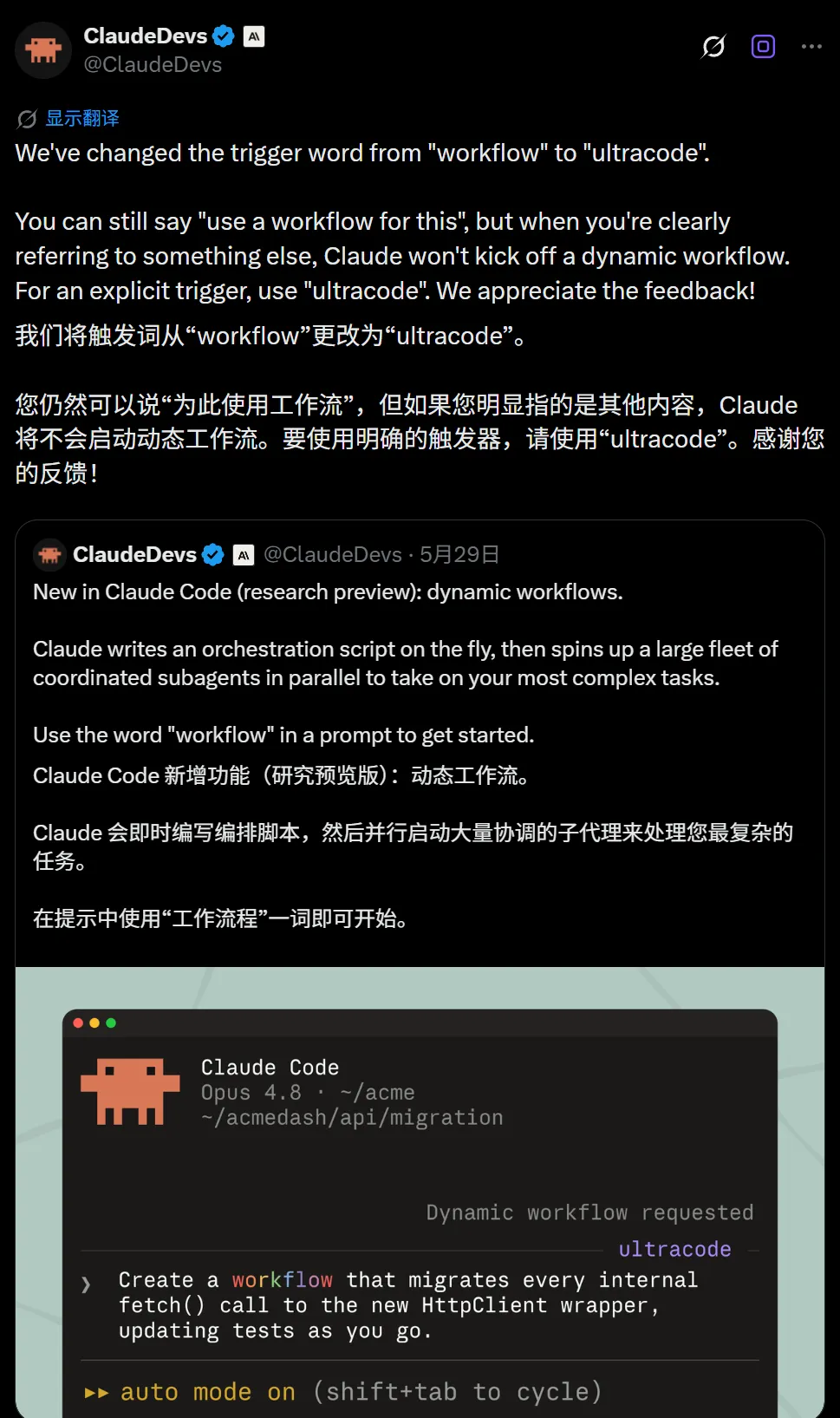
Claude Code: “ultracode”触发词替代“workflow”,启用动态工作流
Claude Code更新后,引入新触发词 “ultracode” 以启动动态工作流。用户在提示中包含“ultracode”,Claude会为任务自动编写流程脚本;在2.1.160版本之前使用的旧触发词是“workflow”。
开启 \effort ultracode 后,系统将在高推理强度下自动判断何时需要工作流并可能连续运行多个流程。
⭐阅读更多:
https://x.com/ClaudeDevs/status/2062257177788858398
🤖️AI 创作
Google: 发布 Magenta RealTime 2,15倍提速的本地实时音乐生成
Google Magenta发布了Magenta RealTime 2(MRT2),这是一个2.4 亿参数的实时音乐生成模型
- 支持文本、音频和MIDI三种输入方式,能在笔记本电脑上实现实时音乐合成;采用40 毫秒帧大小,控制延迟约200 毫秒。
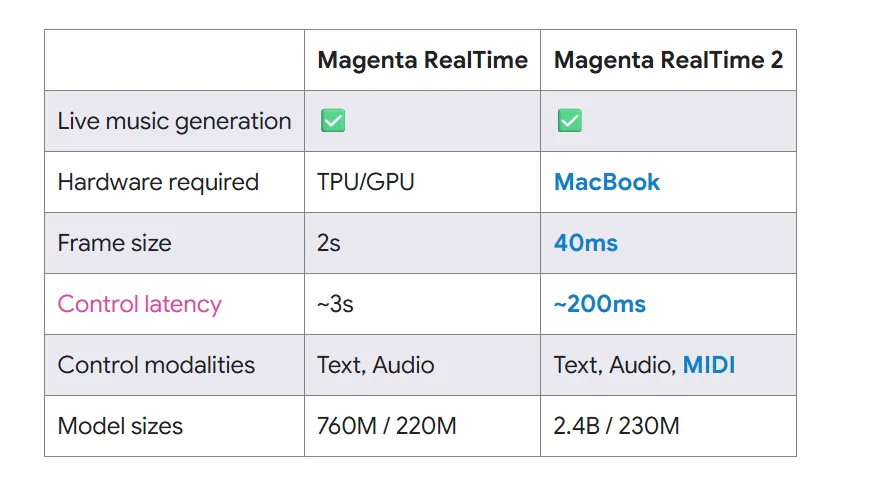
- 使用滑动窗口注意力实现连续流式生成,显著降低记忆占用,响应延迟比上一代低约15倍。
- 提供C++推理引擎和Python库,通过Apple Silicon的MLX框架实现高效本地运行,并随附多个可玩示例应用。
- 基础模型可在MacBook M3 Pro或M2 Max上实时运行,230M参数的小模型甚至能在任何Apple Silicon MacBook上离线推理
⭐官方地址:
https://magenta.withgoogle.com/magenta-realtime-2
Krea AI:发布Krea 2 Turbo 生图模型,2秒极速生成高质量艺术图像
Krea 2 Turbo 是 Krea AI 推出的一款高速图像生成模式。在保持原模型大部分能力的同时,将生成时间缩短到约2秒
- 极致速度与质量:在保持电影级画质的同时,实现了近乎实时的生成体验,支持用户在灵感迸发的瞬间即刻看到成品。
- 全生态兼容:支持风格参考、情绪板(Mood Boards)和 LoRA 微调模型,设计师可以轻松锁定特定视觉风格进行批量创作。
⭐使用地址:
https://www.krea.ai/
ElevenCreative: 推出 Flows Agent,对话间构建复杂工作流
ElevenLabs 旗下的 ElevenCreative 发布了 Flows Agent ,这是一个基于节点的可视化工作流自动构建工具。
- 自然语言构建工作流:用户只需描述“我想要创建一个带有情感调节的配音工作流”,代理就会自动在画布上拖拽节点、选择模型并完成连线。
- 支持复杂的逻辑判断和循环流程,允许用户通过简单的对话调整工作流中的任何微小细节,而无需手动编写逻辑代码。
- 文件上传和模型集成:可上传参考图片、脚本或项目说明,代理利用这些材料构建完整工作流。整合了Nano Banana Pro、Veo、ElevenLabs TTS等50多种图像、视频和声音模型,覆盖完整的创意链条。
⭐阅读更多:
https://elevenlabs.io/docs/eleven-agents/customization/agent-workflows
Miso One:110毫秒响应的 8B 极速情感文本转语音模型
MisoLabsAI发布80 亿参数的文本转语音模型 Miso One ,官方表示该模型具有超越人类的反应速度和极富感染力的情感表达。
- 文本 + 音频双条件:模型同时基于文本和用户提供的音频上下文生成语音,输出能呼应说话者的语气。
- 极低延迟:Miso Labs 宣称模型响应延迟约110 毫秒,显著快于 Elevent Labs(约700 ms)和 Sesame 模型(约300 ms),甚至比人类在对话中的自然反应还要快,是构建实时语音助手的理想选择。
- 人类级情感表现:能够精准捕捉并模拟人类语音中的细微情感波动,生成的音频在语气、停顿和重音上与真人无异。
模型权重开源,API 访问权限即将推出
⭐项目地址:
https://github.com/MisoLabsAI/MisoTTS
🤖️AI 3D/世界模型
北大团队:发布 EvoPhys-World,自进化的 5D 世界模拟器,实现了从“观察世界”到“塑造世界”的跨越。
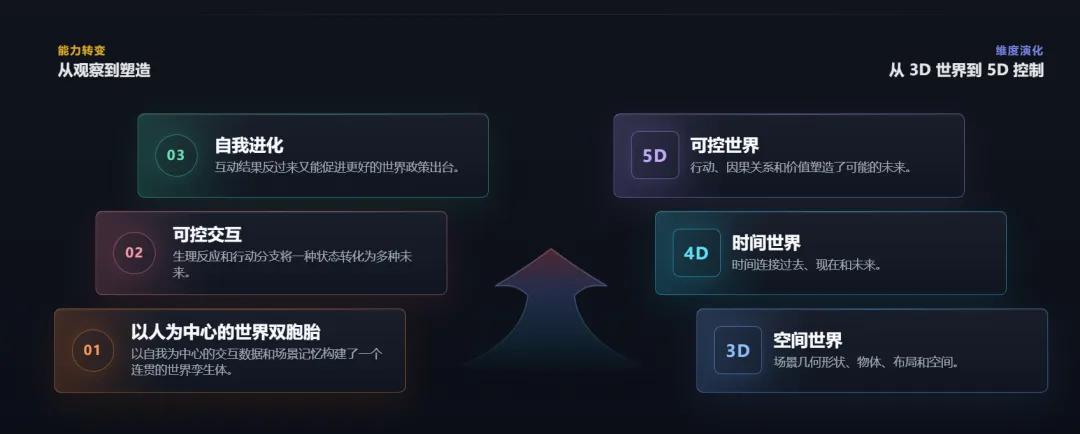
北京大学团队发布了名为 EvoPhys-World 的人机交互场景级 5D 世界模型 ,实现了从“观察世界”到“塑造世界”的跨越。
- 世界记忆与未来想象:模型将场景视为活系统,记住现有状态、预测行动如何改变场景并比较不同未来,然后将结果反馈到下一轮推理。
- 5D扩展:在传统3D空间(物体和布局)的基础上引入时间维度(4D)和控制维度(5D),将动作、因果关系和价值纳入未来预测。
- 交互式双生:利用第一人称交互数据和场景记忆构建一致的“世界双胞胎”,并通过统一的状态‑动作循环实现时空记忆、下一状态预测、下一动作预测与自进化反馈。
该模型旨在支持可控世界生成、多未来决策和真实物理交互,覆盖模拟场景和机器人操作等。
⭐官方地址:
https://evophys.com/
⚠️部分内容由AI生成,可能存在偏差
💗有任何疑问,请提前联系邮箱:alolg@163.com
