 夜雨聆风
夜雨聆风一、Codex
Codex是OpenAI做的一个"AI助手",能写代码、能改文件、能上网、能操作电脑。
它最早是个命令行工具,2025年4月OpenAI放出了Codex CLI,开源的,程序员在终端里敲几行字就能让它干活。到了2026年2月,OpenAI推出了桌面版,有图形界面了,像普通软件一样窗口操作。3月又出了Windows版。到现在,每周有300多万开发者在使用它。
你可以把它理解成ChatGPT的"工程版"。ChatGPT陪人类聊天解闷,Codex是真下场干活的。给它一个任务,比如"把我桌面和下载文件夹里这半年攒的几百个乱七八糟的文件分门别类,照片按月份归档,文档按项目归类,顺便清理掉没用的安装包",它会自己扫描桌面和下载文件,分析内容,创建文件夹并自动移动,最后把清理出的垃圾打包扔进回收站并生成一份整理报告,你点一下“授权访问”就行。整个过程可能一杯咖啡还没喝完。
二、从聊天机器人到电脑管家:Codex的进化之路
要讲清楚Codex的来历,得倒回去几年看。
2022年底,ChatGPT横空出世。 那时候它就是个聊天窗口,你说一句它回一句,挺聪明,但干不了实事。你想让它帮你写个邮件可以,让它直接打开你的邮箱发出去?没门。
2024年初,OpenAI推出了GPT Store。 用户可以自己做各种"自定义GPT",给它们起名字、喂资料、设定角色。一开始大家挺兴奋,做了几百万个,但用着用着发现不对劲——这些东西本质上还是聊天机器人,套了个马甲而已,做不了复杂任务,也记不住你的习惯。
2025年11月,一个名叫Peter Steinberger的奥地利开发者放出了一个开源项目,叫ClawdBot,也就是风靡一时的小龙虾。 这东西跟当时的AI工具都不一样——它不光能聊天,还能实际控制你的电脑,打开应用、点击按钮、操作文件,甚至能在飞书、钉钉上跟你对话。后来改名叫Moltbot,最后定名OpenClaw。短短三个月,GitHub上飙到18万星。(参考: )
OpenClaw火到什么程度?LangChain的CEO Harrison Chase后来回忆说,他们公司内部明令禁止员工在公司的电脑上装OpenClaw,因为安全风险太高。但恰恰就是这种"不受约束"的野性,让它成了当时最现象级的AI项目。
2026年2月,OpenAI把Peter Steinberger招入麾下。 不是收购公司,是acqui-hire(人才收购),OpenClaw项目本身转成了独立开源基金会,OpenAI赞助。Sam Altman在X上发文说,Steinberger将主导OpenAI下一代个人Agent的开发。
几乎同时,OpenAI的Codex桌面版正式上线,开始它是对标Anthropic 公司的claude code,主要用于编程。再往后就是2026年4月那次大更新——Codex能控制你的Mac了,能自己开浏览器、能记住你的偏好、能定时自动执行任务、能接90多个第三方工具。它从一个编码助手,正式进化成了一个"电脑管家"。
三、竞争对手的演化
Codex不是孤例,也不是最早的编程或电脑管家选手。
Manus:领先给大模型装上四肢的智能体
Manus是中国团队Butterfly Effect(Monica团队)做的,2025年初亮相。在那个聊天是AI的主要应用出口、人们还在为AI未来的应用形态做各种猜测的“年代”,它已经被定位成"通用型自主Agent",它除了聊天,还能访问网站,并在云端沙盒里写代码并执行,它第一次将browser use和computer use从少数人的探索,带进大众视野,在manus爆火之后,上网和操作电脑成为新一代Agent的标配。
它的缺点是它活在云端沙盒里,跟我们的本地电脑是隔离的。
Claude Code:Anthropic的"终端极客"
Anthropic的Claude Code走的是另一条路,它最开始也是面向编码的。它主打终端/命令行界面,依托自家claude模型一骑绝尘的code能力,它通过长上下文窗口(支持百万token),能理解大型代码库,做复杂重构,是全球开发者的最爱。Skill,这个一定程度上伴随Claude code走红的概念,
Claude code自2025年中问世,快速给Anthropic公司带来收入,成长为贡献25亿美刀 ARR (Annual Recurring Revenue, 年度经常性收入)的明星产品。(参考)
随着Agent能力向记忆分层、访问网络和电脑使用发展,Claude Code也逐渐将这个方向靠拢,并成为同类产品的佼佼者。
OpenClaw:被收编的"叛逆者"
OpenClaw现在虽然创始人去了OpenAI,但项目本身还在开源社区活着。
Openclaw的核心特点是将大模型的 海马体——分层记忆,和四肢——工具使用带出圈,并带向纵深——从云端沙盒,带进个人本地PC,从面向公众到个人养成,能记住个人习惯,从简短任务,到长时、定期任务执行。在此基础上, 它第一次将交互方式带入社交app,极大的降低了普通人的使用门槛。
Openclaw是Claude code和codex从编程品类产品, 走向面向大众电脑管控类产品的催化剂。同时,由于它是开源产品,从而极大地加速了“电脑管控”级agent技术的扩散和普及。
Hermes:会自我进化的"学霸"
Hermes Agent是Nous Research做的,2026年2月开源。它与Openclaw的最大区别是"自我进化"——做完一个复杂任务后,它会自动把经验变成技能,技能在使用过程中还会自我优化。它有三层记忆系统,能跨会话搜索历史对话,甚至能构建你的用户画像。

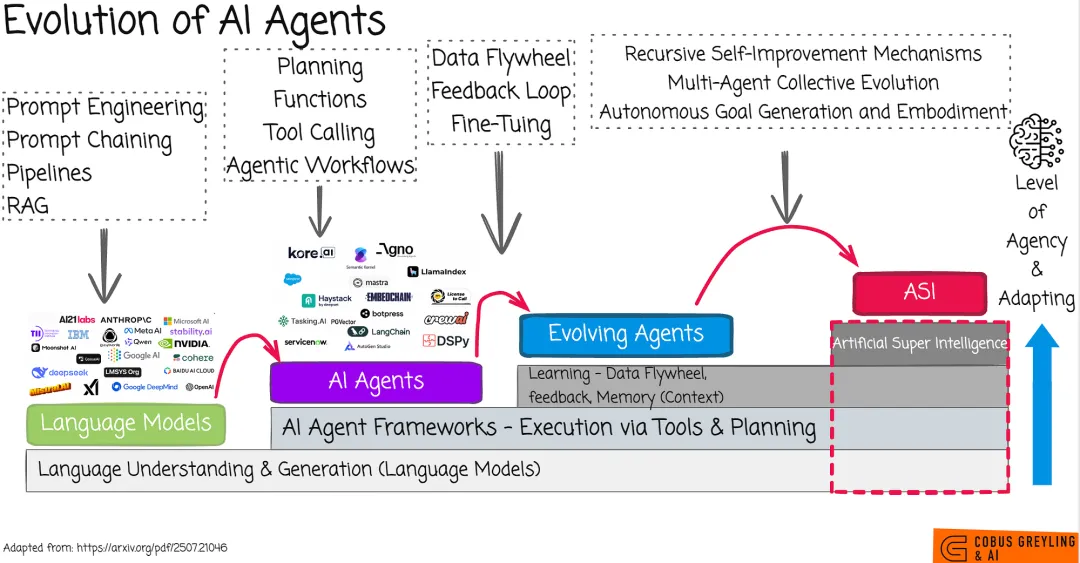
四、Agent的进化史:两条线看Codex的位置
横向对比Codex竞品非常重要,而纵向看AI Agent的演进是另一条主线。Codex正好站在两条线的交点上。
纵线一:工具使用的深化
Agent使用工具的能力,经历了几个阶段:
第一阶段:API调用。 2023年中期,ChatGPT学会了"Function Calling",能调用外部API查天气、算数据。但这有个前提——开发者得先把API接好。没API的工具,Agent干瞪眼。
第二阶段:浏览器自动化,云端沙盒computer use。 2024年到2025年,Anthropic推出Computer Use,OpenAI推出Operator,Google推出Mariner, Manus爆火。Agent学会了看屏幕、点按钮、填表单,像人一样操作网页;也能写代码并编译执行,执行shell命令。这突破了API的限制。
第三阶段:桌面级Computer Use。 2026年,Openclaw、Codex和Claude Code将操作电脑推向纵深,不限于浏览器,任何本地应用都能碰。
纵线二:记忆系统的堆叠
Agent的记忆也经历了几次升级:
第一层:上下文窗口。 最早的Agent只有短期记忆,聊多了就忘,因为模型一次能处理的token有限。
第二层:RAG和知识库。 给Agent外挂一个资料库,需要时检索。但这只是"查资料",不是真正的记忆。
第三层:Context工程。将检索资料、工具执行等各种状态内容分门别类精细裁剪安排到prompt,提升agent精准理解、准确执行的能力
第四层,Skills和分层记忆。 现在的Codex有Skills(技能包)和Automations(自动化),Hermes有三层记忆系统,OpenClaw有SOUL.md持久化记忆。Agent开始记住"你怎么干活",而不是只记住"你说了什么"。
如果说工具是LLM的手臂,分层记忆是LLM的海马体,那么Agent的进化过程,就是为LLM安装手臂和海马体的过程,作为主要的Harness组件,让智能逐步产生长时任务能力,并产生与物理世界交互的能力。
五、三个思考:Codex们的边界和未来
思考一:智能体的"外设困境"
回头看这些AI Agent,有个奇怪的现象:技术路线有些混乱。
想操作电脑?装个Computer Use模块。想记住东西?加个记忆插件。想画图?接个图像生成API。这些能力像一个个U盘,插在大模型这个主机上。
如果说手臂的功能通过外部工程来拼装,还比较符合人类智能的话,那么记忆能力通过外部工程来实现,是妥妥的脱离人类智能范式的“邪路”。
人的记忆不是外设,它藏在感知器官背后,甚至是智能推理的一部分。你看到一个杯子,你不需要先"调用记忆API"去外部查这是什么——认知和记忆是融为一体的。
记忆能力本该属于模型的一环,现在不仅与模型解耦,还能插拔,这可能是个错误。
这种"外设化"的架构,根源在于LLM的范式本身。大语言模型是片段拼接起来的智能。记忆系统被排除在LLM之外,它只能通过外部数据库、RAG、Skills来补丁式地弥补。这是范式层面的简化,不是工程层面的疏忽。
思考二:Codex的终极演化方向
如果LLM范式短期内不变,Codex的演化路径其实很清楚。
工程记忆已经快到头了。虽然记忆系统还远未解决诸如重要性过滤、不同记忆之间的融合等难题,记忆片段缝合感还非常突出,但工程能力上,上下文窗口从4K干到1M token,Skills、Automations、Memory Preview都上了,工程"海马体"基本成型,再往后,记忆系统的边际收益会递减。
唯一的进化空间在工具使用,也就是四肢和感知器官。 目前Codex能接管电脑的很大一部分功能:文件处理、软件全流程、上网、甚至后台并行操作多个应用。但还不完善——底层环境配置、复杂任务的可靠性、跨应用协调,这些都还有大量工作要做。
另一方面是交互体验。 现在主要还是打字。但随着多模态能力成熟,语音控制、视觉交互是必然方向。Andrew Ambrosino在2026年4月就暗示过,Codex的语音交互正在路上。
所以Codex的终极形态,大概率是一个能听懂你说话、能看屏幕且能你肢体语言、能操作你所有软件、能记住你所有习惯的"电脑代理"。它不需要你学会多少电脑指令,你只需要像吩咐同事一样吩咐它。
思考三:可靠性的天花板
但这里有个硬约束。
由于LLM范式的缘故,Codex可能永远无法完全解决可靠性问题。工程化记忆存在天然的破碎——Skills是离散的,Memory是摘要式的,Automations是规则化的。这些碎片拼在一起,能覆盖95%的场景,但剩下5%的极端情况,可能永远搞不定。
举个例子:我们最终能完全通过语音交互,让Codex独立完成一份复杂的PPT吗?从资料搜集、逻辑梳理、视觉设计到排版动画,全程无人干预?
我认为可能是比较困难的, 95%的存在可能无法逾越,这与模型能力上限无关,这是工程缝合的上限。
不过,当它真能接管电脑95%功能的时候,我们还要啥自行车呢?
六、尾声:星际迷航的预言
《星际迷航》里有一幕经典场景:飞船船员对着空气喊一声"Computer",然后下达具体指令——"调出昨天收到的加密通讯"、"分析这颗行星的大气成分"、"把航线偏转15度"。电脑听懂、执行、反馈,全程无需键盘鼠标。

这曾经是纯粹的科幻。但现在看,类似Codex这类产品的演化方向,就是把这一幕变成现实。
Andrew Ambrosino在2026年6月3日的推文里说,Codex的产品愿景是"有史以来最卓越的桌面程序"。这个说法其实保守了。如果桌面程序只是中间的一个过程,那么终极形态就不是"更好的桌面程序",而是"不需要桌面程序"——电脑变成一个听得懂话、看得懂眼色、能自主干活的伙伴。
到那时候,我们像星际迷航里那样通过视听使用电脑,将不再是设想,而是可以预见的现实。
关注我(公众号【正电子脑】),获取更多前沿ai分享。

