 夜雨聆风
夜雨聆风ChatGPT 学会了"做梦",AI 终于不再一转身就忘
ChatGPT | AI记忆 | Dreaming | OpenAI | 隐私
OpenAI 推出 ChatGPT 记忆系统重大升级 Dreaming,事实召回率从 41.5% 跃升至 82.8%,AI 终于能在对话间记住你了。但隐私问题依然是房间里的大象。
上周刚跟 ChatGPT 说完你爱吃素、对花生过敏,这周新开一个对话,它又兴冲冲推荐你一家花生酱主题餐厅。
OpenAI 终于受不了这种抱怨了。
6 月 4 日,OpenAI 正式推出 ChatGPT 记忆系统的重大升级——代号 Dreaming(做梦)。这不是什么小修小补,而是事实召回率从 41.5% 直接拉到 82.8% 的底层重构。
更关键的是,这个功能很快就会推到免费用户。
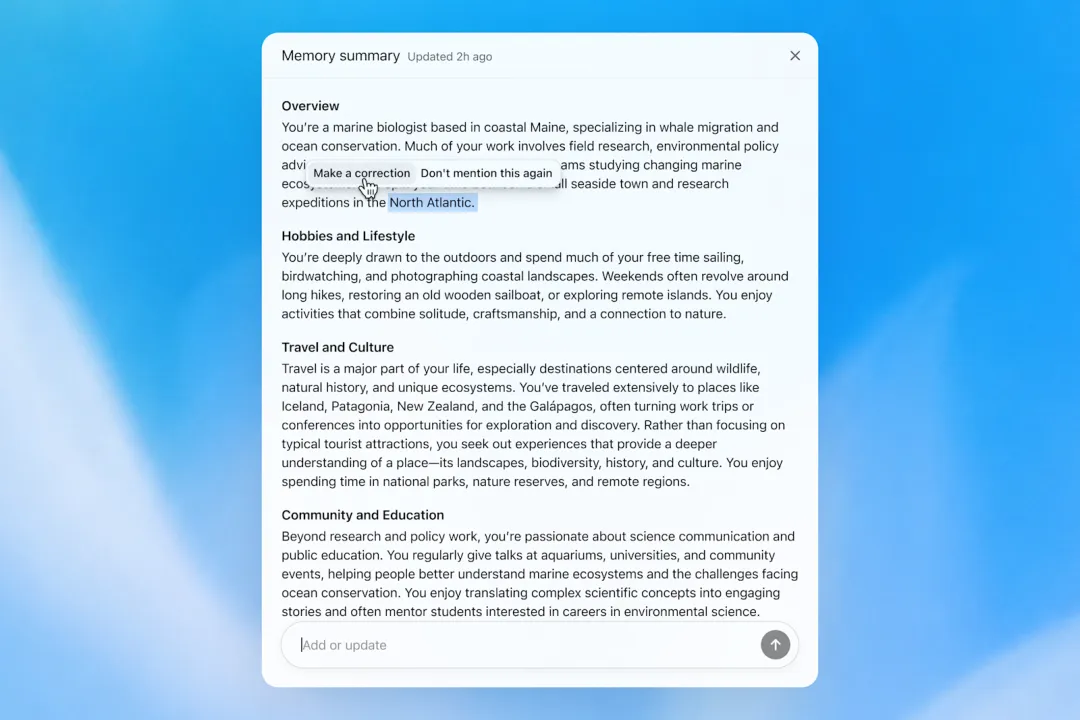
Memory Summary 页面 — 用户可查看和管理 ChatGPT 的全部记忆
一句话解释 Dreaming
旧版 ChatGPT 记忆就像一个记性不好的实习生——你说过的话它记在笔记本上,但笔记本之外的事全忘。而且笔记本会越来越过时,三个月前你说"七月要去新加坡",八月份它还在帮你规划新加坡行程。
Dreaming 的做法完全不同。它不会只在聊天时记笔记,而是在你关掉对话之后,后台自动复习所有历史对话,提炼、整合、更新你的信息。就像你睡着之后大脑还在整理白天的记忆一样——所以叫"做梦"。
这个"做梦"过程不是一天两天的事。OpenAI 从 2025 年 4 月开始内测 Dreaming V0,到今天 V3 版本正式上线,整整迭代了一年。
ChatGPT Dreaming 工作架构示意图
41.5% → 82.8%
Dreaming 事实召回率近乎翻倍
三个核心能力:能记住、能遵守、能跟上
Dreaming 围绕三个目标设计:
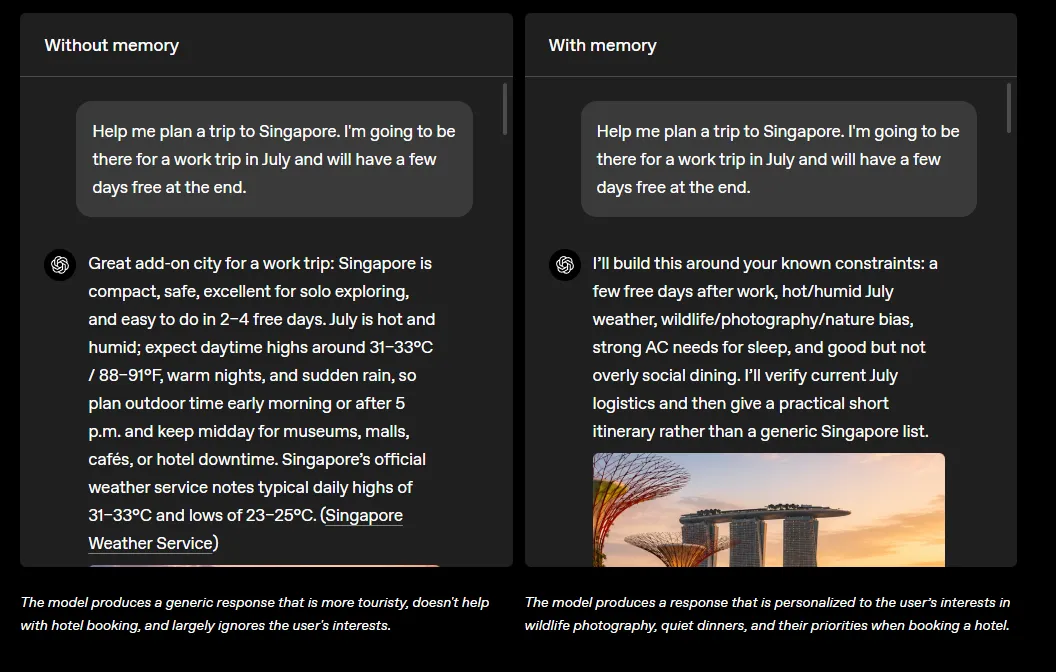
传递上下文:你说一次你的相机型号(Sony A1 II + Nauticam NA-A1II + Backscatter Mini Flash 3),以后每次问 TTL 闪光灯兼容性,它不用再问"你用什么相机",直接给出精确到零件号的答案。
遵循偏好:你说过素食、喜欢安静的餐厅、不喜欢拥挤酒吧,它规划行程时会自动跳过小贩中心和网红打卡地,推荐有预订制的正规餐厅。
保持时效性:旅行结束后,你的位置从"新加坡"自动更新为"Portola Valley"。下次点外卖,它推荐的是加州本地餐厅,不是新加坡的 24 小时 McDelivery。
前两个能力旧版 Saved Memories 也能做到一部分,但第三个——时效性——才是 Dreaming 的真正杀手锏。旧版记忆不会自己变老,只会变得越来越不准确。Dreaming 解决了这个根本问题。
用户终于能看见 AI 记住了什么
之前 ChatGPT 的记忆是黑箱。你知道它记了什么,但你不知道它从哪段对话里记的,也不知道它为什么会突然冒出一句"我记得你上次说过……"。
Dreaming 引入了 Memory Summary 页面——一个你可以直接查看、编辑的记忆仪表盘。你能看到 ChatGPT 对你的全部认知摘要,可以添加、修改、删除任何一条,甚至可以给它下指令:"以后别再提 Stan 了"。
"
AI 的记忆第一次变成了可审计、可管理的东西,而不是一个你只能被动接受的神秘黑箱。
Sam Altman 亲自下场转发
这个功能上线当天,Sam Altman 在 X 上发了一条简短的推文:"big upgrade to chatgpt memory rolling out today!"——以他的标准来看,这算是高调站台了。
OpenAI 联合创始人 Greg Brockman 和多位核心高管也转发了公告。Andrew Curran 提供了最详细的技术解读,称"真正的记忆改变了很多东西"。
66%
用户正面情绪占比(Digg 统计)
不过也有约三分之一的用户抱怨新系统偶尔会出现记忆混淆——比如把不同对话里的信息张冠李戴。
AI 记忆的竞赛已经打响
ChatGPT 不是唯一在做 AI 记忆的玩家。三大 AI 实验室各自走了完全不同的路:
OpenAI 的方案是显式存储 + 后台综合——结构化事实加上对话历史引用的双轨制。ChatGPT Memory 是三者中最成熟的消费级实现,从 2024 年 4 月上线,已有两年多运行历史。
Anthropic 的 Claude 走了另一条路——离线策展式 Dreaming。它不在对话中更新记忆,而是在会话结束后用后台任务批量分析最多 100 段历史对话,提炼工作流模式、错误模式、团队偏好和协调模式。Harvey 法律 AI 启用 Claude Dreaming 后任务完成率提升了 6 倍。但 Claude Dreaming 目前仅限 Agent API 研究预览,普通个人用户短期内用不到。
Google 的做法最激进——Gemini Spark 压根不建独立的记忆系统。它直接读取你 Google 账户里的 Gmail、Calendar、Maps 历史等现有数据。"找一家离我下次会议近的咖啡店"——它不需要"记住"你在哪,因为 Calendar 已经知道了。关闭 Gmail 连接 = 它立即停止知道你的邮件,没有"忘记"这个动作。
Anthropic
学会学习的代理工作流
OpenAI
你亲手训练的个人助手
构建在已有数据之上的智能层
ChatGPT Saved Memories 上线
Dreaming V0 内测,作为 saved memories 补充
Claude Dreaming Agent API 研究预览
Dreaming V3 正式上线(Plus/Pro 美国),数周内推全球
隐私问题:房间里的大象
OpenAI 官方博客花了大量篇幅讲 Dreaming 多好用、多准确,但关于隐私的具体内容——数据存储方式、保留期限、是否用于模型训练、第三方访问权限——几乎只字未提。
OpenAI 社区论坛上已有用户发帖讨论记忆系统的隐私顾虑。核心担忧集中在:AI 越能记住你,它知道的关于你的信息就越多,这些信息会被怎么处理?
Dreaming 让记忆从"你说一句它记一句"变成了"你在所有对话中的信息都会被后台分析整合"。信息采集的广度和深度都上了一个量级,但透明度并没有同步跟上。
核心矛盾:Memory Summary 页面提供了可见性和控制力,但它只能让你管理"AI 记住了什么",并不能回答"AI 用这些记忆做了什么"这个更深层的问题。
从记住偏好到预测需求:下一步是什么?
Dreaming 目前解决的还只是"别忘事"的问题。但记忆系统的终点不会止于此。
一旦 AI 对你的认知足够全面且准确,下一步自然就是预测性服务——你还没开口,它已经知道你今天可能需要什么。从"记住你爱吃素"到"主动帮你筛选附近新开的素食餐厅",中间只差一步。
OpenAI 在博客里明确提到了这个方向:Dreaming 是"为所有用户提供的共享记忆基础"。基础打好之后,上层可以长出很多东西。
从另一个角度看,Dreaming 也意味着 OpenAI 在押注一个趋势:AI 助手的价值将越来越取决于它对你的了解程度。谁的 AI 更了解你,谁的 AI 就更有用。这既是产品竞争力,也是用户锁定。
你愿意让 AI 多了解你一点,来换取更好的服务吗?
这个问题,Dreaming 只是刚刚把选择权推到了你面前。
END
