 夜雨聆风
夜雨聆风用大模型解析PDF,是很多开发者的噩梦。
公式乱码、表格错位、印章识别不了,遇到模糊、折皱或者手机拍照的文档,模型更是直接“装瞎”。特别是在端侧或边缘设备上部署的轻量化小模型,一顿操作猛如虎,一看效果惨不忍睹。
为了解决这些痛点,很多团队的选择是:堆参数、洗数据。但这条路不仅费钱,边际效应也越来越明显。
就在最近,百度 PaddlePaddle 团队交出了一份惊艳的答卷——开源了全新的轻量化多模态文档解析模型 PaddleOCR-VL-1.6。
在参数量依然死死卡在 0.9B(9亿)的前提下,它在权威文档解析榜单 OmniDocBench v1.6 上直接轰出了 96.33% 的综合高分,一举击败了 235B 的 Qwen3-VL、InternVL 3.5 (241B) 以及 Gemini 3 Pro 等一众“巨无霸”!
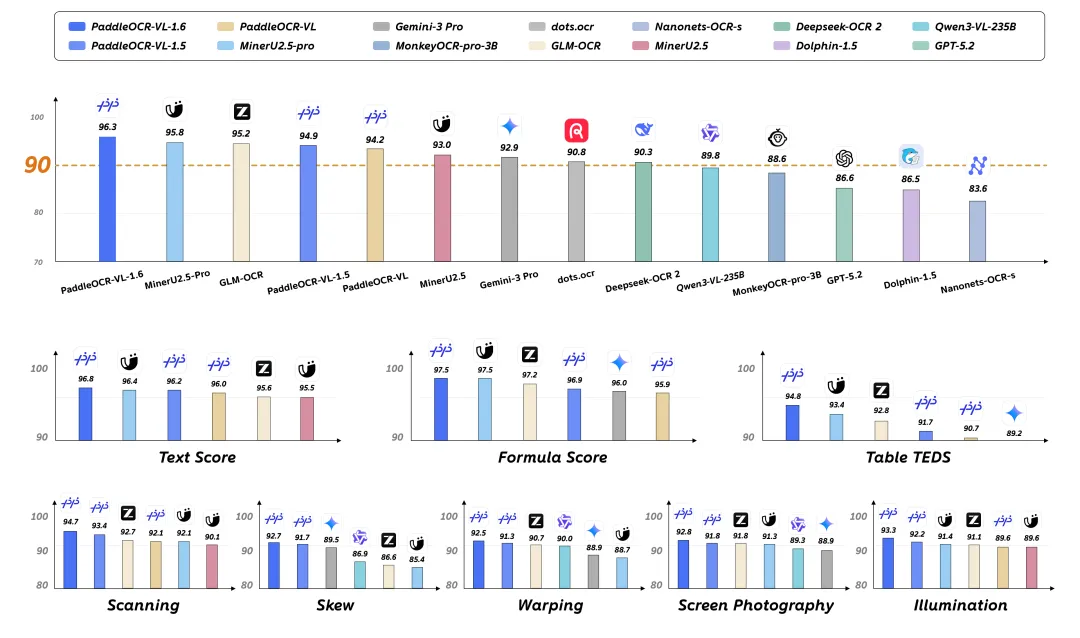
图 1:PaddleOCR-VL-1.6 在 OmniDocBench 上的卓越表现
这不禁让人好奇:百度到底是给这只 0.9B 的“小麻雀”喂了什么灵丹妙药,能让它爆发出了比千亿大模型还强悍的战力?
今天,我们就来深度扒一扒 PaddleOCR-VL-1.6 背后的硬核技术与“教科书级”的后训练秘籍。
一、 核心痛点:为什么盲目堆数据不灵了?
在 PaddleOCR-VL-1.5 时期,这个 0.9B 的小模型就已经打下了非常好的底子。当模型底座已经足够优秀时,剩下的错误往往不再是“均匀分布的噪声”,而是集中在一些“难啃的硬骨头”上。这些区域被称为“欠优化区域”(Under-Optimized Regions, UOR)。
这些区域通常有以下三个特征:
- 1. 模型预测不稳定:
图片稍微压缩一下,或者换个训练 checkpoint,输出就完全变了(边界脆弱)。 - 2. 数据极其稀缺:
像古籍、生僻字、特定工业表格等,在常规采样时很容易被“主流数据”给淹没(覆盖稀疏)。 - 3. 标签本身是脏的:
模型以极高的置信度做出了错误的预测,原因在于原始训练集里的标注本身就标错了(监督不可靠)。
如果只是一味地增加常规训练数据,不仅解决不了这些盲区,还会让小模型把宝贵的参数容量浪费在早已学会的“简单题”上。
因此,PaddleOCR-VL-1.6 的核心逻辑就是:精准定位这些“欠优化区域”,定向死磕!
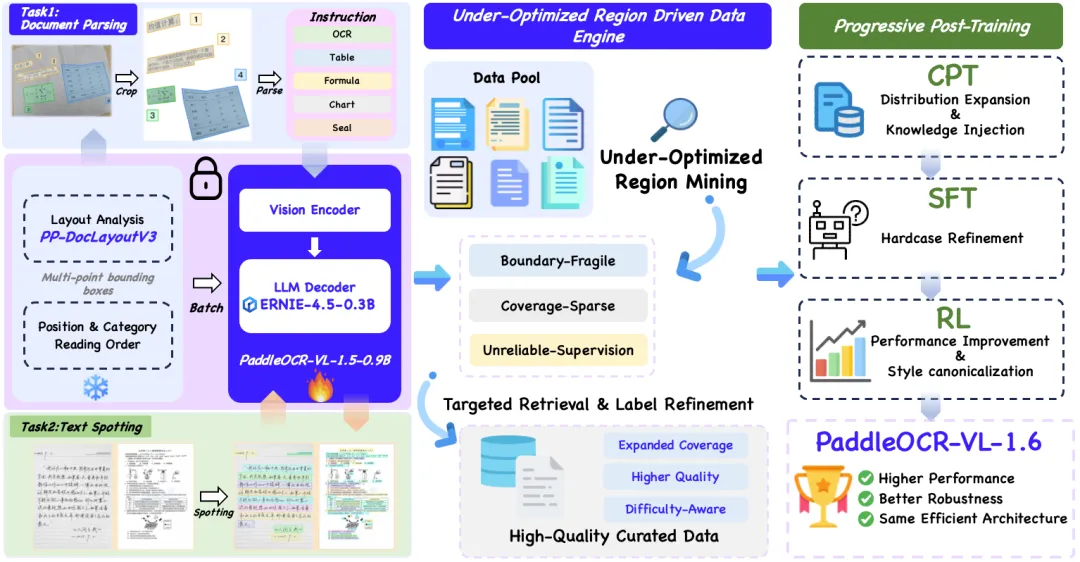
图 2:PaddleOCR-VL-1.6 的整体架构与升级路径
在架构上,它保留了 1.5 版本的轻量级搭配:集成了 Native Resolution 视觉编码器、Adaptive MLP 链接器,以及极轻量的 ERNIE-4.5-0.3B 语言模型。同时,配合负责高精度版面分析的 PP-DocLayoutV3,构成两阶段文档解析管线。不扩增参数,只精雕数据!
二、 三招制敌:UOR 数据引擎如何精准扫盲?
为了把这些“欠优化区域”挖出来,百度设计了一套精妙的 UOR 数据引擎:
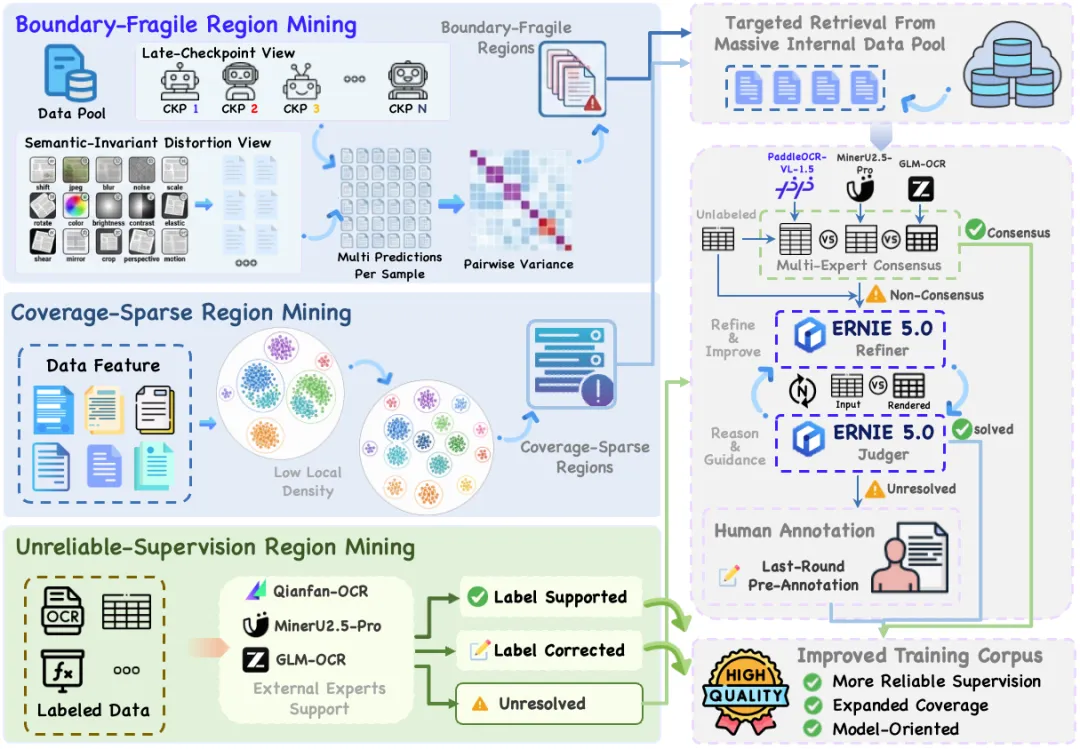
图 3:PaddleOCR-VL-1.6 Data Engine 运行机制
1. 揪出“一碰就碎”的边界脆弱区 (Boundary-Fragile Regions)
有些图片明眼看起来差不多,但只要稍微有些噪点或像素偏移,模型就会发生“退化”。这是因为模型尚未在对应的局部数据空间建立起稳健的映射。
百度的做法是:128次多视角交叉测试!
他们保留了训练后期已基本收敛的 8 个不同 checkpoint。 针对同一张图片,使用包括像素偏移、JPEG 压缩、高斯模糊、非均匀缩放等 16 种无损语义的畸变扰动。 这样一张图片就会产生 8 × 16 = 128个预测结果。计算这 128 个预测两两之间的归一化编辑距离。如果预测差异很大(脆弱性得分高),说明这个样本处于模型的“不稳定决策边缘”。 最终,挑出得分最高的 Top 1% 样本作为检索种子,去海量无标注文档库中检索相似的“高危样本”来喂饱模型。
2. 捞出“被主流掩盖”的覆盖稀疏区 (Coverage-Sparse Regions)
长尾的稀有版面或古籍数据很容易在海量常规数据中被稀释。
为了找出这些冷门数据,PaddleOCR-VL-1.6 引入了基于视觉语义邻域的“动态图割裂算法”:
它首先利用文档特征编码器提取所有样本的视觉特征,并计算余弦相似度。接着,构建关联图,并渐进式地调高相似度阈值,将图不断裂解为细粒度的聚类。这种聚类方式的好处在于,它不会强行把长尾样本塞进主流簇里,而是能清晰地暴露出特征空间里的孤立 outlier 小聚类。通过这种方式,团队定向补充了大量古籍、生僻字、工业图表等长尾数据。
3. 校正“指鹿为马”的监督不可靠区 (Unreliable-Supervision Regions)
训练集里难免有标错的“脏数据”,这会让模型越学越歪。
百度搞了个“背对背专家校验”:
他们引入了千帆 OCR (Qianfan-OCR)、GLM-OCR 和 MinerU 2.5-Pro 三个业界的顶尖专家模型,对原训练样本进行预测。如果原标签与至少一个专家一致,保留;如果原标签跟专家都不对,但有至少两个专家互相一致,那就用专家的共识结论直接替换/修正原标签;如果大家各执一词,则送入精修管线。
三、 黑科技:多专家共识 + 渲染引导的“判官”管线
对于那些专家们也统一不了意见的“疑难杂症”(如极度复杂的嵌套表格、满屏的微积分公式),如何生成高质量的标注?
PaddleOCR-VL-1.6 祭出了其自动化标注的“黑科技”——渲染引导的 Judge-and-Refine 管线。
在这个管线中,百度请出了拥有极强视觉推理能力的自回归多模态大底座 ERNIE 5.0 作为“大裁判”:
- 多专家初审:
ERNIE 5.0 第一次预测时,会同时参考三个专家模型的输出。 - 拒绝盲信,精修迭代:
在后续的修正迭代中,ERNIE 5.0 不再看专家的直接预测,而是聚焦于当前预测和上一步发现的差异,防止被错误偏见带偏。 - 渲染引导(降维打击):
先把模型生成的 HTML 或 LaTeX 渲染成图片,然后让 ERNIE 5.0 在“图片 VS 图片”的同模态视觉维度上进行对比!哪里行对齐歪了、哪里表格行列跨度不对,一目了然!
这种“图片对齐图片”的方式,让自动标注的精度达到了空前的水准,未通过的代码才会交由人工辅助微调,极大地保证了标签的纯净度。
四、 渐进式后训练:CPT -> SFT -> RL 的完美三部曲
有了高质量的数据,怎么训练才最有效率?PaddleOCR-VL-1.6没有选择简单粗暴地混合数据重头来过,而是采用了一套渐进式后训练(Progressive Post-Training)策略:
第一阶段:CPT(持续预训练)拓宽眼界
把所有 UOR 引擎捞出来的新版面数据(共 16.8M 样本)扔进模型,全参数解冻,以较高的学习率(3e-5)进行训练,让模型快速适应长尾新分布。
第二阶段:SFT(有监督微调)重点突破
聚焦在困难和纠错样本(如前文提到的专家无法共识、经过渲染精修的 7.3M 样本)。全参数解冻,以较小的学习率(1e-5),让模型把这些硬骨头死死啃下来。
第三阶段:RL(强化学习)临门一脚
在强化学习(RL)阶段,百度采用了 GRPO 算法。但众所周知,0.9B 的小模型做 RL 极其脆弱,容易学崩。为此,团队研发了**两大 RL 优化绝活**:
百度不用全量数据做 RL,而是用 SFT 模型先跑 16 次 rollout,对样本进行严格筛选:
1. 过滤“无药可救”的(最好的 rollout 成绩也极差)。
2. 过滤“躺赢”的(均值已经极高)。
3. 计算“高潜力得分”:
这里筛选出那些“上限高、均值一般、且生成过程存在不确定性”的样本。这说明模型有能力答对,但目前还不稳定,最需要 RL 鞭策。最终,每个任务仅挑出前 8K,共计 49K 黄金样本 参与 RL。
普通的“对错”二值奖励太稀疏,小模型根本学不会。百度设计了三合一的奖励公式:
其中,Valid 为严格的格式与截断的一票否决门控;Struct 负责对排版(如非矩形表格)进行微调惩罚;Sim 则根据各任务专业指标(表格 TEDS、公式 CDM、图表 RMS-F1)进行匹配打分,做到精细化奖励反馈。
五、 战绩大阅兵:实力到底有多硬?
经过这一整套组合拳,PaddleOCR-VL-1.6 在各项基准测试中展现出了极强的统治力。
1. OmniDocBench v1.6 权威榜单(端侧 SOTA)
在 OmniDocBench v1.6 上,它以 96.33% 的成绩傲视群雄:
数据来源:OmniDocBench 官方 Leaderboard
以 0.9B 的参数体量,在综合评分上压制了包含 GPT-5.2、Gemini 3 Pro 以及 235B 的 Qwen3-VL 在内的所有巨无霸!相较于 1.5 版本,其在最头疼的表格解析(Table-TEDS)上暴涨了 3.09%,公式识别也进一步提升。
2. 真实物理场景(Real5-OmniDocBench)
在模拟现实环境(倾斜、弯曲、阴影、屏幕拍照等)的 Real5-OmniDocBench 评测中,它取得了 93.19% 的 SOTA 战绩,同样力压 Qwen2.5-VL-72B (86.92%) 和 Gemini-2.5 Pro (88.21%)。这证明了其在实际物理采集环境中的顽强生命力!
3. 核心单项能力“全面开花”
无论是印章识别、复杂图表解析还是端侧定位,PaddleOCR-VL-1.6 都展现了碾压级的参数效率:
- 硬核表格识别:
在 In-house 困难表格集上,结构 TEDS 达到了 94.67,大幅领先其他小模型。 - 图表解析:
在 In-house 图表集上,以 91.74 的 RMS-F1 傲视 TinyChart 和 GOT 等一众专用图表模型。 - 印章识别:
最考验局部精细特征的 Seal 识别中,0.9B 参数 of PaddleOCR-VL-1.6 取得了 0.119 的 NED 成绩(越低越好),而 235B 的 Qwen3-VL 仅为 0.382。小模型实现了完美逆袭!
4. 消融实验:步步为营的验证
从消融数据来看,整个后训练的升级逻辑非常清晰:
- CPT 阶段:
引入长尾样本拓宽眼界并修正脏标签,给模型打下坚实的基础(综合分由 94.93 升至 95.62); - SFT 阶段:
死磕疑难与渲染精修样本,完成模型能力的爆发式跨越(综合分拉升至 96.25); - RL 阶段:
利用高潜力样本的 GRPO 强化学习,在模型早已极度逼近天花板的前提下,完成最后的点睛之笔(至 96.33)。
结语
百度 PaddleOCR-VL-1.6 的成功,给整个 AI 社区提供了一个极为珍贵的启示:
不要盲目迷信“模型越大越好”或“数据越多越灵”。 通过对“欠优化区域”进行精细的手术式诊断,配合多专家校验、同模态渲染精修,以及面向小模型定制的强化学习策略,小模型同样可以爆发出顺滑解析、降维打击千亿巨无霸的惊人能量。
对于急需低成本、高性能文档解析能力的开发者来说,这无疑是目前最值得关注的端侧文档解析天花板级方案。
目前,PaddleOCR-VL-1.6 的代码、模型已全部开源,赶紧去 HuggingFace 和 GitHub 上体验一把这只 0.9B 的“降维打击怪兽”吧!
虽然 PaddleOCR-VL-1.6 解析能力极为硬核,但其显存和内存开销却非常亲民。得益于极轻量的 0.9B(9亿)参数架构,您可以非常低成本地在各类设备上进行部署:
- 常规 CPU 平台(个人电脑/工控机):
推荐 Intel Core i5/i7/i9、Ryzen 5/7/9 或 Apple M 系列芯片,运行内存(RAM)建议 16GB 及以上。可配合 OpenVINO 或 ONNXRuntime 加速推理。 - 轻量 GPU 平台(消费级显卡/开发本):
推荐 NVIDIA GTX 1660 / RTX 3050 / RTX 4060 等(显存 ≥ 6GB)入门级显卡。FP16 模式下显存仅需约 3GB~4GB 即可流畅运行。 - 边缘嵌入式平台(智能终端):
支持在 NVIDIA Jetson Orin Nano (8GB) / Jetson Orin NX 等开发板上运行,非常适合端侧智能设备集成。 - 高并发服务器平台(云端部署):
推荐 NVIDIA Tesla T4、RTX 4090 或 A10/A30 显卡,可在极低延迟下实现大规模、多线程 of PDF 解析与版面分析服务。
GitHub 源码仓库: https://github.com/PaddlePaddle/PaddleOCR
HuggingFace 模型权重: https://huggingface.co/PaddlePaddle
你有什么好观点?欢迎评论区聊聊。
点个「关注」,一起追赶最前沿、最有趣的信息☝️
