我是小李,如今作为数据运营主管,带团队交付报表时最深刻的体会是:数据对不对,业务部门可能要核对半天才能发现;但报表丑不丑,领导和对接人一眼就能看出差距。- 表头没对齐、列宽挤成一团,领导第一句就是 “这表看着不清楚,重新整整”;
- 边框忽粗忽细、颜色杂乱,打印出来像 “没做完的草稿”,拿不出手;
- 没冻结窗口,汇报时一滚动就看不到字段名,手忙脚乱翻回去找列名;
- 为了 “好看” 乱用合并单元格,后续筛选、透视时全崩,数据团队怨声载道。
所以我们团队的固定交付流程早已标准化:pandas 把数据处理干净 → openpyxl 做最后的样式封装 → 输出即交付,既保证数据准确,又让报表专业得体,省去反复修改格式的内耗。作为数据运营主管,我梳理了团队从 “数据及格” 到 “交付优秀” 的核心美化需求,覆盖专业报表制作全流程,让数据不仅准确更具可读性,适配对内汇报、对外对接总部 / 客户等所有交付场景:- 基础样式:优化表头字体对齐、行高列宽,快速让报表从 “草稿” 变 “成品”,是性价比最高的美化操作;
- 高级样式:设置统一边框、层次化填充、精准合并单元格,让报表有边界、有重点,提升专业质感;
- 交互优化:添加冻结窗口、自动筛选器,让报表从 “能看” 升级为 “好用”,大幅提升业务同事使用体验;
- 单元格批量处理:实现连续相同项自动合并(优化展示层)、合并单元格拆分回填(还原数据层),平衡展示友好性与数据可分析性;
- 交付规范:明确样式设置的时机、合并单元格的使用原则,规避样式错乱、数据处理踩坑等返工问题,实现高效交付。
一、基础样式:字体 / 对齐 / 行高列宽
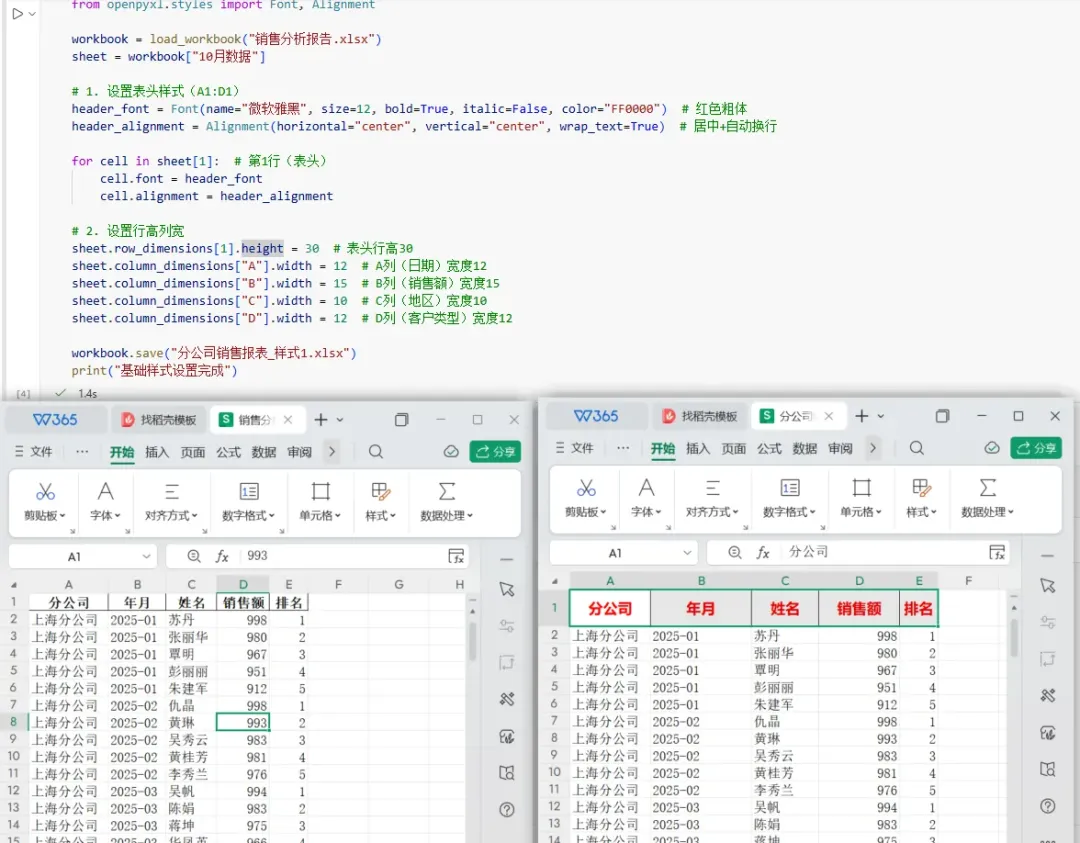
办公场景:团队刚用 pandas 算出 “10 月销售明细”,但表头像草稿:字体杂乱、没居中、列宽挤到一起,直接发出去显得不专业。需要快速优化基础样式,让报表第一眼就 “规整”。“请用 openpyxl 打开《销售分析报告.xlsx》的《10月数据》Sheet,把第1行表头设置为:微软雅黑、12号、红色、加粗;水平垂直居中并自动换行。再把第1行行高设为30,并设置A/B/C/D列宽分别为12/15/10/12。最后另存为新文件。”from openpyxl import load_workbookfrom openpyxl.styles import Font, Alignmentworkbook = load_workbook("销售分析报告.xlsx")sheet = workbook["10月数据"]# 1. 设置表头样式(A1:D1)header_font = Font(name="微软雅黑", size=12, bold=True, italic=False, color="FF0000") # 红色粗体header_alignment = Alignment(horizontal="center", vertical="center", wrap_text=True) # 居中+自动换行for cell in sheet[1]: # 第1行(表头) cell.font = header_font cell.alignment = header_alignment# 2. 设置行高列宽sheet.row_dimensions[1].height = 30 # 表头行高30sheet.column_dimensions["A"].width = 12 # A列(日期)宽度12sheet.column_dimensions["B"].width = 15 # B列(销售额)宽度15sheet.column_dimensions["C"].width = 10 # C列(地区)宽度10sheet.column_dimensions["D"].width = 12 # D列(客户类型)宽度12workbook.save("分公司销售报表_样式1.xlsx")print("基础样式设置完成")
1. 基础样式是 “性价比最高” 的美化操作:改完表头 + 列宽,报表立刻从 “草稿” 变 “成品”,团队新人也能快速上手;2. 建议只对 “最终交付文件” 做样式优化,不要对中间过程文件反复套样式 —— 后续增删列、筛选数据时,样式容易错乱,反而增加返工成本。二、高级样式:边框 / 填充 / 合并单元格
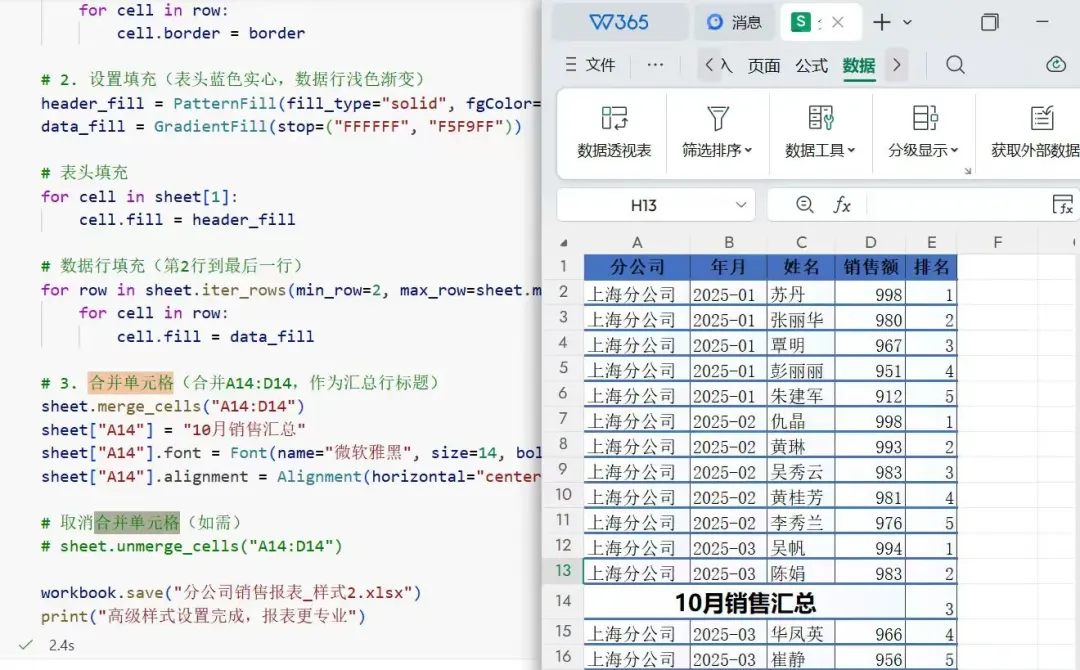
办公场景:要把月度销售汇总表发给总部 / 客户,需要让报表 “有边界、有层次”:整体边框统一、表头突出、数据区易读,还要给汇总行加合并单元格标题,让重点一目了然。请用 openpyxl 给《销售分析报告.xlsx》的《10月数据》设置高级样式:整表边框(左右细深灰、上下粗蓝);表头蓝色实心填充;数据行白到浅蓝渐变填充;并合并A14:D14写入‘10月销售汇总’,字体14号加粗居中。最后另存为新文件。from openpyxl.styles import Side, Border, PatternFill, GradientFillfrom openpyxl import load_workbookfrom openpyxl.styles import Font, Alignmentworkbook = load_workbook("销售分析报告.xlsx")sheet = workbook["10月数据"]# 1. 设置边框(给数据区域A1:D157加边框)thin_side = Side(style="thin", color="333333") # 细边框(深灰色)thick_side = Side(style="thick", color="4472C4") # 粗边框(蓝色)border = Border(left=thin_side, right=thin_side, top=thick_side, bottom=thick_side)for row in sheet.iter_rows(min_row=1, max_row=sheet.max_row, min_col=1, max_col=sheet.max_column): for cell in row: cell.border = border# 2. 设置填充(表头蓝色实心,数据行浅色渐变)header_fill = PatternFill(fill_type="solid", fgColor="4472C4") # 蓝色实心data_fill = GradientFill(stop=("FFFFFF", "F5F9FF")) # 白色到浅蓝色渐变# 表头填充for cell in sheet[1]: cell.fill = header_fill# 数据行填充(第2行到最后一行)for row in sheet.iter_rows(min_row=2, max_row=sheet.max_row, min_col=1, max_col=sheet.max_column): for cell in row: cell.fill = data_fill# 3. 合并单元格(合并A14:D14,作为汇总行标题)sheet.merge_cells("A14:D14")sheet["A14"] = "10月销售汇总"sheet["A14"].font = Font(name="微软雅黑", size=14, bold=True)sheet["A14"].alignment = Alignment(horizontal="center")# 取消合并单元格(如需)# sheet.unmerge_cells("A14:D14")workbook.save("分公司销售报表_样式2.xlsx")print("高级样式设置完成,报表更专业")
三、冻结窗口与筛选器
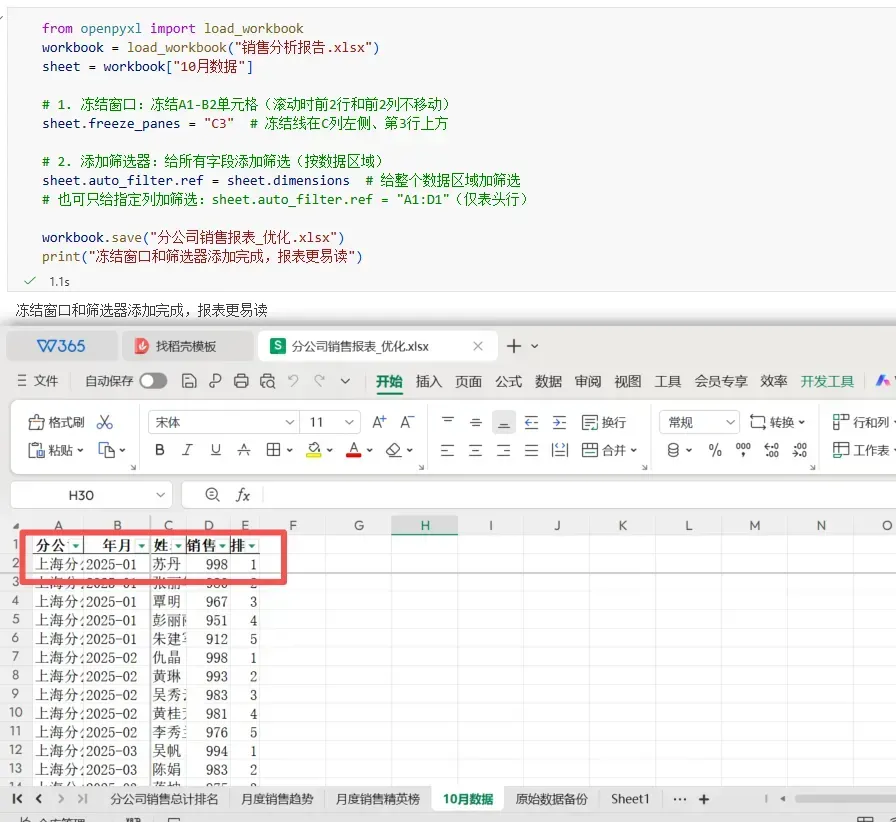
办公场景:在部门汇报会上,你滚动销售报表展示明细,表头跟着消失,领导突然问 “这列是哪个地区的销售额?”,你只能尴尬地往上翻;发给业务同事后,他们第一件事就是手动加筛选 —— 冻结窗口 + 自动筛选,是报表从 “能看” 到 “好用” 的分水岭。“请用 openpyxl 给《分公司销售报表.xlsx》的《10月销售》Sheet 设置冻结窗口:冻结前2行和前2列(freeze_panes=C3)。并对整个数据区域添加自动筛选(auto_filter.ref=sheet.dimensions)。保存为新文件。”from openpyxl import load_workbookworkbook = load_workbook("分公司销售报表.xlsx")sheet = workbook["10月销售"]# 1. 冻结窗口:冻结A1-B2单元格(滚动时前2行和前2列不移动)sheet.freeze_panes = "C3" # 冻结线在C列左侧、第3行上方# 2. 添加筛选器:给所有字段添加筛选(按数据区域)sheet.auto_filter.ref = sheet.dimensions # 给整个数据区域加筛选# 也可只给指定列加筛选:sheet.auto_filter.ref = "A1:D1"(仅表头行)workbook.save("分公司销售报表_优化.xlsx")print("冻结窗口和筛选器添加完成,报表更易读")
1. freeze_panes="C3" 的核心逻辑:冻结线以上(前 2 行)和左侧(前 2 列)固定,适合 “表头 + 关键维度列” 需要常驻的场景;如果只需要冻结表头,用 freeze_panes="A2"(仅冻结第一行)即可;2. 筛选器建议覆盖整个数据区域(sheet.dimensions),无论数据量增减,都能自动适配,无需手动调整筛选范围;3. 这两个功能是团队交付报表的 “必加项”,看似简单,却能极大提升业务同事的使用体验,减少后续咨询。四、单元格批量合并与拆分
合并单元格是把 “双刃剑”:对人友好(展示清晰),对机器不友好(数据处理困难)。作为数据运营主管,我要求团队遵循 “展示层合并,数据层拆分” 的原则 —— 对外交付用合并单元格优化展示,对内分析前先拆分恢复数据完整性。4.1 单元格合并:连续相同项自动合并
办公场景:制作《产品销售清单》时,同一个客户会连续出现多行(对应不同产品),人工通常会把客户名称合并起来,让报表更 “规整”。但 Sheet 多、行数多时,手动合并效率低还易出错,需要批量自动化合并。“请写一个函数:对指定列把连续相同的单元格自动合并。然后遍历《产品清单.xlsx》所有 Sheet,从第6行开始读取B列客户名称、C列产品编码,对连续相同的区域分别执行合并,保存为《产品清单-合并单元.xlsx》。”from openpyxl import load_workbook # 用于读取和操作Excel文件def Merge_cells(ws, target_list, start_row, col): """ 合并工作表中指定列的连续相同单元格 参数: ws: openpyxl工作表对象 target_list: 包含待合并数据的列表(如 ['A', 'A', 'B', 'B', 'B']) start_row: 开始合并的行号(从1开始计数) col: 需要合并的列字母(如 'B', 'C') 实现逻辑: - 遍历列表,找出连续相同的元素区间 - 对每个区间执行单元格合并操作 - 例如:['A', 'A', 'B', 'B', 'B'] → 合并前2个A,后3个B """ # ====================== # 1. 初始化变量 # ====================== start = 0 # 开始行计数,对应列表中的索引位置 end = 0 # 结束行计数,对应列表中的索引位置 reference = target_list[0] # 设定基准值,以列表第一个元素开始比较 # ====================== # 2. 遍历目标列表 # ====================== for i in range(len(target_list)): # 遍历列表中的每个元素 # ====================== # 3. 检查当前元素是否与基准不同 # ====================== if target_list[i] != reference: # 如果当前元素与基准不同 reference = target_list[i] # 更新基准为当前元素 end = i - 1 # 设置当前区间的结束位置 # ====================== # 4. 执行单元格合并 # ====================== # 构造合并范围:col + str(start + start_row) + ":" + col + str(end + start_row) # 例如:start=0, start_row=6 → 起始行6;end=1, start_row=6 → 结束行7 # 最终范围:"B6:B7" 表示合并B列的第6行到第7行 merge_range = col + str(start + start_row) + ":" + col + str(end + start_row) ws.merge_cells(merge_range) # 执行合并操作 start = end + 1 # 设置下一个区间的开始位置 # ====================== # 5. 处理最后一个区间 # ====================== if i == len(target_list) - 1: # 如果是列表的最后一个元素 end = i # 设置结束位置为当前索引 # 合并从当前start到end的区间 merge_range = col + str(start + start_row) + ":" + col + str(end + start_row) ws.merge_cells(merge_range)# ======================# 主程序:读取Excel并执行合并# ======================# 加载Excel文件wb = load_workbook('产品清单.xlsx')# ======================# 1. 获取所有工作表名称# ======================# get_sheet_names() 已被弃用,建议使用 wb.sheetnames# 但为了保持原代码兼容性,这里继续使用sheet_names = wb.get_sheet_names()# ======================# 2. 遍历每个工作表# ======================for sheet_name in sheet_names: # 遍历每个工作表 # 获取当前工作表对象 ws = wb[sheet_name] # ====================== # 3. 初始化数据列表 # ====================== customer_list = [] # 存储客户名称的列表 pn_list = [] # 存储产品编码的列表 # ====================== # 4. 读取指定范围的数据 # ====================== # 从第6行到倒数第3行(ws.max_row-2),读取B列和C列的数据 for row in range(6, ws.max_row - 2): # range(6, max_row-2) 表示从第6行开始到倒数第3行结束 # 读取B列(客户名称)的数据 customer = ws['B' + str(row)].value # 例如:'B6', 'B7', 'B8'... # 读取C列(产品编码)的数据 pn = ws['C' + str(row)].value # 例如:'C6', 'C7', 'C8'... # 将数据添加到对应列表 customer_list.append(customer) pn_list.append(pn) # ====================== # 5. 执行单元格合并 # ====================== start_row = 6 # 定义开始合并的行号为第6行 # 合并B列(客户名称)中连续相同的单元格 Merge_cells(ws, customer_list, start_row, "B") # "B" 表示客户名称在B列 # 合并C列(产品编码)中连续相同的单元格 Merge_cells(ws, pn_list, start_row, "C") # "C" 表示产品编码在C列# ======================# 6. 保存结果# ======================# 将修改后的工作簿保存到新文件wb.save("产品清单-合并单元.xlsx")print("✅ 单元格合并完成!结果已保存到 '产品清单-合并单元.xlsx'")
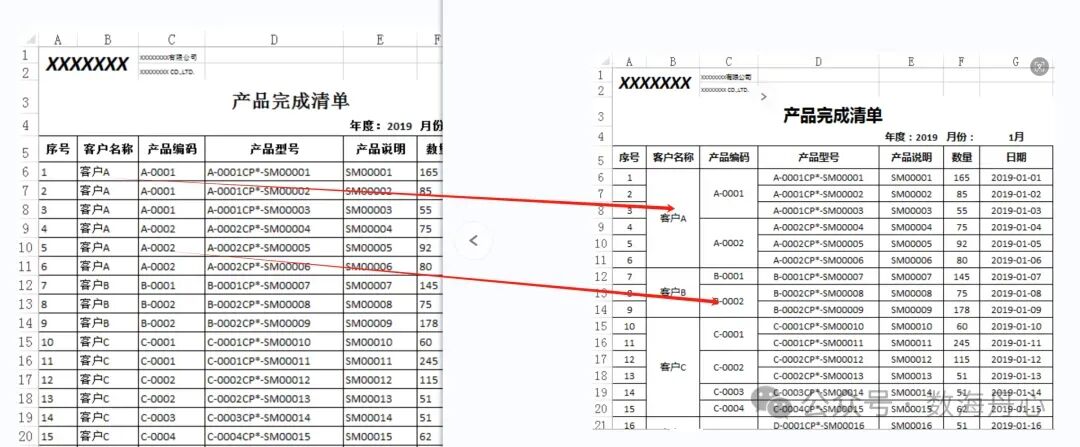 1. 连续相同项合并的关键前提:相同内容必须连续排列,如果数据本身乱序,需先排序再合并,否则合并结果不符合业务直觉;2. 合并仅用于 “对外展示报表”,对内分析、数据导入系统前,务必拆分回填,避免数据丢失。
1. 连续相同项合并的关键前提:相同内容必须连续排列,如果数据本身乱序,需先排序再合并,否则合并结果不符合业务直觉;2. 合并仅用于 “对外展示报表”,对内分析、数据导入系统前,务必拆分回填,避免数据丢失。4.2 单元格拆分:取消合并并回填值
办公场景:业务部门发来的《产品清单 - 合并单元.xlsx》用了大量合并单元格,团队要基于这份数据做销售分析,用 pandas 读进来后发现大量 NaN—— 合并区域只有左上角有值,其他单元格为空,导致分组统计、透视表结果失真。所以只要进入 “数据分析 / 多表合并” 环节,第一步就是 “拆分 + 回填”。“请写一个安全版函数:遍历 Excel 所有 Sheet,把所有合并单元格取消合并,并将合并区域左上角的值填充到拆分后的每个单元格。最后另存为新文件,并做异常捕获与资源关闭。”import openpyxlfrom openpyxl.utils import get_column_letterdef unmerge_all_cells(file_path, output_path): """ 安全版:拆分Excel文件中所有工作表的合并单元格 参数: file_path (str): 源文件路径 output_path (str): 输出文件路径 """ try: # 加载工作簿 book = openpyxl.load_workbook(file_path) # 遍历所有工作表 for sheet_name in book.sheetnames: sheet = book[sheet_name] # 获取合并单元格范围 merged_ranges = sheet.merged_cells.ranges.copy() for merged_range in merged_ranges: # 获取原始值 start_cell = merged_range.start_cell original_value = start_cell.value # 拆分单元格 sheet.unmerge_cells(range_string=merged_range.coord) # 填充原始值到所有拆分后的单元格 for row_idx, col_idx in merged_range.cells: cell = sheet.cell(row=row_idx, column=col_idx) cell.value = original_value # 保存结果 book.save(output_path) print(f"✅ 处理完成!结果已保存到: {output_path}") except Exception as e: print(f"❌ 处理失败: {e}") finally: if 'book' in locals(): book.close()# 使用增强版函数# unmerge_all_cells("产品清单-合并单元.xlsx", "test02.xlsx")
1. 拆分回填是 “让数据恢复可分析形态” 的关键动作,建议做成团队通用预处理脚本,所有外部接收的报表先过一遍,避免后续分析踩坑;2. 回填后的数据无 NaN,用 pandas 读取后可直接做分组、透视、合并,效率翻倍,错误率显著降低。
做报表,数据准确是底线,排版专业是上限。很多人花几小时核对数据,却忽略了最后一步的美化,导致辛苦做的成果不被认可,实在可惜。以上这套 Excel 美化系统,覆盖了 90% 的交付场景,代码可直接复制使用,新手也能快速上手。建议收藏转发,下次做报表再也不用被领导催着“重新整整”!我是小李,持续分享数据运营实战干货,关注我,少走数据弯路✨
 夜雨聆风
夜雨聆风