 夜雨聆风
夜雨聆风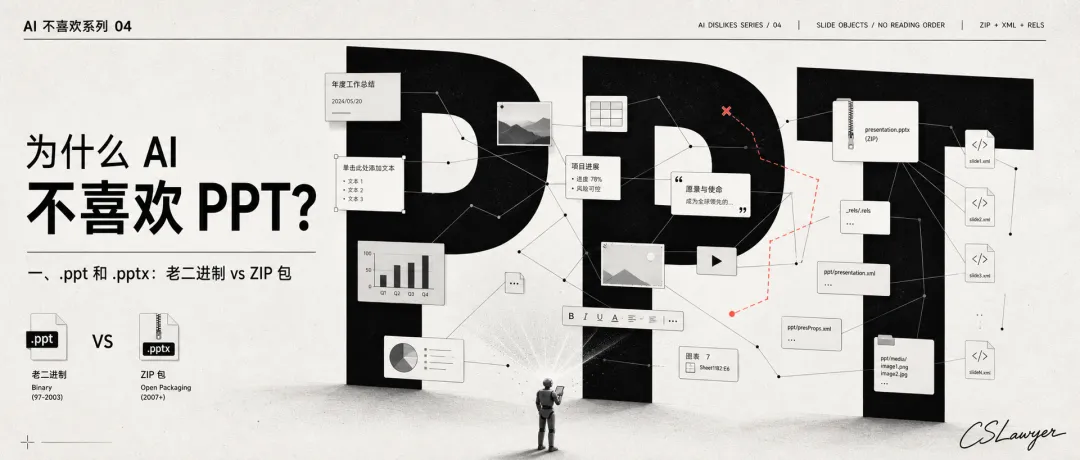
▲ 封面
"AI 不喜欢系列"第四篇。前三篇写了 .docx(装修好的办公室)、PDF(办公室的高清照片)、.xlsx(塞满便签和公式的工作台)。这一篇讲 PPT——和前三个都不一样。
.docx 至少还有段落。PDF 至少还有页面。.xlsx 至少还有网格。
PPT 连这些都没有。它是一堆独立画布,每张画布上随意散落着文本框、图片、图表和形状。没有阅读顺序,没有数据模型,没有语义层级。
一、.ppt 和 .pptx:老二进制 vs ZIP 包
和 Excel 一样,先分清两种格式。
.ppt 是老式二进制格式。 PowerPoint 97-2003 时代的产物,基于 OLE 复合文档结构。纯二进制,改 .zip 解不了,依赖专门解析器。
.pptx 是 ZIP + XML 格式。 PowerPoint 2007 之后的默认格式。把 演示.pptx 改成 演示.zip,解压后:
[Content_Types].xml
\_rels/
docProps/
ppt/
核心在 ppt/ 目录:
ppt/presentation.xml — 演示文稿结构
ppt/slides/slide1.xml — 第一页幻灯片
ppt/slides/slide2.xml — 第二页幻灯片
ppt/notesSlides/notesSlide1.xml — 第一页的演讲者备注
ppt/slideLayouts/ — 版式定义
ppt/slideMasters/ — 母版定义
ppt/theme/theme1.xml — 主题
ppt/media/ — 图片、音频、视频
ppt/charts/ — 图表数据
和 .docx、.xlsx 一样的配方:ZIP 壳 + XML 肉 + 关系文件做胶水。
但 PPT 有个其他格式没有的问题:它的内容分布在几十个独立文件里,每个文件之间靠关系文件(.rels)串联。而且一张幻灯片内部的文本框、图片、形状,彼此之间没有明确的先后顺序——它们只是被"放在"页面上的独立对象。
二、人类为什么喜欢 PPT?
PPT 不是为了精确记录而设计的。它是为了说服。
它的核心能力是:把复杂信息压缩成可视化的、有说服力的叙述。文字 + 图表 + 图片 + 动画,逐页推进,引导听众注意力。
法律和商业场景里,PPT 承担着 Word 和 Excel 都做不了的事:案件汇报、客户方案展示、项目路演、庭审可视化、内部培训、专家报告摘要、法律产品介绍、年会总结。
人类喜欢 PPT,是因为它能把一个复杂的故事讲得简单好看。一页一个观点,一页一个逻辑推进,视觉冲击辅助记忆。
但"讲得简单好看"这件事,恰好是 AI 最难理解的。
三、AI 为什么头疼?七个核心问题
1. 内容是碎片,不是连续文本
Word 里有一段话:"甲方应于合同签订后 15 日内支付第一期款项,金额为人民币 100 万元。"
PPT 里这句话可能被拆成四个独立的文本框:
文本框 1(顶部标题):付款节点
文本框 2(左侧):甲方应在合同签订后
文本框 3(中间大字):15 日
文本框 4(底部):支付第一期款项 ¥1,000,000
人类看这一页,视觉上自动把它们拼成完整信息。AI 看到的却是四个毫无关联的对象——它们之间没有"谁先谁后""谁属于谁"的标记。
更麻烦的是,AI 连应该按什么顺序读都不知道。左上到右下?标题先读?大字先读?没有标准答案。

▲ 示意图
2. 阅读顺序:PPT 的元问题
Word 有自然的阅读顺序:从上到下,从左到右。Excel 有明确的网格坐标。PDF 至少按页面排列。
PPT 没有。一张幻灯片上的每个元素——文本框、图片、形状、图表——都独立地放在一个绝对坐标上。哪个在前、哪个在后、哪个属于哪个,全凭人类视觉判断。
AI 面对一张幻灯片时,要做的事情比"读文字"复杂得多:先识别所有独立元素,再推断它们之间的逻辑关系,再决定以什么顺序拼接成可理解的文本。每一步都可能出错。
3. SmartArt 和图表:视觉修辞,不是数据
PPT 里的图表和 Excel 里的图表是两回事。
Excel 图表背后有数据源——改一个数字,图就跟着变。
PPT 里的图表经常是"拍扁"的。粘贴进来的 Excel 图表变成了一组独立形状。SmartArt 流程图、组织结构图、时间线——在 PPT 内部是若干个矩形、箭头和文本框的组合,不是结构化数据。
AI 看到 SmartArt 时,看到的不是"三个步骤的流程",而是几十个独立形状散落在页面上。推断它们组成一个流程图——这是视觉理解,不是文本解析。
4. 动画和逐条显示
PPT 的动画能力意味着:一张幻灯片上的内容,可能不是"同时可见"的。
第一条(点击后出现)
第二条(点击后出现)
第三条(点击后出现)
演讲者逐条展开,控制信息节奏。但 AI 读取 .pptx 时,看到的是"这个 slide 上有三条文字"——它不知道这三条是依次出现的,也不知道它们之间的递进关系。
更隐蔽的是:有些内容在动画里"出现后又消失了"。人类看现场演示时知道那段话是过渡性的,AI 看文件时无法区分。
5. 演讲者备注:藏在暗处的最重要信息
做 PPT 的人都知道一个秘密:真正的干货不在幻灯片上,在备注里。
幻灯片上写的是"Q3 收入增长 15%"。备注里写的是"这个数字含一次性项目,实际同口径只增长 3%,讲的时候不要展开,客户问到再补充。"
AI 处理 PPT 时,要不要读备注?读了,怎么和幻灯片内容对应?不读,丢了最关键的上下文。
而且备注是逐页独立的——备注页 1 对应 slide 1,备注页 2 对应 slide 2——没有跨页的连贯叙事。AI 需要自己把备注和幻灯片内容缝合起来,同时判断:哪些备注是演讲提示(可以忽略),哪些备注是实质性补充(必须纳入理解)。
6. 母版和版式:全局样式在别处
PPT 的字体、颜色、背景、占位符通常不在每一页里定义,而在母版和版式中。
一页幻灯片上你看到的是"标题:项目背景",它的字体是 28pt 微软雅黑,颜色是深蓝。这些信息可能来自三层继承:演示文稿主题 → 母版 → 具体版式。
AI 只读 slide.xml,可能拿不到完整样式信息。而样式在 PPT 里有时候是语义信号——比如"红色标题 = 风险提示""灰色文字 = 参考信息"。
7. 图片里的文字:PPT 最爱用截图
PPT 是人类把"别的格式"塞进来的万能容器。
合同关键条款截图、判决书片段截图、财务数据截图、微信聊天记录截图、网页截图、地图截图——这些在 PPT 里司空见惯。它们是图片,里面的文字不在任何 XML 里。
AI 读 PPT 时,图片就是图片。要理解里面的文字,得对每张图单独做 OCR。而 PPT 里的截图质量往往不高——压缩过的、调整过尺寸的、加了滤镜和边框的——OCR 准确率更低。
四、PPT 和前面三个格式:一张对比表
| 格式 | 内容单元 | 阅读顺序 | AI 的核心困难 |
|---|---|---|---|
| .docx | 段落 | 从上到下 | 文本被样式切碎 |
| 页面 | 从左上到右下 | 坐标文字,缺少语义 | |
| .xlsx | 单元格 | 行列网格 | 合并单元格、公式、颜色 |
| .pptx | 文本框/形状/图片 | 无固定顺序 | 碎片对象 + 视觉排版 + 备注分离 |
PPT 是唯一一个连"从哪开始读"都需要 AI 自己猜的格式。
五、法律场景里的 PPT
PPT 在法律工作中比外人想象的常见得多:
案件汇报。 案情摘要、争议焦点、证据索引、法律依据——做成十几页 PPT 给合伙人或客户汇报,比递一份 50 页的法律意见书高效得多。但这种 PPT 往往信息密度极高,每一页都有多个文本框、时间线图表、证据关系图。
庭审可视化。 用图表、时间线、关系图向法庭展示案情脉络。这些幻灯片上的内容不是文章逻辑,是视觉论证逻辑——AI 提取后如果只是按文本框顺序堆砌,论证结构就塌了。
客户方案。 律师的服务方案、项目建议书、报价说明,经常以 PPT 交付。里面的组织架构图、项目时间线、服务清单,都是视觉化信息。
培训课件。 法律培训、内部知识分享、新人入职培训——PPT 是主力格式。但如果想把培训内容结构化入库让 AI 做知识管理,PPT 直接丢进去的效果很差。
这些场景里有一个共同矛盾:PPT 被当成"交付物",但它的原生形态不适合 AI 直接理解和检索。
六、AI 的格式偏好(加入 PPT)
从最好到最差:
最友好:Markdown / TXT / JSON / CSV
较友好:规范 docx、规范 xlsx、规范 HTML
一般:普通 docx、普通 xlsx、普通 PDF 文本版
较差:复杂排版 PDF、扫描 PDF、复杂 xlsx、.pptx
最差:.ppt(老式二进制)、扫描 PDF 里的表格、低清拍照 PDF
.pptx 的问题不在于"读不到内容"——技术上提取文本框文字不难。问题在于提取到的内容失去了结构和语境。文本框散落,顺序丢失,备注分离,图片文字遗漏,动画逻辑消失——文字都在,但已经不是原来的意思了。
七、正确的使用方式
不要不用 PPT。PPT 是人类沟通的顶级工具。但要清楚它适合什么、不适合什么。
PPT 适合的:演示和汇报、视觉化论证、辅助演讲叙事、方案展示——一句话,适合"对着一群人讲"的场景。
PPT 不适合的:作为 AI 的知识来源、作为文档数据库的原生格式、作为需要精确检索和对比的文本载体。
如果 PPT 里包含需要被 AI 理解和检索的信息,正确的做法是:
PPT 原件(保留,给人讲)
↓ 提取每页的文本框 + 备注
↓ 按演讲逻辑重组成连续文档
↓ 图片中的文字单独 OCR 并入正文
↓ 输出 Markdown / JSON
↓ 交给 AI 分析或入库检索
也就是:PPT 做"展示层",Markdown 做"理解层"。各司其职。
八、四篇系列收束
写了四个格式,规律很清楚了:
| .docx | .xlsx | .pptx | ||
|---|---|---|---|---|
| 本质 | ZIP + XML 文档包 | 固定版面电子纸 | ZIP + XML 表格包 | ZIP + XML 幻灯片包 |
| 人用它做什么 | 编辑、批注、协作 | 归档、签章、交付 | 计算、台账、分析 | 演示、说服、汇报 |
| AI 为什么头疼 | 文本被样式切碎 | 坐标代替语义 | 合并单元格+公式+颜色 | 内容碎片化+无阅读顺序 |
| 一句话 | 装修好的办公室 | 办公室的高清照片 | 塞满便签和公式的工作台 | 散落着便利贴的故事板 |
四种格式,一个底层逻辑:格式越是为"人眼观看"和"人工操作"优化的,对 AI 就越不友好。
不是格式的错。是它们诞生的时候,没人在意机器怎么读。
所以今天最务实的做法不是抛弃这些格式——在法律行业做这件事不现实。而是建立一条清晰的转换层:人用 Office 格式办公和交付,机器用结构化文本理解和分析。不要让 PPT 直接当 AI 的知识库,不要让 PDF 直接当 AI 的工作底稿,不要让 Excel 的合并单元格裸奔进 RAG 系统。
各取所需,互不耽误。
作者简介: 陈石律师,浙江海泰律师事务所副主任、高级合伙人、房地产与建设工程部主任,宁波市律师协会副秘书长、第七届宁波仲裁委员会仲裁员,聚焦建筑房地产、投融资、并购重组及商事争议解决。曾获多家法律媒体与专业机构认可,荣登 LegalOne 2025 中国区建工及房地产实务先锋 45 强、律新社 2025 年度管理合伙人 20 佳(华东),入选《商法》The A-List 法律精英,获评 ALB China 区域市场十五佳长三角地区律师新星,并获律新社 2024 年度并购领域品牌之星。长期为万科、华润置地、信达地产、保利置业、招商蛇口、中海地产等企业提供法律服务,承办"首宗百亿地王""长春第一高楼""台州第一高楼"等代表性项目,累计服务项目投资额超千亿。近年来持续推动 AI 与法律实务融合,强调以结构化方法打通技术逻辑、法律判断与商业场景;著有《赋能法律人:AI 底层思维与应用范式》,并在多地开展相关主题讲座与分享。四明山法师 AI 夜校(legalAGI.cn)发起人。
