 夜雨聆风
夜雨聆风本期摘要
AI把所有文字都切成Token碎片,用向量表示。它不知道"猫"长什么样,只知道"猫"这个Token和"动物""宠物"的向量距离近。这是AI理解语言的底层逻辑。
上篇回顾
大模型训练三步:预训练(学语言)、SFT(学对话格式)、RLHF(学说人话)。缺一不可,RLHF是ChatGPT成功的关键。
你正在读的这些字,每一个字AI都"见过"。但AI完全不认识这些字。
人类看到"猫",脑子里会浮现一只毛茸茸的小动物。AI看到"猫",只是一个编号和一个向量——一串几千维的数字。
这听起来很抽象,但理解这一点,是理解AI所有行为的基础。
一、人类和AI看到同一个字,看到的是完全不同的东西
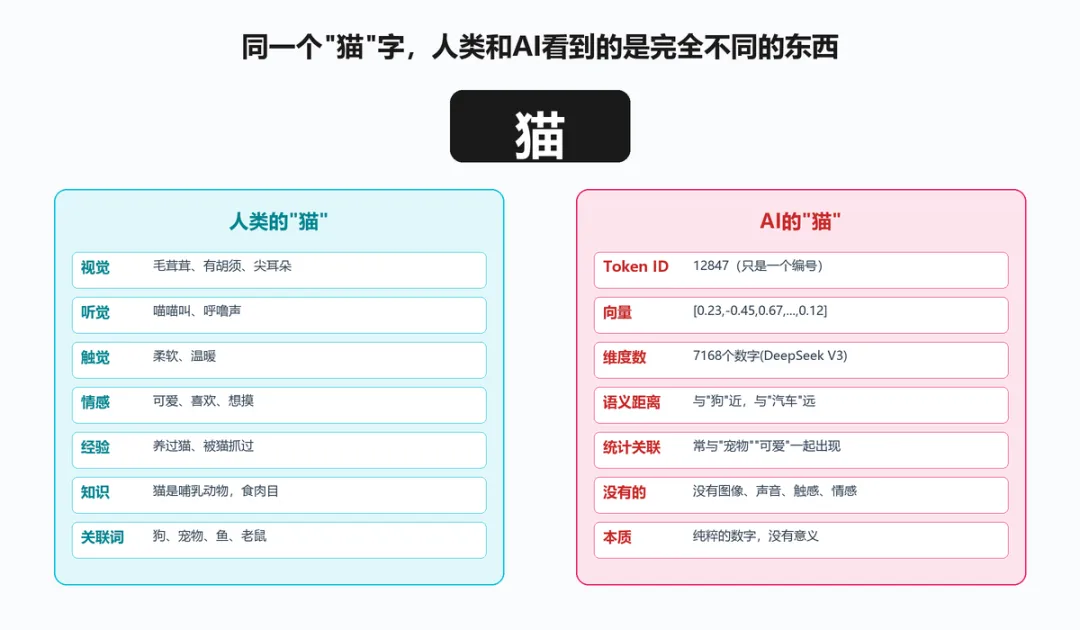
▲ 人类vs AI对"猫"字的不同理解
让我们做一个对比实验。
人类看到"猫"字
你的大脑会调动大量信息:视觉(毛茸茸、尖耳朵)、听觉(喵喵叫)、触觉(柔软温暖)、情感(可爱、喜欢)、经验(养过猫、被猫抓过)、知识(哺乳动物、食肉目)。这些是你从小到大积累的真实世界经验。
AI看到"猫"字
AI拥有的只有:Token ID(一个编号),以及对应的Embedding向量——一个几千维的数组,比如[0.23,-0.45,0.67,...,0.12]。这串数字代表"猫"这个Token在向量空间中的位置(DeepSeek V3是7168维,GPT-3是12288维,GPT-4维度未公开)。没有图像、没有声音、没有情感、没有真实经验。
这就是AI和人类最根本的区别:人类的理解是基于真实世界的经验,AI的理解是基于文本中的统计关联。
AI不知道"猫"长什么样、摸起来是什么感觉、喵喵叫是什么声音。它只知道"猫"这个Token经常和"可爱""宠物""毛茸茸""喵喵叫"这些Token一起出现。
它不是"理解"了猫,而是"记住"了"猫"和其他词的共现模式。
二、Token:AI的最小处理单位
在变成向量之前,文字首先要被切成Token。Token是AI的最小处理单位——一个Token可能是一个完整的词,也可能是半个词,也可能是一个汉字。
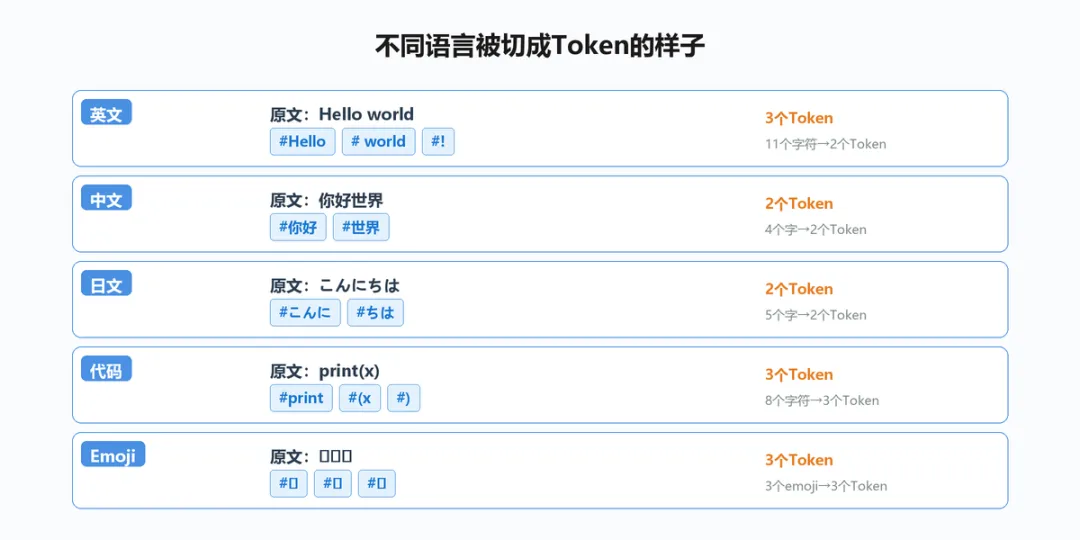
▲ 不同语言的Token切分示例
不同语言被Tokenizer切分的方式不同:
英文
英文Tokenizer很高效。常见词(hello、the、world)都是一个Token。只有生僻词才会被切成多个Token(比如"antidisestablishmentarianism"可能被切成5-6个)。英文的Token效率很高。
中文
中文Tokenizer的效率取决于词表。常见双字词(你好、世界)可能被打包成一个Token。但单字和生僻词各是一个Token。整体来说,中文的Token数通常比英文多30-50%表达同样的内容。
代码
代码模型的Tokenizer针对编程语言优化。关键字(print、if、for)是单独的Token,变量名会被切成子词。这使得AI处理代码时Token效率和英文差不多。
Emoji
每个emoji通常是一个Token。这是因为emoji在Unicode中有独立的码位,Tokenizer可以直接识别。
理解Token有一个很实际的意义:API按Token收费,不是按字数收费。同样意思的内容,中文比英文贵,因为中文需要更多Token。
这也解释了为什么AI处理生僻人名、专业术语时成本高——这些低频内容会被切成多个Token,占用更多上下文空间。
三、向量空间:AI的"概念地图"
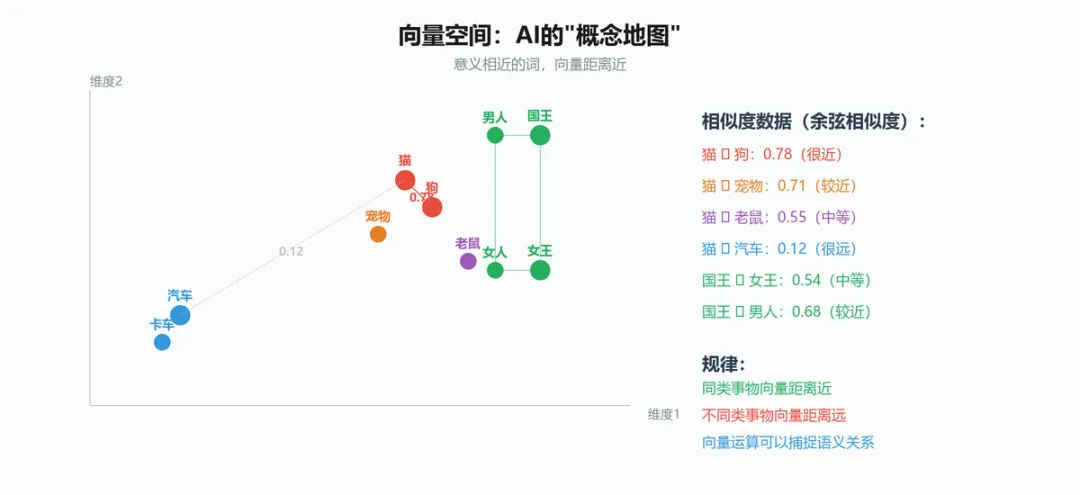
▲ 向量空间中的语义距离示意
Token ID只是编号,真正让AI"理解"语义的是Embedding向量——每个Token对应一个高维向量。
DeepSeek V3的向量是7168维,GPT-3是12288维(GPT-4之后OpenAI不再公开维度)。每一维代表某种抽象特征。这些特征不是人工定义的,是模型在预训练过程中自动学习到的。
向量空间的魔力在于:意义相近的词,向量在空间中的距离也近。
举几个示意性的例子(数值用于说明规律,非精确实测):
同类事物距离近:
猫 ↔ 狗:0.78(都很高,同为宠物)
猫 ↔ 宠物:0.71(语义相关)
猫 ↔ 老鼠:0.55(有关联但不是同类)
不同类事物距离远:
猫 ↔ 汽车:0.12(几乎无关)
猫 ↔ 量子力学:0.05(完全无关)
猫 ↔ 香蕉:0.08(无关)
神奇的向量运算:
vec(国王) - vec(男人) + vec(女人) ≈ vec(女王)(结果向量最接近"女王")
这个向量运算"国王-男人+女人≈女王"是Word2Vec论文(2013年)中的经典发现,揭示了向量空间能编码语义关系。现代大模型的Embedding维度更高、关系更复杂,但"相似概念在空间中相邻"这个核心规律一脉相承。
这不是人工设计的,是模型在预训练过程中自动涌现的。模型在学习预测下一个词的过程中,不知不觉学会了把相似概念放在向量空间中的相邻位置。
这个向量空间,就是AI的"世界观"。AI的所有"知识"、"理解"、"推理",都建立在这个向量空间之上。
四、AI不懂"意义",只懂"关联"
这是整篇文章最重要的一个概念,希望你认真读这一段:
AI不知道"猫"是什么,它只知道"猫"这个Token经常和"可爱""宠物""毛茸茸"一起出现。
这是统计关联,不是真正的理解。
类比一下:假设你是一个外国人,从来没见过猫。你读了一万本关于猫的书,记住了所有描述猫的文字——"毛茸茸""可爱""喵喵叫""抓老鼠"。你能写出关于猫的文章,但你不知道猫真正长什么样。
AI就是那个"外国人"。它"读"了几万亿Token的文本,但它从来没有"看过"一只真正的猫。
统计关联够用吗?
在大部分任务上,统计关联已经够用了。翻译、摘要、问答、代码生成——这些任务本质上就是文字模式匹配。统计关联足以完成。
什么时候不够用?
当任务需要真实世界经验时,统计关联就不够了。比如:判断一个物理实验的结果、理解一个笑话的双关、感知一段音乐的情感。这些需要超出文本之外的经验。
为什么AI会犯常识错误?
因为AI没有真实世界的经验。它知道"猫吃鱼"是因为训练文本中"猫"和"鱼"经常一起出现,不是因为它见过猫吃鱼。当遇到训练数据中没有的模式时,它就会犯错。
五、这对我们使用AI有什么启示
理解了AI的"世界观",你就能更好地理解AI为什么会这样回答,以及如何更好地使用它。
理解Token是理解AI的第一步
所有后续概念——上下文窗口、成本计算、Prompt优化——都建立在Token之上。选对模型(Tokenizer)直接影响成本和效果
向量空间是AI的"世界观"
AI的所有"知识"都编码在向量空间里。理解向量,才能理解AI为什么会这样回答,以及如何引导它给出更好的回答
统计关联不等于真正理解
AI很强大,但它的"理解"和人类的理解本质不同。知道这一点,才不会对它有不切实际的期待,也不会低估它的能力
AI不知道它在说什么
它不知道"猫"是什么,只知道"猫"这个Token的统计关联。但这不意味着它没用——在文字处理任务上,统计关联已经足够强大
小结
AI不认识汉字也不认识单词,它只认识Token和向量。它不知道"猫"长什么样,只知道"猫"这个Token的向量位置。
向量空间中,意义相近的词距离近。这是AI理解语义的数学基础——不是人工设计的,是训练过程中自动涌现的。
AI不懂意义,只懂关联。但在文字处理任务上,统计关联已经够强大了。
下期预告
Tokenizer分词器
一段话到底是怎么被切成碎片的?BPE算法、子词切分、为什么"strawberry"会被切成奇怪的几块——下一期拆开Tokenizer的内部机制。
看完有启发的话,点个"在看"再走
本文包含AI辅助创作内容,作者已审核并对全文负责
