 夜雨聆风
夜雨聆风2026年6月第一周AI大事件:代码自主化、端侧推理与Agent安全三重变奏
本周,Anthropic、微软、Google、OpenAI、阿里巴巴五家巨头几乎同时亮出了自己的底牌。如果你只盯着其中一家看,可能会觉得"嗯,不错"。但如果把它们放在一起,你会发现一张更大的图正在拼合。
这一周,硅谷和台北同时热闹非凡。
微软Build 2026开发者大会在旧金山拉开帷幕;Computex 2026在台北登场,Intel、Nvidia轮番登台。而就在这两场大会期间,Anthropic抛出了一颗重磅炸弹,OpenAI悄悄升级了Codex,Google则用一个12B的小模型重新定义了"本地AI"的边界。
笔者把这周的信息梳理之后,发现三条主线正在浮出水面。它们互相关联,指向同一个方向:AI正在从"云端玩具"变成"生产工具"——而这个过程,比大多数人预想的更快。
一、Anthropic的80%:代码自主化不再是远景
如果说之前"AI写代码"还停留在"帮你补全几行"的阶段,那Anthropic这周给出的数据足以让每个工程师重新思考自己的职业定位。
超过80%——这是Anthropic在2026年5月合并到生产代码库中的代码中,由Claude自主编写的比例。不是辅助生成,不是"人类写80%+AI写20%",而是反过来:AI写了80%,人类做审查和架构决策。
更值得关注的是附带效应:Anthropic工程师人均每季度交付的代码量,相比2021-2025年基线,增长了8倍。在复杂、开放式工程问题上,Claude的成功率从2025年11月到2026年5月提升了50个百分点,达到76%。而其内部Mythos Preview模型在优化AI训练代码的基准测试中,实现了52倍加速——对比之下,一个熟练的人类开发者花4-8小时手动重构只能做到4倍加速。
这意味着什么?笔者认为有三层含义:
第一,AI编程的衡量标准变了。 以前我们问"AI能写代码吗",现在该问"AI能独立完成工程任务吗"。SWE-bench这类评估框架在过去两年内已经趋于饱和,不是因为AI变慢了,而是因为基准测试不够用了。
第二,"递归自我改进"的幽灵正在逼近。 Anthropic自己的报告坦率地将这一进展描述为"递归自我改进"的早期信号——AI模型开始有能力改进自己依赖的代码基础设施。这不是科幻,是写入生产环境的代码统计数据。
第三,企业的竞争基线被重置了。 如果你的竞对能够用AI完成80%的编码工作,而你还在让工程师一行一行地敲——这不是效率差距,这是生存问题。
不过,也别急着恐慌。Anthropic同时指出,代码量的暴涨意味着"有更多的代码需要人去审查"。工程师的角色不是消失,而是从"写代码的人"变成"定义目标和把关质量的人"。
二、端侧AI三连击:Google、微软、Perplexity同时押注"本地优先"
如果说Anthropic代表的是"让AI越来越强",那本周另一条主线恰恰相反:让AI离你越来越近。
Google Gemma 4 12B:把多模态塞进16GB笔记本
Google本周发布了Gemma 4 12B,一个119.5亿参数的开源模型,Apache 2.0许可,仅需16GB显存或统一内存就能在普通笔记本上本地运行。
技术上最亮眼的设计是"统一架构"——这个模型没有传统的独立编码器。传统多模态系统需要单独的视觉编码器和音频编码器来翻译数据,而Gemma 4用一个仅3500万参数的轻量线性投影层替代了视觉编码器,音频编码器则直接砍掉,原始音频波形直接流入核心LLM的嵌入空间。
这意味着什么?更低的延迟、更少的内存占用,以及对隐私敏感场景的原生友好——医疗、金融、国防等行业的敏感数据不再需要离开你的电脑。
它还有个256K token的上下文窗口,支持原生的"思考模式"和函数调用,开箱即用就能构建Agent。
Microsoft Surface RTX Spark:1 petaflop的桌面AI算力
微软在Build大会上发布的Surface RTX Spark Dev Box更进一步:128GB统一内存、Nvidia Blackwell架构RTX Spark处理器、1 petaflop的AI算力,塞进一个小型台式机箱。
这台机器可以直接加载并运行超过1200亿参数的大模型——不需要任何API调用。微软Windows与设备执行副总裁Pavan Davuluri在发布会上算了一笔账:跑10万token的上下文,仅KV缓存就可能吃掉40-50GB内存——这就是为什么他们押注128GB统一内存架构。
笔者觉得最耐人寻味的是:微软是Azure云服务的母公司,却主动推出了一款"减少云依赖"的硬件。 这相当于一个卖汽油的公司开始卖电动车。Andrew Hill的原话是"让开发者把真正的前沿模型调用留给真正的前沿问题"。背后的逻辑很清楚:开发者本地原型开发,最终部署时还是上Azure。但不可否认,这种"本地优先、云端兜底"的模式正在成为新常态。
Perplexity:本地和云端之间,AI自己选
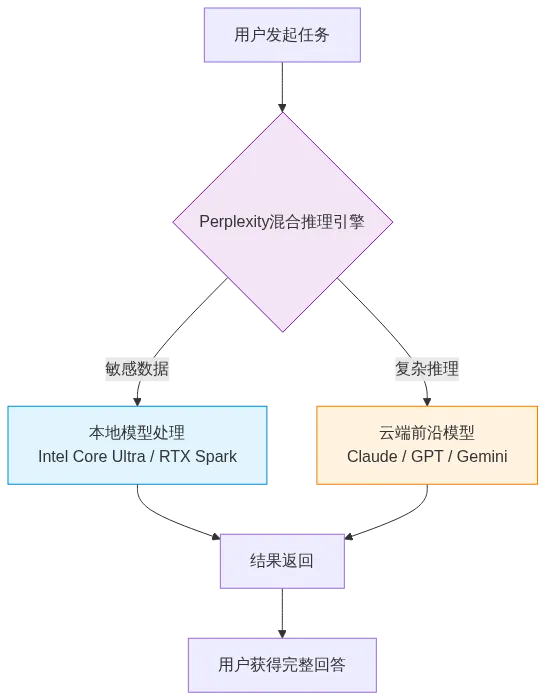
Computex 2026上,Perplexity CEO Aravind Srinivas展示了更激进的方案:一个能自动决策每个子任务该在本地还是云端执行的混合推理系统。
关键区别在于:你没有"选择在本地运行"——系统自己判断。财务数据、健康信息等敏感内容自动留在本地设备;重推理任务则路由到云端前沿模型。一个任务,多个执行位置,全程自动编排。
Srinivas在Intel CEO Lip-Bu Tan的Keynote上做了现场演示,用的是搭载Intel Core Ultra Series 3的设备。Perplexity方面表示该功能将在未来几周内上线。
把这三件事放在一起看,一个清晰的趋势出现了:"本地AI"不再等于"阉割版AI"。 Google用12B参数实现了多模态,微软用128GB统一内存拉高了本地算力天花板,Perplexity用智能路由解决了"本地不够用、云端不安全"的两难。三者各解决拼图的一块,合在一起就是端侧AI的完整图景。
三、AI Agent的"安全带":微软MXC和OpenAI Codex的双重变奏
趋势一告诉我们AI能自己写代码了,趋势二告诉我们AI能跑在本地了。但还有一个问题没回答——你敢让它放手干吗?
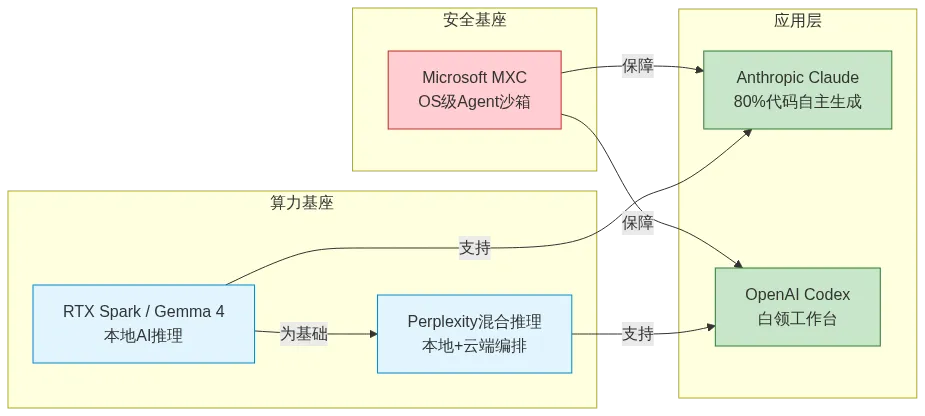
Microsoft MXC:操作系统的原生Agent沙箱
微软在Build上发布的MXC(Microsoft Execution Containers)是本周笔者认为最有远见的产品之一——不是因为它有多炫酷,而是因为它解决的恰恰是整个行业最不敢面对的问题。
MXC是一个嵌入Windows操作系统的策略驱动执行层。它的核心能力是:让IT管理员精确声明AI Agent能访问什么、不能访问什么,由操作系统内核在运行时强制执行。
这个"沙箱"可以从轻量级进程隔离一路扩展到微虚拟机、Linux容器、甚至Windows 365云实例。每个Agent被绑定到一个强身份(本地ID或Microsoft Entra云身份),Agent的每一个动作都可追溯、可审计、可治理。
为什么这很重要?因为安全圈在过去几个月里已经反复证明了AI Agent可以被提示注入、恶意工具调用和数据泄露攻破。微软自己说得很直白:"问题不只是Agent,而是Agent运行的整个系统。每一次Agent与人类、工具、应用、模型以及其他Agent的交互,都暴露了新的攻击面。"
MXC的定位很清楚:不是让Agent不那么危险,而是让Agent运行的环境从根本上变得更可控。
OpenAI Codex:程序员工具变身白领工作台
OpenAI这边则是另一条路线——让Agent在企业日常运营中变得不可或缺。
Codex本周的升级有几个数据值得注意:
500万周活用户中来源[1],,非开发者占20%(金融分析师、市场营销、运营人员、研究员) 非开发者用户增速是工程师的3倍 推出6个角色专用插件,整合62款主流企业应用来源[2](Snowflake、Figma、Salesforce等) 新增"Sites"功能,Agent可以在企业内部快速搭建交互式工作空间 新增"Annotations",解决AI编辑文档时"全量重写"的老问题
笔者观察到,OpenAI和微软正在从不同方向合围企业市场:微软从OS层面做安全基座,OpenAI从应用层做工作流渗透。一个管"不出事",一个管"能干事"。
而Gartner的预测进一步印证了这个趋势:到2026年底,40%的企业应用来源: Gartner 2026预测[3]将包含任务特定的AI Agent——目前这个比例不到5%。从现在到年底还有6个月,意味着企业AI Agent的渗透率需要在半年内增长8倍。
四、附:本周AI模型API定价全景
阿里巴巴本周还发布了Qwen3.7-Plus多模态模型,输入1.60/百万token,比上代Qwen3.7-Max降了60%。但一个值得注意的变化是:它是闭源的。这与Qwen此前聚焦开源的战略形成了鲜明反差——毕竟Airbnb等美国巨头已经在生产环境中依赖Qwen的开源模型。
从VentureBeat整理的定价表来看,当前API市场已经形成了清晰的分层:
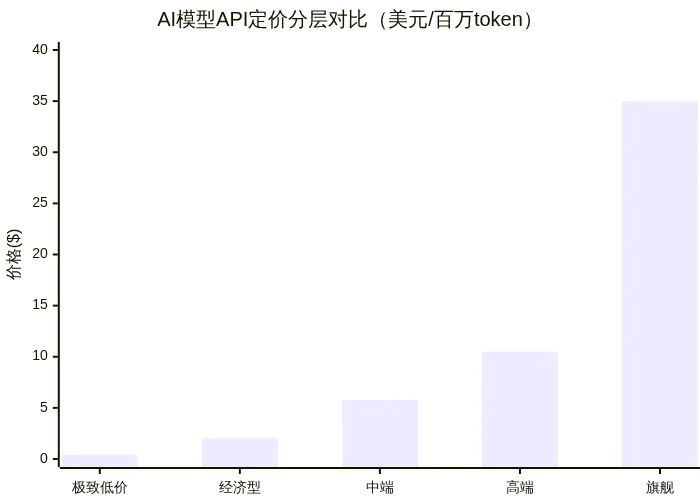
这个价差——最低到最高相差近90倍——在笔者看来,恰恰说明了为什么Microsoft要推RTX Spark、为什么Perplexity要做混合推理。当你每次调用都可能被收取$35/百万token的时候,"本地跑、云端兜底"不是一种选择,而是一种数学必然。
笔者总结
把本周的新闻串起来,笔者看到的是一个清晰的三角结构:
底边是"算力下移"——Google用Gemma 4证明12B就能跑多模态,微软用RTX Spark把120B模型拉到桌面,Perplexity用混合推理打通了最后一公里。"不开WiFi也能用AI"这件事,从幻想变成了产品。
左边是"能力上探"——Anthropic证明了AI不仅能写代码,还能独立完成80%的生产级软件开发。这不是"帮你写个函数",而是"你告诉我要做什么,我直接把整个系统弄好"。工程师的护城河正在从"会写代码"转移到"知道该写什么代码"。
右边是"安全兜底"——微软的MXC和OpenAI的Codex升级分别从底层安全和工作流渗透两个维度,回答了同一个问题:企业能不能信任AI Agent。没有这个答案,前面两条线的所有进展都走不出Demo阶段。
这三个点,缺一不可。而2026年6月的第一周,恰好三个点同时被按下加速键。
最后说一句题外话:笔者注意到一个有趣的细节。Anthropic的报告中提到,代码量8倍增长的同时,"意味着有更多的代码需要人去审查"。这其实揭示了一个普遍的认知盲区——自动化的终点不是消灭人类劳动,而是改变人类劳动的性质。 审查AI写的代码,定义AI应该做什么,设计AI运行的边界——这些才是下一代工程师的核心技能。
你准备好迎接这个转变了吗?
9项自查清单
引用链接
[1]来源: https://openai.com/index/introducing-codex/
[2]来源: https://openai.com/index/introducing-codex/
[3]来源: Gartner 2026预测: https://www.gartner.com/en/newsroom
