 夜雨聆风
夜雨聆风AI 应用失败时,最该复盘的往往不是“模型够不够聪明”,而是任务边界、上下文预算和产品范围有没有被设计好。
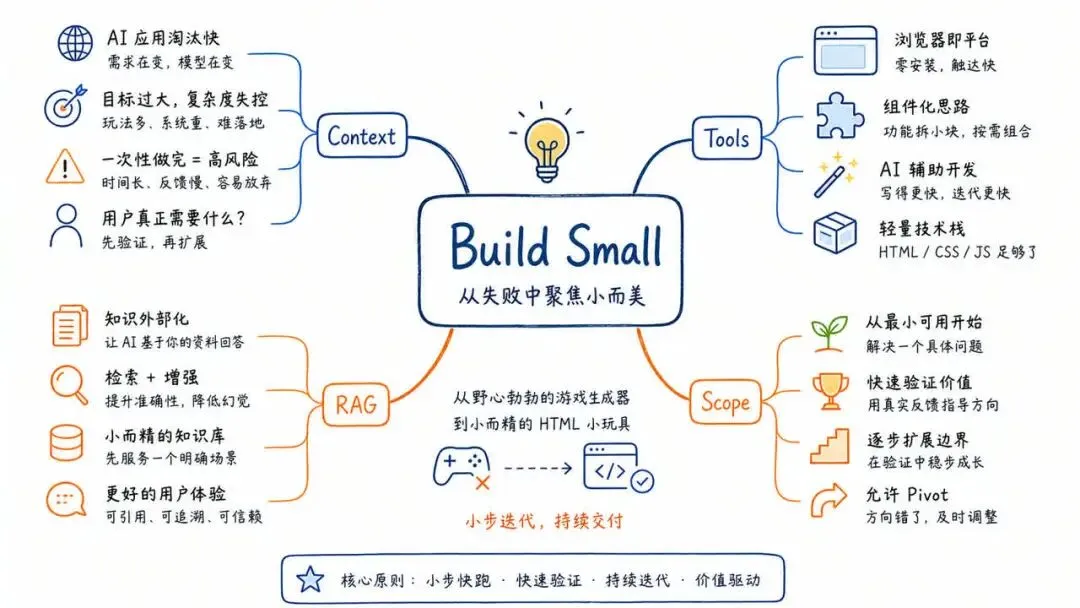
一个失败项目,比成功 Demo 更容易暴露 AI 产品的真实约束。
一个很典型的失败故事
Hugging Face Blog 上有一篇很短的项目复盘,标题很诚实:Amazing Digital Dentures,一个失败项目。
作者最初想做一个“数字宠物”:它会给你生成冒险任务,把待办事项包装成游戏,像一个过度工程化的 gamified todo list。
后来范围失控了。
项目从“辅助现实生活里的行动”滑向“让模型生成完整 three.js 游戏”。作者尝试了长提示词、技能卡、扩大上下文、把技能蒸馏成文本、再做 RAG。结果仍然经常生成不能运行的游戏,页面变成空白。
最后,项目被收缩成一个更小的 HTML toy maker:能一次生成时钟、待办、贪吃蛇、打砖块这类简单东西,但复杂到俄罗斯方块就会崩。
这不是一个宏大案例,却很有代表性。
第一处问题:任务从产品目标漂移到技术炫技
最初的产品目标其实是清楚的:用一个数字宠物让用户更愿意完成现实世界的任务。
这对应的是行为设计、动机反馈、任务拆解和留存机制。
但后来焦点变成了“能不能生成完整游戏”。这就从一个产品问题,变成了一个高难度代码生成问题。
这类漂移在 AI 产品里非常常见:
本来要解决用户问题,最后在证明模型能力; 本来只需要稳定小功能,最后追求一站式自动生成; 本来要做一个闭环,最后堆了更多提示词和工具。
AI 产品最容易犯的错,是把“模型能不能做到”误当成“用户是否需要”。
第二处问题:上下文不是越多越好
作者尝试加入 GitHub 上的 skill cards,希望模型生成更好的游戏代码。
但技能卡撑爆了短上下文。后来扩大上下文,又没有真正解决问题。
这说明一个关键事实:上下文窗口不是垃圾桶。
把更多规则、范例、技能说明塞进去,不一定会提升结果,反而可能制造噪音。模型不知道哪些约束优先,也不知道当前任务到底需要哪一部分知识。
RAG 也不是万能解。它可以帮助取回相关知识,但如果任务本身过大、验证链路不足、输出需要复杂调试,RAG 只能缓解信息不足,不能替代工程闭环。
第三处问题:缺少可验证的中间步骤
生成一个完整 three.js 游戏,不是一个单步任务。
它至少包括:
设计玩法; 搭建场景; 写交互逻辑; 处理资源和坐标; 运行并调试; 根据错误修复。
如果让模型一次性吐出完整代码,没有运行、测试、截图、错误反馈,就很容易得到“看起来像代码,但实际空白”的结果。
这也是 AI 工程实践的核心:
生成不是终点,验证才是闭环。
为什么收缩后反而更接近可用
作者最后把项目收缩成 simple HTML toymaker。
这听起来像降级,但可能是正确方向。
简单 HTML 小玩具的边界更清楚,依赖更少,验证更快,用户也更容易理解它能做什么。它不再承诺“生成完整游戏世界”,而是承诺“做一个小而可玩的网页东西”。
对很多 AI 应用来说,成功不是把范围扩大,而是把范围缩到模型和产品都能稳定兑现。
给 AI 产品团队的四条经验
1. 先定义最小可交付任务
不要问“模型最多能做什么”,先问“用户最小需要什么”。
2. 把生成拆成可验证步骤
尤其是代码、设计、数据分析类任务,必须有运行、检查和修复环节。
3. 控制上下文,而不是盲目加料
技能、文档、示例都应该按需检索,并且明确优先级。
4. 允许产品主动降级
如果完整游戏不稳定,就做小玩具;如果自动代理不稳定,就做人机协作;如果一键完成不稳定,就做分步确认。
降级不是失败,失控才是失败。
结尾:Build Small,不只是黑客松口号
AI 应用的很多问题,并不需要更大的模型来解决,而需要更小的产品边界。
把任务变小,把验证补上,把承诺说清楚,往往比继续堆 prompt 更有效。
这篇失败复盘真正有价值的地方,就在于它提醒我们:一个不能稳定交付的小产品,不会因为名字里有 AI 就变成大产品。
参考资料
Hugging Face Blog: Amazing Digital Dentures (a failed project)
